虚拟机已死,容器才是未来?
时间:2016-05-04 20:14 来源:linux.it.net.cn 作者:IT
我也曾经是容器技术尤其是 Docker 粉丝,但用了一年后觉得事情也没那么美好,而颇有一些同学以及一些公司依然认为容器就是银弹,虚拟机已经是昨儿黄花必须打倒,大家赶紧一切皆容器。这里我对这种观点吐吐槽。仅代表作者个人看法
首先要明确的是,软件开发和运维活动中,可维护性、正确性、性能的优先级是依次降低的,不要跟我抬杠少数极端情况。关于可维护性和正确性的先后,著 名的 "worse is better" 文章就是很好的无奈的解释,如果你犹豫这两者,这还情有可原,毕竟真善美和糙快猛的斗争从未停歇,而你如果第一反应觉得性能是最重要的,那就不要继续往下 看了,洗洗去睡吧——适合的才是最好的。
那么对于虚拟机 vs 容器,自然我们也需要从这三方面考察。
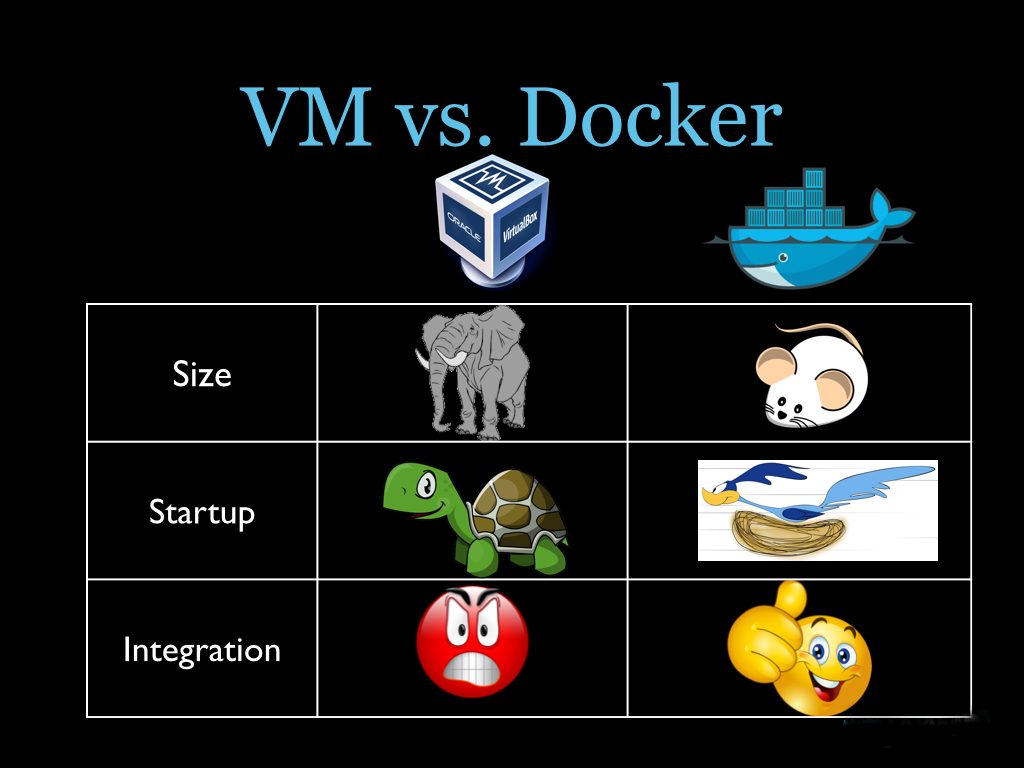
回合一:可维护性之争
虚拟机—维护性
从 hypervisor 讲,Xen/KVM/vSphere/HyperV 都很成熟了,久经考验,BSD 也在凑热闹搞 bhyve(FreeBSD) 和 vmm(OpenBSD),最近 unikernel 也在试图跑在 hypervisor 上,而 AWS/GCE/Azure 等等云计算巨头以及 Intel/AMD 等在CPU、磁盘和网络IO虚拟化技术上的投资显然不会立马推翻,Linux 上虚拟机的开源管理方案也已成熟定型:libvirt, OpenStack, 没人吃饱了撑的去弄个 “新的开源” 项目替换它们,虽然我很不喜欢 OpenStack 的乱糟和复杂。VM 的动态迁移也是成熟技术,出来好多年了,实现原理非常简单,反正整个 OS 内存一锅端弄过去,不操心少个依赖进程的内存没过去。想用不同版本内核? 想要自定义内核模块?想调整内核参数?期望更安全的隔离?期望如同物理机版几乎一致的使用体验?VM 就是虚拟机的缩写嘛,这些都是拿手戏。
容器— 维护性
Linux 容器,Linux 一贯的作风,慢慢演化,不求仔细设计,然后就是 cgroup, pid/uts/ipc/net/uid namespace 一个个实现出来,凑出一个容器技术,貌似 uid namespace 还是最近刚刚出来的特性。用户空间则更是群雄并起,LXC,Docker,rkt,LXD,各有拥蹇,鹿死谁手,还真不好说,在这个局还没明朗的时 候,Mesos、Swarm、Kubernetes、Nomad 又出来一堆搅局的,眼下看来最吸引眼球的 Kubernetes 俨然有 OpenStack 继任者的感觉,但依然很嫩,没几个人敢在生产环境大规模使用。
