Redis+Keepalived高可用方案详细分析
时间:2016-05-29 23:16 来源:linux.it.net.cn 作者:IT
上一篇简单的了解了一下redis官方自带的HA方案sentinel,试用发现还是不错的,但是由于还没有合并进稳定分支中,所以在生产环境也不敢使用,还有一个就是需求还暂时不能完全满足,所以就尝试一下redis+keepalived方案,毕竟keepalived现在还是很稳定的,而且资料也充足。
实验环境
ubuntu12.04 10.20.112.26 默认的master
10.20.112.27 默认的slave
VIP 10.20.112.29
redis-server 2.6.16
keepalived默认只能做到对网络故障和keepalived本身的监控,即当出现网络故障或者keepalived本身出现问题时,进行切换。但我们更关注的是机器上运行的业务,如果业务出问题了VIP没有变化,整体来说还是失败的。这时候就需要根据业务进程的运行状态决定是否需要进行主备切换。还好keepalived提供了这样一个自定义脚本监控功能,不过该参数设置在官方默认的文档中并没有出现。
其实文档中有两个我们常用的参数都没有提到:
1 vrrp_script && track_script
vrrp_script代码块是用来定义监控脚本,脚本执行时间间隔以及脚本的执行结果导致优先级变更幅度的。
vrrp_script chk_redis {
script "/etc/keepalived/scripts/redis_check.sh" #指定执行脚本的路径
interval 1 #指定脚本的执行时间间隔
weight 10 #脚本结果导致的优先级变更:10表示优先级+10;-10则表示优先级-10
}
定义好vrrp_script代码块之后,就可以在instance中使用了
track_script {
chk_redis
}
注意:VRRP脚本(vrrp_script)和VRRP实例(vrrp_instance)属于同一个级别
2 notify_stop
keepalived停止运行前运行notify_stop指定的脚本。
配合官方文档提到的以下三个参数一起使用,功能更强大:
notify_master keepalived切换到master时执行的脚本
notify_backup keepalived切换到backup时执行的脚本
notify_fault keepalived出现故障时执行的脚本
3 还有个问题需要注意
当master down了,backup接管了,master再次起来,不能再成为master。否则master恢复了再接管的话,会造成业务来回切换,这时候就需要nopreempt参数了。
nopreempt:设置不抢占,这里只能设置在state为backup的节点上,而且这个节点的优先级必须别另外的高。
先来看看方案的整体思路:
通过keepalived的自定义脚本功能监控本机的redis服务状态,当监控脚本检测到redis服务出现异常时,则改变本机keepalived的优先级,同时这会导致master/backup角色的变化,而keepalived在角色变化时也会触发一些机制执行相关脚本,这就为我们改变redis的master/slave状态提供了机会,这样做的目的是为了是redis的master/slave直接的数据保持一致。
在keepalived+redis的使用过程中有四种情况:
1 一种是keepalived挂了,同时redis也挂了,这样的话直接VIP飘走之后,是不需要进行redis数据同步的,因为redis挂了,你也无法去master上同步,不过会损失已经写在master上却还没同步到slave上面的这部分数据。
2 另一种是keepalived挂了,redis没挂,这时候VIP飘走后,redis的master/slave还是老的对应关系,如果不变化的话会把数据写入redis slave中,从而不会同步到master上去,这就要借助监控脚本反转redis的master/slave关系。这时候就要预留一点时间进行数据同步,然后反转master/slave。
3 还有一种是keepalived没挂,redis挂了,这时候根据监控脚本会检测到redis挂了,并且降低keepalived master的优先级,同样会导致VIP飘走,情况和第二种一样,也是需要进行数据同步,然后反转当前redis的master/slave关系的。
4 随后一种是keepalived没挂,redis也没挂,大吉大利啊,什么都不用操作。
本文的实验环境四种情况都适合,第一种是不需要同步数据的,脚本会默认去同步数据,但是其实是不会成功的。脚本主要是用来处理第二和第三种情况的。
配置10.20.112.26
1 安装keepalived
apt-get install keepalived
2 安装redis
redis是采用源码编译安装的,ubuntu12.04默认自带版本没有这么高,安装过程参照以前文档。
3 配置keepalived
global_defs {
lvs_id LVS_redis
}
vrrp_script chk_redis {
script "/etc/keepalived/scripts/redis_check.sh"
weight -20
interval 2
}
vrrp_instance VI_1 {
state backup
interface eth0
virtual_router_id 51
nopreempt
priority 200
advert_int 5
track_script {
chk_redis
}
virtual_ipaddress {
10.20.112.29
}
notify_master /etc/keepalived/scripts/redis_master.sh
notify_backup /etc/keepalived/scripts/redis_backup.sh
notify_fault /etc/keepalived/scripts/redis_fault.sh
notify_stop /etc/keepalived/scripts/redis_stop.sh
