Centos 6.3 Hadoop集群配置详解
时间:2016-03-11 23:16 来源:linux.it.net.cn 作者:IT
环境:4台服务器 1 Master 3 Slave, 系统Centos 6.3,预先安装好JDK 1.7 和openssh(对相关安装配置过程有疑问或者困难的请google或者查阅笔者之前的blog),且关闭防火墙(避免配置好后运行过程引起不必要的意外)
服务器清单如下
1
2
3
4
5
6
7
8
9
HostName IP
Master 192.168.1.200
Slave01 192.168.1.201
Slave02 192.168.1.202
Slave03 192.168.1.203
一.修改Hostname
将4台服务器的hostname 分别更改为Master,Slave01,Slave02,Slave03
1
2
3
sudo vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=XXXX
请将XXXX替换成对应服务器的Hostname
分别修改4台服务器的hosts
1
2
3
4
5
6
7
8
sudo vim /etc/hosts
192.168.1.200 Master
192.168.1.201 Slave01
192.168.1.202 Slave02
192.168.1.203 Slave03
//保存
reboot//重启后生效
可以通过输入hostname命令查看是否配置成功
二.设置SSH无密码登录
1)生成无密码秘钥对
在Master机器上执行如下命令
1
2
cd ~/.ssh
ssh-keygen -t rsa -P '' -f id_rsa
按照提示信息回车即可
2)追加id_rsa.pub到授权的key里面去
1
2
3
sudo cat id_rsa.pub >>authorized_keys
chmod 600 authorized_keys
切记需要修改成600权限,不安全的权限设置,会让你不能使用RSA功能
3)修改SSH配置文件
1
sudo vim /etc/ssh/sshd_config
修改以下内容
1
2
3
RSAAuthentication yes # 启用 RSA 认证
PubkeyAuthentication yes # 启用公钥私钥配对认证方式
AuthorizedKeysFile ~/.ssh/authorized_keys # 公钥文件路径
4)重启SSH服务
1
sudo service sshd restart
然后验证是否配置成功,可以通过ssh localhost看看是否需要输入密码,如果无需输入密码,说明配置成功,反之可以用如下2个命令进行问题定位和解决
ssh -v localhost
tail /var/log/secure -n 20
5)接着配置Master和Slave相互之间无密码SSH登陆
把Master上的 id_rsa.pub和id_rsa通过scp分别复制到3个slave服务器上,然后重复上述的 2,3,4操作
1
2
3
scp id_rsa.pub frankwong@192.168.1.203:/home/frankwong/.ssh
scp id_rsa frankwong@192.168.1.203:/home/frankwong/.ssh
最后通过测试Master和Slave之间是否可以相互无密码SSH登陆
三.配置Hadoop
把hadoop-1.1.2.tar.gz 通过winSCP上传到linux上,解压缩,然后修改权限
1
2
3
4
5
cd~
sudo mv hadoop-1.1.2.tar.gz /opt
sudo tar -zxvf hadoop-1.1.2.tar.gz
sudo mv hadoop-1.1.2 hadoop
sudo chown -R frankwong:frankwong hadoop
修改环境变量,切换到root权限
1
2
3
4
sudo vim /etc/profile
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
source /etc/profile
切换成frankwong用户
接着我们开始进入主题,登陆Master
1)配置hadoop-env.sh
配置JDK路径和日志保存路径
1
2
3
4
5
vim /opt/hadoop/conf/hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.7.0_17
export HADOOP_LOG_DIR=${HADOOP_HOME}/logs
2)配置core-site.xml文件
请先在 /opt/hadoop 目录下建立 tmp 文件夹
备注:如没有配置hadoop.tmp.dir参数,此时系统默认的临时目录为:/tmp/hadoo-hadoop。而这个目录在每次重启后都会被干掉,必须重新执行format才行,否则会出错。
1
