Redis HA方案之sentinel
时间:2016-05-29 23:16 来源:linux.it.net.cn 作者:IT
上一篇研究了redis监控,这一篇来分析redis HA,广泛流传的是keepalived+redis,这个我在分析时有些问题还没搞明白,下一篇会提到,这一篇主要是研究官方的sentinel。
IP 10.20.112.26/27
redis-server 2.6.16
官网:http://redis.io/topics/sentinel
sentinel是一个管理redis实例的工具,它可以实现对redis的监控、通知、自动故障转移。sentinel不断的检测redis实例是否可以正常工作,通过API向其他程序报告redis的状态,如果redis master不能工作,则会自动启动故障转移进程,将其中的一个slave提升为master,其他的slave重新设置新的master服务器。
sentinel是一个分布式系统,在源码包的src目录下会有redis-sentinel命令,其实比较其和redis-server命令的md5sum值,发现是一样的,你可以在多台机器上部署sentinel进程,共同监控redis实例。
redis sentinel 10.20.112.26:26379
redis master 10.20.112.26:6379
redis slave 10.20.112.26:6380
redis slave 10.20.112.27:6379
redis slave 10.20.112.27:6380
部署10.20.112.26,所有redis配置文件在/etc/redis/
redis_6379.conf
daemonize yes
pidfile /var/run/redis_6379.pid
port 6379
bind 0.0.0.0
timeout 0
tcp-keepalive 0
loglevel notice
logfile /var/log/redis_6379.log
databases 16
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename dump_6379.rdb
dir ./
slave-serve-stale-data yes
slave-read-only yes
repl-disable-tcp-nodelay no
slave-priority 100
appendonly no
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
lua-time-limit 5000
slowlog-log-slower-than 10000
slowlog-max-len 128
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-entries 512
list-max-ziplist-value 64
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
activerehashing yes
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
hz 10
aof-rewrite-incremental-fsync yes
redis_6380.conf
###配置和redis_6379.conf大部分一致,只要修改如下几行
pidfile /var/run/redis_6380.pid
port 6380
logfile /var/log/redis_6380.log
dbfilename dump_6380.rdb
sentinel.conf
port 26379
sentinel monitor mymaster 0.0.0.0 6379 1
sentinel down-after-milliseconds mymaster 30000
sentinel can-failover mymaster yes
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 900000
部署完毕后,启动redis实例,三个配置文件中sentinel.conf的配置文件大家不常见,不过里面内容比较少,解释起来很方便,在文章最后面有解释。
部署10.20.112.27
在27上面同样部署redis_6379.conf和redis_6380.conf,方法同26一样,可以在27上部署sentinel,也可以不用部署sentinel,我选择没有部署sentinel。
在10.20.112.26/27上分别执行如下命令:
###10.20.112.26
#终端1
redis-cli -p 6379
#终端2
redis-cli -p 6380
SLAVEOF 10.20.112.26 6379
###10.20.112.27
#终端1
redis-cli -p 6379
SLAVEOF 10.20.112.26 6379
#终端2
redis-cli -p 6380
SLAVEOF 10.20.112.26 6379
在26上执行如下命令:
redis-cli -p 6379 INFO Replication
效果如下:

可以看到有三台slave连接上来。
在27上执行如下命令:
redis-cli -p 6379 INFO Replication
redis-cli -p 6380 INFO Replication
效果如下:

可以看到他们的master都是26的6379
在26上启动sentinel
redis-server sentinel.conf --sentinel
效果如下:

执行如下命令,查看master信息:
redis-cli -h 10.20.112.26 -p 26379 info sentinel
效果如下:

可以看到master的信息及状态。
开始模拟redis master故障,在26上执行如下命令:
redis-cli -p 6379 shutdown
sentinel日志如下:

在27上执行以下命令:
redis-cli -p 6379 info Replication
redis-cli -p 6380 info Replication
结果如下:
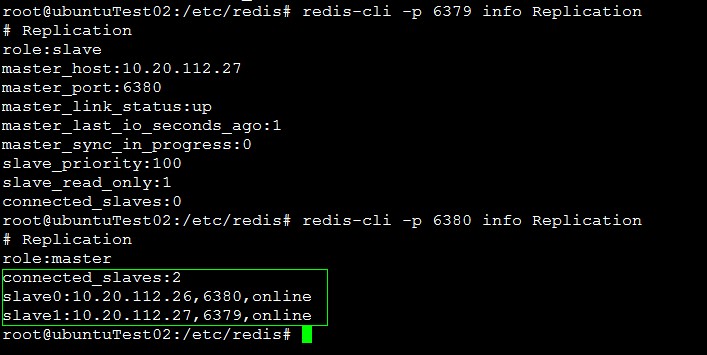
可以看到sentinel选择10.20.112.27的6380为新的redis master。而且其他redis slave已经链接到新的master上面了。
下面我们接着恢复26上面的6379 redis,这时候27的6380是master,26的6380和27的6379作为slave链接到master上面。26执行如下命令:
redis-server redis_6379.conf
sentinel日志如下:

这时候我们在27上看看6379和6380的信息:
redis-cli -p 6379 info Replication
redis-cli -p 6380 info Replication
效果如下:

可以看到新恢复的26的6379并没有恢复到master,而是作为新的slave链接到现有的master上面。
sentinel.conf详解
#sentinel实例监听的端口
port 26379
#告诉sentinel监控这个名为mymaster的master,它的监听地址是127.0.0.1,并且设置failing sentinel为2,表示当有2台sentinel探测到该实例失败时,该实例进入O_DOWN状态。
sentinel monitor mymaster 127.0.0.1 6379 2
#redis实例多少毫秒不可达sentinel,sentinel则认为该实例的状态转变为S_DOWN,但是这个状态还不足以启动automatic failover机制。只有足够多的实例认为该实例是S_DOWN状态,这时该实例进入O_DOWN状态,
sentinel down-after-milliseconds mymaster 30000
#在sentinel检测到O_DOWN后,是否对这台redis启动failover机制
sentinel can-failover mymaster yes
#在failover时,我们可以设置允许多少slave同时可以连接新的master。该值越低,完成failover的进程花费的时间越多,如果对从数据要求不是很及时,你可能不需要所有的从在同一时间同步到新的主(同步到新主,意味着数据重传),你确定在宕机时只有一个从可达则设置为1(如果这样的话其它的从还能用老的数据来干活
sentinel parallel-syncs mymaster 1
#设置failover的超时时间是多少毫秒
sentinel failover-timeout mymaster 900000
redis sentinel在监控redis实例时有两种redis宕机状态S_DOWN和O_DOWN:
S_DOWN:当sentinel在指定的超时时间内没有收到一个正确的ping回复值,则认为是S_DOWN
O_DOWN:O_DOWN的条件是有足够多的sentinel认为该redis实例是S_DOWN。
注意:O_DOWN只能是发生在主服务器,sentinel和其他从服务器不会发生O_DOWN
上面只是简单的试用,sentinel还没合并进稳定版本中,大家可以尝试试用。
(责任编辑:IT)
上一篇研究了redis监控,这一篇来分析redis HA,广泛流传的是keepalived+redis,这个我在分析时有些问题还没搞明白,下一篇会提到,这一篇主要是研究官方的sentinel。 IP 10.20.112.26/27 redis-server 2.6.16 官网:http://redis.io/topics/sentinel sentinel是一个管理redis实例的工具,它可以实现对redis的监控、通知、自动故障转移。sentinel不断的检测redis实例是否可以正常工作,通过API向其他程序报告redis的状态,如果redis master不能工作,则会自动启动故障转移进程,将其中的一个slave提升为master,其他的slave重新设置新的master服务器。 sentinel是一个分布式系统,在源码包的src目录下会有redis-sentinel命令,其实比较其和redis-server命令的md5sum值,发现是一样的,你可以在多台机器上部署sentinel进程,共同监控redis实例。
redis sentinel 10.20.112.26:26379 redis master 10.20.112.26:6379 redis slave 10.20.112.26:6380 redis slave 10.20.112.27:6379 redis slave 10.20.112.27:6380
部署10.20.112.26,所有redis配置文件在/etc/redis/ redis_6379.conf
daemonize yes pidfile /var/run/redis_6379.pid port 6379 bind 0.0.0.0 timeout 0 tcp-keepalive 0 loglevel notice logfile /var/log/redis_6379.log databases 16 save 900 1 save 300 10 save 60 10000 stop-writes-on-bgsave-error yes rdbcompression yes rdbchecksum yes dbfilename dump_6379.rdb dir ./ slave-serve-stale-data yes slave-read-only yes repl-disable-tcp-nodelay no slave-priority 100 appendonly no appendfsync everysec no-appendfsync-on-rewrite no auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb lua-time-limit 5000 slowlog-log-slower-than 10000 slowlog-max-len 128 hash-max-ziplist-entries 512 hash-max-ziplist-value 64 list-max-ziplist-entries 512 list-max-ziplist-value 64 set-max-intset-entries 512 zset-max-ziplist-entries 128 zset-max-ziplist-value 64 activerehashing yes client-output-buffer-limit normal 0 0 0 client-output-buffer-limit slave 256mb 64mb 60 client-output-buffer-limit pubsub 32mb 8mb 60 hz 10 aof-rewrite-incremental-fsync yesredis_6380.conf