}
4 配置redis,/etc/redis/redis.com
最简单的配置就是把默认配置文件中的bind 127.0.0.1修改为0.0.0.0即可。
5 建立redis状态切换脚本
在/etc/keepalived目录下建立log和scripts目录。
在script下有五个脚本,一个是检测redis状态的redis_check.sh脚本,其余四个是keepalived状态变化时执行的脚本。keepalived有master/backup/stop/fault四种状态,因为我们主要是关注系统上的业务,所以在在keepalived进入fault/stop状态后,也认为是进入了backup状态,需要对redis的master/slave关系进行反转,否则即使VIP漂移过去,但是redis的主从关系还没有改变,会导致数据不一致,所以最终四个脚本只有两种内容。
5.1 redis服务状态检测脚本redis_check.sh(27上面内容和它一样)
#!/bin/bash
###/etc/keepalived/scripts/redis_check.sh
ALIVE=`/usr/bin/redis-cli PING`
if [ "$ALIVE" == "PONG" ]; then
echo $ALIVE
exit 0
else
echo $ALIVE
exit 1
fi
5.2 keepalived进入master状态时的检测脚本redis_master.sh
#!/bin/bash
###/etc/keepalived/scripts/redis_master.sh
REDISCLI="redis-cli"
LOGFILE="/etc/keepalived/log/redis-state.log"
pid=$$
echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[slaver]" >> $LOGFILE
echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[slaver] Run 'SLAVEOF 10.20.112.27 6379'" >> $LOGFILE
$REDISCLI SLAVEOF 10.20.112.27 6379 >> $LOGFILE 2>&1
echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[slaver] wait 10 sec for data sync from old master" >> $LOGFILE
sleep 10
echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[slaver] data rsync from old mater ok..." >> $LOGFILE
echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[master] Run slaveof no one,close master/slave" >> $LOGFILE
$REDISCLI SLAVEOF NO ONE >> $LOGFILE 2>&1
echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[master] wait other slave connect...." >> $LOGFILE
5.3 keepalived进入backup/stop/fault时的检测脚本,由于内容都一致,所以只写出redis_backup.sh
#!/bin/bash
###/etc/keepalived/scripts/redis_backup.sh
REDISCLI="redis-cli"
LOGFILE="/etc/keepalived/log/redis-state.log"
pid=$$
echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[master]" >> $LOGFILE
echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[master] Being slave state..." >> $LOGFILE 2>&1
echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[master] wait 10 sec for data sync from old master" >> $LOGFILE
sleep 10
echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[master] data rsync from old mater ok..." >> $LOGFILE
echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[slaver] Run 'SLAVEOF 10.20.112.27 6379'" >> $LOGFILE
$REDISCLI SLAVEOF 10.20.112.27 6379 >> $LOGFILE 2>&1
echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[slaver] slave connect to 10.20.112.27 ok..." >> $LOGFILE
配置10.20.112.27
1 安装keepalived
2 安装redis
3 配置redis,/etc/redis/redis.com
前面三步骤均一样
4 配置keepalived
global_defs {
lvs_id LVS_redis
}
vrrp_script chk_redis {
script "/etc/keepalived/scripts/redis_check.sh"
weight -20
interval 2
}
vrrp_instance VI_1 {
state backup
