MongoDB与MySQL的插入、查询性能测试
时间:2015-10-10 14:11 来源:linux.it.net.cn 作者:IT
1.1 MongoDB的简单介绍
在当今的数据库市场上,MySQL无疑是占有一席之地的。作为一个开源的关系型数据库,MySQL被大量应用在各大网站后台中,承担着信息存储的重要作用。2009年,甲骨文公司(Oracle)收购Sun公司,MySQL成为Oracle旗下产品。
而MongoDB是一种文件导向的数据库管理系统,属于一种通称为NoSQL的数据库,是10gen公司旗下的开源产品,其内部数据存储的方式与传统的关系型数据有很大差别。
NoSQL的全称是Not Only SQL,也可以理解非关系型的数据库,是一种新型的革命式的数据库设计方式,不过它不是为了取代传统的关系型数据库而被设计的,它们分别代表了不同的数据库设计思路。
虽然MongoDB背后的公司没有Oracle强大,但其目前也正在被应用在各行各业中。MongoDB是目前被应用最广泛的NoSQL数据库产品。
1.2 MongoDB的存储特点
在传统的关系型数据库中,数据是以表单为媒介进行存储的,每个表单均拥有纵向的列和横向的行。以MySQL为例,如果用户想以学生的学号为索引,存入其姓名与住址信息时,数据库中存放的信息便如下图所示:
ID
Name
Address
10001
Alice
A1
10002
Bob
A2
10003
Cara
A3
10004
David
A4
10005
Eve
A5
上图表明数据库中存入了5个表项,其记录了学号为10001 – 10005的学生的姓名与住址信息。
如果用户欲把相应的信息重新存入MongoDB数据库,那么数据库中的信息应该为如下所示:
"_id" : "10001",
"Name" : "Alice",
"Address" : "A1",
"_id" : "10002",
"Name" : "Bob",
"Address" : "A2",
"_id" : "10003",
"Name" : " Cara",
"Address" : "A3",
"_id" : "10004",
"Name" : " David",
"Address" : "A4",
"_id" : "10005",
"Name" : " Eve",
"Address" : "A5",
由此可见,相比较MySQL,MongoDB以一种直观文档的方式来完成数据的存储。它很像JavaScript中定义的JSON格式,不过数据在存储的时候MongoDB数据库为文档增加了序列化的操作,最终存进磁盘的其实是一种叫做BSON的格式,即Binary-JSON。
对比两个数据库中数据存储的差异,你可能没有什么特别的直观感受。让我们再看看MongoDB存放的另一组数据:
"_id" : "10001",
"score" : {
"Maths" : 71,
"English" : 62,
}
"_id" : "10002",
"score" : {
"Maths" : 81,
"Chemistry" : 74,
"Sport" : {
"Basketball" : 67,
"Badminton" : 76,
},
}
上述数据表明了学号为10001与10002两名学生的课程分数信息。如果想把同样的数据存入MySQL数据中的话,势必要很费一番功夫。在关系型数据库中,列的数目一般事先固定,各列之间可以由列名来识别。如果想存入以上数据,我们可以采取如下方法:
ID
Maths
English
Chemistry
Basketball
Badminton
10001
71
62
null
null
null
10002
81
null
74
67
76
或者如下这种:
ID
Course
Score
Course
Score
Course
Score
Course
Score
10001
Maths
71
English
62
null
null
null
null
10002
Maths
81
