运维技术面试
时间:2015-12-08 17:12 来源:blog.51cto.com 作者:Cool King
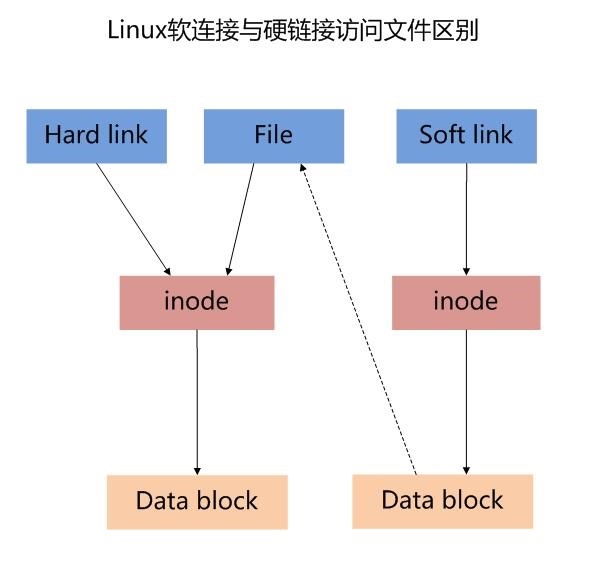
1. 软连接与硬链接区别
2. Linux文件删除原理
3. linux系统的启动过程
-
1. 检查硬件,即计算机硬件是否满足运行基本条件。(如果硬件有问题主板会发出有频率的蜂鸣,启动终止);
-
2. 查找软盘、光盘或硬盘的引导装在程序(指引导记录,即MBR);
-
3. 将引导装在程序(MBR)载入内存,将控制权交给MBR.
-
加载并执行GRUB
-
加载并执行内核以及initrd镜像
-
1. 挂载根文件系统;
-
2. 运行/sbin/init程序,初始化系统环境;
-
根据/etc/inittab设定linux的运行级别
-
根据运行级别,执行对应级别的程序
4. top命令右上角的load average的值是什么意思,高于多少代表负载有问题
-
“有多少核心即为有多少负荷”法则: 在多核处理中,你的系统均值不应该高于处理器核心的总数量。
-
“核心的核心”法则: 核心分布在分别几个单个物理处理中并不重要,其实两颗四核的处理器 等于 四个双核处理器 等于 八个单处理器。所以,它应该有八个处理器内核。
5. 查看网络I/O命令
dstat [-afv] [options..] [delay [count]]
使用 dstat -h查看全部选项,这里不逐一列举,下面简单介绍下常用选项
常用选项如下:
# 直接跟数字,表示#秒收集一次数据,默认为一秒;dstat 5表示5秒更新一次
-c,--cpu 统计CPU状态,包括 user, system, idle(空闲等待时间百分比), wait(等待磁盘IO), hardware interrupt(硬件中断), software interrupt(软件中断)等;
-d, --disk 统计磁盘读写状态
-D total,sda 统计指定磁盘或汇总信息
-l, --load 统计系统负载情况,包括1分钟、5分钟、15分钟平均值
-m, --mem 统计系统物理内存使用情况,包括used, buffers, cache, free
-s, --swap 统计swap已使用和剩余量
-n, --net 统计网络使用情况,包括接收和发送数据
-N eth1,total 统计eth1接口汇总流量
-r, --io 统计I/O请求,包括读写请求
-p, --proc 统计进程信息,包括runnable、uninterruptible、new
-y, --sys 统计系统信息,包括中断、上下文切换
-t 显示统计时时间,对分析历史数据非常有用
--fs 统计文件打开数和inodes数
1
dstat -N lo,eth0 100 5
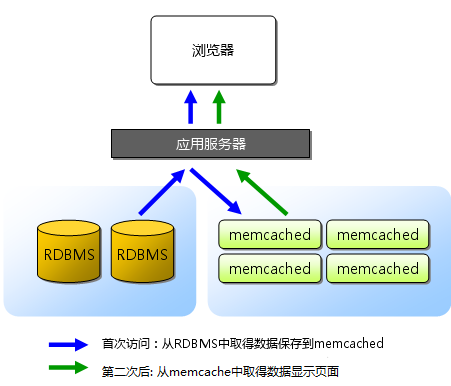
6. memcache运行原理
7. 当一个网站访问慢时,你怎么去优化 ###
8. mysql主从不同步怎么解决
-
在master端执行:
mysql> flush logs;
mysql> show master status;
PS:记下File、Position的值。
-
在slave端执行:
mysql> stop slave;
mysql> CHANGE MASTER TO MASTER_LOG_FILE='bin-log.000002',MASTER_LOG_POS=107;
mysql> start slave;
mysql> show slave status
-
跳过指定数量的事务:
mysql>slave stop;
mysql>SET GLOBAL SQL_SLAVE_SKIP_COUNTER = 1 #跳过一个事务
mysql>slave start
-
修改mysql的配置文件,通过slave_skip_errors参数来跳所有错误或指定类型的错误
vi /etc/my.cnf
[mysqld]
slave-skip-errors=1062,1053,1146 #跳过指定error no类型的错误
slave-skip-errors=all #跳过所有错误
9. 进程和线程的区别
-
进程(英语:process),是计算机中已运行程序的实体。进程是程序的基本执行实体,进程本身不是基本运行单位,而是线程的容器
-
线程(英语:thread)是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
10. 常用的RAID原理
11. 有没有做过性能调优
12. 请求一个网站的过程
13. lvs/dr调度的过程
14. 我想查看WEB日志中访问TOP 10的IP有哪些怎么查看
cat logfile |cut -d ' ' -f 5 |sort |uniq -c | sort -nr | head -n 10 |less
15. CDN的主要原理
16. 跨服务器同步文件
ls /tmp/test | grep ".*\.jpg\|.*\.png"
find /tmp/test -type f -regex '.*\.jpg\|.*\.png'
-
xargs + scp命令
ls /tmp/test | grep ".*\.jpg\|.*\.png" | xargs -n1 -I {} scp {} root@192.168.1.97:/tmp
find /tmp/test -type f -regex '.*\.jpg\|.*\.png' | xargs -n1 -I {} scp {} root@192.168.1.97:/tmp
使用xargs接收管道标准输入,然后执行远程拷贝命令.
