CentOS 7 SSH配置免密码登录
时间:2016-05-29 05:01 来源:linux.it.net.cn 作者:IT
目的
在搭建Linux集群服务的时候,主服务器需要启动从服务器的服务,如果通过手动启动,集群内服务器几台还好,要是像阿里1000台的云梯Hadoop集群的话,轨迹启动一次集群就得几个工程师一两天时间,是不是很恐怖。如果使用免密登录,主服务器就能通过程序执行启动脚步,自动帮我们将从服务器的应用启动。而这一切就是建立在ssh服务的免密码登录之上的。所以要学习集群部署,就必须了解linux的免密码登录。
原理
使用一种被称为"公私钥"认证的方式来进行ssh登录. "公私钥"认证方式简单的解释是
首先在客户端上创建一对公私钥 (公钥文件:~/.ssh/id_rsa.pub; 私钥文件:~/.ssh/id_rsa)
然后把公钥放到服务器上(~/.ssh/authorized_keys), 自己保留好私钥
当ssh登录时,ssh程序会发送私钥去和服务器上的公钥做匹配.如果匹配成功就可以登录了
提示(新手必读)
Java代码 
-
(1)配置免登录前,请确保网络环境达到要求(后续内容有详细说明)
-
(2)免登录其实是在本机生成两把锁,一把所谓的公钥是放到要登录的那台服务器上的,其实是一串文本。
-
(3)被登录的服务器上只会有一个公钥文件,叫authorized_keys。如果被登录的服务器有多个客户端要连上来,就会把每个文本密钥存成一行。
-
(4)客户端发送到服务器端的密钥文件一定要放到登录用户主目录的~/.ssh这个隐藏目录下,
-
比如用hadoop用户登录到192.168.102.248服务器,如果hadoop的主目录是/home/hadoop,那么,密钥文件一定是在/home/hadoop/.ssh/下
-
(5)如果直接将authorized_keys的文件从客户端通过scp或者ssh-copy-id方式发送到服务器端,会覆盖原来的文件,对其他用户有影响,所以发送时要进行改名后合并,
配置环境:
(1)服务器IP、名称、网卡信息
3台 Redhat 5.6 linux 64位系统内容如下:
IP地址: 服务器名称 网卡名称 用户名 主目录
192.168.102.247 hadoop1 eth0 hadoop /home/hadoop
192.168.102.248 hadoop2 eth0 hadoop /home/hadoop
192.168.102.249 hadoop3 eth0 hadoop /home/hadoop
配置准备:
(1)添加用户
Java代码
-
1. 以root用户分别登录各服务器。
-
-
2. 执行如下命令,创建用户。
-
useradd -d /home/hadoop -s /bin/bash -m hadoop
-
3. 执行如下命令,为用户“hadoop ”设置密码。
-
passwd hadoop
-
4. 您需要根据系统的提示输入两次密码“aaaa@1111”。
-
-
5. 为“hadoop ”赋予“sudo”权限。
-
a. 执行以下命令,添加“/etc/sudoers”文件的写权限。
-
chmod u+w /etc/sudoers
-
b. 使用vi编辑器,在“/etc/sudoers”文件中“root ALL=(ALL) ALL”后添加语句,如黑体部分 所示。
-
root ALL=(ALL) ALL
-
<strong> hadoop ALL=(ALL) ALL</strong>
-
c. 执行以下命令,删除“/etc/sudoers”文件的写权限。
-
chmod u-w /etc/sudoers
(2)配置网络
(一)修改服务器主机名称 hostname,
以root用户登录,需要修改3个地方,hostname 指令,如果只修改这一处,重启电脑后还是会变回来。/etc/hosts主机文件, 这个地方修改是给 DNS解析用的。单独修改也不行。只有三个地方同时修改才能算修改完成。修改完成后重启服务器。
