hadoop-ID分析
时间:2015-10-08 12:00 来源:linux.it.net.cn 作者:IT
我们开始来分析Hadoop MapReduce的内部的运行机制。用户向Hadoop提交Job(作业),作业在JobTracker对象的控制下执行。Job被分解成为Task(任务),分发到集群中,在TaskTracker的控制下运行。Task包括MapTask和ReduceTask,是MapReduce的Map操作和Reduce操作执行的地方。这中任务分布的方法比较类似于HDFS中NameNode和DataNode的分工,NameNode对应的是JobTracker,DataNode对应的是TaskTracker。JobTracker,TaskTracker和MapReduce的客户端通过RPC通信,具体可以参考HDFS部分的分析。
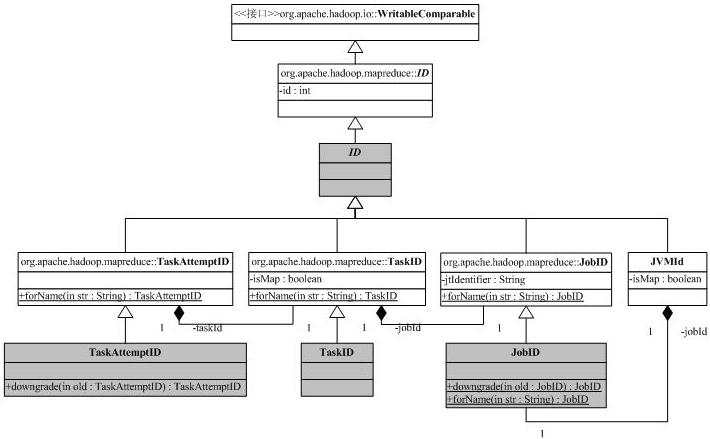
我们先来分析一些辅助类,首先是和ID有关的类,ID的继承树如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
* Licensed to the Apache Software Foundation (ASF) under one
package org.apache.hadoop.mapreduce;
import java.io.DataInput;
/**
* A general identifier, which internally stores the id
* as an integer. This is the super class of {@link JobID},
* {@link TaskID} and {@link TaskAttemptID}.
*
* @see JobID
* @see TaskID
* @see TaskAttemptID
*/
public abstract class ID implements WritableComparable<ID> {
protected static final char SEPARATOR = '_';
protected int id;
/** constructs an ID object from the given int */
public ID(int id) {
this.id = id;
}
protected ID() {
}
/** returns the int which represents the identifier */
public int getId() {
return id;
}
@Override
public String toString() {
return String.valueOf(id);
}
@Override
public int hashCode() {
return Integer.valueOf(id).hashCode();
}
@Override
public boolean equals(Object o) {
if (this == o)
return true;
if(o == null)
return false;
if (o.getClass() == this.getClass()) {
ID that = (ID) o;
return this.id == that.id;
}
else
return false;
}
/** Compare IDs by associated numbers */
public int compareTo(ID that) {
return this.id - that.id;
}
public void readFields(DataInput in) throws IOException {
this.id = in.readInt();
}
public void write(DataOutput out) throws IOException {
out.writeInt(id);
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
* Licensed to the Apache Software Foundation (ASF) under one
package org.apache.hadoop.mapreduce;
import java.io.DataInput;
/**
* JobID represents the immutable and unique identifier for
* the job. JobID consists of two parts. First part
* represents the jobtracker identifier, so that jobID to jobtracker map
* is defined. For cluster setup this string is the jobtracker
* start time, for local setting, it is "local".
* Second part of the JobID is the job number. <br>
* An example JobID is :
* <code>job_200707121733_0003</code> , which represents the third job
* running at the jobtracker started at <code>200707121733</code>.
* <p>
* Applications should never construct or parse JobID strings, but rather
* use appropriate constructors or {@link #forName(String)} method.
*
* @see TaskID
* @see TaskAttemptID
* @see org.apache.hadoop.mapred.JobTracker#getNewJobId()
* @see org.apache.hadoop.mapred.JobTracker#getStartTime()
*/
public class JobID extends org.apache.hadoop.mapred.ID
implements Comparable<ID> {
protected static final String JOB = "job";
private final Text jtIdentifier;
protected static final NumberFormat idFormat = NumberFormat.getInstance();
static {
idFormat.setGroupingUsed(false);
idFormat.setMinimumIntegerDigits(4);
}
/**
* Constructs a JobID object
* @param jtIdentifier jobTracker identifier
* @param id job number
*/
public JobID(String jtIdentifier, int id) {
super(id);
this.jtIdentifier = new Text(jtIdentifier);
}
public JobID() {
jtIdentifier = new Text();
}
public String getJtIdentifier() {
return jtIdentifier.toString();
}
@Override
public boolean equals(Object o) {
if (!super.equals(o))
return false;
JobID that = (JobID)o;
return this.jtIdentifier.equals(that.jtIdentifier);
}
/**Compare JobIds by first jtIdentifiers, then by job numbers*/
@Override
public int compareTo(ID o) {
JobID that = (JobID)o;
int jtComp = this.jtIdentifier.compareTo(that.jtIdentifier);
if(jtComp == 0) {
return this.id - that.id;
}
else return jtComp;
}
/**
* Add the stuff after the "job" prefix to the given builder. This is useful,
* because the sub-ids use this substring at the start of their string.
