linux设备模型之字符设备
时间:2016-02-22 12:55 来源:linux.it.net.cn 作者:IT
Linux设备模型之字符设备
以ldd中scull为例来分析一下设备模型的字符设备。
对scull做了一些修改,一方面是内核版本不同引起的一些定义上的修改,另一方面是去除了scull中包括的scullpipe等设备。
为使得我们对字符设备更清晰,我们不分析scull的具体实现,简单理解成内存字符设备。
希望结合文件系统的相关概念,从系统调用深入文件的file_operation,见证linux的“一切都是文件”。
我也阅读过其他人的blog,对于有点观点不是很认同,个人认为sysfs是基于kobject这个基础对象的文件系统,这个文件系统是基于内存的。设计这个文件系统的目的是电源管理、热插拔设备等等的需要(具体见ldd3--14章)。而/dev这个目录,我觉得是devtmpfs挂载的,这也是一个基于内存的文件系统。正是这是文件系统,我们的设备才在vfs统一视图下被当作文件处理。所以我们才可以对设备进行read write ioctl等等。
先看下scull设备的注册:
module_init(scull_init_module);int scull_init_module(void)
intscull_init_module(void)
{
intresult, i;
dev_tdev = 0;
/*
*Get a range of minor numbers to work with, asking for a dynamic
*major unless directed otherwise at load time.
*/
if(scull_major) {
dev= MKDEV(scull_major, scull_minor);
result= register_chrdev_region(dev, scull_nr_devs, "scull");
}else {
result= alloc_chrdev_region(&dev, scull_minor, scull_nr_devs,
"scull");
scull_major= MAJOR(dev);
}
if(result < 0) {
printk(KERN_WARNING"scull: can't get major %d\n", scull_major);
returnresult;
}
/*
* allocate the devices -- we can't have them static, as the number
* can be specified at load time
*/
scull_devices= kmalloc(scull_nr_devs * sizeof(struct scull_dev), GFP_KERNEL);
if(!scull_devices) {
result= -ENOMEM;
gotofail; /* Make this more graceful */
}
memset(scull_devices,0, scull_nr_devs * sizeof(struct scull_dev));
/*Initialize each device. */
for(i = 0; i < scull_nr_devs; i++) {
scull_devices[i].quantum= scull_quantum;
scull_devices[i].qset= scull_qset;
init_MUTEX(&scull_devices[i].sem);
scull_setup_cdev(&scull_devices[i],i);
}
/*At this point call the init function for any friend device */
dev= MKDEV(scull_major, scull_minor + scull_nr_devs);
dev+= scull_p_init(dev);
dev+= scull_access_init(dev);
#ifdefSCULL_DEBUG /* only when debugging */
scull_create_proc();
#endif
return0; /* succeed */
fail:
scull_cleanup_module();
returnresult;
}
Init的过程我们分下面几个部分分析:
-
设备号的分配:
if (scull_major) {
dev = MKDEV(scull_major,scull_minor);
result =register_chrdev_region(dev, scull_nr_devs, "scull");
} else {
result =alloc_chrdev_region(&dev, scull_minor, scull_nr_devs,
"scull");
scull_major = MAJOR(dev);
}
if (result < 0) {
printk(KERN_WARNING "scull:can't get major %d\n", scull_major);
return result;
}
设备号有两种方法:一是事先知道用哪个设备编号,则可以用register_chrdev_region,而是动态分配,交给alloc_chrdev_region函数处理。
在debug的过程中,dev的参数是263192576,转换成16进制就是FB00000;所以主设备号就是0xfb=251;
-
设备的内存分配:
scull_devices =kmalloc(scull_nr_devs * sizeof(struct scull_dev), GFP_KERNEL);
if (!scull_devices) {
result = -ENOMEM;
goto fail; /* Make this moregraceful */
}
memset(scull_devices,0, scull_nr_devs * sizeof(struct scull_dev));
这个没什么好讲的了。。。。
-
初始化每一个设备:
/* Initialize each device. */
for (i = 0; i <scull_nr_devs; i++) {
scull_devices[i].quantum =scull_quantum;
scull_devices[i].qset =scull_qset;
init_MUTEX(&scull_devices[i].sem);
scull_setup_cdev(&scull_devices[i],i);
}
初始化4个scull设备,scull_devices内部的初始化我们不管了,只看如何建立字符设备。
-
其实可以没有这个第四步,因为4是
#ifdef SCULL_DEBUG /* only whendebugging */
scull_create_proc();
#endif
这里是通过proc做debug用的,了解一下就行。
我们回到上面第3步的scull_setup_cdev(&scull_devices[i],i);
取i为0分析,
staticvoid scull_setup_cdev(struct scull_dev *dev, int index)
{
interr, devno = MKDEV(scull_major, scull_minor + index);
cdev_init(&dev->cdev,&scull_fops);
dev->cdev.owner= THIS_MODULE;
dev->cdev.ops= &scull_fops;
err= cdev_add (&dev->cdev, devno, 1);
/*Fail gracefully if need be */
if(err)
printk(KERN_NOTICE"Error %d adding scull%d", err, index);
}
也分成多步分析:
-
生成设备号:
利用刚才自动分配的主设备号和从0开始定义的次设备号,用MKDEV宏生成设备号。
比如说有N个同样的设备,次设备号我们一般取0—N-1.
-
初始化scull_dev结构体中内嵌的cdev结构体:
cdev_init(&dev->cdev,&scull_fops);
scull_fops的定义如下:
structfile_operations scull_fops = {
.owner= THIS_MODULE,
.llseek= scull_llseek,
.read= scull_read,
.write= scull_write,
.ioctl= scull_ioctl,
.open= scull_open,
.release= scull_release,
};
因为linux号称一切皆是文件,这个文件操作结构体包含着scull设备文件的open、read、write等操作。这个结构体很重要,后面我们还要继续邂逅他。
先看下cdev结构体:
structcdev {
structkobject kobj;
structmodule *owner;
conststruct file_operations *ops;
structlist_head list;
dev_tdev;
unsignedint count;
};
初始化cdev的list;
初始化cdev内嵌的kobj
将cdev的ops(file_operations)设置为scull_fops。
dev->cdev.owner= THIS_MODULE;
dev->cdev.ops= &scull_fops;
-
向系统添加字符设备
cdev_add(&dev->cdev, devno, 1);
intcdev_add(struct cdev *p, dev_t dev, unsigned count)
{
p->dev= dev;
p->count= count;
returnkobj_map(cdev_map, dev, count, NULL, exact_match, exact_lock, p);
}
一眼就看出这个cdev_map有点意思,不得不先看看cdev_map是怎么来的?