interface eth0
virtual_router_id 51
priority 190
advert_int 5
track_script {
chk_redis
}
virtual_ipaddress {
10.20.112.29
}
notify_master /etc/keepalived/scripts/redis_master.sh
notify_backup /etc/keepalived/scripts/redis_backup.sh
notify_fault /etc/keepalived/scripts/redis_fault.sh
notify_stop /etc/keepalived/scripts/redis_stop.sh
}
5 建立redis状态切换脚本
在/etc/keepalived目录下建立log和scripts目录
5.1 redis服务状态检测脚本redis_check.sh(26上面内容和它一样)
5.2 keepalived进入master状态时的检测脚本redis_master.sh
#!/bin/bash
###/etc/keepalived/scripts/redis_master.sh
REDISCLI="/usr/bin/redis-cli"
LOGFILE="/etc/keepalived/log/redis-state.log"
pid=$$
echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[backup]" >> $LOGFILE
echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[backup] Run 'SLAVEOF 10.20.112.26 6379'" >> $LOGFILE
$REDISCLI SLAVEOF 10.20.112.26 6379 >> $LOGFILE 2>&1
echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[backup] wait 10 sec for data sync from old master" >> $LOGFILE
sleep 10
echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[master] data rsync from old mater ok..." >> $LOGFILE
echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[master] Run slaveof no one,close master/slave" >> $LOGFILE
$REDISCLI SLAVEOF NO ONE >> $LOGFILE 2>&1
echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[master] wait other slave connect...." >> $LOGFILE
5.3 keepalived进入backup/stop/fault时的检测脚本,由于内容都一致,所以只写出redis_backup.sh
#!/bin/bash
###/etc/keepalived/scripts/redis_backup.sh
REDISCLI="/usr/bin/redis-cli"
LOGFILE="/etc/keepalived/log/redis-state.log"
pid=$$
echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[master] Being slave state..." >> $LOGFILE 2>&1
echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[master] wait 15 sec for data sync from old master" >> $LOGFILE
sleep 15
echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[master] data rsync from old mater ok..." >> $LOGFILE
echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[slaver] Run 'SLAVEOF 10.20.112.26 6379'" >> $LOGFILE
$REDISCLI SLAVEOF 10.20.112.26 6379 >> $LOGFILE 2>&1
echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[slaver] slave connect to 10.20.112.26 ok..." >> $LOGFILE
下面开始试验
既然我们设置了nopreempt,那么在启动keepalived的时候就有启动的顺序问题了,我们把redis的master和keepalived的master(虽然配置文件中都是backup,但是我们是想让26这台做master的)默认设置在同一台机器上,由于在keepalived的master上面设置了nopreempt参数,所以在启动keepalived服务的时候,一定要先启动redis master的那台,因为在设置了nopreempt了,keepalived在启动后都是先进入backup状态,而脚本又设置了进入backup状态后,会连接新的对方进行数据同步,所以,在启动keepalived之前还有一个条件就是redis的master和slave中的数据必须一致。这样先启动redis的master那台的keepalived,虽然redis master会连接到redis slave同步数据,但是两边数据在刚开始的时候是一致的,并不会产生什么问题。
1 先启动26和27上的redis服务,配置27从26上面同步数据,同步完毕后,取消27的同步机制。
