Redis Cluster
时间:2016-05-29 23:19 来源:linux.it.net.cn 作者:IT
公司以一种错误的姿势使用了redis的功能,而且业务框架已经变得很大,虽然大家也都认为不合理,但是暂时看不到重构希望,可苦逼了后端人员,索性看看redis cluster能不能解决我的顾虑,redis 3出来也一段时间了,网上的文章也很多了,生产上大规模使用的公司不多,而且因为要对cluster的支持,导致很多原有lib库都无法使用了,不过这并不妨碍我们追索知识的步伐....
Redis很早的时候已经提供了Master-Slave功能,直到3.0版本的时候才提供了cluster功能,还是alpha版本,cluster并不支持多个键的操作,这样会导致需要在多个节点间移动数据,因为cluster中数据是被自动的分配到多个redis节点的。在cluster中部分节点出现不可用的时候,cluster还是可以继续提供正常服务的(当然要看你的集群配置)。
下面聊聊关于redis cluster的一些信息,每个在cluster中的redis节点都会监听两个端口,一个是和客户端通讯的TCP端口(6379),一个是用作cluster内部数据传输的,比如错误检测、cluster配置更新、故障转移等等(16379)。这样cluster的通讯问题就解决了,但数据是怎么在cluster中存放的?redis cluster没有采用一致性哈希,而是采用hash slot 。一个redis cluster有固定的16384个hash slot,这么多slot被均匀的分配到cluster中的master节点上,而一个key具体的存储在哪个slot上,则是通过key的CRC16编码对16384取模得出的。上面提到了cluster中的master节点,估计很多人就迷糊了,为了当部分节点失效时,cluster仍能保持可用,Redis 集群采用每个节点拥有 1(主服务自身)到 N 个副本(N-1 个附加的从服务器)的主从模型。是不是和master/slave很像。但是redis cluster却不是强一致性的,在一定的条件下,cluster可能会丢失一些写入的请求命令,因为cluster内部master和slave之间的数据是异步复制的,比如你给master中写入数据,返回ok,但是这时候该数据并不一定就完全的同步到slave上了(采用异步主要是提高性能,主要是在性能和一致性间的一个平衡),如果这时候master宕机了,这部分没有写入slave的数据就丢失了,不过这种可能性还是很小的。上面这些信息都来自官方解释,只是大概的描述了redis cluster的一些基本信息。
。一个redis cluster有固定的16384个hash slot,这么多slot被均匀的分配到cluster中的master节点上,而一个key具体的存储在哪个slot上,则是通过key的CRC16编码对16384取模得出的。上面提到了cluster中的master节点,估计很多人就迷糊了,为了当部分节点失效时,cluster仍能保持可用,Redis 集群采用每个节点拥有 1(主服务自身)到 N 个副本(N-1 个附加的从服务器)的主从模型。是不是和master/slave很像。但是redis cluster却不是强一致性的,在一定的条件下,cluster可能会丢失一些写入的请求命令,因为cluster内部master和slave之间的数据是异步复制的,比如你给master中写入数据,返回ok,但是这时候该数据并不一定就完全的同步到slave上了(采用异步主要是提高性能,主要是在性能和一致性间的一个平衡),如果这时候master宕机了,这部分没有写入slave的数据就丢失了,不过这种可能性还是很小的。上面这些信息都来自官方解释,只是大概的描述了redis cluster的一些基本信息。
其实个人觉得redis之前也有单独的数据分片功能和主从功能,cluster只是把这些功能合并在一起,外加一些集群的状态检测。下面看看redis cluster的集群架构图:
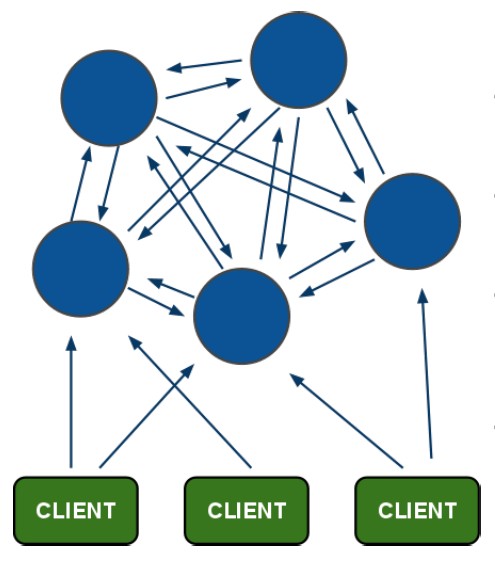
客户端连接在cluster中的任何一个节点上都可以获取到其他节点的数据,不过这幅图看着有点乱,一般cluster内部不会这么多节点互为主从的。
下面我们简单的使用一下,操作系统是一台ubuntu14.04系统(启动6个实例,3 Master/3 Slave):
1 下载最新版redis
wget 'http://download.redis.io/releases/redis-3.0.4.tar.gz'
2 编译安装
#安装到/opt/redis-cluster目录
tar zxvf redis-3.0.4.tar.gz
cd redis-3.0.4/
make
make PREFIX=/opt/redis-cluster install
#创建配置目录,拷贝相关文件
mkdir /opt/redis-cluster/{log conf rdb run}
cp src/redis-trib.rb /opt/redis-cluster/bin/
3 安装其他依赖包
apt-get install ruby1.9.1
gem install redis
4 创建配置文件

看看6379的具体信息:grep -v -E '(^#|^$)' redis-6379.conf
daemonize yes