staticstruct kobj_map *cdev_map;
kobj_map结构体如下:
structkobj_map {
structprobe {
structprobe *next;
dev_tdev;
unsignedlong range;
structmodule *owner;
kobj_probe_t*get;
int(*lock)(dev_t, void *);
void*data;
}*probes[255];
structmutex *lock;
};
这个kobj_map结构体就是包含了一个大小为255的结构体数组和一个锁。
这个cdev_map是在chrdev_init函数中初始化的,其实不知不觉我们已经调到了fs目录下的char_dev.c,这个放在fs目录下,从某个角度也说明了字符设备其实也是文件。
start_kernel(void)vfs_caches_init chrdev_init();
vfs就是linux文件系统的一个关键层,没有vfs,linux就不能支持如此多类别的文件系统。有人解释vfs是虚拟文件系统,我倒觉得将s理解为switch更为恰当些。
稍微扯远了,再回到chrdev_init中来:
void__init chrdev_init(void)
{
cdev_map= kobj_map_init(base_probe, &chrdevs_lock);
bdi_init(&directly_mappable_cdev_bdi);
}
structkobj_map *kobj_map_init(kobj_probe_t *base_probe, struct mutex *lock)
{
structkobj_map *p = kmalloc(sizeof(struct kobj_map), GFP_KERNEL);
structprobe *base = kzalloc(sizeof(*base), GFP_KERNEL);
inti;
if((p == NULL) || (base == NULL)) {
kfree(p);
kfree(base);
returnNULL;
}
base->dev= 1;
base->range= ~0;
base->get= base_probe;
for(i = 0; i < 255; i++)
p->probes[i]= base;
p->lock= lock;
returnp;
}
给structkobj_map *p申请内存,在给structprobe*base申请内存。这个probe结构体就是我们在kobj_map中包的结构体数组的结构体,取名为base,后面我们用base来初始化255中的每一个结构体。
Bdi_init函数暂且不管它了。。。
再回到cdev_add中的kobj_map(cdev_map,dev, count, NULL, exact_match, exact_lock, p);
intkobj_map(struct kobj_map *domain, dev_t dev, unsigned long range,
struct module *module, kobj_probe_t *probe,
int (*lock)(dev_t, void *), void *data)
{
unsignedn = MAJOR(dev + range - 1) - MAJOR(dev) + 1;
unsignedindex = MAJOR(dev);
unsignedi;
structprobe *p;
if(n > 255)
n= 255;
p= kmalloc(sizeof(struct probe) * n, GFP_KERNEL);
if(p == NULL)
return-ENOMEM;
for(i = 0; i < n; i++, p++) {
p->owner= module;
p->get= probe;
p->lock= lock;
p->dev= dev;
p->range= range;
p->data= data;
}
mutex_lock(domain->lock);
for(i = 0, p -= n; i < n; i++, p++, index++) {
structprobe **s = &domain->probes[index % 255];
while(*s && (*s)->range < range)
s= &(*s)->next;
p->next= *s;
*s= p;
}
mutex_unlock(domain->lock);
return0;
}
下面用mknod来创建一个字符设备。
先cat/proc/devices如下:
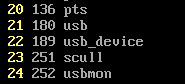
得到主设备号为251,然后mknod /dev/scull0 c 251 0
系统调用关系如下:
#0 sys_mknodat (dfd=-100, filename=0xbfc66907 "/dev/scull0",mode=8630,
dev=64256)at fs/namei.c:2019
#1 0xc029fd35 in sys_mknod (filename=0xbfc66907 "/dev/scull0",mode=8630,
dev=64256)at fs/namei.c:2068
#2 0xc0104657 in ?? () at arch/x86/kernel/entry_32.S:457
在fs/namei.c中的
SYSCALL_DEFINE4(mknodat,int, dfd, const char __user *, filename, int, mode,
unsigned,dev)
断点显示如下:
Breakpoint2, sys_mknodat (dfd=-100, filename=0xbfc66907 "/dev/scull0",
mode=8630,dev=64256) at fs/namei.c:2019
sys_mknodat函数有一段如下:
switch(mode & S_IFMT) {
case0: case S_IFREG:
error= vfs_create(nd.path.dentry->d_inode,dentry,mode,&nd);
break;
caseS_IFCHR: case S_IFBLK:
error= vfs_mknod(nd.path.dentry->d_inode,dentry,mode,
new_decode_dev(dev));
break;
caseS_IFIFO: case S_IFSOCK:
error= vfs_mknod(nd.path.dentry->d_inode,dentry,mode,0);
break;
}
可以看出,我们可以用mknod来创建普通文件,字符设备文件,块设备文件,FIFO和socket文件。
这里只关心字符设备文件:
error= vfs_mknod(nd.path.dentry->d_inode,dentry,mode,
new_decode_dev(dev));
先看下new_decode_dev(dev)做了什么,其中dev的值是64256
staticinline dev_t new_decode_dev(u32 dev)
{
unsignedmajor = (dev & 0xfff00) >> 8;
unsignedminor = (dev & 0xff) | ((dev >> 12) & 0xfff00);
returnMKDEV(major, minor);
}
自己算一下major=0xfb=251minor=0
返回设备号0xFB00000.
接下来看vfs_mknod函数,这个和文件系统紧密相关(inode和dentry的概念)。
vfs_mknod(dir=0xdf910228, dentry=0xdf1ddf68, mode=8630, dev=263192576)
atfs/namei.c:1969
这个函数关键在于调用dir这个inode下的i_op中的mknod函数:
error= dir->i_op->mknod(dir, dentry, mode, dev);
其实这个用的是
shmem_mknod(dir=0xdf910228, dentry=0xdf1ddf68, mode=8630, dev=263192576)
用df–hT:
Filesystem Type Size Used Avail Use% Mounted on
/dev/sda1 ext4 19G 17G 1.6G 92% /
none devtmpfs 245M 248K 245M 1% /dev
none tmpfs 249M 252K 249M 1% /dev/shm
none tmpfs 249M 308K 249M 1% /var/run
none tmpfs 249M 0 249M 0% /var/lock
none tmpfs 249M 0 249M 0% /lib/init/rw
.host:/ vmhgfs 74G 48G 26G 66% /mnt/hgfs
可以看到一个名为devtmpfs的文件系统挂载在/dev目录上。
Devtmpfs是个什么文件系统,我们从drivers/base下的Kconfig文件先看个大概:
configDEVTMPFS
bool"Maintain a devtmpfs filesystem to mount at /dev"
dependson HOTPLUG && SHMEM && TMPFS
help
Thiscreates a tmpfs filesystem instance early at bootup.
Inthis filesystem, the kernel driver core maintains device
nodeswith their default names and permissions for all
registereddevices with an assigned major/minor number.
Userspacecan modify the filesystem content as needed, add
symlinks,and apply needed permissions.
Itprovides a fully functional /dev directory, where usually
udevruns on top, managing permissions and adding meaningful
symlinks.
Invery limited environments, it may provide a sufficient
functional/dev without any further help. It also allows simple
rescuesystems, and reliably handles dynamic major/minor numbers.