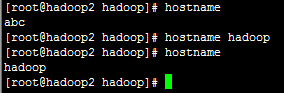
【1】 hostname 指令中修改。
直接输入hostname查看主机名是不是hadoop,如果不是,输入“hostname hadoop” 再输入 “hostname” 进行验证
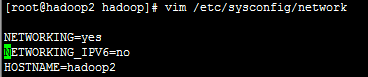
【2】使用 vim /etc/sysconfig/network 修改网络配置中主机名,将修改 HOSTNAME=hadoop
(二)配置IP映射
以root用户登录,依次修改每台服务器的主机信息,通过 vim /etc/hosts修改主机信息,加入主机别名
如果主机IP是192.168.102.247,本机主机名是hadoop1,那么 /etc/hosts 文件的内容应该包含一下内容:
Java代码
-
127.0.0.1 localhost
-
192.168.102.247 hadoop1
-
192.168.102.248 hadoop2
-
192.168.102.249 hadoop3
-
192.168.102.247 localhost
如果主机IP是192.168.102.248,本机主机名是hadoop2,那么 /etc/hosts 文件的内容应该包含一下内容:
Java代码
-
127.0.0.1 localhost
-
192.168.102.247 hadoop1
-
192.168.102.248 hadoop2
-
192.168.102.249 hadoop3
-
192.168.102.248 localhost
如果主机IP是192.168.102.249,本机主机名是hadoop3,那么 /etc/hosts 文件的内容应该包含一下内容:
Java代码
-
127.0.0.1 localhost
-
192.168.102.247 hadoop1
-
192.168.102.248 hadoop2
-
192.168.102.249 hadoop3
-
192.168.102.249 localhost
这里是一个小坑特别说明一下
之前看到网上如下的配置(拿hadoop1举例)
127.0.0.1 hadoop1 localhost
192.168.102.247 hadoop1
192.168.102.248 hadoop2
192.168.102.249 hadoop3
这样会找出造成hadoop集群启动后,集群中只有一个活动的节点,网上查说是
:一个ip对应两个名字,Linux系统应该只采纳排序靠头的记录,当之后有同ip的记录时,估计会抛弃。最后造成一个回环,每 个节点获得namenode的信息都是localhost名字,而具体到各个机器,localhost
反向映射到自己,最后造成集群中一个死路回环。
(三)修改网卡名称 --(可选)
1. 以root用户登录各服务器。
2. 使用vi编辑器,修改“/etc/udev/rules.d/70-persistent-net.rules”文件 --- (如果服务器没有此文件就跳过)。如果是虚拟机,没有此文件,就不用修改 ,主要是修改NAME="eth0"
Java代码
-
# PCI device 0x14e4:0x1713 (tg3)
-
-
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:1e:ec:0f:79:f
-
-
6", ATTR{type}=="1", KERNEL=="eth*", NAME="eth0"
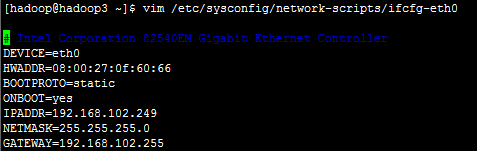
3. 使用vi编辑器,修改“/etc/sysconfig/network-scripts/ifcfg-eth0”文件。
主要是DEVICE=“eth0"
4. 执行reboot命令,重新启动服务器。