pidfile /opt/redis-cluster/run/redis-6379.pid
port 6379
tcp-backlog 511
timeout 0
tcp-keepalive 0
loglevel notice
logfile "/opt/redis-cluster/log/redis-6379.log"
databases 16
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename dump-6379.rdb
dir /opt/redis-cluster/rdb
slave-serve-stale-data yes
slave-read-only yes
repl-diskless-sync no
repl-diskless-sync-delay 5
repl-disable-tcp-nodelay no
slave-priority 100
appendonly yes
appendfilename "redis-6379.aof"
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
lua-time-limit 5000
cluster-enabled yes
cluster-config-file nodes-6379.conf
cluster-node-timeout 15000
slowlog-log-slower-than 10000
slowlog-max-len 128
latency-monitor-threshold 0
notify-keyspace-events ""
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-entries 512
list-max-ziplist-value 64
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
hll-sparse-max-bytes 3000
activerehashing yes
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
hz 10
aof-rewrite-incremental-fsync yes
其实大部分都是原有的配置信息,不需要做大的改动,与端口相关的都需要调整,与集群相关的配置如下:
cluster-enabled yes
cluster-config-file nodes-6379.conf
cluster-node-timeout 15000
注意其中的nodes-6379.conf这个文件不需要创建,在初始化集群的时候会自动创建的。
5 在启动redis实例前先修改一些系统级别的配置
echo never > /sys/kernel/mm/transparent_hugepage/enabled
# 打开/etc/sysctl.conf,追加如下内容
vm.overcommit_memory = 1
#使配置生效
sysctl -p
6 启动所有redis实例
cd /opt/redis-cluster/bin
./redis-server /opt/redis-cluster/conf/redis-6379.conf
./redis-server /opt/redis-cluster/conf/redis-6380.conf
./redis-server /opt/redis-cluster/conf/redis-6381.conf
./redis-server /opt/redis-cluster/conf/redis-7379.conf
./redis-server /opt/redis-cluster/conf/redis-7380.conf
./redis-server /opt/redis-cluster/conf/redis-7381.conf
7 redis-trib.rb
redis-trib.rb是一个官方提供的用来操作cluster的ruby脚本,我们后面管理cluster会经常使用到这个脚本
Usage: redis-trib <command> <options> <arguments ...>
create host1:port1 ... hostN:portN
--replicas <arg>
check host:port
fix host:port
reshard host:port
--from <arg>
--to <arg>
--slots <arg>
--yes
add-node new_host:new_port existing_host:existing_port
--slave
--master-id <arg>
del-node host:port node_id
set-timeout host:port milliseconds
call host:port command arg arg .. arg
import host:port
--from <arg>
help (show this help)
For check, fix, reshard, del-node, set-timeout you can specify the host and port of any working node in the cluster.