Linux容器里进程的跨机器动态迁移我还没听说,不要说是个服务就得有集群有 HA 嘛,可还真有不少用户一个服务就单机顶着呢,就算有热备或者冷备,在线那台机器内存里的东西可宝贵了,轻易不能丢。用Linux容器就不能挑内核,不能加 载内核模块,不能挂载文件系统,不能调整内核参数,不能改网络配置,等等,不要告诉我你能——你是不是开了 docker run --privileged 了? 你是不是没 drop capability?你是不是没有 remap uid?话说某大公司的容器还真就用 --privileged 选项跑的呢。 而 Linux 的隔离不彻底恐怕大部分人都没意识到,/sys, /dev, /selinux 还有 /proc 下的某些关键文件比如 /proc/kcore 没隔离呢。
Redhat 做的 project Atomic 意识到这些问题,正在积极的给 Docker 加 SELinux 支持,指定 SELinux policy,但 Docker 官方爱搭不理,而且 SELinux 这种高端技术是凡人玩的么? 结局大概依然是 "FAQ 1: 关掉 SELinux"。Linux 容器本来并不局限在一个容器里跑几个进程,但 Docker 官方为了加强“轻量级”这词的洗脑效果,搞出个无比脑残的 single process 理念,被无数人捧臭脚,所幸有些人慢慢意识到问题,Yelp 搞了个 dumb-init 擦了一半屁股,还有无数 docker image 用 runit、supervisor 之类的做 /sbin/init 替换,但问题在于这要自定义启动脚本,需要加 ssh/cron/syslog/logrotate 等等边角料——这已然是解决了无数遍的问题,还要解决一遍,不觉得麻烦吗?难道没有人认为这些包的作者或者打包者更善于处理服务启动脚本么?像 systemd 那种搞法还算正道,特意考虑容器环境,跳过一些步骤,但貌似还没做完善,需要手动删除一些 .service 文件。
虚拟机 vs 容器
也许有人会说 docker pull/push 多方便啊,docker build 多方便啊,可不要忘了,vm image storage 早在 openstack 里就解决了,自己处理也不是个大事,vm image build 也有 Hashicorp 的 Packer 工具代劳,不是个事。Docker 自豪的官方 docker registry 其实大家最多用用 base os image,那些 app 级别的出于信任以及定制考虑都会自己 build。而 Docker 自豪的 layered storage 也是无数血泪,aufs & overlayfs 坑了多少人?容器社区最近还特崇拜 immutable deployment,以把容器根文件系统弄做只读的为荣,全然不管有紧急安全更新或者功能修正怎么处理——什么,你要说 docker rm && docker run 再起一批不就完事么?真有这么简单就好了。