Chemistry
74
Basketball
67
Badminton
76
上述两种存储方式无论选哪一种,都不能很直观地呈现两名学生的各科成绩与各学科之间隶属关系,在存储空间上的利用也不尽如意,并且可扩展性也不够好。当然,为了解决这些问题,我们还可以使用多张表单来存储学生的成绩,但这样也会使数据库中的内容更加复杂。
1.2 MongoDB的应用场景
在另一方面,对开发者来说,如果是因为业务需求或者是项目初始阶段,而导致数据的具体格式无法明确定义的话,MongoDB的这一鲜明特性就脱颖而出了。相比传统的关系型数据库,它非常容易被扩展,这也为写代码带来了极大的方便。
不过MongoDB对数据之间事务关系支持比较弱,如果业务这一方面要求比较高的话,MongoDB还是并不适合此类型的应用。
另外,MongoDB出现的时机比较晚,还具备一些非常鲜明的特性。比如:
1. 它里面自带了一个名叫GirdFS的分布式文件系统,这就为MongoDB的部署提供了很大便利。而像MySQL这种比较早的数据库,虽然市面上有很多不同的分表部署的方案,但这种终究不如MongoDB直接官方支持来得便捷实在。
2. 另外,MongoDB内部还自建了对map-reduce运算框架的支持,虽然这种支持从功能上看还算是比较简单的,相当于MySQL里GroupBy功能的扩展版,不过也为数据的统计带来了方便。
3. MongoDB在启动后会将数据库中的数据以文件映射的方式加载到内存中。如果内存资源相当丰富的话,这将极大地提高数据库的查询速度,毕竟内存的I/O效率比磁盘高多了。
但是,作为一个新鲜的事务,MongoDB也存在着很多不足。它在为开发人员提供了便利的情况下,却在运维上面临着不少难题,比如:
1. 比起MySQL,MongoDB没有成熟的运维经验,需要不断地探索。
2. MongoDB中的数据存放具有相当的随意性,不具有MySQL在开始就定义好了。对运维人员来说,他们可能不清楚数据库内部数据的数据格式,这也会数据库的运维带来了麻烦。
2. 测试目的
MongoDB与MySQL作为两种不同类型的数据库,当其中存放的记录越来越多的时候,其插入效率将会受到怎样的影响,是本次实验所关注的对象。
在这里,我们将本次实验数据库中数据存储的规模定在1亿条。
3. 测试条件
机器配置: CPU:Intel(R) Xeon(R) CPU E5-2620 @ 2.00GHz
内存:65954040 KB
(关键词:12核CPU,64G内存,给我多好)
操作系统: Linux version 2.6.32_1-8-0-0 (gcc version 4.4.4 20100726 (Red Hat 4.4.4-13) (GCC) )
MongoDB版本: 2.2.3,无任何优化配置,单机测试
MySQL版本: 5.1.49,无任何优化配置,单机测试
测试语言: Python 2.7.1
数据库接口驱动:
MongoDB : PyMongo 2.1.1
MySQL: MySQLdb 1.2.3
4. 概念普及
在数据库存放的数据中,有一种特殊的键值叫做主键,它用于惟一地标识表中的某一条记录。也就是说,一个表不能有多个主键,并且主键不能为空值。
无论是MongoDB还是MySQL,都存在着主键的定义。
对于MongoDB来说,其主键名叫”_id”,在生成数据的时候,如果用户不主动为其分配一个主键的话,MongoDB会自动为其生成一个随机分配的值。
在MySQL中,主键的指定是在MySQL插入数据时指明PRIMARY KEY来定义的。当没有指定主键的时候,另一种工具 —— 索引,相当于替代了主键的功能。索引可以为空,也可以有重复,另外有一种不允许重复的索引叫惟一索引。如果既没有指定主键也没有指定索引的话,MySQL会自动为数据创建一个。
5. 测试方法
1. 制定一个数据库表项的字段模板,以此模板为基准向数据库中插入数据。