猜测/dev和上面的shmem_mknod有关系。
利用kgdb仔细看一下:
(gdb)p *dentry
$16= {d_count = {counter = 1}, d_flags = 0, d_lock = {{rlock = {raw_lock= {
slock= 257}}}}, d_mounted = 0,d_inode = 0x0,d_hash = {next = 0x0,
pprev= 0xc141119c},d_parent = 0xdf4012a8,d_name = {hash = 3558180945,
len= 6, name = 0xdf1ddfc4 "scull0"}, d_lru = {next =0xdf1ddf94,
prev= 0xdf1ddf94}, d_u = {d_child = {next = 0xdf17682c,
prev= 0xdf4012e4}, d_rcu = {next = 0xdf17682c, func = 0xdf4012e4}},
d_subdirs= {next = 0xdf1ddfa4, prev = 0xdf1ddfa4}, d_alias = {
next= 0xdf1ddfac, prev = 0xdf1ddfac}, d_time = 2451638784,
d_op= 0xc07ae990,d_sb = 0xdf8f6e00,d_fsdata = 0x0,
d_iname="scull0\000\066\000\000\f`\233\000\000\f\253\000\000\000\000\006\004u\000\000\000\006\004F\233\000\000(\001\253\000\000\000\206"}
先看下d_parent这个dentry的内容:
(gdb)p *(struct dentry *)0xdf4012a8
$21= {d_count = {counter = 210}, d_flags = 16, d_lock = {{rlock = {
raw_lock= {slock = 1542}}}}, d_mounted = 0, d_inode = 0xdf910228,
d_hash= {next = 0x0, pprev = 0x0}, d_parent = 0xdf4012a8, d_name = {
hash= 0, len = 1, name = 0xdf401304 "/"}, d_lru = {next =0xdf4012d4,
prev= 0xdf4012d4}, d_u = {d_child = {next = 0xdf4012dc,
prev= 0xdf4012dc}, d_rcu = {next = 0xdf4012dc, func = 0xdf4012dc}},
d_subdirs= {next = 0xdf1ddf9c, prev = 0xdf40171c}, d_alias = {
next= 0xdf910240, prev = 0xdf910240}, d_time = 0, d_op = 0x0,
d_sb= 0xdf8f6e00, d_fsdata = 0x0, d_iname = "/", '\000'<repeats 38 times>}
我们看到了”/”,但如果scull0在/目录下,那就有问题了,因为路径应该是/dev/dev/scull0,如果对文件系统有些了解,就知道这里应该挂载了一个文件系统。
这个文件系统就是:
staticstruct file_system_type dev_fs_type = {
.name= "devtmpfs",
.get_sb= dev_get_sb,
.kill_sb= kill_litter_super,
};
这个”/”代表的是dev_fs_type文件系统的根。他是挂载在我们的根文件系统的目录下的。
再看一下super_block:
(gdb)p *dentry->d_sb
$20= {s_list = {next = 0xdf8f7800, prev = 0xdf8f6c00}, s_dev = 5,
s_dirt= 0 '\000', s_blocksize_bits = 12 '\f', s_blocksize = 4096,
s_maxbytes= 2201170804736, s_type = 0xc09f20a0, s_op = 0xc07a7c40,
dq_op= 0xc07affe0, s_qcop = 0xc07b0000, s_export_op = 0xc07a7f8c,
s_flags= 1078001664, s_magic = 16914836, s_root = 0xdf4012a8, s_umount = {
count= 0, wait_lock = {{rlock = {raw_lock = {slock = 0}}}}, wait_list = {
next= 0xdf8f6e44, prev = 0xdf8f6e44}}, s_lock = {count = {counter = 1},
wait_lock= {{rlock = {raw_lock = {slock = 0}}}}, wait_list = {
next= 0xdf8f6e54, prev = 0xdf8f6e54}, owner = 0x0},
s_count= 1073741824, s_need_sync = 0, s_active = {counter = 2},
s_security= 0x0, s_xattr = 0xc09d6650, s_inodes = {next = 0xdbd975d0,
prev= 0xdf910238}, s_anon = {first = 0x0}, s_files = {next = 0xdafe3700,
prev= 0xd2744100}, s_dentry_lru = {next = 0xdf8f6e88, prev = 0xdf8f6e88},
s_nr_dentry_unused= 0, s_bdev = 0x0, s_bdi = 0xc09d6a80, s_mtd = 0x0,
s_instances= {next = 0xc09f20b8, prev = 0xc09f20b8}, s_dquot = {flags = 0,
dqio_mutex= {count = {counter = 1}, wait_lock = {{rlock = {raw_lock = {
slock= 0}}}}, wait_list = {next = 0xdf8f6eb4,
prev= 0xdf8f6eb4}, owner = 0x0}, dqonoff_mutex = {count = {
counter= 1}, wait_lock = {{rlock = {raw_lock = {slock = 0}}}},
wait_list= {next = 0xdf8f6ec8, prev = 0xdf8f6ec8}, owner = 0x0},
dqptr_sem= {count = 0, wait_lock = {{rlock = {raw_lock = {slock = 0}}}},
wait_list= {next = 0xdf8f6edc, prev = 0xdf8f6edc}}, files = {0x0, 0x0},
info= {{dqi_format = 0x0, dqi_fmt_id = 0, dqi_dirty_list = {next = 0x0,
---Type<return> to continue, or q <return> to quit---
prev= 0x0}, dqi_flags = 0, dqi_bgrace = 0, dqi_igrace = 0,
dqi_maxblimit= 0, dqi_maxilimit = 0, dqi_priv = 0x0}, {
dqi_format= 0x0, dqi_fmt_id = 0, dqi_dirty_list = {next = 0x0,
prev= 0x0}, dqi_flags = 0, dqi_bgrace = 0, dqi_igrace = 0,
dqi_maxblimit= 0, dqi_maxilimit = 0, dqi_priv = 0x0}}, ops = {0x0,
0x0}},s_frozen = 0, s_wait_unfrozen = {lock = {{rlock = {raw_lock = {
slock= 0}}}}, task_list = {next = 0xdf8f6f5c,
prev= 0xdf8f6f5c}}, s_id = "devtmpfs",'\000' <repeats 23 times>,
s_fs_info= 0xdf8026c0, s_mode = 0, s_time_gran = 1, s_vfs_rename_mutex = {
count= {counter = 1}, wait_lock = {{rlock = {raw_lock = {slock = 0}}}},
wait_list= {next = 0xdf8f6f98, prev = 0xdf8f6f98}, owner = 0x0},
s_subtype= 0x0, s_options = 0x0}
从这里也可以看到这里是挂载在/dev的一个内存文件系统:devtmpfs
为什么vfs_mknod会跳到shmem_mknod(dir->i_op->mknod(dir,dentry, mode, dev);)
因为devtmpfs在mount的时候
staticint dev_get_sb(struct file_system_type *fs_type, int flags,
const char *dev_name, void *data, struct vfsmount *mnt)
{
returnget_sb_single(fs_type, flags, data, shmem_fill_super, mnt);
}
是shmem_fill_super函数来填充devtmpfs的super_block的。