* @param builder the builder to append to
* @return the builder that was passed in
*/
public StringBuilder appendTo(StringBuilder builder) {
builder.append(SEPARATOR);
builder.append(jtIdentifier);
builder.append(SEPARATOR);
builder.append(idFormat.format(id));
return builder;
}
@Override
public int hashCode() {
return jtIdentifier.hashCode() + id;
}
@Override
public String toString() {
return appendTo(new StringBuilder(JOB)).toString();
}
@Override
public void readFields(DataInput in) throws IOException {
super.readFields(in);
this.jtIdentifier.readFields(in);
}
@Override
public void write(DataOutput out) throws IOException {
super.write(out);
jtIdentifier.write(out);
}
/** Construct a JobId object from given string
* @return constructed JobId object or null if the given String is null
* @throws IllegalArgumentException if the given string is malformed
*/
public static JobID forName(String str) throws IllegalArgumentException {
if(str == null)
return null;
try {
String[] parts = str.split("_");
if(parts.length == 3) {
if(parts[0].equals(JOB)) {
return new org.apache.hadoop.mapred.JobID(parts[1],
Integer.parseInt(parts[2]));
}
}
}catch (Exception ex) {//fall below
}
throw new IllegalArgumentException("JobId string : " + str
+ " is not properly formed");
}
}
这张图可以看出现在Hadoop的org.apache.hadoop.mapred向org.apache.hadoop.mapreduce迁移带来的一些问题,其中灰色是标注为@Deprecated的。ID携带一个整型,实现了WritableComparable接口,这表明它可以比较,而且可以被Hadoop的io机制串行化/解串行化(必须实现compareTo/readFields/write方法)。JobID是系统分配给作业的唯一标识符,它的toString结果是job_<jobtrackerID>_<jobNumber>。例子:job_200707121733_0003表明这是jobtracker 200707121733(利用jobtracker的开始时间作为ID)的第3号作业。
作业分成任务执行,任务号TaskID包含了它所属的作业ID,同时也有任务ID,同时还保持了这是否是一个Map任务(成员变量isMap)。任务号的字符串表示为task_<jobtrackerID>_<jobNumber>_[m|r]_<taskNumber>,如task_200707121733_0003_m_000005表示作业200707121733_0003的000005号任务,改任务是一个Map任务。
一个任务有可能有多个执行(错误恢复/消除Stragglers等),所以必须区分任务的多个执行,这是通过类TaskAttemptID来完成,它在任务号的基础上添加了尝试号。一个任务尝试号的例子是attempt_200707121733_0003_m_000005_0,它是任务task_200707121733_0003_m_000005的第0号尝试。
JVMId用于管理任务执行过程中的Java虚拟机,我们后面再讨论。
(责任编辑:IT)
我们开始来分析Hadoop MapReduce的内部的运行机制。用户向Hadoop提交Job(作业),作业在JobTracker对象的控制下执行。Job被分解成为Task(任务),分发到集群中,在TaskTracker的控制下运行。Task包括MapTask和ReduceTask,是MapReduce的Map操作和Reduce操作执行的地方。这中任务分布的方法比较类似于HDFS中NameNode和DataNode的分工,NameNode对应的是JobTracker,DataNode对应的是TaskTracker。JobTracker,TaskTracker和MapReduce的客户端通过RPC通信,具体可以参考HDFS部分的分析。 我们先来分析一些辅助类,首先是和ID有关的类,ID的继承树如下:
这张图可以看出现在Hadoop的org.apache.hadoop.mapred向org.apache.hadoop.mapreduce迁移带来的一些问题,其中灰色是标注为@Deprecated的。ID携带一个整型,实现了WritableComparable接口,这表明它可以比较,而且可以被Hadoop的io机制串行化/解串行化(必须实现compareTo/readFields/write方法)。JobID是系统分配给作业的唯一标识符,它的toString结果是job_<jobtrackerID>_<jobNumber>。例子:job_200707121733_0003表明这是jobtracker 200707121733(利用jobtracker的开始时间作为ID)的第3号作业。
作业分成任务执行,任务号TaskID包含了它所属的作业ID,同时也有任务ID,同时还保持了这是否是一个Map任务(成员变量isMap)。任务号的字符串表示为task_<jobtrackerID>_<jobNumber>_[m|r]_<taskNumber>,如task_200707121733_0003_m_000005表示作业200707121733_0003的000005号任务,改任务是一个Map任务。 一个任务有可能有多个执行(错误恢复/消除Stragglers等),所以必须区分任务的多个执行,这是通过类TaskAttemptID来完成,它在任务号的基础上添加了尝试号。一个任务尝试号的例子是attempt_200707121733_0003_m_000005_0,它是任务task_200707121733_0003_m_000005的第0号尝试。
JVMId用于管理任务执行过程中的Java虚拟机,我们后面再讨论。 |