2. 在内存中自动生成1亿条待测试数据。数据的格式这里不再一一列出,其里面包含了大概45个字段,其中有一个关键的字段是1 – 100,000,000 的md5值,它们彼此并不相同,其他字段的数据都是写死。每条数据的大小大概有1K。
记住,本次测试的方法是先在内存中生成1亿条数据后,再执行插入操作的。还好测试机器的内存足够大,能够存下如此多的数据。
3. 以如下四种模式向数据库中插入数据,每插1000条数据时,就往一个固定的文件中写入该时刻的时间:
a) 在MongoDB中指定_id为1 – 100,000,000 的md5值,将数据插入;
b) 在MongoDB中不指定_id值,将1 – 100,000,000 的md5值视为普通的字段插入;
c) 在MySQL中以1 – 100,000,000 的md5值为PRIMARY KEY,将数据插入;
d) 在MySQL中不指定PRIMARY KEY,将1 – 100,000,000 的md5值视为普通的字段插入。
4. 根据生成的时间文件记录,分析MySQL与MongoDB的插入性能。
5. 进一步,在以上四种数据库的基础上,再分别测试一下数据库的读取性能。
6. 测试过程
写好测试脚本之后,运行之,睡一觉起床来看结果就可以了。过程是漫长的,但结果却是可喜可贺的 :D
7. 测试结果
7.1 平均每条数据的插入时间
先上张图,来点直观感受:
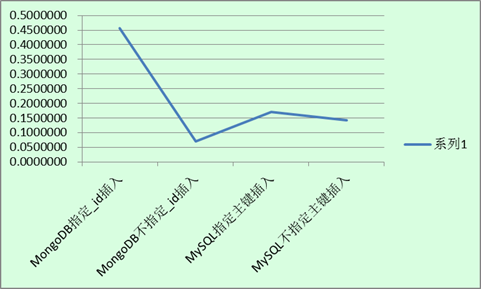
图上数据横坐标是平均每插入1000条数据所需要的时间,单位是秒。记住,是每1000条数据,不是每条数据哦。
总结:
1. 数据库的平均插入速率:MongoDB不指定_id插入 > MySQL不指定主键插入 > MySQL指定主键插入 > MongoDB指定_id插入。
2. MongoDB在指定_id与不指定_id插入时速度相差很大,而MySQL的差别却小很多。
分析:
1. 在指定_id或主键时,两种数据库在插入时要对索引值进行处理,并查找数据库中是否存在相同的键值,这会减慢插入的速率。
2. 在MongoDB中,指定索引插入比不指定慢很多,这是因为,MongoDB里每一条数据的_id值都是唯一的。当在不指定_id插入数据的时候,其_id是系统自动计算生成的。MongoDB通过计算机特征值、时间、进程ID与随机数来确保生成的_id是唯一的。而在指定_id插入时,MongoDB每插一条数据,都需要检查此_id可不可用,当数据库中数据条数太多的时候,这一步的查询开销会拖慢整个数据库的插入速度。
3. MongoDB会充分使用系统内存作为缓存,这是一种非常优秀的特性。我们的测试机的内存有64G,在插入时,MongoDB会尽可能地在内存快写不进去数据之后,再将数据持久化保存到硬盘上。这也是在不指定_id插入的时候,MongoDB的效率遥遥领先的原因。但在指定_id插入时,当数据量一大内存装不下时,MongoDB就需要将磁盘中的信息读取到内存中来查重,这样一来其插入效率反而慢了。
4. MySQL不愧是一种非常稳定的数据库,无论在指定主键还是在不指定主键插入的情况下,其效率都差不了太多。
7.2 插入稳定性分析
插入稳定性是指,随着数据量的增大,每插入一定量数据时的插入速率情况。
在本次测试中,我们把这个指标的规模定在10w,即显示的数据是在每插入10w条数据时,在这段时间内每秒钟能插入多少条数据。
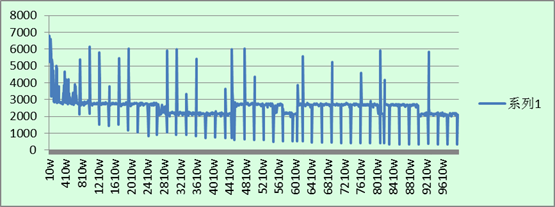
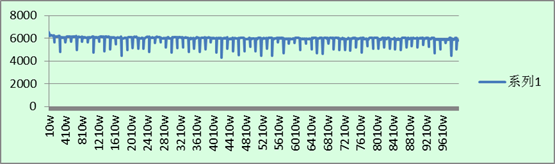
先呈现四张图上来:
1. MongoDB指定_id插入:
2. MongoDB不指定_id插入:
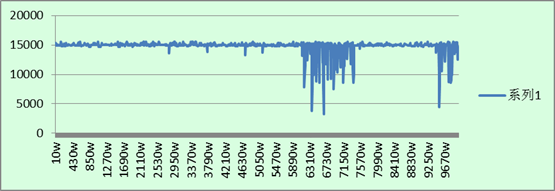
3. MySQL指定PRIMARY KEY插入:
4. MySQL不指定PRIMARY KEY插入:
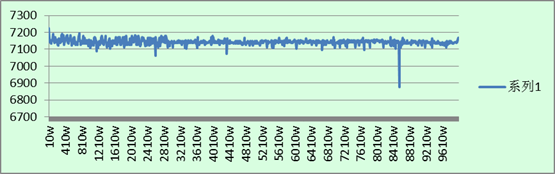
总结:
1. 整体上的插入速度还是和上一回的统计数据类似:MongoDB不指定_id插入 > MySQL不指定主键插入 > MySQL指定主键插入 > MongoDB指定_id插入。