那么在shmem_get_inode中
caseS_IFDIR:
inc_nlink(inode);
/*Some things misbehave if size == 0 on a directory */
inode->i_size= 2 * BOGO_DIRENT_SIZE;
inode->i_op= &shmem_dir_inode_operations;
inode->i_fop= &simple_dir_operations;
由于mountpoint是dev这个目录,所以dev对应的inode的i_op就是shmem_dir_inode_operations。
所以:
在vfs_mknod(dir=0xdf910228, dentry=0xdf1ddf68, mode=8630, dev=263192576)
atfs/namei.c:1969
中,
error= dir->i_op->mknod(dir, dentry, mode, dev);
就调到了:
staticconst struct inode_operations shmem_dir_inode_operations = {
#ifdefCONFIG_TMPFS
.create =shmem_create,
.lookup =simple_lookup,
.link =shmem_link,
.unlink =shmem_unlink,
.symlink =shmem_symlink,
.mkdir =shmem_mkdir,
.rmdir =shmem_rmdir,
.mknod =shmem_mknod,
.rename =shmem_rename,
#endif
#ifdefCONFIG_TMPFS_POSIX_ACL
.setattr =shmem_notify_change,
.setxattr =generic_setxattr,
.getxattr =generic_getxattr,
.listxattr =generic_listxattr,
.removexattr =generic_removexattr,
.check_acl =generic_check_acl,
#endif
};
中的shmem_mknod。
Devtmpfs暂且不谈了,还是直接看下shmem_mknod吧
在shmem_mknod中,通过shmem_get_inode含糊来创建新的inode。
inode= shmem_get_inode(dir->i_sb, mode, dev, VM_NORESERVE);
shmem_get_inode(sb=0xdf8f6e00, mode=8630, dev=263192576, flags=2097152)
在shmem_get_inode中,这个函数首先用new_inode(sb)函数生成一个新的inode,在各种文件系统的xx_get_inode函数中这都是第一步;第二步就是设置inode这个大结构体的各个成员了,这里我们主要看i_op和i_fop。
在
switch(mode & S_IFMT) {
default:
inode->i_op= &shmem_special_inode_operations;
init_special_inode(inode,mode, dev);
中,我们走到了default:
I_op设置为shmem_special_inode_operations
而init_special_inode函数是在fs目录下的inode.c中,
在这个函数中,根据mode进行了细分,看是不是chr,blk,fifio和sock。
如果是chr字符文件,那么
if(S_ISCHR(mode)) {
inode->i_fop= &def_chr_fops;
inode->i_rdev= rdev;
}
这里i_fop赋为def_chr_fops
conststruct file_operations def_chr_fops = {
.open= chrdev_open,
};
i_rdev设为rdev,也就是设备号0xFB00000;
在ldd3一书中,在第3章介绍了一些重要的结构体,包括了inode结构。
书中有这么一段话:
Inode结构包含大量关于文件的信息。作为一个通用的规则,这个结构只有两个成员对于编写驱动代码有用:
Dev_ti_rdev;
对于代表设备文件的节点,这个成员包含实际的设备编号。
Structcdev *i_cdev;
Structcdev是内核的内部结构,代表字符设备;这个成员包含一个指针,指向这个结构,当节点
这个时候inode的i_rdev已正确赋值,而i_cdev暂且未指向正确的字符设备。
再回到shmem_mknod来,既然inode出来了,那就要与dentry建立关系。
在shmem_mknod(structinode *dir, struct dentry *dentry, int mode, dev_tdev)中的dentry我们前面已经看过了,就是scull0的目录项。
d_instantiate(dentry,inode); /* d_instantiate - fill in inode information for a dentry*/
mknod到这里走到末尾了,这个时候可以在/dev下看到scull0这个字符设备节点。
既然字符设备成了一个文件,那要使一个文件能够读写,那么文件首先要被open。
下面我们open/dev/scull0,看看open系统调用到底层是如何一步一步深入的。
Sys_opendo_sys_open do_filp_open do_lastfinish_opennameidata_to_filp __dentry_open chrdev_open
在__dentry_open函数是如何调用chrdev_open的?
__dentry_open的函数原型是:
staticstruct file *__dentry_open(struct dentry *dentry, struct vfsmount*mnt,
structfile *f,
int(*open)(struct inode *, struct file *),
conststruct cred *cred)
1、inode= dentry->d_inode;
2、f->f_op= fops_get(inode->i_fop);这里inode的i_fop指针就是def_chr_fops
3、if(!open && f->f_op)
open= f->f_op->open;这是open就指向了def_chr_fops中的chrdev_open
4、 if(open) {
error= open(inode, f);
if(error)
gotocleanup_all;
}
这里才调用了chrdev_open函数。
下面仔细分析chrdev_open函数:
给出chrdev_open函数的定义:
staticint chrdev_open(struct inode *inode, struct file *filp)
{
structcdev *p;
structcdev *new = NULL;
intret = 0;
spin_lock(&cdev_lock);
p= inode->i_cdev; ------1-------
if(!p) { -------2-------
structkobject *kobj;
intidx;
spin_unlock(&cdev_lock);
kobj= kobj_lookup(cdev_map, inode->i_rdev, &idx);
if(!kobj)
return-ENXIO;
new= container_of(kobj, struct cdev, kobj);
spin_lock(&cdev_lock);
/*Check i_cdev again in case somebody beat us to it while
we dropped the lock. */
p= inode->i_cdev;
if(!p) {
inode->i_cdev= p = new;
list_add(&inode->i_devices,&p->list);
new= NULL;
}else if (!cdev_get(p))
ret= -ENXIO;
}else if (!cdev_get(p))
ret= -ENXIO;
spin_unlock(&cdev_lock);
cdev_put(new);
if(ret)
returnret;
ret= -ENXIO;
filp->f_op= fops_get(p->ops);
if(!filp->f_op)
gotoout_cdev_put;
if(filp->f_op->open) {
ret= filp->f_op->open(inode,filp);
if(ret)
gotoout_cdev_put;
}
return0;
out_cdev_put:
cdev_put(p);
returnret;
}
-
利用inode结构体中的i_cdev获取cdev的指针,因为前面我们看到inode的i_cdev是没关联的,所以i_cdev的值是0x0;
-
因为第一步,所以这里的if为真,
2a、首先根据前面初始化和map过的cdev_map来根据inode->i_rdev(设备号)来lookup正确的kobj。
kobj= kobj_lookup(cdev_map, inode->i_rdev, &idx);
2b、利用container_of宏获取cdev
new= container_of(kobj, struct cdev, kobj);
这个时候new就是scull_dev中内嵌的那个cdev
p= inode->i_cdev;
if(!p) {
inode->i_cdev= p = new;
list_add(&inode->i_devices,&p->list);
new= NULL;
}
将inode的i_cdev设上了正确的值。
3、跳转到真正的open scull_open
filp->f_op= fops_get(p->ops);
if(!filp->f_op)
gotoout_cdev_put;