-
find命令 + scp命令
find /tmp/test -type f -regex '.*\.jpg\|.*\.png' -exec scp {} root@192.168.1.97:/tmp \;
也可以配合xargs命令完成
find /tmp/test -type f -regex '.*\.jpg\|.*\.png' | xargs -n1 -I {} scp {} root@192.168.1.97:/tmp
这两条效果一样的,执行过程都是建立子进程逐个文件scp.比较坑的是, 你要使用scp文件的话,没有秘钥认证远程主机的话,每个文件都要输一次密码...
-
rsync同步 普通rsync同步:
find /tmp/test -type f -regex '.*\.jpg\|.*\.png' | xargs -n1 -I {} rsync {} root@192.168.1.97:/tmp
上传rsync server同步(需要远程主机已搭建rsync服务器):
find /tmp -type f -regex '.*\.jpg\|.*\.png'| xargs -n1 -I {} rsync -avzP {} wys@192.168.1.98::wys
以上的两条和scp一样需要逐个密码认证,而rsync有--password-file指定密码文件(注意密码文件权限必须600,否则会报错)来戴我们认证密码,像这样:
find /tmp -type f -regex '.*\.jpg\|.*\.png'| xargs -n1 -I {} rsync -avzP {} --password-file=/tmp/wys.password wys@192.168.1.98::wys
同步的命令或者服务也有很多,但是像这种临时性的不是很大量的使用我觉得最多rsync就够了.
...-I {} CMD {} XXX...
17. mysql增删改查基础问题(笔试基础)
-
增
INSERT INTO 表名称 VALUES(值1,值2,...); #按列的顺序将值依次赋给对应列的对象
INSERT INTO 表名称(列1,列2) VALUES(值1,值2); #对应列插入相应值
-
删
DELETE FROM 表名称 WHERE 列 运算符 值; # 例: DELETE FROM tab WHERE name=job; 匹配到name列值为job的一条记录,删除它
DELETE * FROM 表名称; #清空表
-
改
UPDATE 表名称 SET 列名称=新值 WHERE 列=值; 例: UPDATE tab SET name=eason WHERE id=3; 匹配到id列值为3的记录,修改该记录name的值为eason
-
查
SELECT 列名称1,列名称2... FROM 表名称; # 指定列查询
SELECT * FROM 表名称; # 查询表所有内容
SELECT 列名称 FROM 表名称 WHERE 列 运算符 值; # 例: SELECT name FROM tab WHERE id<10; 匹配到tab的id列小于10的记录, 查看这些记录name列的值
SELECT DISTINCT 列名称 FROM 表名称; #删除返回结果的重复项
SELECT * FROM 表名称 ORDER BY 列名称; #按照某一列排序(从小到大顺序)
SELECT * FROM 表名称 ORDER BY 列名称 DESC; #按照某一列排序(倒序)
18. 服务器更换主板后linux无法识别网卡
>#mv /etc/udev/rules.d/70-persistent-net.rules /etc/udev/rules.d/70-persistent-net.rules.bak
>#reboot #重启后会生成新的缓存文件
(责任编辑:IT)
1. 软连接与硬链接区别
2. Linux文件删除原理3. linux系统的启动过程
4. top命令右上角的load average的值是什么意思,高于多少代表负载有问题
5. 查看网络I/O命令dstat [-afv] [options..] [delay [count]] 使用 dstat -h查看全部选项,这里不逐一列举,下面简单介绍下常用选项 常用选项如下: # 直接跟数字,表示#秒收集一次数据,默认为一秒;dstat 5表示5秒更新一次 -c,--cpu 统计CPU状态,包括 user, system, idle(空闲等待时间百分比), wait(等待磁盘IO), hardware interrupt(硬件中断), software interrupt(软件中断)等; -d, --disk 统计磁盘读写状态 -D total,sda 统计指定磁盘或汇总信息 -l, --load 统计系统负载情况,包括1分钟、5分钟、15分钟平均值 -m, --mem 统计系统物理内存使用情况,包括used, buffers, cache, free -s, --swap 统计swap已使用和剩余量 -n, --net 统计网络使用情况,包括接收和发送数据 -N eth1,total 统计eth1接口汇总流量 -r, --io 统计I/O请求,包括读写请求 -p, --proc 统计进程信息,包括runnable、uninterruptible、new -y, --sys 统计系统信息,包括中断、上下文切换 -t 显示统计时时间,对分析历史数据非常有用 --fs 统计文件打开数和inodes数
6. memcache运行原理7. 当一个网站访问慢时,你怎么去优化 ###8. mysql主从不同步怎么解决
9. 进程和线程的区别
10. 常用的RAID原理11. 有没有做过性能调优12. 请求一个网站的过程13. lvs/dr调度的过程14. 我想查看WEB日志中访问TOP 10的IP有哪些怎么查看
15. CDN的主要原理16. 跨服务器同步文件
17. mysql增删改查基础问题(笔试基础)
18. 服务器更换主板后linux无法识别网卡>#mv /etc/udev/rules.d/70-persistent-net.rules /etc/udev/rules.d/70-persistent-net.rules.bak >#reboot #重启后会生成新的缓存文件 (责任编辑:IT) |