2. 从图中可以看出,在指定主键插入数据的时候,MySQL与MongoDB在不同数据数量级时,每秒插入的数据每隔一段时间就会有一个波动,在图表中显示成为规律的毛刺现象。而在不指定插入数据时,在大多数情况下插入速率都比较平均,但随着数据库中数据的增多,插入的效率在某一时段有瞬间下降,随即又会变稳定。
3. 整体上来看,MongoDB的速率波动比MySQL的严重,方差变化较大。
4. MongoDB在指定_id插入时,当插入的数据变多之后,插入效率有明显地下降。在其他三种的插入测试中,从开始到结束,其插入的速率在大多数的时候都固定在一个标准上。
分析:
1. 毛刺现象是因为,当插入的数据太多的时候,MongoDB需要将内存中的数据写进硬盘,MySQL需要重新分表。这些操作每当数据库中的数据达到一定量级后就会自动进行,因此每隔一段时间就会有一个明显的毛刺。
2. MongoDB毕竟还是新生事物,其稳定性没有已应用多年的MySQL优秀。
3. MongoDB在指定_id插入的时候,其性能的下降还是很厉害的。
7.3 MySQL与MongoDB读取性能的简单测试
这是一个附加的测试,也并没有测试得非常完整,但还是很能说明一些问题的。
测试方法:
先在1 – 100, 000, 000这一亿个数中,分别随机取1w, 5w, 10w, 20w, 50w个互不相同的数字,再计算其md5值,并保存。
至于为什么最高只选到50w这个规模,这是因为我在随机生成100w个互不相同的数字的时候,写的脚本跑了一晚上都没有跑出来,估计是我生成的算法写得太烂了。我不想重新再弄了,暂就以50w为上限吧。
在上述带主键插入的两个数据库里,分别以上一步生成的md5源为输入进行查询操作。同样,每查询1000条数据在日志文件中将当前系统时间写入。
测试结果:
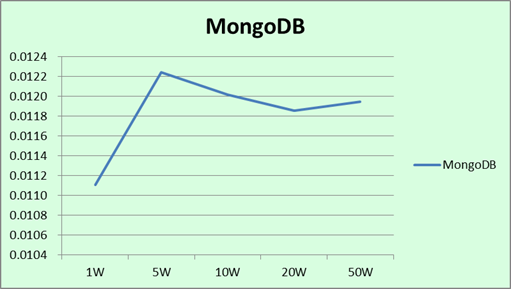
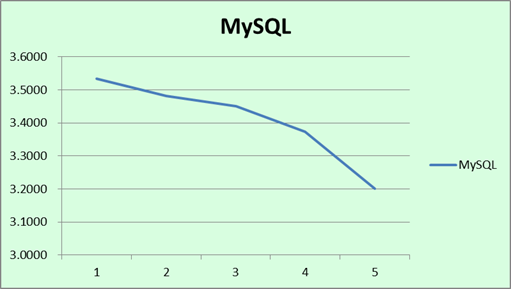
以下三张图的横坐标是每查询1000条数据所需要的时间,单位为s;纵坐标是查询的规模,分为1w, 5w,10w, 20w, 50w五个等级。
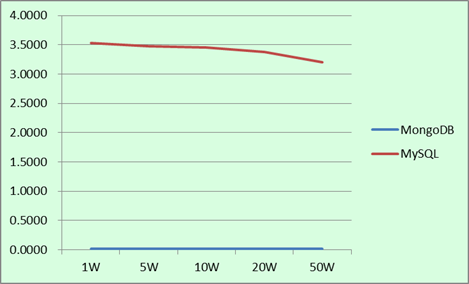
这张图是详细对比,可以看出MySQL与MongoDB之间的差异了吗……
总结:
1. 在读取的数据规模不大时,MongoDB的查询速度真是一骑绝尘,甩开MySQL好远好远。
2. 在查询的数据量逐渐增多的时候,MySQL的查询速度是稳步下降的,而MongoDB的查询速度却有些起伏。
分析:
1. 如果MySQL没有经过查询优化的话,其查询速度就不要跟MongoDB比了。MongoDB可以充分利用系统的内存资源,我们的测试机器内存是64GB的,内存越大MongoDB的查询速度就越快,毕竟磁盘与内存的I/O效率不是一个量级的。
2. 本次实验的查询的数据也是随机生成的,因此所有待查询的数据都存在MongoDB的内存缓存中的概率是很小的。在查询时,MongoDB需要多次将内存中的数据与磁盘进行交互以便查找,因此其查询速率取决于其交互的次数。这样就存在这样一种可能性,尽管待查询的数据数目较多,但这段随机生成的数据被MongoDB以较少的次数从磁盘中取出。因此,其查询的平均速度反而更快一些。这样看来,MongoDB的查询速度波动也处在一个合理的范围内。
3. MySQL的稳定性还是毋庸置疑的。
8. 测试总结
8.1 测试结论
1. 相比较MySQL,MongoDB数据库更适合那些读作业较重的任务模型。MongoDB能充分利用机器的内存资源。如果机器的内存资源丰富的话,MongoDB的查询效率会快很多。
2. 在带”_id”插入数据的时候,MongoDB的插入效率其实并不高。如果想充分利用MongoDB性能的话,推荐采取不带”_id”的插入方式,然后对相关字段作索引来查询。
8.2 测试需要进一步注意的问题