8 初始化启动cluster
./redis-trib.rb create --replicas 1 172.16.1.100:6379 172.16.1.100:6380 172.16.1.100:6381 172.16.1.100:7379 172.16.1.100:7380 172.16.1.100:7381
结果如下:
>>> Creating cluster
Connecting to node 172.16.1.100:6379: OK
Connecting to node 172.16.1.100:6380: OK
Connecting to node 172.16.1.100:6381: OK
Connecting to node 172.16.1.100:7379: OK
Connecting to node 172.16.1.100:7380: OK
Connecting to node 172.16.1.100:7381: OK
>>> Performing hash slots allocation on 6 nodes...
Using 3 masters: ###注意三个6xxx的都被定义为master的了
172.16.1.100:6379
172.16.1.100:6380
172.16.1.100:6381
Adding replica 172.16.1.100:7379 to 172.16.1.100:6379 ###注意三个7xxx的都被定义为相关的slave了
Adding replica 172.16.1.100:7380 to 172.16.1.100:6380
Adding replica 172.16.1.100:7381 to 172.16.1.100:6381
M: cdb8b1fe29feb9a564fbfed6599aa61dda250eb1 172.16.1.100:6379
slots:0-5460 (5461 slots) master ###6379被分配了0-5460个slots
M: a188b59b30056f61c1cf55ff5072d60b6f8ce5d7 172.16.1.100:6380
slots:5461-10922 (5462 slots) master ###6380被分配了5461-10922个slots
M: fada90b0520d5aa3305bc89651cc7bb5de9b2a16 172.16.1.100:6381
slots:10923-16383 (5461 slots) master ###6381被分配了10923-16383个slots
S: 818fb192631cf8c34bc58f24d2538444abe7d995 172.16.1.100:7379 ###剩余的三个slave
replicates cdb8b1fe29feb9a564fbfed6599aa61dda250eb1
S: 1cf6ed9f8a5049513fb631e78207c7f0b1ba6674 172.16.1.100:7380
replicates a188b59b30056f61c1cf55ff5072d60b6f8ce5d7
S: bc09734e243b9b2e9fe2f64c55aaf72073c6918b 172.16.1.100:7381
replicates fada90b0520d5aa3305bc89651cc7bb5de9b2a16
Can I set the above configuration? (type 'yes' to accept): yes ###是否在nodes配置文件中保存更新配置