5. 执行ifconfig命令,查看网卡名称。
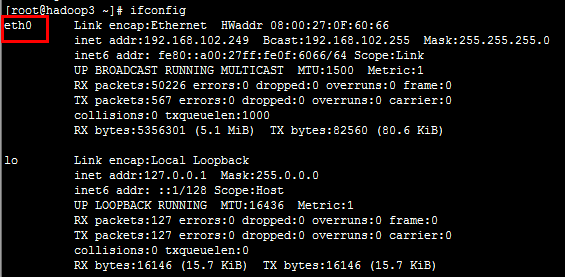
6. 参考“步骤1”至“步骤5”,将所有服务器的网卡名称设置为“eth0”。
配置免登录
(1)创建或者修改密钥目录权限 (此操作在所有服务器完成后再进入下一步)
Java代码
-
假设本机的IP为“192.168.102.247”,配置免登录的操作步骤如下:
-
1. 以hadoop用户登录各服务器。
-
2. 执行以下命令,修改“.ssh 目录”权限。
-
chmod 755 ~/.ssh
-
说明:如果“.ssh”目录不存在,请在/home/hadoop目录执行 mkdir ~/.ssh 命令创建。
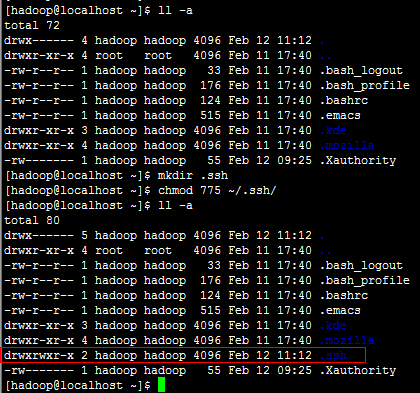
(2)创建公钥和私钥(此操作在所有服务器完成后再进入下一步)
Java代码
-
1. 以hadoop用户登录本机(假设本机的IP为“192.168.102.247”)。
-
-
2. 执行以下命令,进入“.ssh”目录。
-
cd /home/hadoop/.ssh
-
-
3. 执行以下命令后,如果提示,就一直按“Enter”键,直至生成公钥。
-
ssh-keygen -t rsa
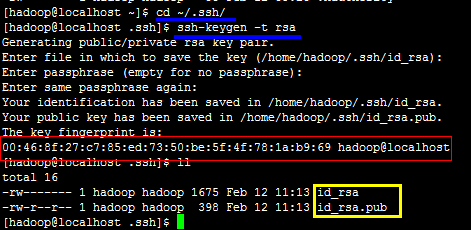
如果创建公钥和私钥后(黄色部分),提示的用户名hadoop@后面不是本机别名(上图红色部分),说明主机名称需要重新配置一次,然后记得重启,然后删除/.ssh目录下的公钥和私钥,重新生成,直到生成的密钥后缀是本机别名.
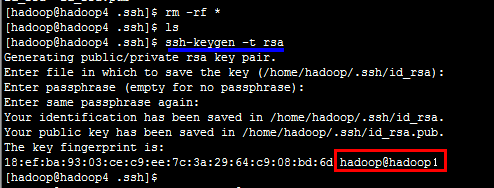
(3)拷贝公钥到服务器(要登录上去的那台服务器)
Java代码
-
1. 执行以下命令(假设本机是192.168.102.247),并根据提示输入登录密码,配置免登录。
-
scp id_rsa.pub hadoop@hadoop2:/home/hadoop/.ssh/authorized_keys_from_hadoop1
-
scp id_rsa.pub hadoop@hadoop2:/home/hadoop/.ssh/authorized_keys_from_hadoop1
-
执行完成后,目标服务器的/home/hadoop/.ssh/目录下就应该有一个authorized_keys_from_hadoop1文件


(4)在被登录的服务器上生成公钥, 公钥合并
Java代码
-
1. 登录到要被登录的服务器()进入./ssh目录
-
cd ~/.ssh
-
2. 将客户端发送来的公钥文件进行合并
-
cat authorized_keys_from_hadoop1 >> authorized_keys
-
说明:如果authorized_keys不存在就会自动创建,如果存在就会追加
-

(5)验证
Java代码
-
* 验证
-
配置免登录完成后,在本机中输入“ssh hadoop@hadoop2” 或者 “ssh hadoop@192.168.102.248” 。
-
* 如果无需输入密码,则表示配置免登录成功。
-
* 如果仍需要输入密码,则可能是.ssh目录和文件权限需要修改。
以下是正常情况:

(6) 目录文件权限修改方法
以root用户登录,依次进入服务器、客户端,执行以下权限修改命令。如果还是不行,请重复 配置免登录操作(需要删除公钥和私钥再做一次)。
Java代码
-
chown hadoop: ~/.ssh
-
chown hadoop: ~/.ssh/*
-
chmod 700 ~/.ssh
-
chmod 600 ~/.ssh/*

修改权限后在登录,就应该能正常了。
(责任编辑:IT)