这个就是在27的redis上面执行slaveof 10.20.112.26 6379,等待数据同步完毕后再执行slaveos on one,让26和27的redis都保持master状态
2 接着启动26的keepalived,不要启动27的keepalived,在26和27上面各开启三个终端,观察自定义日志和系统日志状态
26的syslog
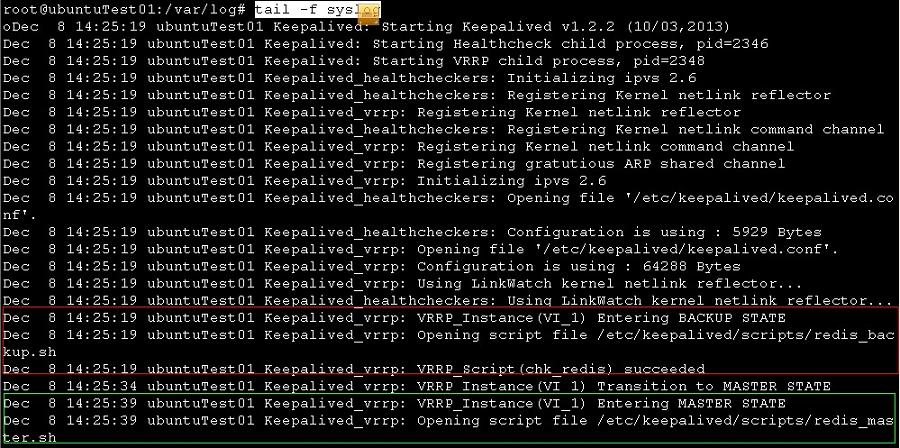
红框 19秒keepalived启动后,由于设置了不抢占,且起始状态都是backup,所以启动后keepalived先进入backup状态,进入bankup状态后,成功的执行了redis_backup.sh脚本
绿框 34秒的时候,keepalived开始向master状态转变,注意:这个时间很重要,为什么是34秒呢?默认是3秒后就开始向master状态转变,由于我们设置了advert_int 5,默认检测三次,所以15秒之后才向master转变,为什么设置间隔这么长时间呢?是为了让redis_backup.sh脚本有充足的时间执行完毕。39秒的时候成功的转变为master状态,这时候会执行redis_master.sh脚本。
26的redis-state.log
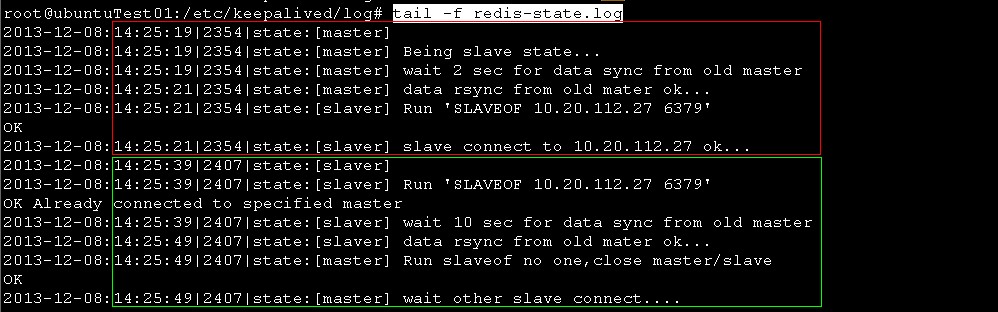
过程解释:
红框 确实如系统日志表现的那样,19秒的时候先进入backup状态,执行redis_backup.sh脚本。redis_backup是keepalived进入到backup状态时执行的脚本。进入到banckup状态,说明自身以前是master状态或者无状态,这时候会等待两秒种,让之前的slave把数据同步完,2秒钟在数据大的时候有些短,其实是可以设置的,只要小于3倍的advert_int时间就行,因为3倍的时间之后会转为master状态的。 2秒钟之后我们的redis连接到27上面(27这时候充当master),开始进行正常的master/slave机制同步数据,也就是红框中21秒的时候。到此为止,redis_backup.sh执行完毕。
绿框 由于设置了不抢占,所以过了3倍的advert_int时间之后,开始向master状态转变,这个转变过程需要的时间是不固定的,在上面的日志中需要5秒,正式的成为master状态,这时候会执行redis_master.sh脚本,脚本指定需要到27的redis上同步数据(27在红框中的时候是充当master的),你可以看到已经有连接了,那是因为在红框中已经连接过一次了,我设置的是同步10秒钟之后断开和27的连接,可以看到49秒的时候执行了slaveof no one命令,断开了和27的连接,把26自身的redis提升为master,这时候数据也是最新的了。
3 待26的各项进程都ok后,我们开始启动27上面的keepalived服务
27的syslog
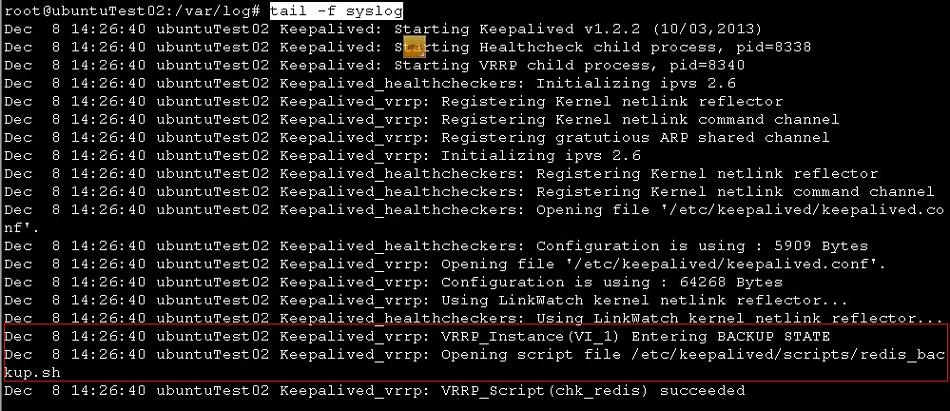
红框 40秒的时候启动27的keepalived,由于默认都是backup,所以直接进入backup状态,由于27的优先级比26低,所以27并不会过度到master状态,这时候26是master状态了。在backup状态执行了redis_backup.sh脚本。
27的redis-state.log

红框 在进入backup状态后,默认之前是master状态或者无状态,所以等待15秒,让26把数据同步完(26这时候充当backup),在15秒之后,开始向backup转变,开始执行slaveof 10.20.112.26 6379,作为26的slave。
下面要模拟故障3:
1 kill掉26的redis进程,保持keepalived进程。(模拟3)
26的syslog
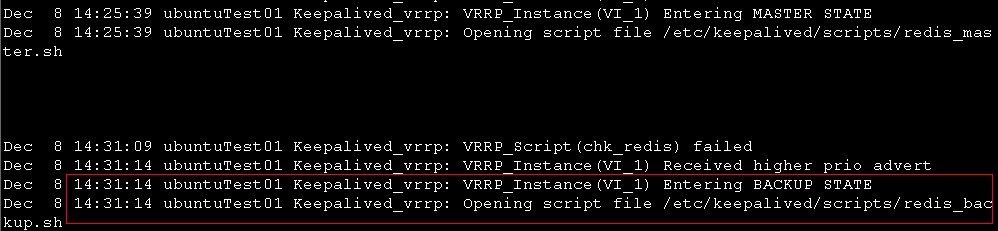
红框 可以看到检测脚本chk_redis发现redis已经宕掉,降低了26的keepalived的优先级,导致26进入backup状态,开始执行redis_backup.sh监控脚本
26的redis-state.log
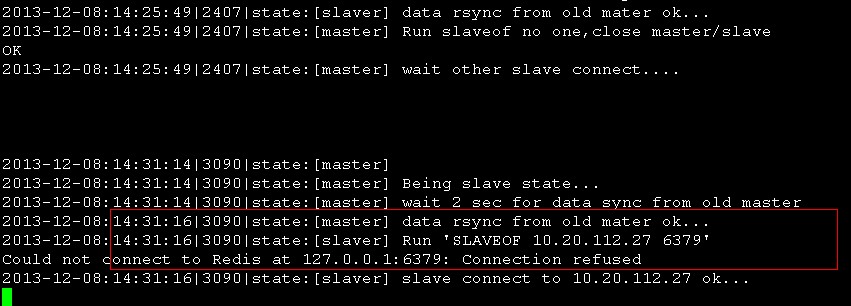
红框 由于redis我是kill掉的,所以必然不能进行数据同步了,不过这并不影响使用。
27的syslog
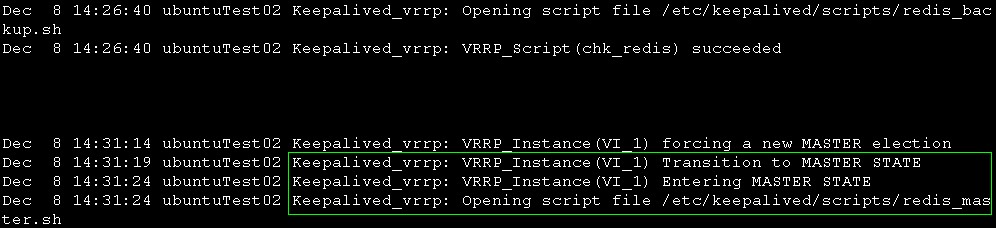
绿框 可以看到27转变到master状态,并且执行了redis_master.sh脚本
27的redis-state.log
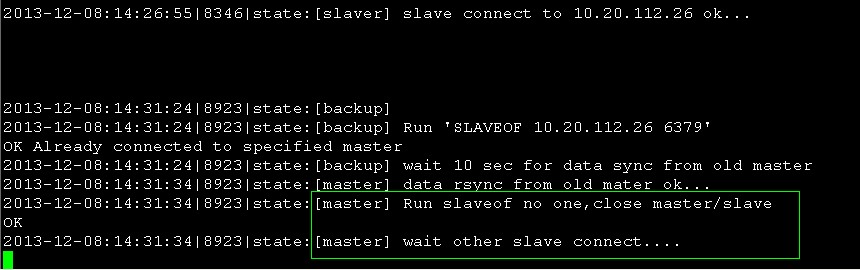
绿框 由于26的redis是kill掉的,所以即使27转变到master状态也不能去26同步数据,当然27也等不到26连接上来,不过并不影响我们使用。
下面要模拟故障2:
2 kill掉26的keepalived进程,保持redis进程。(模拟2)
26的syslog
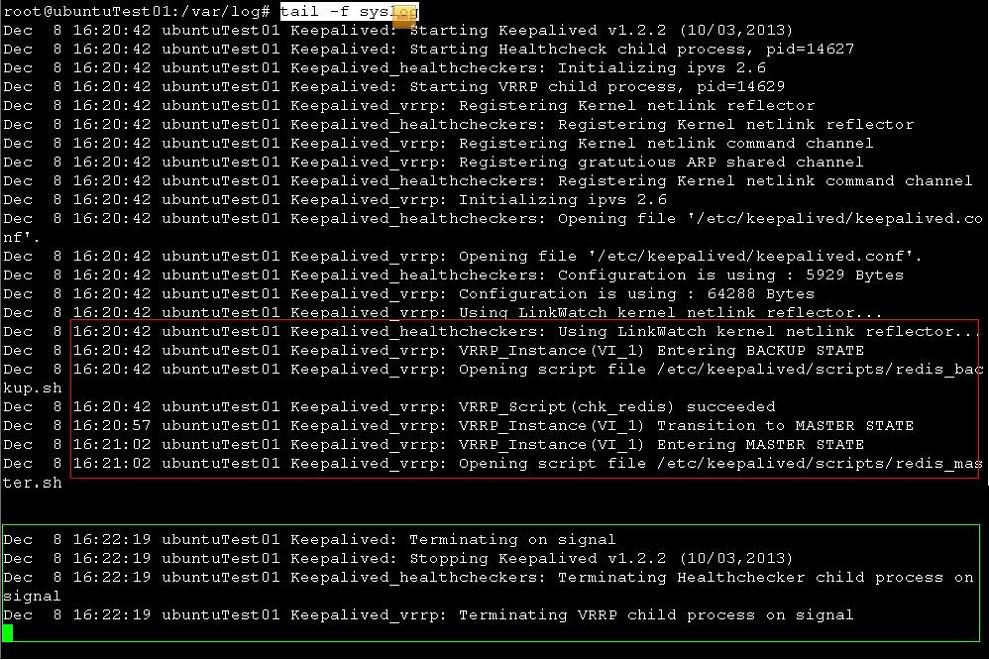
红框 是keepslived的启动过程,在模拟3中已经详细分析过
绿框 是kill掉keepalived进程后的日志。
26的redis-state.log
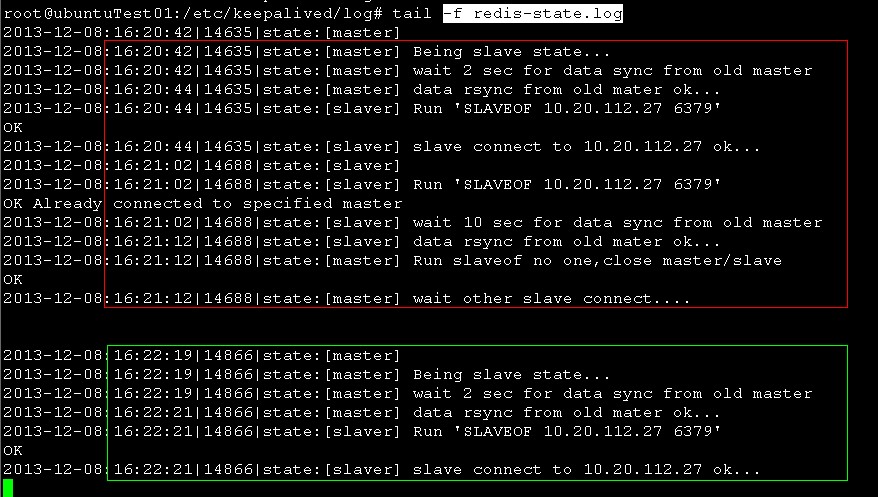
红框 是keepalived启动过程中执行的监控脚本日志,前面模拟3中已经详细分析过
绿框 是keepalived进程kill掉之后,执行的监控脚本日志,在等待27同步完数据后,作为27的slave连接上去。
26的redis info
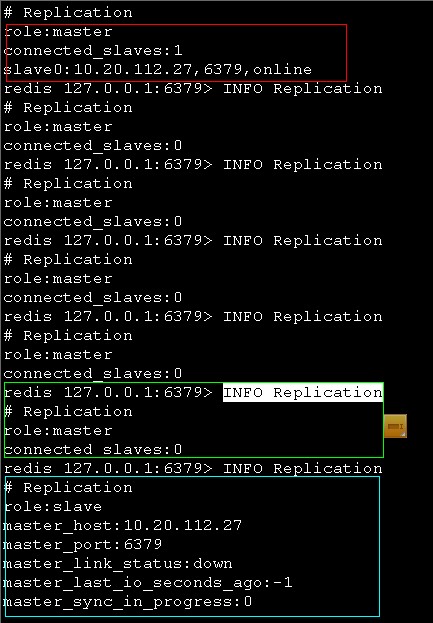
可以看到master/slave的转变过程
27的syslog
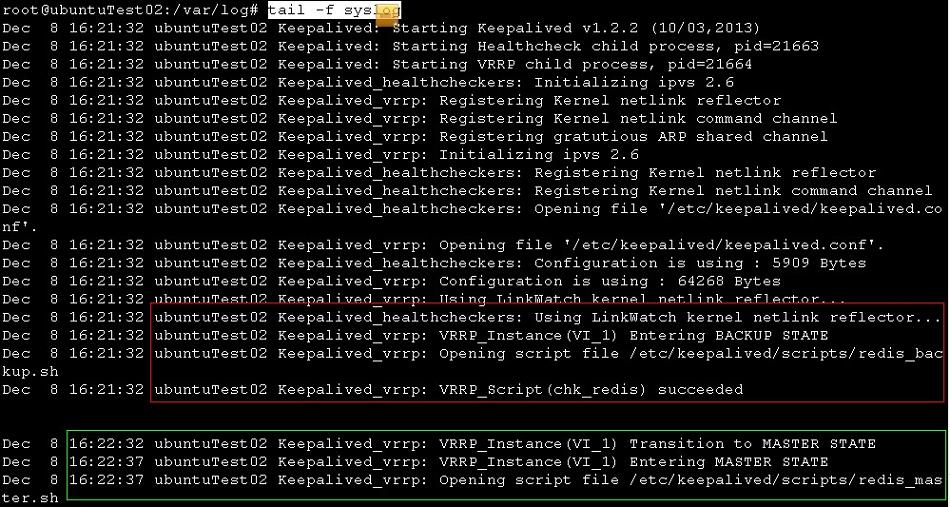
红框 是keepalived作为backup的启动过程,在模拟3中已经分析过。
绿框 是kill掉26的keepalived进程后,27转变为master时的日志,执行了redis_master.sh脚本。
27的redis-state.log
