使用grep、awk统计查询日志
时间:2015-10-06 22:52 来源:www.it.net.cn 作者:IT网
linux命令给我们带来了很多方便,多熟悉写命令能节省不少时间!
日志样本:
囧,日志格式是我随便定得(莫喷,在明珠时有专门的数据组统计日志,日志都非常规范,在这完全乱套了),为了方便统计支付成功的总金额旁边都空了个空格,这样的话方便使用awk取出金额!
1
2
[INFO] 2014-11-05 15:30:31,067 [http-bio-8060-exec-24] [com.xxxx.service.impl.PayServiceImpl.updatePayOver:56]module:[PAY],orderid:[xxxxxxx],trade_no:[xxxxxxxx],total_fee:[2560.0],payMethod:[百度钱包]
[INFO] 2014-11-05 15:30:31,095 [http-bio-8060-exec-24] [com.xxxx.service.impl.PayServiceImpl.updatePayOver:60]module:[PAY],orderid:[xxxxxxx],trade_no:[xxxxxxxx],total_fee:[ 2560.0 ],payMethod:[百度钱包],code:[payok]
第一步:统计出支付成功的日志
*”[]“属于正则关键字故需要转义
1
grep 'code:\[payok\]' catalina.out
当然,为了性能我们可以查出支付成功的订单时就将它写入一个文件,后面的查询再依据这个来查询!
1
grep 'code:\[payok\]' catalina.out > ~/test.txt
第二部:取出金额,并计算金额
1
cat ~/test.txt | awk '{print $6}' | awk '{sum+=$1} END {print sum}'
当然需要查询支付成功的订单的数目直接
1
wc -l ~/test.txt
下面对上面的查询进行扩展:
1. 查询当天的支付的订单数目
1
cat ~/test.txt | grep -c `date "+%Y-%m-%d"`
同样也是先筛选出支付成功的订单,然后再塞选今天的数目
这里先列出grep常用的命令行选项:
1
2
3
4
5
6
7
8
9
10
-c 只显示有多少行匹配,而不具体显示匹配的行。
-h 不显示文件名。
-i 在字符串比较的时候忽略大小写。
-l 只显示包含匹配模板的行的文件名清单。
-L 只显示不包含匹配模板的行的文件名清单。
-n 在每一行前面打印改行在文件中的行数。
-v 反向检索,只显示不匹配的行。
-w 只显示完整单词的匹配。
-x 只显示完整行的匹配。
-r/-R 如果文件参数是目录,该选项将递归搜索该目录下的所有子目录和文件。
2. 查询当月支付成功的订单
1
cat ~/test.txt | grep `date "+%Y-%m"`
date为日期函数``表示嵌套命令,也可以直接grep 2014-11,对于中文字符或者有空格的需要grep 后面的参数加上""引号(单引或者双引貌似都行)
3. 统计10月和11月的订单grep支持正则,很是强大
1
grep '2014-1[0-1]'
剩下的不多说的,看官自己去扩展
下面来说说replace、find
1. 查询多个 tomcat的 Context信息(之前面试的时候有遇到过,确实很方便)
1
find ./ -name server.xml | xargs grep "<Context"
2. 统一更改配置文件中的支付回调域名(前提:有100多个配置文件source_xxx.properties修改,实在受不了,查了这个命令,非常好用)
1
replace 'xxx.xxx.cn' 'xx.xxx.cn' -- source_*
希望大家补充,我也好去多学习一些,啊哈哈哈...
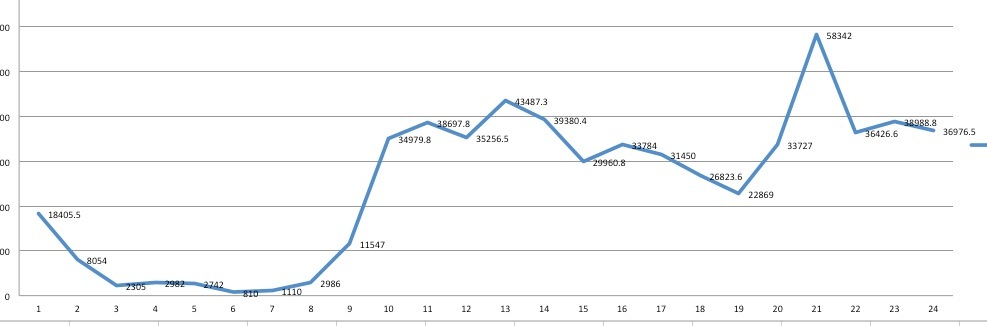
下面是按照每天统计出来的热点图,如图可看出其实7点左右支付的人最少最适合更新代码!
(责任编辑:IT)
| linux命令给我们带来了很多方便,多熟悉写命令能节省不少时间! 日志样本: 囧,日志格式是我随便定得(莫喷,在明珠时有专门的数据组统计日志,日志都非常规范,在这完全乱套了),为了方便统计支付成功的总金额旁边都空了个空格,这样的话方便使用awk取出金额!
*”[]“属于正则关键字故需要转义
第二部:取出金额,并计算金额
当然需要查询支付成功的订单的数目直接
下面对上面的查询进行扩展: 1. 查询当天的支付的订单数目
同样也是先筛选出支付成功的订单,然后再塞选今天的数目 这里先列出grep常用的命令行选项:
2. 查询当月支付成功的订单
date为日期函数``表示嵌套命令,也可以直接grep 2014-11,对于中文字符或者有空格的需要grep 后面的参数加上""引号(单引或者双引貌似都行) 3. 统计10月和11月的订单grep支持正则,很是强大
下面来说说replace、find 1. 查询多个 tomcat的 Context信息(之前面试的时候有遇到过,确实很方便)
2. 统一更改配置文件中的支付回调域名(前提:有100多个配置文件source_xxx.properties修改,实在受不了,查了这个命令,非常好用)
希望大家补充,我也好去多学习一些,啊哈哈哈... 下面是按照每天统计出来的热点图,如图可看出其实7点左右支付的人最少最适合更新代码!
|