目的 在搭建Linux集群服务的时候,主服务器需要启动从服务器的服务,如果通过手动启动,集群内服务器几台还好,要是像阿里1000台的云梯Hadoop集群的话,轨迹启动一次集群就得几个工程师一两天时间,是不是很恐怖。如果使用免密登录,主服务器就能通过程序执行启动脚步,自动帮我们将从服务器的应用启动。而这一切就是建立在ssh服务的免密码登录之上的。所以要学习集群部署,就必须了解linux的免密码登录。
原理
提示(新手必读)
Java代码
配置环境: (1)服务器IP、名称、网卡信息 3台 Redhat 5.6 linux 64位系统内容如下: IP地址: 服务器名称 网卡名称 用户名 主目录 192.168.102.247 hadoop1 eth0 hadoop /home/hadoop 192.168.102.248 hadoop2 eth0 hadoop /home/hadoop 192.168.102.249 hadoop3 eth0 hadoop /home/hadoop
配置准备: (1)添加用户
Java代码
(2)配置网络 (一)修改服务器主机名称 hostname, 以root用户登录,需要修改3个地方,hostname 指令,如果只修改这一处,重启电脑后还是会变回来。/etc/hosts主机文件, 这个地方修改是给 DNS解析用的。单独修改也不行。只有三个地方同时修改才能算修改完成。修改完成后重启服务器。 【1】 hostname 指令中修改。 直接输入hostname查看主机名是不是hadoop,如果不是,输入“hostname hadoop” 再输入 “hostname” 进行验证
【2】使用 vim /etc/sysconfig/network 修改网络配置中主机名,将修改 HOSTNAME=hadoop
(二)配置IP映射 以root用户登录,依次修改每台服务器的主机信息,通过 vim /etc/hosts修改主机信息,加入主机别名 如果主机IP是192.168.102.247,本机主机名是hadoop1,那么 /etc/hosts 文件的内容应该包含一下内容:
Java代码
如果主机IP是192.168.102.248,本机主机名是hadoop2,那么 /etc/hosts 文件的内容应该包含一下内容:
Java代码
如果主机IP是192.168.102.249,本机主机名是hadoop3,那么 /etc/hosts 文件的内容应该包含一下内容:
Java代码
这里是一个小坑特别说明一下
之前看到网上如下的配置(拿hadoop1举例) 127.0.0.1 hadoop1 localhost192.168.102.247 hadoop1 192.168.102.248 hadoop2 192.168.102.249 hadoop3
这样会找出造成hadoop集群启动后,集群中只有一个活动的节点,网上查说是
:一个ip对应两个名字,Linux系统应该只采纳排序靠头的记录,当之后有同ip的记录时,估计会抛弃。最后造成一个回环,每 个节点获得namenode的信息都是localhost名字,而具体到各个机器,localhost
(三)修改网卡名称 --(可选)
1. 以root用户登录各服务器。
Java代码
配置免登录 (1)创建或者修改密钥目录权限 (此操作在所有服务器完成后再进入下一步)
Java代码
(2)创建公钥和私钥(此操作在所有服务器完成后再进入下一步)
Java代码
如果创建公钥和私钥后(黄色部分),提示的用户名hadoop@后面不是本机别名(上图红色部分),说明主机名称需要重新配置一次,然后记得重启,然后删除/.ssh目录下的公钥和私钥,重新生成,直到生成的密钥后缀是本机别名.
(3)拷贝公钥到服务器(要登录上去的那台服务器)
Java代码
(4)在被登录的服务器上生成公钥, 公钥合并
Java代码
(5)验证
Java代码
(6) 目录文件权限修改方法 以root用户登录,依次进入服务器、客户端,执行以下权限修改命令。如果还是不行,请重复 配置免登录操作(需要删除公钥和私钥再做一次)。
Java代码
(责任编辑:IT) |