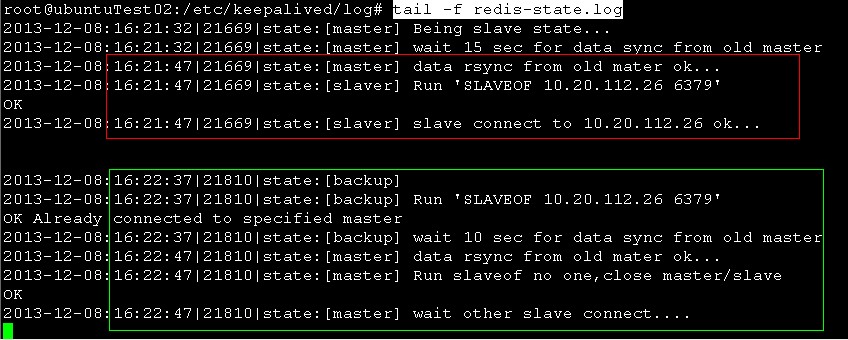
红框 是keepalived启动时执行的监控脚本日志,由于开始是backup的,所以没有过多的状态切换过程。
绿框 是26的keepalived进程被kill掉之后,27转变为master时执行的脚本日志,由于keepalived挂了,但是26的redis进程还在,所以先和26进行数据同步,完成之后再把自己提升为redis master。
27的redis info
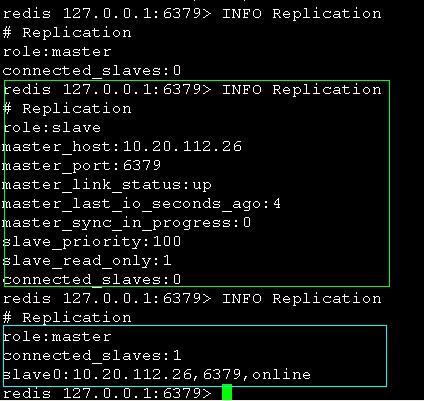
可以看到redis的master/slave变化过程
以上就是我所能想到的keepalived+redis HA方案中需要注意的地方。
(责任编辑:IT)
上一篇简单的了解了一下redis官方自带的HA方案sentinel,试用发现还是不错的,但是由于还没有合并进稳定分支中,所以在生产环境也不敢使用,还有一个就是需求还暂时不能完全满足,所以就尝试一下redis+keepalived方案,毕竟keepalived现在还是很稳定的,而且资料也充足。 实验环境 ubuntu12.04 10.20.112.26 默认的master 10.20.112.27 默认的slave VIP 10.20.112.29 redis-server 2.6.16
keepalived默认只能做到对网络故障和keepalived本身的监控,即当出现网络故障或者keepalived本身出现问题时,进行切换。但我们更关注的是机器上运行的业务,如果业务出问题了VIP没有变化,整体来说还是失败的。这时候就需要根据业务进程的运行状态决定是否需要进行主备切换。还好keepalived提供了这样一个自定义脚本监控功能,不过该参数设置在官方默认的文档中并没有出现。 其实文档中有两个我们常用的参数都没有提到: 1 vrrp_script && track_script vrrp_script代码块是用来定义监控脚本,脚本执行时间间隔以及脚本的执行结果导致优先级变更幅度的。
vrrp_script chk_redis {
script "/etc/keepalived/scripts/redis_check.sh" #指定执行脚本的路径
interval 1 #指定脚本的执行时间间隔
weight 10 #脚本结果导致的优先级变更:10表示优先级+10;-10则表示优先级-10
}
定义好vrrp_script代码块之后,就可以在instance中使用了
track_script {
chk_redis
}
注意:VRRP脚本(vrrp_script)和VRRP实例(vrrp_instance)属于同一个级别 2 notify_stop keepalived停止运行前运行notify_stop指定的脚本。 配合官方文档提到的以下三个参数一起使用,功能更强大:
notify_master keepalived切换到master时执行的脚本 3 还有个问题需要注意 当master down了,backup接管了,master再次起来,不能再成为master。否则master恢复了再接管的话,会造成业务来回切换,这时候就需要nopreempt参数了。 nopreempt:设置不抢占,这里只能设置在state为backup的节点上,而且这个节点的优先级必须别另外的高。
先来看看方案的整体思路: 通过keepalived的自定义脚本功能监控本机的redis服务状态,当监控脚本检测到redis服务出现异常时,则改变本机keepalived的优先级,同时这会导致master/backup角色的变化,而keepalived在角色变化时也会触发一些机制执行相关脚本,这就为我们改变redis的master/slave状态提供了机会,这样做的目的是为了是redis的master/slave直接的数据保持一致。 在keepalived+redis的使用过程中有四种情况: 1 一种是keepalived挂了,同时redis也挂了,这样的话直接VIP飘走之后,是不需要进行redis数据同步的,因为redis挂了,你也无法去master上同步,不过会损失已经写在master上却还没同步到slave上面的这部分数据。 2 另一种是keepalived挂了,redis没挂,这时候VIP飘走后,redis的master/slave还是老的对应关系,如果不变化的话会把数据写入redis slave中,从而不会同步到master上去,这就要借助监控脚本反转redis的master/slave关系。这时候就要预留一点时间进行数据同步,然后反转master/slave。 3 还有一种是keepalived没挂,redis挂了,这时候根据监控脚本会检测到redis挂了,并且降低keepalived master的优先级,同样会导致VIP飘走,情况和第二种一样,也是需要进行数据同步,然后反转当前redis的master/slave关系的。 4 随后一种是keepalived没挂,redis也没挂,大吉大利啊,什么都不用操作。 本文的实验环境四种情况都适合,第一种是不需要同步数据的,脚本会默认去同步数据,但是其实是不会成功的。脚本主要是用来处理第二和第三种情况的。
配置10.20.112.26 1 安装keepalived
apt-get install keepalived2 安装redis redis是采用源码编译安装的,ubuntu12.04默认自带版本没有这么高,安装过程参照以前文档。 3 配置keepalived
global_defs {
lvs_id LVS_redis
}
vrrp_script chk_redis {
script "/etc/keepalived/scripts/redis_check.sh"
weight -20
interval 2
}
vrrp_instance VI_1 {
state backup
interface eth0
virtual_router_id 51
nopreempt
priority 200
advert_int 5
track_script {
chk_redis
}
virtual_ipaddress {
10.20.112.29
}