像 Linux kernel 和 git 那种才是正经 unix 设计的思想,分层堆叠,底层提供mechanism,高层提供 policy,各取所需,可惜人总是易于被洗脑,在接受各种高大上policy的时候全然忘了mechanism还在不在自己手里。
回合二:正确性之争
强隔离、full OS 体验、保留 mechanism,这才是正道。另外容器还隐藏了一个坑,/proc/cpuinfo和free命令输出是host os的,这坑了无数探测系统资源自动决定默认线程池和内存池大小的程序,尤以Java最为普遍。
回合三:性能之争
容器粉丝津津乐道——启动容器快,容器的开销少。 这两点确实如此但好处真的有那么巨大么?谁有事没事不停创建虚拟机?谁的虚拟机生命周期平均在分钟级别?谁的“用完全启动时间”平均在秒级? 至于说到虚拟机浪费的资源太多,其实也就是个障眼法。理论上服务器的资源利用率平均不应该超过 80%而实际上绝大部分公司的服务器资源利用率应该都不到 50%,大量的CPU、内存、本地磁盘都是常年浪费的,所以 VM 的额外开销不过是浪费了原本就在浪费的资源罢了。就单机的巅峰 I/O 能力来言,VM 确实不敌容器。但平时根本就用不到巅峰状态, 原本一个 VM 里多进程干的事,非得搞多个容器跑,这容器开销,这人力开销怎么算?
关于容器还有一个幻想,那就是可以在物理机上直接跑容器,开销巨低、管理巨方便,用专用物理机方式提供多租户强隔离。前面两点上面已经驳过了,话说 还有人用 openstack 管理 docker 容器呢。 我只是说一下第三点,在一台物理机上直接跑容器的一个最容易被忽视的问题:现在用来提供云服务的物理机一般都是硬件超级牛逼,跑上百个容器都没问题,但问 题在于用户很可能只需要几个容器,所以要么跟人共用物理机,要么浪费资源白交钱。哪怕用户需要上百个容器,出于容灾考虑,也不可以把上百容器部署到一台物 理机上,所以还是要么跟人共用物理机,要么浪费资源。
方案
以上是我的观点,我并不是“容器黑”,而是“实用白”。AWS、Azure、GCE 都主推在虚拟机上跑容器,按虚拟机收费,这非常明智的解决了问题:老的纯 VM 基础设施不用动,计费照旧,单物理机可以被安全的多租户共用,资源隔离有保证(起码比共享内核强多了),把容器管理软件如“kubernetes”给用 户,既满足用户的容器需求,又不担心容器的多租户问题。
所以我认为:以 VM 为基础,以容器为辅助点,要买就买 VM,自己管理容器,别买 CAAS 直接提供的容器,别看不到底下物理机或者虚拟机。用 VM 还是用容器,冷静考察自己的应用上容器是否有好处。最后,残念,VM 开源管理软件能搞个比 OpenStack 简单的东西吗?