2
3
4
5
6
7
8
<property>
<name>fs.default.name</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>Hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value>
</property>
3)配置hdfs-site.xml文件
1
2
3
4
5
6
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
4)配置mapred-site.xml文件
1
2
3
4
5
6
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>http://Master:9001</value>
</property>
</configuration>
5)配置masters文件
1
vim masters
增加Master
6)配置slaves文件(Master主机特有)
Slave01
Slave02
Slave03
7)把hadoop复制到其他Slave上
把Master配置好的hadoop文件全部复制到3个Slave的/opt目录下
8)启动服务
在Master上输入
hadoop namenode -format//格式化
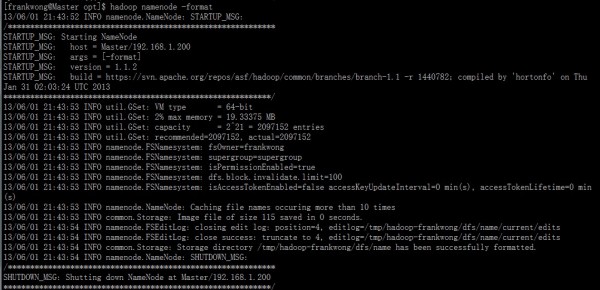
start-all.sh//启动服务

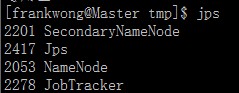
查看Master状态:在Master上输入jps,结果如下
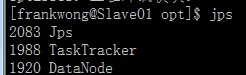
查看Slave状态:在任意一台Slave上输入jps,结果如下
还可以通过 hadoop dfsadmin -report 查看集群节点信息
9)网页查看集群
http://Master:50030
http://Master:50070
(责任编辑:IT)
| 环境:4台服务器 1 Master 3 Slave, 系统Centos 6.3,预先安装好JDK 1.7 和openssh(对相关安装配置过程有疑问或者困难的请google或者查阅笔者之前的blog),且关闭防火墙(避免配置好后运行过程引起不必要的意外)
服务器清单如下
一.修改Hostname
请将XXXX替换成对应服务器的Hostname 分别修改4台服务器的hosts
可以通过输入hostname命令查看是否配置成功 二.设置SSH无密码登录1)生成无密码秘钥对 在Master机器上执行如下命令
按照提示信息回车即可 2)追加id_rsa.pub到授权的key里面去
切记需要修改成600权限,不安全的权限设置,会让你不能使用RSA功能 3)修改SSH配置文件
修改以下内容
4)重启SSH服务
然后验证是否配置成功,可以通过ssh localhost看看是否需要输入密码,如果无需输入密码,说明配置成功,反之可以用如下2个命令进行问题定位和解决
ssh -v localhost 5)接着配置Master和Slave相互之间无密码SSH登陆 把Master上的 id_rsa.pub和id_rsa通过scp分别复制到3个slave服务器上,然后重复上述的 2,3,4操作
最后通过测试Master和Slave之间是否可以相互无密码SSH登陆 三.配置Hadoop把hadoop-1.1.2.tar.gz 通过winSCP上传到linux上,解压缩,然后修改权限
修改环境变量,切换到root权限
切换成frankwong用户 接着我们开始进入主题,登陆Master 1)配置hadoop-env.sh 配置JDK路径和日志保存路径
2)配置core-site.xml文件 请先在 /opt/hadoop 目录下建立 tmp 文件夹 备注:如没有配置hadoop.tmp.dir参数,此时系统默认的临时目录为:/tmp/hadoo-hadoop。而这个目录在每次重启后都会被干掉,必须重新执行format才行,否则会出错。
3)配置hdfs-site.xml文件
4)配置mapred-site.xml文件
5)配置masters文件
增加Master 6)配置slaves文件(Master主机特有) Slave01 Slave02 Slave03 7)把hadoop复制到其他Slave上 把Master配置好的hadoop文件全部复制到3个Slave的/opt目录下 8)启动服务 在Master上输入 hadoop namenode -format//格式化
start-all.sh//启动服务
查看Master状态:在Master上输入jps,结果如下
查看Slave状态:在任意一台Slave上输入jps,结果如下
还可以通过 hadoop dfsadmin -report 查看集群节点信息 9)网页查看集群http://Master:50030 http://Master:50070
(责任编辑:IT) |