notify_master /etc/keepalived/scripts/redis_master.sh
notify_backup /etc/keepalived/scripts/redis_backup.sh
notify_fault /etc/keepalived/scripts/redis_fault.sh
notify_stop /etc/keepalived/scripts/redis_stop.sh
}
4 配置redis,/etc/redis/redis.com 最简单的配置就是把默认配置文件中的bind 127.0.0.1修改为0.0.0.0即可。 5 建立redis状态切换脚本 在/etc/keepalived目录下建立log和scripts目录。 在script下有五个脚本,一个是检测redis状态的redis_check.sh脚本,其余四个是keepalived状态变化时执行的脚本。keepalived有master/backup/stop/fault四种状态,因为我们主要是关注系统上的业务,所以在在keepalived进入fault/stop状态后,也认为是进入了backup状态,需要对redis的master/slave关系进行反转,否则即使VIP漂移过去,但是redis的主从关系还没有改变,会导致数据不一致,所以最终四个脚本只有两种内容。 5.1 redis服务状态检测脚本redis_check.sh(27上面内容和它一样)
#!/bin/bash ###/etc/keepalived/scripts/redis_check.sh ALIVE=`/usr/bin/redis-cli PING` if [ "$ALIVE" == "PONG" ]; then echo $ALIVE exit 0 else echo $ALIVE exit 1 fi 5.2 keepalived进入master状态时的检测脚本redis_master.sh
#!/bin/bash ###/etc/keepalived/scripts/redis_master.sh REDISCLI="redis-cli" LOGFILE="/etc/keepalived/log/redis-state.log" pid=$$ echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[slaver]" >> $LOGFILE echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[slaver] Run 'SLAVEOF 10.20.112.27 6379'" >> $LOGFILE $REDISCLI SLAVEOF 10.20.112.27 6379 >> $LOGFILE 2>&1 echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[slaver] wait 10 sec for data sync from old master" >> $LOGFILE sleep 10 echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[slaver] data rsync from old mater ok..." >> $LOGFILE echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[master] Run slaveof no one,close master/slave" >> $LOGFILE $REDISCLI SLAVEOF NO ONE >> $LOGFILE 2>&1 echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[master] wait other slave connect...." >> $LOGFILE 5.3 keepalived进入backup/stop/fault时的检测脚本,由于内容都一致,所以只写出redis_backup.sh
#!/bin/bash ###/etc/keepalived/scripts/redis_backup.sh REDISCLI="redis-cli" LOGFILE="/etc/keepalived/log/redis-state.log" pid=$$ echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[master]" >> $LOGFILE echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[master] Being slave state..." >> $LOGFILE 2>&1 echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[master] wait 10 sec for data sync from old master" >> $LOGFILE sleep 10 echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[master] data rsync from old mater ok..." >> $LOGFILE echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[slaver] Run 'SLAVEOF 10.20.112.27 6379'" >> $LOGFILE $REDISCLI SLAVEOF 10.20.112.27 6379 >> $LOGFILE 2>&1 echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[slaver] slave connect to 10.20.112.27 ok..." >> $LOGFILE 配置10.20.112.27 1 安装keepalived 2 安装redis 3 配置redis,/etc/redis/redis.com 前面三步骤均一样 4 配置keepalived