对MongoDB的读取测试考虑不周,虽然这只是一个额外的测试。在这个测试中,随机生成大量待测试的数据很有必要,但生成大量互不相同的数据就没有必要了。正是这一点,把我的读取测试规模限定在了50w条,没能进一步进行分析。
8.3 MongoDB的优势
1. MongoDB适合那些对数据库具体数据格式不明确或者数据库数据格式经常变化的需求模型,而且对开发者十分友好。
2. MongoDB官方就自带一个分布式文件系统,可以很方便地部署到服务器机群上。MongoDB里有一个Shard的概念,就是方便为了服务器分片使用的。每增加一台Shard,MongoDB的插入性能也会以接近倍数的方式增长,磁盘容量也很可以很方便地扩充。
3. MongoDB还自带了对map-reduce运算框架的支持,这也很方便进行数据的统计。
其他方面的优势还在发掘中,本人也是刚刚接触这个不久。
8.4 MongoDB的缺陷
1. 事务关系支持薄弱。这也是所有NoSQL数据库共同的缺陷,不过NoSQL并不是为了事务关系而设计的,具体应用还是很需求。
2. 稳定性有些欠缺,这点从上面的测试便可以看出。
3. MongoDB一方面在方便开发者的同时,另一方面对运维人员却提出了相当多的要求。业界并没有成熟的MongoDB运维经验,MongoDB中数据的存放格式也很随意,等等问题都对运维人员的考验。
(责任编辑:IT)
1.1 MongoDB的简单介绍在当今的数据库市场上,MySQL无疑是占有一席之地的。作为一个开源的关系型数据库,MySQL被大量应用在各大网站后台中,承担着信息存储的重要作用。2009年,甲骨文公司(Oracle)收购Sun公司,MySQL成为Oracle旗下产品。 而MongoDB是一种文件导向的数据库管理系统,属于一种通称为NoSQL的数据库,是10gen公司旗下的开源产品,其内部数据存储的方式与传统的关系型数据有很大差别。 NoSQL的全称是Not Only SQL,也可以理解非关系型的数据库,是一种新型的革命式的数据库设计方式,不过它不是为了取代传统的关系型数据库而被设计的,它们分别代表了不同的数据库设计思路。 虽然MongoDB背后的公司没有Oracle强大,但其目前也正在被应用在各行各业中。MongoDB是目前被应用最广泛的NoSQL数据库产品。 1.2 MongoDB的存储特点在传统的关系型数据库中,数据是以表单为媒介进行存储的,每个表单均拥有纵向的列和横向的行。以MySQL为例,如果用户想以学生的学号为索引,存入其姓名与住址信息时,数据库中存放的信息便如下图所示:
上图表明数据库中存入了5个表项,其记录了学号为10001 – 10005的学生的姓名与住址信息。 如果用户欲把相应的信息重新存入MongoDB数据库,那么数据库中的信息应该为如下所示:
由此可见,相比较MySQL,MongoDB以一种直观文档的方式来完成数据的存储。它很像JavaScript中定义的JSON格式,不过数据在存储的时候MongoDB数据库为文档增加了序列化的操作,最终存进磁盘的其实是一种叫做BSON的格式,即Binary-JSON。 对比两个数据库中数据存储的差异,你可能没有什么特别的直观感受。让我们再看看MongoDB存放的另一组数据:
上述数据表明了学号为10001与10002两名学生的课程分数信息。如果想把同样的数据存入MySQL数据中的话,势必要很费一番功夫。在关系型数据库中,列的数目一般事先固定,各列之间可以由列名来识别。如果想存入以上数据,我们可以采取如下方法:
或者如下这种:
上述两种存储方式无论选哪一种,都不能很直观地呈现两名学生的各科成绩与各学科之间隶属关系,在存储空间上的利用也不尽如意,并且可扩展性也不够好。当然,为了解决这些问题,我们还可以使用多张表单来存储学生的成绩,但这样也会使数据库中的内容更加复杂。 1.2 MongoDB的应用场景在另一方面,对开发者来说,如果是因为业务需求或者是项目初始阶段,而导致数据的具体格式无法明确定义的话,MongoDB的这一鲜明特性就脱颖而出了。相比传统的关系型数据库,它非常容易被扩展,这也为写代码带来了极大的方便。 不过MongoDB对数据之间事务关系支持比较弱,如果业务这一方面要求比较高的话,MongoDB还是并不适合此类型的应用。