(责任编辑:IT)
我也曾经是容器技术尤其是 Docker 粉丝,但用了一年后觉得事情也没那么美好,而颇有一些同学以及一些公司依然认为容器就是银弹,虚拟机已经是昨儿黄花必须打倒,大家赶紧一切皆容器。这里我对这种观点吐吐槽。仅代表作者个人看法 首先要明确的是,软件开发和运维活动中,可维护性、正确性、性能的优先级是依次降低的,不要跟我抬杠少数极端情况。关于可维护性和正确性的先后,著 名的 "worse is better" 文章就是很好的无奈的解释,如果你犹豫这两者,这还情有可原,毕竟真善美和糙快猛的斗争从未停歇,而你如果第一反应觉得性能是最重要的,那就不要继续往下 看了,洗洗去睡吧——适合的才是最好的。 那么对于虚拟机 vs 容器,自然我们也需要从这三方面考察。
回合一:可维护性之争 虚拟机—维护性 从 hypervisor 讲,Xen/KVM/vSphere/HyperV 都很成熟了,久经考验,BSD 也在凑热闹搞 bhyve(FreeBSD) 和 vmm(OpenBSD),最近 unikernel 也在试图跑在 hypervisor 上,而 AWS/GCE/Azure 等等云计算巨头以及 Intel/AMD 等在CPU、磁盘和网络IO虚拟化技术上的投资显然不会立马推翻,Linux 上虚拟机的开源管理方案也已成熟定型:libvirt, OpenStack, 没人吃饱了撑的去弄个 “新的开源” 项目替换它们,虽然我很不喜欢 OpenStack 的乱糟和复杂。VM 的动态迁移也是成熟技术,出来好多年了,实现原理非常简单,反正整个 OS 内存一锅端弄过去,不操心少个依赖进程的内存没过去。想用不同版本内核? 想要自定义内核模块?想调整内核参数?期望更安全的隔离?期望如同物理机版几乎一致的使用体验?VM 就是虚拟机的缩写嘛,这些都是拿手戏。 容器— 维护性 Linux 容器,Linux 一贯的作风,慢慢演化,不求仔细设计,然后就是 cgroup, pid/uts/ipc/net/uid namespace 一个个实现出来,凑出一个容器技术,貌似 uid namespace 还是最近刚刚出来的特性。用户空间则更是群雄并起,LXC,Docker,rkt,LXD,各有拥蹇,鹿死谁手,还真不好说,在这个局还没明朗的时 候,Mesos、Swarm、Kubernetes、Nomad 又出来一堆搅局的,眼下看来最吸引眼球的 Kubernetes 俨然有 OpenStack 继任者的感觉,但依然很嫩,没几个人敢在生产环境大规模使用。 Linux容器里进程的跨机器动态迁移我还没听说,不要说是个服务就得有集群有 HA 嘛,可还真有不少用户一个服务就单机顶着呢,就算有热备或者冷备,在线那台机器内存里的东西可宝贵了,轻易不能丢。用Linux容器就不能挑内核,不能加 载内核模块,不能挂载文件系统,不能调整内核参数,不能改网络配置,等等,不要告诉我你能——你是不是开了 docker run --privileged 了? 你是不是没 drop capability?你是不是没有 remap uid?话说某大公司的容器还真就用 --privileged 选项跑的呢。 而 Linux 的隔离不彻底恐怕大部分人都没意识到,/sys, /dev, /selinux 还有 /proc 下的某些关键文件比如 /proc/kcore 没隔离呢。 Redhat 做的 project Atomic 意识到这些问题,正在积极的给 Docker 加 SELinux 支持,指定 SELinux policy,但 Docker 官方爱搭不理,而且 SELinux 这种高端技术是凡人玩的么? 结局大概依然是 "FAQ 1: 关掉 SELinux"。Linux 容器本来并不局限在一个容器里跑几个进程,但 Docker 官方为了加强“轻量级”这词的洗脑效果,搞出个无比脑残的 single process 理念,被无数人捧臭脚,所幸有些人慢慢意识到问题,Yelp 搞了个 dumb-init 擦了一半屁股,还有无数 docker image 用 runit、supervisor 之类的做 /sbin/init 替换,但问题在于这要自定义启动脚本,需要加 ssh/cron/syslog/logrotate 等等边角料——这已然是解决了无数遍的问题,还要解决一遍,不觉得麻烦吗?