global_defs {
lvs_id LVS_redis
}
vrrp_script chk_redis {
script "/etc/keepalived/scripts/redis_check.sh"
weight -20
interval 2
}
vrrp_instance VI_1 {
state backup
interface eth0
virtual_router_id 51
priority 190
advert_int 5
track_script {
chk_redis
}
virtual_ipaddress {
10.20.112.29
}
notify_master /etc/keepalived/scripts/redis_master.sh
notify_backup /etc/keepalived/scripts/redis_backup.sh
notify_fault /etc/keepalived/scripts/redis_fault.sh
notify_stop /etc/keepalived/scripts/redis_stop.sh
}
5 建立redis状态切换脚本 在/etc/keepalived目录下建立log和scripts目录 5.1 redis服务状态检测脚本redis_check.sh(26上面内容和它一样) 5.2 keepalived进入master状态时的检测脚本redis_master.sh
#!/bin/bash ###/etc/keepalived/scripts/redis_master.sh REDISCLI="/usr/bin/redis-cli" LOGFILE="/etc/keepalived/log/redis-state.log" pid=$$ echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[backup]" >> $LOGFILE echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[backup] Run 'SLAVEOF 10.20.112.26 6379'" >> $LOGFILE $REDISCLI SLAVEOF 10.20.112.26 6379 >> $LOGFILE 2>&1 echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[backup] wait 10 sec for data sync from old master" >> $LOGFILE sleep 10 echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[master] data rsync from old mater ok..." >> $LOGFILE echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[master] Run slaveof no one,close master/slave" >> $LOGFILE $REDISCLI SLAVEOF NO ONE >> $LOGFILE 2>&1 echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[master] wait other slave connect...." >> $LOGFILE 5.3 keepalived进入backup/stop/fault时的检测脚本,由于内容都一致,所以只写出redis_backup.sh
#!/bin/bash ###/etc/keepalived/scripts/redis_backup.sh REDISCLI="/usr/bin/redis-cli" LOGFILE="/etc/keepalived/log/redis-state.log" pid=$$ echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[master] Being slave state..." >> $LOGFILE 2>&1 echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[master] wait 15 sec for data sync from old master" >> $LOGFILE sleep 15 echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[master] data rsync from old mater ok..." >> $LOGFILE echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[slaver] Run 'SLAVEOF 10.20.112.26 6379'" >> $LOGFILE $REDISCLI SLAVEOF 10.20.112.26 6379 >> $LOGFILE 2>&1 echo "`date +'%Y-%m-%d:%H:%M:%S'`|$pid|state:[slaver] slave connect to 10.20.112.26 ok..." >> $LOGFILE