另外,MongoDB出现的时机比较晚,还具备一些非常鲜明的特性。比如: 1. 它里面自带了一个名叫GirdFS的分布式文件系统,这就为MongoDB的部署提供了很大便利。而像MySQL这种比较早的数据库,虽然市面上有很多不同的分表部署的方案,但这种终究不如MongoDB直接官方支持来得便捷实在。 2. 另外,MongoDB内部还自建了对map-reduce运算框架的支持,虽然这种支持从功能上看还算是比较简单的,相当于MySQL里GroupBy功能的扩展版,不过也为数据的统计带来了方便。 3. MongoDB在启动后会将数据库中的数据以文件映射的方式加载到内存中。如果内存资源相当丰富的话,这将极大地提高数据库的查询速度,毕竟内存的I/O效率比磁盘高多了。
但是,作为一个新鲜的事务,MongoDB也存在着很多不足。它在为开发人员提供了便利的情况下,却在运维上面临着不少难题,比如: 1. 比起MySQL,MongoDB没有成熟的运维经验,需要不断地探索。 2. MongoDB中的数据存放具有相当的随意性,不具有MySQL在开始就定义好了。对运维人员来说,他们可能不清楚数据库内部数据的数据格式,这也会数据库的运维带来了麻烦。 2. 测试目的MongoDB与MySQL作为两种不同类型的数据库,当其中存放的记录越来越多的时候,其插入效率将会受到怎样的影响,是本次实验所关注的对象。 在这里,我们将本次实验数据库中数据存储的规模定在1亿条。 3. 测试条件机器配置: CPU:Intel(R) Xeon(R) CPU E5-2620 @ 2.00GHz 内存:65954040 KB (关键词:12核CPU,64G内存,给我多好) 操作系统: Linux version 2.6.32_1-8-0-0 (gcc version 4.4.4 20100726 (Red Hat 4.4.4-13) (GCC) ) MongoDB版本: 2.2.3,无任何优化配置,单机测试 MySQL版本: 5.1.49,无任何优化配置,单机测试 测试语言: Python 2.7.1 数据库接口驱动: MongoDB : PyMongo 2.1.1 MySQL: MySQLdb 1.2.3 4. 概念普及在数据库存放的数据中,有一种特殊的键值叫做主键,它用于惟一地标识表中的某一条记录。也就是说,一个表不能有多个主键,并且主键不能为空值。 无论是MongoDB还是MySQL,都存在着主键的定义。 对于MongoDB来说,其主键名叫”_id”,在生成数据的时候,如果用户不主动为其分配一个主键的话,MongoDB会自动为其生成一个随机分配的值。 在MySQL中,主键的指定是在MySQL插入数据时指明PRIMARY KEY来定义的。当没有指定主键的时候,另一种工具 —— 索引,相当于替代了主键的功能。索引可以为空,也可以有重复,另外有一种不允许重复的索引叫惟一索引。如果既没有指定主键也没有指定索引的话,MySQL会自动为数据创建一个。 5. 测试方法1. 制定一个数据库表项的字段模板,以此模板为基准向数据库中插入数据。 2. 在内存中自动生成1亿条待测试数据。数据的格式这里不再一一列出,其里面包含了大概45个字段,其中有一个关键的字段是1 – 100,000,000 的md5值,它们彼此并不相同,其他字段的数据都是写死。每条数据的大小大概有1K。 记住,本次测试的方法是先在内存中生成1亿条数据后,再执行插入操作的。还好测试机器的内存足够大,能够存下如此多的数据。 3. 以如下四种模式向数据库中插入数据,每插1000条数据时,就往一个固定的文件中写入该时刻的时间: a) 在MongoDB中指定_id为1 – 100,000,000 的md5值,将数据插入; b) 在MongoDB中不指定_id值,将1 – 100,000,000 的md5值视为普通的字段插入; c) 在MySQL中以1 – 100,000,000 的md5值为PRIMARY KEY,将数据插入; d) 在MySQL中不指定PRIMARY KEY,将1 – 100,000,000 的md5值视为普通的字段插入。 4. 根据生成的时间文件记录,分析MySQL与MongoDB的插入性能。 5. 进一步,在以上四种数据库的基础上,再分别测试一下数据库的读取性能。