if(filp->f_op->open) {
ret= filp->f_op->open(inode,filp);
if(ret)
gotoout_cdev_put;
}
这个p->ops就是前面scull_setup_cdev函数中的dev->cdev.ops= &scull_fops;的scull_fops
所以接下来的open就是scull_fops中的open,也就是scull_open。
到这里,我们基本上了解了字符设备文件是如何产生的,系统调用又是如何一步步到达字符驱动的file_operations从而进行设备的控制操作的。
但是我在看ldd3时,前面很多讲并发竞争、阻塞I/O、内存分配、中断处理等知识点时用到的以scull这个内存的设备构造太复杂了,这里尽可能将scull设备的内部结构简化。
原来scull_dev是:
structscull_dev {
structscull_qset *data; /* Pointer to first quantum set */
intquantum; /* the current quantum size */
intqset; /* the current array size */
unsignedlong size; /* amount of data stored here */
unsignedint access_key; /* used by sculluid and scullpriv */
structsemaphore sem; /* mutual exclusion semaphore */
structcdev cdev; /* Char device structure */
};
我们简化后,再看看write和read的系统调用的过程:
Write的调用过程:
Sys_writevfs_writescull_write
Read的调用过程:
Sys_readvfs_readscull_read
在这里,我们需要提到一个技巧:
在设备打开的时候,一般会将file的私有数据private_data指向设备结构体,这样在read()、write()等函数的时候就可以通过private_data方便访问设备结构体。
(责任编辑:IT)
Linux设备模型之字符设备
以ldd中scull为例来分析一下设备模型的字符设备。 对scull做了一些修改,一方面是内核版本不同引起的一些定义上的修改,另一方面是去除了scull中包括的scullpipe等设备。 为使得我们对字符设备更清晰,我们不分析scull的具体实现,简单理解成内存字符设备。
希望结合文件系统的相关概念,从系统调用深入文件的file_operation,见证linux的“一切都是文件”。
我也阅读过其他人的blog,对于有点观点不是很认同,个人认为sysfs是基于kobject这个基础对象的文件系统,这个文件系统是基于内存的。设计这个文件系统的目的是电源管理、热插拔设备等等的需要(具体见ldd3--14章)。而/dev这个目录,我觉得是devtmpfs挂载的,这也是一个基于内存的文件系统。正是这是文件系统,我们的设备才在vfs统一视图下被当作文件处理。所以我们才可以对设备进行read write ioctl等等。
先看下scull设备的注册: module_init(scull_init_module);int scull_init_module(void)
intscull_init_module(void) { intresult, i; dev_tdev = 0;
/* *Get a range of minor numbers to work with, asking for a dynamic *major unless directed otherwise at load time. */ if(scull_major) { dev= MKDEV(scull_major, scull_minor); result= register_chrdev_region(dev, scull_nr_devs, "scull"); }else { result= alloc_chrdev_region(&dev, scull_minor, scull_nr_devs, "scull"); scull_major= MAJOR(dev); } if(result < 0) { printk(KERN_WARNING"scull: can't get major %d\n", scull_major); returnresult; }
/* * allocate the devices -- we can't have them static, as the number * can be specified at load time */ scull_devices= kmalloc(scull_nr_devs * sizeof(struct scull_dev), GFP_KERNEL); if(!scull_devices) { result= -ENOMEM; gotofail; /* Make this more graceful */ } memset(scull_devices,0, scull_nr_devs * sizeof(struct scull_dev));
/*Initialize each device. */ for(i = 0; i < scull_nr_devs; i++) { scull_devices[i].quantum= scull_quantum; scull_devices[i].qset= scull_qset; init_MUTEX(&scull_devices[i].sem); scull_setup_cdev(&scull_devices[i],i); }
/*At this point call the init function for any friend device */ dev= MKDEV(scull_major, scull_minor + scull_nr_devs); dev+= scull_p_init(dev); dev+= scull_access_init(dev);
#ifdefSCULL_DEBUG /* only when debugging */ scull_create_proc(); #endif
return0; /* succeed */
fail: scull_cleanup_module(); returnresult; }
Init的过程我们分下面几个部分分析:
if (scull_major) { dev = MKDEV(scull_major,scull_minor); result =register_chrdev_region(dev, scull_nr_devs, "scull"); } else { result =alloc_chrdev_region(&dev, scull_minor, scull_nr_devs, "scull"); scull_major = MAJOR(dev); } if (result < 0) { printk(KERN_WARNING "scull:can't get major %d\n", scull_major); return result; } 设备号有两种方法:一是事先知道用哪个设备编号,则可以用register_chrdev_region,而是动态分配,交给alloc_chrdev_region函数处理。 在debug的过程中,dev的参数是263192576,转换成16进制就是FB00000;所以主设备号就是0xfb=251;
scull_devices =kmalloc(scull_nr_devs * sizeof(struct scull_dev), GFP_KERNEL); if (!scull_devices) { result = -ENOMEM; goto fail; /* Make this moregraceful */ } memset(scull_devices,0, scull_nr_devs * sizeof(struct scull_dev)); 这个没什么好讲的了。。。。
/* Initialize each device. */ for (i = 0; i <scull_nr_devs; i++) { scull_devices[i].quantum =scull_quantum; scull_devices[i].qset =scull_qset; init_MUTEX(&scull_devices[i].sem); scull_setup_cdev(&scull_devices[i],i); } 初始化4个scull设备,scull_devices内部的初始化我们不管了,只看如何建立字符设备。
#ifdef SCULL_DEBUG /* only whendebugging */ scull_create_proc(); #endif 这里是通过proc做debug用的,了解一下就行。
我们回到上面第3步的scull_setup_cdev(&scull_devices[i],i); 取i为0分析,
staticvoid scull_setup_cdev(struct scull_dev *dev, int index) { interr, devno = MKDEV(scull_major, scull_minor + index);
cdev_init(&dev->cdev,&scull_fops); dev->cdev.owner= THIS_MODULE; dev->cdev.ops= &scull_fops; err= cdev_add (&dev->cdev, devno, 1); /*Fail gracefully if need be */ if(err) printk(KERN_NOTICE"Error %d adding scull%d", err, index); }
也分成多步分析:
利用刚才自动分配的主设备号和从0开始定义的次设备号,用MKDEV宏生成设备号。 比如说有N个同样的设备,次设备号我们一般取0—N-1.