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join.....
>>> Performing Cluster Check (using node 172.16.1.100:6379)
M: cdb8b1fe29feb9a564fbfed6599aa61dda250eb1 172.16.1.100:6379
slots:0-5460 (5461 slots) master
M: a188b59b30056f61c1cf55ff5072d60b6f8ce5d7 172.16.1.100:6380
slots:5461-10922 (5462 slots) master
M: fada90b0520d5aa3305bc89651cc7bb5de9b2a16 172.16.1.100:6381
slots:10923-16383 (5461 slots) master
M: 818fb192631cf8c34bc58f24d2538444abe7d995 172.16.1.100:7379
slots: (0 slots) master
replicates cdb8b1fe29feb9a564fbfed6599aa61dda250eb1
M: 1cf6ed9f8a5049513fb631e78207c7f0b1ba6674 172.16.1.100:7380
slots: (0 slots) master
replicates a188b59b30056f61c1cf55ff5072d60b6f8ce5d7
M: bc09734e243b9b2e9fe2f64c55aaf72073c6918b 172.16.1.100:7381
slots: (0 slots) master
replicates fada90b0520d5aa3305bc89651cc7bb5de9b2a16
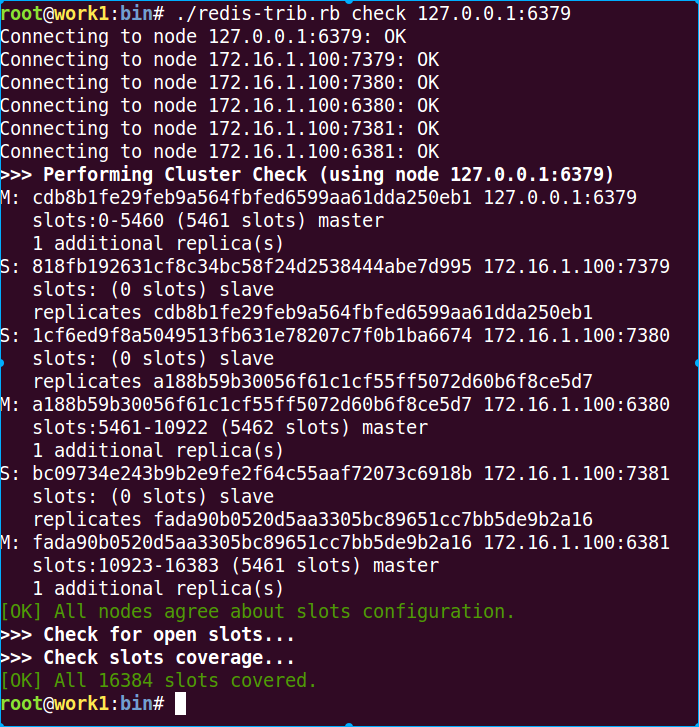
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
检查一下cluster的状态:redis-trib.rb check 127.0.0.1:6379
9 接入cluster,并存入一个key/value (name/guo)
redis-cli -c -h 127.0.0.1 -p 6379
注意:redis-cli在接入集群模式时,要使用-c参数
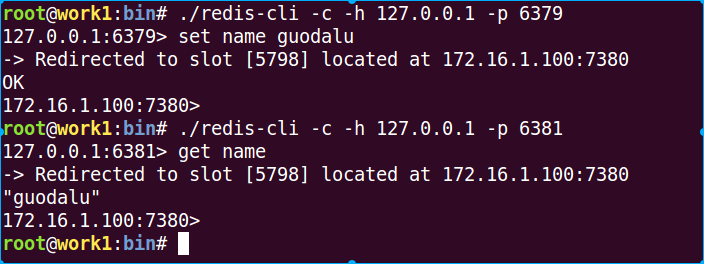
可以看到我在6379接入cluster中,并存入可一个name/guodalu键值对,但是cluster却把我保存的值定位到7380去了,而我使用6381接入cluster中后,再次获取name值时,会被自动的定位到7380上。我们来看看是我是怎么被定位到7380的。
1 先计算guodalu的CRC16值是0xA36B,转化成10进制是41835
2 41835对16384取模是9067,9067 slot是落在6380上的,而7380是6380的slave。
下面我们把7380停止,可以看到再次检查cluster的时候,并不会报错。
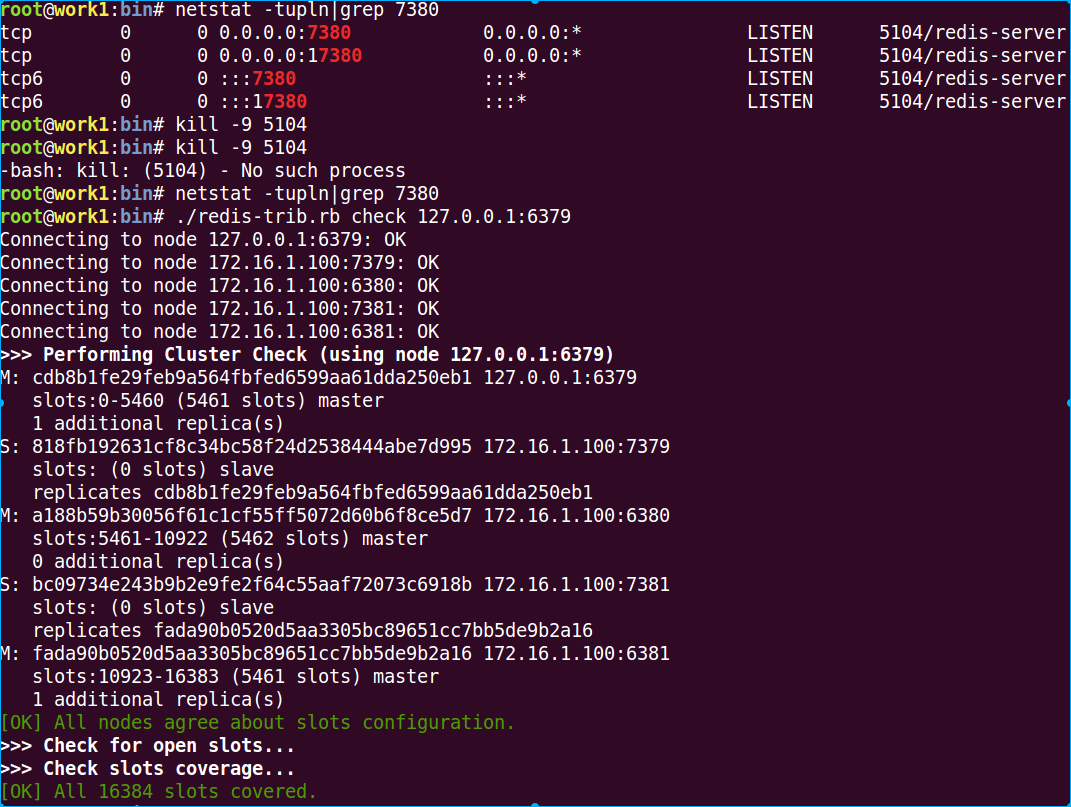
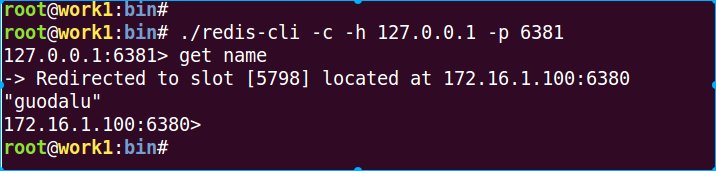
我们在6381上接入cluster,获取name
10 恢复7380,停止6380