6. 测试过程写好测试脚本之后,运行之,睡一觉起床来看结果就可以了。过程是漫长的,但结果却是可喜可贺的 :D 7. 测试结果7.1 平均每条数据的插入时间先上张图,来点直观感受:
图上数据横坐标是平均每插入1000条数据所需要的时间,单位是秒。记住,是每1000条数据,不是每条数据哦。
总结: 1. 数据库的平均插入速率:MongoDB不指定_id插入 > MySQL不指定主键插入 > MySQL指定主键插入 > MongoDB指定_id插入。 2. MongoDB在指定_id与不指定_id插入时速度相差很大,而MySQL的差别却小很多。
分析: 1. 在指定_id或主键时,两种数据库在插入时要对索引值进行处理,并查找数据库中是否存在相同的键值,这会减慢插入的速率。 2. 在MongoDB中,指定索引插入比不指定慢很多,这是因为,MongoDB里每一条数据的_id值都是唯一的。当在不指定_id插入数据的时候,其_id是系统自动计算生成的。MongoDB通过计算机特征值、时间、进程ID与随机数来确保生成的_id是唯一的。而在指定_id插入时,MongoDB每插一条数据,都需要检查此_id可不可用,当数据库中数据条数太多的时候,这一步的查询开销会拖慢整个数据库的插入速度。 3. MongoDB会充分使用系统内存作为缓存,这是一种非常优秀的特性。我们的测试机的内存有64G,在插入时,MongoDB会尽可能地在内存快写不进去数据之后,再将数据持久化保存到硬盘上。这也是在不指定_id插入的时候,MongoDB的效率遥遥领先的原因。但在指定_id插入时,当数据量一大内存装不下时,MongoDB就需要将磁盘中的信息读取到内存中来查重,这样一来其插入效率反而慢了。 4. MySQL不愧是一种非常稳定的数据库,无论在指定主键还是在不指定主键插入的情况下,其效率都差不了太多。 7.2 插入稳定性分析插入稳定性是指,随着数据量的增大,每插入一定量数据时的插入速率情况。 在本次测试中,我们把这个指标的规模定在10w,即显示的数据是在每插入10w条数据时,在这段时间内每秒钟能插入多少条数据。 先呈现四张图上来:
1. MongoDB指定_id插入:
2. MongoDB不指定_id插入:
3. MySQL指定PRIMARY KEY插入:
4. MySQL不指定PRIMARY KEY插入:
总结: 1. 整体上的插入速度还是和上一回的统计数据类似:MongoDB不指定_id插入 > MySQL不指定主键插入 > MySQL指定主键插入 > MongoDB指定_id插入。 2. 从图中可以看出,在指定主键插入数据的时候,MySQL与MongoDB在不同数据数量级时,每秒插入的数据每隔一段时间就会有一个波动,在图表中显示成为规律的毛刺现象。而在不指定插入数据时,在大多数情况下插入速率都比较平均,但随着数据库中数据的增多,插入的效率在某一时段有瞬间下降,随即又会变稳定。 3. 整体上来看,MongoDB的速率波动比MySQL的严重,方差变化较大。 4. MongoDB在指定_id插入时,当插入的数据变多之后,插入效率有明显地下降。在其他三种的插入测试中,从开始到结束,其插入的速率在大多数的时候都固定在一个标准上。
分析: 1. 毛刺现象是因为,当插入的数据太多的时候,MongoDB需要将内存中的数据写进硬盘,MySQL需要重新分表。这些操作每当数据库中的数据达到一定量级后就会自动进行,因此每隔一段时间就会有一个明显的毛刺。 2. MongoDB毕竟还是新生事物,其稳定性没有已应用多年的MySQL优秀。 3. MongoDB在指定_id插入的时候,其性能的下降还是很厉害的。