cdev_init(&dev->cdev,&scull_fops); scull_fops的定义如下: structfile_operations scull_fops = { .owner= THIS_MODULE, .llseek= scull_llseek, .read= scull_read, .write= scull_write, .ioctl= scull_ioctl, .open= scull_open, .release= scull_release, }; 因为linux号称一切皆是文件,这个文件操作结构体包含着scull设备文件的open、read、write等操作。这个结构体很重要,后面我们还要继续邂逅他。 先看下cdev结构体: structcdev { structkobject kobj; structmodule *owner; conststruct file_operations *ops; structlist_head list; dev_tdev; unsignedint count; }; 初始化cdev的list; 初始化cdev内嵌的kobj 将cdev的ops(file_operations)设置为scull_fops。 dev->cdev.owner= THIS_MODULE; dev->cdev.ops= &scull_fops;
cdev_add(&dev->cdev, devno, 1); intcdev_add(struct cdev *p, dev_t dev, unsigned count) { p->dev= dev; p->count= count; returnkobj_map(cdev_map, dev, count, NULL, exact_match, exact_lock, p); } 一眼就看出这个cdev_map有点意思,不得不先看看cdev_map是怎么来的? staticstruct kobj_map *cdev_map; kobj_map结构体如下: structkobj_map { structprobe { structprobe *next; dev_tdev; unsignedlong range; structmodule *owner; kobj_probe_t*get; int(*lock)(dev_t, void *); void*data; }*probes[255]; structmutex *lock; }; 这个kobj_map结构体就是包含了一个大小为255的结构体数组和一个锁。
这个cdev_map是在chrdev_init函数中初始化的,其实不知不觉我们已经调到了fs目录下的char_dev.c,这个放在fs目录下,从某个角度也说明了字符设备其实也是文件。
start_kernel(void)vfs_caches_init chrdev_init(); vfs就是linux文件系统的一个关键层,没有vfs,linux就不能支持如此多类别的文件系统。有人解释vfs是虚拟文件系统,我倒觉得将s理解为switch更为恰当些。
稍微扯远了,再回到chrdev_init中来: void__init chrdev_init(void) { cdev_map= kobj_map_init(base_probe, &chrdevs_lock); bdi_init(&directly_mappable_cdev_bdi); }
structkobj_map *kobj_map_init(kobj_probe_t *base_probe, struct mutex *lock) { structkobj_map *p = kmalloc(sizeof(struct kobj_map), GFP_KERNEL); structprobe *base = kzalloc(sizeof(*base), GFP_KERNEL); inti;
if((p == NULL) || (base == NULL)) { kfree(p); kfree(base); returnNULL; }
base->dev= 1; base->range= ~0; base->get= base_probe; for(i = 0; i < 255; i++) p->probes[i]= base; p->lock= lock; returnp; } 给structkobj_map *p申请内存,在给structprobe*base申请内存。这个probe结构体就是我们在kobj_map中包的结构体数组的结构体,取名为base,后面我们用base来初始化255中的每一个结构体。 Bdi_init函数暂且不管它了。。。
再回到cdev_add中的kobj_map(cdev_map,dev, count, NULL, exact_match, exact_lock, p); intkobj_map(struct kobj_map *domain, dev_t dev, unsigned long range, struct module *module, kobj_probe_t *probe, int (*lock)(dev_t, void *), void *data) { unsignedn = MAJOR(dev + range - 1) - MAJOR(dev) + 1; unsignedindex = MAJOR(dev); unsignedi; structprobe *p;
if(n > 255) n= 255;
p= kmalloc(sizeof(struct probe) * n, GFP_KERNEL);
if(p == NULL) return-ENOMEM;
for(i = 0; i < n; i++, p++) { p->owner= module; p->get= probe; p->lock= lock; p->dev= dev; p->range= range; p->data= data; } mutex_lock(domain->lock); for(i = 0, p -= n; i < n; i++, p++, index++) { structprobe **s = &domain->probes[index % 255]; while(*s && (*s)->range < range) s= &(*s)->next; p->next= *s; *s= p; } mutex_unlock(domain->lock); return0; }
下面用mknod来创建一个字符设备。 先cat/proc/devices如下:
得到主设备号为251,然后mknod /dev/scull0 c 251 0 系统调用关系如下: #0 sys_mknodat (dfd=-100, filename=0xbfc66907 "/dev/scull0",mode=8630, dev=64256)at fs/namei.c:2019 #1 0xc029fd35 in sys_mknod (filename=0xbfc66907 "/dev/scull0",mode=8630, dev=64256)at fs/namei.c:2068 #2 0xc0104657 in ?? () at arch/x86/kernel/entry_32.S:457
在fs/namei.c中的 SYSCALL_DEFINE4(mknodat,int, dfd, const char __user *, filename, int, mode, unsigned,dev)
断点显示如下: Breakpoint2, sys_mknodat (dfd=-100, filename=0xbfc66907 "/dev/scull0", mode=8630,dev=64256) at fs/namei.c:2019 sys_mknodat函数有一段如下: switch(mode & S_IFMT) { case0: case S_IFREG: error= vfs_create(nd.path.dentry->d_inode,dentry,mode,&nd); break; caseS_IFCHR: case S_IFBLK: error= vfs_mknod(nd.path.dentry->d_inode,dentry,mode, new_decode_dev(dev)); break; caseS_IFIFO: case S_IFSOCK: error= vfs_mknod(nd.path.dentry->d_inode,dentry,mode,0); break; } 可以看出,我们可以用mknod来创建普通文件,字符设备文件,块设备文件,FIFO和socket文件。
这里只关心字符设备文件: error= vfs_mknod(nd.path.dentry->d_inode,dentry,mode, new_decode_dev(dev)); 先看下new_decode_dev(dev)做了什么,其中dev的值是64256 staticinline dev_t new_decode_dev(u32 dev) { unsignedmajor = (dev & 0xfff00) >> 8; unsignedminor = (dev & 0xff) | ((dev >> 12) & 0xfff00); returnMKDEV(major, minor); }
自己算一下major=0xfb=251minor=0 返回设备号0xFB00000.
接下来看vfs_mknod函数,这个和文件系统紧密相关(inode和dentry的概念)。 vfs_mknod(dir=0xdf910228, dentry=0xdf1ddf68, mode=8630, dev=263192576) atfs/namei.c:1969
这个函数关键在于调用dir这个inode下的i_op中的mknod函数: error= dir->i_op->mknod(dir, dentry, mode, dev); 其实这个用的是 shmem_mknod(dir=0xdf910228, dentry=0xdf1ddf68, mode=8630, dev=263192576) 用df–hT: Filesystem Type Size Used Avail Use% Mounted on /dev/sda1 ext4 19G 17G 1.6G 92% / none devtmpfs 245M 248K 245M 1% /dev none tmpfs 249M 252K 249M 1% /dev/shm none tmpfs 249M 308K 249M 1% /var/run none tmpfs 249M 0 249M 0% /var/lock none tmpfs 249M 0 249M 0% /lib/init/rw .host:/ vmhgfs 74G 48G 26G 66% /mnt/hgfs
可以看到一个名为devtmpfs的文件系统挂载在/dev目录上。
Devtmpfs是个什么文件系统,我们从drivers/base下的Kconfig文件先看个大概: configDEVTMPFS bool"Maintain a devtmpfs filesystem to mount at /dev" dependson HOTPLUG && SHMEM && TMPFS help Thiscreates a tmpfs filesystem instance early at bootup. Inthis filesystem, the kernel driver core maintains device nodeswith their default names and permissions for all registereddevices with an assigned major/minor number. Userspacecan modify the filesystem content as needed, add symlinks,and apply needed permissions. Itprovides a fully functional /dev directory, where usually udevruns on top, managing permissions and adding meaningful symlinks. Invery limited environments, it may provide a sufficient functional/dev without any further help. It also allows simple rescuesystems, and reliably handles dynamic major/minor numbers.