难道没有人认为这些包的作者或者打包者更善于处理服务启动脚本么?像 systemd 那种搞法还算正道,特意考虑容器环境,跳过一些步骤,但貌似还没做完善,需要手动删除一些 .service 文件。 虚拟机 vs 容器 也许有人会说 docker pull/push 多方便啊,docker build 多方便啊,可不要忘了,vm image storage 早在 openstack 里就解决了,自己处理也不是个大事,vm image build 也有 Hashicorp 的 Packer 工具代劳,不是个事。Docker 自豪的官方 docker registry 其实大家最多用用 base os image,那些 app 级别的出于信任以及定制考虑都会自己 build。而 Docker 自豪的 layered storage 也是无数血泪,aufs & overlayfs 坑了多少人?容器社区最近还特崇拜 immutable deployment,以把容器根文件系统弄做只读的为荣,全然不管有紧急安全更新或者功能修正怎么处理——什么,你要说 docker rm && docker run 再起一批不就完事么?真有这么简单就好了。 像 Linux kernel 和 git 那种才是正经 unix 设计的思想,分层堆叠,底层提供mechanism,高层提供 policy,各取所需,可惜人总是易于被洗脑,在接受各种高大上policy的时候全然忘了mechanism还在不在自己手里。 回合二:正确性之争 强隔离、full OS 体验、保留 mechanism,这才是正道。另外容器还隐藏了一个坑,/proc/cpuinfo和free命令输出是host os的,这坑了无数探测系统资源自动决定默认线程池和内存池大小的程序,尤以Java最为普遍。 回合三:性能之争 容器粉丝津津乐道——启动容器快,容器的开销少。 这两点确实如此但好处真的有那么巨大么?谁有事没事不停创建虚拟机?谁的虚拟机生命周期平均在分钟级别?谁的“用完全启动时间”平均在秒级? 至于说到虚拟机浪费的资源太多,其实也就是个障眼法。理论上服务器的资源利用率平均不应该超过 80%而实际上绝大部分公司的服务器资源利用率应该都不到 50%,大量的CPU、内存、本地磁盘都是常年浪费的,所以 VM 的额外开销不过是浪费了原本就在浪费的资源罢了。就单机的巅峰 I/O 能力来言,VM 确实不敌容器。但平时根本就用不到巅峰状态, 原本一个 VM 里多进程干的事,非得搞多个容器跑,这容器开销,这人力开销怎么算? 关于容器还有一个幻想,那就是可以在物理机上直接跑容器,开销巨低、管理巨方便,用专用物理机方式提供多租户强隔离。前面两点上面已经驳过了,话说 还有人用 openstack 管理 docker 容器呢。 我只是说一下第三点,在一台物理机上直接跑容器的一个最容易被忽视的问题:现在用来提供云服务的物理机一般都是硬件超级牛逼,跑上百个容器都没问题,但问 题在于用户很可能只需要几个容器,所以要么跟人共用物理机,要么浪费资源白交钱。哪怕用户需要上百个容器,出于容灾考虑,也不可以把上百容器部署到一台物 理机上,所以还是要么跟人共用物理机,要么浪费资源。 方案 以上是我的观点,我并不是“容器黑”,而是“实用白”。AWS、Azure、GCE 都主推在虚拟机上跑容器,按虚拟机收费,这非常明智的解决了问题:老的纯 VM 基础设施不用动,计费照旧,单物理机可以被安全的多租户共用,资源隔离有保证(起码比共享内核强多了),把容器管理软件如“kubernetes”给用 户,既满足用户的容器需求,又不担心容器的多租户问题。 所以我认为:以 VM 为基础,以容器为辅助点,要买就买 VM,自己管理容器,别买 CAAS 直接提供的容器,别看不到底下物理机或者虚拟机。用 VM 还是用容器,冷静考察自己的应用上容器是否有好处。最后,残念,VM 开源管理软件能搞个比 OpenStack 简单的东西吗? (责任编辑:IT) |