7.3 MySQL与MongoDB读取性能的简单测试这是一个附加的测试,也并没有测试得非常完整,但还是很能说明一些问题的。
测试方法: 先在1 – 100, 000, 000这一亿个数中,分别随机取1w, 5w, 10w, 20w, 50w个互不相同的数字,再计算其md5值,并保存。 至于为什么最高只选到50w这个规模,这是因为我在随机生成100w个互不相同的数字的时候,写的脚本跑了一晚上都没有跑出来,估计是我生成的算法写得太烂了。我不想重新再弄了,暂就以50w为上限吧。 在上述带主键插入的两个数据库里,分别以上一步生成的md5源为输入进行查询操作。同样,每查询1000条数据在日志文件中将当前系统时间写入。
测试结果:
以下三张图的横坐标是每查询1000条数据所需要的时间,单位为s;纵坐标是查询的规模,分为1w, 5w,10w, 20w, 50w五个等级。
这张图是详细对比,可以看出MySQL与MongoDB之间的差异了吗……
总结: 1. 在读取的数据规模不大时,MongoDB的查询速度真是一骑绝尘,甩开MySQL好远好远。 2. 在查询的数据量逐渐增多的时候,MySQL的查询速度是稳步下降的,而MongoDB的查询速度却有些起伏。
分析: 1. 如果MySQL没有经过查询优化的话,其查询速度就不要跟MongoDB比了。MongoDB可以充分利用系统的内存资源,我们的测试机器内存是64GB的,内存越大MongoDB的查询速度就越快,毕竟磁盘与内存的I/O效率不是一个量级的。 2. 本次实验的查询的数据也是随机生成的,因此所有待查询的数据都存在MongoDB的内存缓存中的概率是很小的。在查询时,MongoDB需要多次将内存中的数据与磁盘进行交互以便查找,因此其查询速率取决于其交互的次数。这样就存在这样一种可能性,尽管待查询的数据数目较多,但这段随机生成的数据被MongoDB以较少的次数从磁盘中取出。因此,其查询的平均速度反而更快一些。这样看来,MongoDB的查询速度波动也处在一个合理的范围内。 3. MySQL的稳定性还是毋庸置疑的。 8. 测试总结8.1 测试结论1. 相比较MySQL,MongoDB数据库更适合那些读作业较重的任务模型。MongoDB能充分利用机器的内存资源。如果机器的内存资源丰富的话,MongoDB的查询效率会快很多。 2. 在带”_id”插入数据的时候,MongoDB的插入效率其实并不高。如果想充分利用MongoDB性能的话,推荐采取不带”_id”的插入方式,然后对相关字段作索引来查询。 8.2 测试需要进一步注意的问题对MongoDB的读取测试考虑不周,虽然这只是一个额外的测试。在这个测试中,随机生成大量待测试的数据很有必要,但生成大量互不相同的数据就没有必要了。正是这一点,把我的读取测试规模限定在了50w条,没能进一步进行分析。 8.3 MongoDB的优势1. MongoDB适合那些对数据库具体数据格式不明确或者数据库数据格式经常变化的需求模型,而且对开发者十分友好。 2. MongoDB官方就自带一个分布式文件系统,可以很方便地部署到服务器机群上。MongoDB里有一个Shard的概念,就是方便为了服务器分片使用的。每增加一台Shard,MongoDB的插入性能也会以接近倍数的方式增长,磁盘容量也很可以很方便地扩充。 3. MongoDB还自带了对map-reduce运算框架的支持,这也很方便进行数据的统计。
其他方面的优势还在发掘中,本人也是刚刚接触这个不久。 8.4 MongoDB的缺陷1. 事务关系支持薄弱。这也是所有NoSQL数据库共同的缺陷,不过NoSQL并不是为了事务关系而设计的,具体应用还是很需求。 2. 稳定性有些欠缺,这点从上面的测试便可以看出。 3. MongoDB一方面在方便开发者的同时,另一方面对运维人员却提出了相当多的要求。业界并没有成熟的MongoDB运维经验,MongoDB中数据的存放格式也很随意,等等问题都对运维人员的考验。 (责任编辑:IT) |