猜测/dev和上面的shmem_mknod有关系。
利用kgdb仔细看一下: (gdb)p *dentry $16= {d_count = {counter = 1}, d_flags = 0, d_lock = {{rlock = {raw_lock= { slock= 257}}}}, d_mounted = 0,d_inode = 0x0,d_hash = {next = 0x0, pprev= 0xc141119c},d_parent = 0xdf4012a8,d_name = {hash = 3558180945, len= 6, name = 0xdf1ddfc4 "scull0"}, d_lru = {next =0xdf1ddf94, prev= 0xdf1ddf94}, d_u = {d_child = {next = 0xdf17682c, prev= 0xdf4012e4}, d_rcu = {next = 0xdf17682c, func = 0xdf4012e4}}, d_subdirs= {next = 0xdf1ddfa4, prev = 0xdf1ddfa4}, d_alias = { next= 0xdf1ddfac, prev = 0xdf1ddfac}, d_time = 2451638784, d_op= 0xc07ae990,d_sb = 0xdf8f6e00,d_fsdata = 0x0, d_iname="scull0\000\066\000\000\f`\233\000\000\f\253\000\000\000\000\006\004u\000\000\000\006\004F\233\000\000(\001\253\000\000\000\206"}
先看下d_parent这个dentry的内容: (gdb)p *(struct dentry *)0xdf4012a8 $21= {d_count = {counter = 210}, d_flags = 16, d_lock = {{rlock = { raw_lock= {slock = 1542}}}}, d_mounted = 0, d_inode = 0xdf910228, d_hash= {next = 0x0, pprev = 0x0}, d_parent = 0xdf4012a8, d_name = { hash= 0, len = 1, name = 0xdf401304 "/"}, d_lru = {next =0xdf4012d4, prev= 0xdf4012d4}, d_u = {d_child = {next = 0xdf4012dc, prev= 0xdf4012dc}, d_rcu = {next = 0xdf4012dc, func = 0xdf4012dc}}, d_subdirs= {next = 0xdf1ddf9c, prev = 0xdf40171c}, d_alias = { next= 0xdf910240, prev = 0xdf910240}, d_time = 0, d_op = 0x0, d_sb= 0xdf8f6e00, d_fsdata = 0x0, d_iname = "/", '\000'<repeats 38 times>}
我们看到了”/”,但如果scull0在/目录下,那就有问题了,因为路径应该是/dev/dev/scull0,如果对文件系统有些了解,就知道这里应该挂载了一个文件系统。 这个文件系统就是: staticstruct file_system_type dev_fs_type = { .name= "devtmpfs", .get_sb= dev_get_sb, .kill_sb= kill_litter_super, }; 这个”/”代表的是dev_fs_type文件系统的根。他是挂载在我们的根文件系统的目录下的。
再看一下super_block: (gdb)p *dentry->d_sb $20= {s_list = {next = 0xdf8f7800, prev = 0xdf8f6c00}, s_dev = 5, s_dirt= 0 '\000', s_blocksize_bits = 12 '\f', s_blocksize = 4096, s_maxbytes= 2201170804736, s_type = 0xc09f20a0, s_op = 0xc07a7c40, dq_op= 0xc07affe0, s_qcop = 0xc07b0000, s_export_op = 0xc07a7f8c, s_flags= 1078001664, s_magic = 16914836, s_root = 0xdf4012a8, s_umount = { count= 0, wait_lock = {{rlock = {raw_lock = {slock = 0}}}}, wait_list = { next= 0xdf8f6e44, prev = 0xdf8f6e44}}, s_lock = {count = {counter = 1}, wait_lock= {{rlock = {raw_lock = {slock = 0}}}}, wait_list = { next= 0xdf8f6e54, prev = 0xdf8f6e54}, owner = 0x0}, s_count= 1073741824, s_need_sync = 0, s_active = {counter = 2}, s_security= 0x0, s_xattr = 0xc09d6650, s_inodes = {next = 0xdbd975d0, prev= 0xdf910238}, s_anon = {first = 0x0}, s_files = {next = 0xdafe3700, prev= 0xd2744100}, s_dentry_lru = {next = 0xdf8f6e88, prev = 0xdf8f6e88}, s_nr_dentry_unused= 0, s_bdev = 0x0, s_bdi = 0xc09d6a80, s_mtd = 0x0, s_instances= {next = 0xc09f20b8, prev = 0xc09f20b8}, s_dquot = {flags = 0, dqio_mutex= {count = {counter = 1}, wait_lock = {{rlock = {raw_lock = { slock= 0}}}}, wait_list = {next = 0xdf8f6eb4, prev= 0xdf8f6eb4}, owner = 0x0}, dqonoff_mutex = {count = { counter= 1}, wait_lock = {{rlock = {raw_lock = {slock = 0}}}}, wait_list= {next = 0xdf8f6ec8, prev = 0xdf8f6ec8}, owner = 0x0}, dqptr_sem= {count = 0, wait_lock = {{rlock = {raw_lock = {slock = 0}}}}, wait_list= {next = 0xdf8f6edc, prev = 0xdf8f6edc}}, files = {0x0, 0x0}, info= {{dqi_format = 0x0, dqi_fmt_id = 0, dqi_dirty_list = {next = 0x0, ---Type<return> to continue, or q <return> to quit--- prev= 0x0}, dqi_flags = 0, dqi_bgrace = 0, dqi_igrace = 0, dqi_maxblimit= 0, dqi_maxilimit = 0, dqi_priv = 0x0}, { dqi_format= 0x0, dqi_fmt_id = 0, dqi_dirty_list = {next = 0x0, prev= 0x0}, dqi_flags = 0, dqi_bgrace = 0, dqi_igrace = 0, dqi_maxblimit= 0, dqi_maxilimit = 0, dqi_priv = 0x0}}, ops = {0x0, 0x0}},s_frozen = 0, s_wait_unfrozen = {lock = {{rlock = {raw_lock = { slock= 0}}}}, task_list = {next = 0xdf8f6f5c, prev= 0xdf8f6f5c}}, s_id = "devtmpfs",'\000' <repeats 23 times>, s_fs_info= 0xdf8026c0, s_mode = 0, s_time_gran = 1, s_vfs_rename_mutex = { count= {counter = 1}, wait_lock = {{rlock = {raw_lock = {slock = 0}}}}, wait_list= {next = 0xdf8f6f98, prev = 0xdf8f6f98}, owner = 0x0}, s_subtype= 0x0, s_options = 0x0}
从这里也可以看到这里是挂载在/dev的一个内存文件系统:devtmpfs
为什么vfs_mknod会跳到shmem_mknod(dir->i_op->mknod(dir,dentry, mode, dev);)
因为devtmpfs在mount的时候 staticint dev_get_sb(struct file_system_type *fs_type, int flags, const char *dev_name, void *data, struct vfsmount *mnt) { returnget_sb_single(fs_type, flags, data, shmem_fill_super, mnt); }
是shmem_fill_super函数来填充devtmpfs的super_block的。 那么在shmem_get_inode中 caseS_IFDIR: inc_nlink(inode); /*Some things misbehave if size == 0 on a directory */ inode->i_size= 2 * BOGO_DIRENT_SIZE; inode->i_op= &shmem_dir_inode_operations; inode->i_fop= &simple_dir_operations; 由于mountpoint是dev这个目录,所以dev对应的inode的i_op就是shmem_dir_inode_operations。