下面开始试验 既然我们设置了nopreempt,那么在启动keepalived的时候就有启动的顺序问题了,我们把redis的master和keepalived的master(虽然配置文件中都是backup,但是我们是想让26这台做master的)默认设置在同一台机器上,由于在keepalived的master上面设置了nopreempt参数,所以在启动keepalived服务的时候,一定要先启动redis master的那台,因为在设置了nopreempt了,keepalived在启动后都是先进入backup状态,而脚本又设置了进入backup状态后,会连接新的对方进行数据同步,所以,在启动keepalived之前还有一个条件就是redis的master和slave中的数据必须一致。这样先启动redis的master那台的keepalived,虽然redis master会连接到redis slave同步数据,但是两边数据在刚开始的时候是一致的,并不会产生什么问题。 1 先启动26和27上的redis服务,配置27从26上面同步数据,同步完毕后,取消27的同步机制。 这个就是在27的redis上面执行slaveof 10.20.112.26 6379,等待数据同步完毕后再执行slaveos on one,让26和27的redis都保持master状态 2 接着启动26的keepalived,不要启动27的keepalived,在26和27上面各开启三个终端,观察自定义日志和系统日志状态 26的syslog
红框 19秒keepalived启动后,由于设置了不抢占,且起始状态都是backup,所以启动后keepalived先进入backup状态,进入bankup状态后,成功的执行了redis_backup.sh脚本 绿框 34秒的时候,keepalived开始向master状态转变,注意:这个时间很重要,为什么是34秒呢?默认是3秒后就开始向master状态转变,由于我们设置了advert_int 5,默认检测三次,所以15秒之后才向master转变,为什么设置间隔这么长时间呢?是为了让redis_backup.sh脚本有充足的时间执行完毕。39秒的时候成功的转变为master状态,这时候会执行redis_master.sh脚本。 26的redis-state.log
过程解释: 红框 确实如系统日志表现的那样,19秒的时候先进入backup状态,执行redis_backup.sh脚本。redis_backup是keepalived进入到backup状态时执行的脚本。进入到banckup状态,说明自身以前是master状态或者无状态,这时候会等待两秒种,让之前的slave把数据同步完,2秒钟在数据大的时候有些短,其实是可以设置的,只要小于3倍的advert_int时间就行,因为3倍的时间之后会转为master状态的。 2秒钟之后我们的redis连接到27上面(27这时候充当master),开始进行正常的master/slave机制同步数据,也就是红框中21秒的时候。到此为止,redis_backup.sh执行完毕。 绿框 由于设置了不抢占,所以过了3倍的advert_int时间之后,开始向master状态转变,这个转变过程需要的时间是不固定的,在上面的日志中需要5秒,正式的成为master状态,这时候会执行redis_master.sh脚本,脚本指定需要到27的redis上同步数据(27在红框中的时候是充当master的),你可以看到已经有连接了,那是因为在红框中已经连接过一次了,我设置的是同步10秒钟之后断开和27的连接,可以看到49秒的时候执行了slaveof no one命令,断开了和27的连接,把26自身的redis提升为master,这时候数据也是最新的了。 3 待26的各项进程都ok后,我们开始启动27上面的keepalived服务 27的syslog
红框 40秒的时候启动27的keepalived,由于默认都是backup,所以直接进入backup状态,由于27的优先级比26低,所以27并不会过度到master状态,这时候26是master状态了。在backup状态执行了redis_backup.sh脚本。 27的redis-state.log
红框 在进入backup状态后,默认之前是master状态或者无状态,所以等待15秒,让26把数据同步完(26这时候充当backup),在15秒之后,开始向backup转变,开始执行slaveof 10.20.112.26 6379,作为26的slave。
下面要模拟故障3: 1 kill掉26的redis进程,保持keepalived进程。(模拟3) 26的syslog
红框 可以看到检测脚本chk_redis发现redis已经宕掉,降低了26的keepalived的优先级,导致26进入backup状态,开始执行redis_backup.sh监控脚本 26的redis-state.log
红框 由于redis我是kill掉的,所以必然不能进行数据同步了,不过这并不影响使用。 27的syslog
绿框 可以看到27转变到master状态,并且执行了redis_master.sh脚本 27的redis-state.log
绿框 由于26的redis是kill掉的,所以即使27转变到master状态也不能去26同步数据,当然27也等不到26连接上来,不过并不影响我们使用。 下面要模拟故障2: 2 kill掉26的keepalived进程,保持redis进程。(模拟2) 26的syslog
红框 是keepslived的启动过程,在模拟3中已经详细分析过 绿框 是kill掉keepalived进程后的日志。 26的redis-state.log
红框 是keepalived启动过程中执行的监控脚本日志,前面模拟3中已经详细分析过 绿框 是keepalived进程kill掉之后,执行的监控脚本日志,在等待27同步完数据后,作为27的slave连接上去。 26的redis info
可以看到master/slave的转变过程 27的syslog
红框 是keepalived作为backup的启动过程,在模拟3中已经分析过。 绿框 是kill掉26的keepalived进程后,27转变为master时的日志,执行了redis_master.sh脚本。 27的redis-state.log
红框 是keepalived启动时执行的监控脚本日志,由于开始是backup的,所以没有过多的状态切换过程。 绿框 是26的keepalived进程被kill掉之后,27转变为master时执行的脚本日志,由于keepalived挂了,但是26的redis进程还在,所以先和26进行数据同步,完成之后再把自己提升为redis master。 27的redis info
可以看到redis的master/slave变化过程
以上就是我所能想到的keepalived+redis HA方案中需要注意的地方。 (责任编辑:IT) |