###配置和redis_6379.conf大部分一致,只要修改如下几行 pidfile /var/run/redis_6380.pid port 6380 logfile /var/log/redis_6380.log dbfilename dump_6380.rdbsentinel.conf
port 26379 sentinel monitor mymaster 0.0.0.0 6379 1 sentinel down-after-milliseconds mymaster 30000 sentinel can-failover mymaster yes sentinel parallel-syncs mymaster 1 sentinel failover-timeout mymaster 900000 部署完毕后,启动redis实例,三个配置文件中sentinel.conf的配置文件大家不常见,不过里面内容比较少,解释起来很方便,在文章最后面有解释。 部署10.20.112.27 在27上面同样部署redis_6379.conf和redis_6380.conf,方法同26一样,可以在27上部署sentinel,也可以不用部署sentinel,我选择没有部署sentinel。 在10.20.112.26/27上分别执行如下命令:
###10.20.112.26 #终端1 redis-cli -p 6379 #终端2 redis-cli -p 6380 SLAVEOF 10.20.112.26 6379 ###10.20.112.27 #终端1 redis-cli -p 6379 SLAVEOF 10.20.112.26 6379 #终端2 redis-cli -p 6380 SLAVEOF 10.20.112.26 6379在26上执行如下命令:
redis-cli -p 6379 INFO Replication效果如下:
可以看到有三台slave连接上来。 在27上执行如下命令:
redis-cli -p 6379 INFO Replication redis-cli -p 6380 INFO Replication效果如下:
可以看到他们的master都是26的6379 在26上启动sentinel
redis-server sentinel.conf --sentinel效果如下:
执行如下命令,查看master信息:
redis-cli -h 10.20.112.26 -p 26379 info sentinel效果如下:
可以看到master的信息及状态。 开始模拟redis master故障,在26上执行如下命令:
redis-cli -p 6379 shutdownsentinel日志如下:
在27上执行以下命令:
redis-cli -p 6379 info Replication redis-cli -p 6380 info Replication结果如下:
可以看到sentinel选择10.20.112.27的6380为新的redis master。而且其他redis slave已经链接到新的master上面了。
下面我们接着恢复26上面的6379 redis,这时候27的6380是master,26的6380和27的6379作为slave链接到master上面。26执行如下命令:
redis-server redis_6379.confsentinel日志如下:
这时候我们在27上看看6379和6380的信息:
redis-cli -p 6379 info Replication redis-cli -p 6380 info Replication效果如下:
可以看到新恢复的26的6379并没有恢复到master,而是作为新的slave链接到现有的master上面。
sentinel.conf详解
#sentinel实例监听的端口 port 26379 #告诉sentinel监控这个名为mymaster的master,它的监听地址是127.0.0.1,并且设置failing sentinel为2,表示当有2台sentinel探测到该实例失败时,该实例进入O_DOWN状态。 sentinel monitor mymaster 127.0.0.1 6379 2 #redis实例多少毫秒不可达sentinel,sentinel则认为该实例的状态转变为S_DOWN,但是这个状态还不足以启动automatic failover机制。只有足够多的实例认为该实例是S_DOWN状态,这时该实例进入O_DOWN状态, sentinel down-after-milliseconds mymaster 30000 #在sentinel检测到O_DOWN后,是否对这台redis启动failover机制 sentinel can-failover mymaster yes #在failover时,我们可以设置允许多少slave同时可以连接新的master。该值越低,完成failover的进程花费的时间越多,如果对从数据要求不是很及时,你可能不需要所有的从在同一时间同步到新的主(同步到新主,意味着数据重传),你确定在宕机时只有一个从可达则设置为1(如果这样的话其它的从还能用老的数据来干活 sentinel parallel-syncs mymaster 1 #设置failover的超时时间是多少毫秒 sentinel failover-timeout mymaster 900000
redis sentinel在监控redis实例时有两种redis宕机状态S_DOWN和O_DOWN: S_DOWN:当sentinel在指定的超时时间内没有收到一个正确的ping回复值,则认为是S_DOWN
O_DOWN:O_DOWN的条件是有足够多的sentinel认为该redis实例是S_DOWN。
上面只是简单的试用,sentinel还没合并进稳定版本中,大家可以尝试试用。 (责任编辑:IT) |