所以: 在vfs_mknod(dir=0xdf910228, dentry=0xdf1ddf68, mode=8630, dev=263192576) atfs/namei.c:1969 中, error= dir->i_op->mknod(dir, dentry, mode, dev); 就调到了: staticconst struct inode_operations shmem_dir_inode_operations = { #ifdefCONFIG_TMPFS .create =shmem_create, .lookup =simple_lookup, .link =shmem_link, .unlink =shmem_unlink, .symlink =shmem_symlink, .mkdir =shmem_mkdir, .rmdir =shmem_rmdir, .mknod =shmem_mknod, .rename =shmem_rename, #endif #ifdefCONFIG_TMPFS_POSIX_ACL .setattr =shmem_notify_change, .setxattr =generic_setxattr, .getxattr =generic_getxattr, .listxattr =generic_listxattr, .removexattr =generic_removexattr, .check_acl =generic_check_acl, #endif };
中的shmem_mknod。
Devtmpfs暂且不谈了,还是直接看下shmem_mknod吧
在shmem_mknod中,通过shmem_get_inode含糊来创建新的inode。 inode= shmem_get_inode(dir->i_sb, mode, dev, VM_NORESERVE); shmem_get_inode(sb=0xdf8f6e00, mode=8630, dev=263192576, flags=2097152)
在shmem_get_inode中,这个函数首先用new_inode(sb)函数生成一个新的inode,在各种文件系统的xx_get_inode函数中这都是第一步;第二步就是设置inode这个大结构体的各个成员了,这里我们主要看i_op和i_fop。 在 switch(mode & S_IFMT) { default: inode->i_op= &shmem_special_inode_operations; init_special_inode(inode,mode, dev); 中,我们走到了default: I_op设置为shmem_special_inode_operations 而init_special_inode函数是在fs目录下的inode.c中, 在这个函数中,根据mode进行了细分,看是不是chr,blk,fifio和sock。 如果是chr字符文件,那么 if(S_ISCHR(mode)) { inode->i_fop= &def_chr_fops; inode->i_rdev= rdev; } 这里i_fop赋为def_chr_fops conststruct file_operations def_chr_fops = { .open= chrdev_open, }; i_rdev设为rdev,也就是设备号0xFB00000;
在ldd3一书中,在第3章介绍了一些重要的结构体,包括了inode结构。 书中有这么一段话: Inode结构包含大量关于文件的信息。作为一个通用的规则,这个结构只有两个成员对于编写驱动代码有用: Dev_ti_rdev; 对于代表设备文件的节点,这个成员包含实际的设备编号。 Structcdev *i_cdev; Structcdev是内核的内部结构,代表字符设备;这个成员包含一个指针,指向这个结构,当节点 这个时候inode的i_rdev已正确赋值,而i_cdev暂且未指向正确的字符设备。
再回到shmem_mknod来,既然inode出来了,那就要与dentry建立关系。 在shmem_mknod(structinode *dir, struct dentry *dentry, int mode, dev_tdev)中的dentry我们前面已经看过了,就是scull0的目录项。 d_instantiate(dentry,inode); /* d_instantiate - fill in inode information for a dentry*/ mknod到这里走到末尾了,这个时候可以在/dev下看到scull0这个字符设备节点。
既然字符设备成了一个文件,那要使一个文件能够读写,那么文件首先要被open。 下面我们open/dev/scull0,看看open系统调用到底层是如何一步一步深入的。 Sys_opendo_sys_open do_filp_open do_lastfinish_opennameidata_to_filp __dentry_open chrdev_open
在__dentry_open函数是如何调用chrdev_open的? __dentry_open的函数原型是: staticstruct file *__dentry_open(struct dentry *dentry, struct vfsmount*mnt, structfile *f, int(*open)(struct inode *, struct file *), conststruct cred *cred) 1、inode= dentry->d_inode; 2、f->f_op= fops_get(inode->i_fop);这里inode的i_fop指针就是def_chr_fops 3、if(!open && f->f_op) open= f->f_op->open;这是open就指向了def_chr_fops中的chrdev_open 4、 if(open) { error= open(inode, f); if(error) gotocleanup_all; } 这里才调用了chrdev_open函数。
下面仔细分析chrdev_open函数: 给出chrdev_open函数的定义: staticint chrdev_open(struct inode *inode, struct file *filp) { structcdev *p; structcdev *new = NULL; intret = 0;
spin_lock(&cdev_lock); p= inode->i_cdev; ------1------- if(!p) { -------2------- structkobject *kobj; intidx; spin_unlock(&cdev_lock); kobj= kobj_lookup(cdev_map, inode->i_rdev, &idx); if(!kobj) return-ENXIO; new= container_of(kobj, struct cdev, kobj); spin_lock(&cdev_lock); /*Check i_cdev again in case somebody beat us to it while we dropped the lock. */ p= inode->i_cdev; if(!p) { inode->i_cdev= p = new; list_add(&inode->i_devices,&p->list); new= NULL; }else if (!cdev_get(p)) ret= -ENXIO; }else if (!cdev_get(p)) ret= -ENXIO; spin_unlock(&cdev_lock); cdev_put(new); if(ret) returnret;
ret= -ENXIO; filp->f_op= fops_get(p->ops); if(!filp->f_op) gotoout_cdev_put;
if(filp->f_op->open) { ret= filp->f_op->open(inode,filp); if(ret) gotoout_cdev_put; }
return0;
out_cdev_put: cdev_put(p); returnret; }
2a、首先根据前面初始化和map过的cdev_map来根据inode->i_rdev(设备号)来lookup正确的kobj。 kobj= kobj_lookup(cdev_map, inode->i_rdev, &idx); 2b、利用container_of宏获取cdev new= container_of(kobj, struct cdev, kobj); 这个时候new就是scull_dev中内嵌的那个cdev p= inode->i_cdev; if(!p) { inode->i_cdev= p = new; list_add(&inode->i_devices,&p->list); new= NULL; } 将inode的i_cdev设上了正确的值。
3、跳转到真正的open scull_open filp->f_op= fops_get(p->ops); if(!filp->f_op) gotoout_cdev_put;
if(filp->f_op->open) { ret= filp->f_op->open(inode,filp); if(ret) gotoout_cdev_put; } 这个p->ops就是前面scull_setup_cdev函数中的dev->cdev.ops= &scull_fops;的scull_fops
所以接下来的open就是scull_fops中的open,也就是scull_open。
到这里,我们基本上了解了字符设备文件是如何产生的,系统调用又是如何一步步到达字符驱动的file_operations从而进行设备的控制操作的。
但是我在看ldd3时,前面很多讲并发竞争、阻塞I/O、内存分配、中断处理等知识点时用到的以scull这个内存的设备构造太复杂了,这里尽可能将scull设备的内部结构简化。 原来scull_dev是: structscull_dev { structscull_qset *data; /* Pointer to first quantum set */ intquantum; /* the current quantum size */ intqset; /* the current array size */ unsignedlong size; /* amount of data stored here */ unsignedint access_key; /* used by sculluid and scullpriv */ structsemaphore sem; /* mutual exclusion semaphore */ structcdev cdev; /* Char device structure */ };
我们简化后,再看看write和read的系统调用的过程:
Write的调用过程: Sys_writevfs_writescull_write
Read的调用过程: Sys_readvfs_readscull_read
在这里,我们需要提到一个技巧: 在设备打开的时候,一般会将file的私有数据private_data指向设备结构体,这样在read()、write()等函数的时候就可以通过private_data方便访问设备结构体。 (责任编辑:IT) |