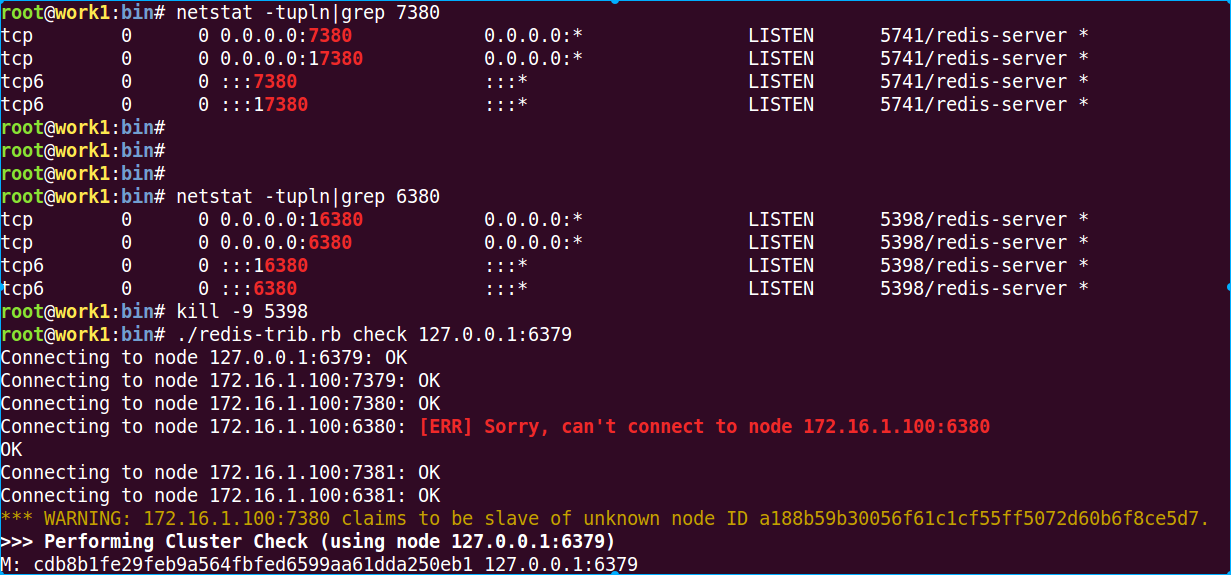
可以看到这时候check cluster的时候,会提示一个节点已经故障,我们这时候再尝试获取key
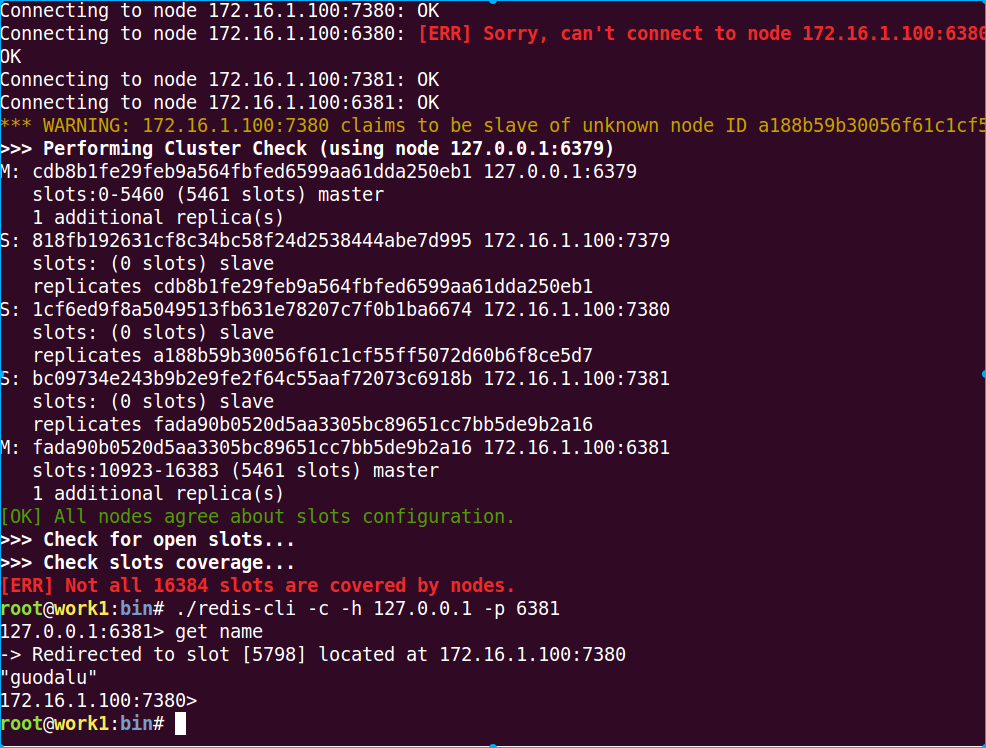
可以看到还是可以获取到的。如果把6380和7380同时停止呢?
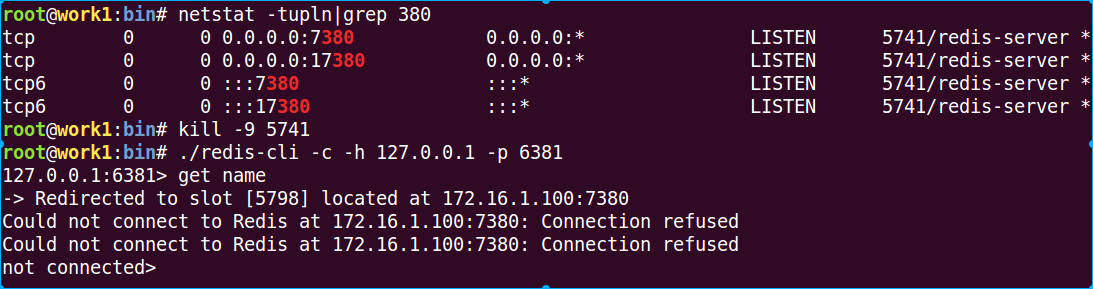
如果cluster中的master和slave全部故障的话,则这部分数据还是不可用的。
11 在cluster中新增一个redis master节点
启动redis 8379实例
./redis-server /opt/redis-cluster/conf/redis-8379.conf
然后把该实例加入cluster中:第一个参数是新加入的redis节点,第二个参数是cluster中的任何一个已有的节点
./redis-trib.rb add-node 127.0.0.1:8379 127.0.0.1:6379
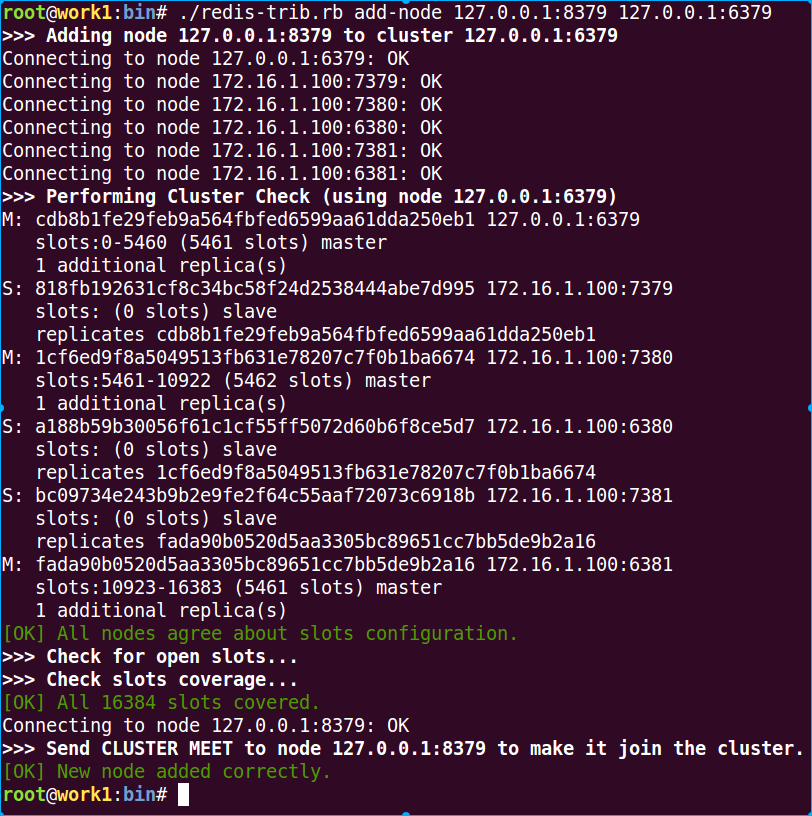
这时候检查一下cluster状态
./redis-trib.rb check 127.0.0.1:6379
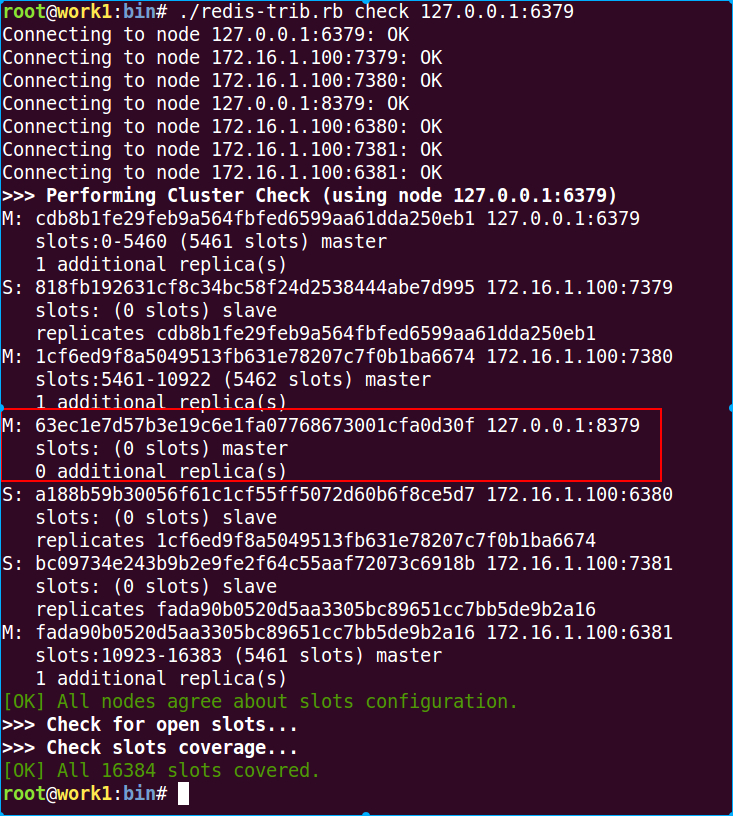
可以看到8379已经加入cluster中了,默认是以master加入cluster的,而且副本为1,但是这个新的master却没有被cluster分配slots,所以它里面是没有数据的,当有slave服务器要升级为master服务器时,它不能参与选举。这时候我们可以使用重新划分slots的特性给新加入的8379迁移其他节点上的slots,这个后面操作。
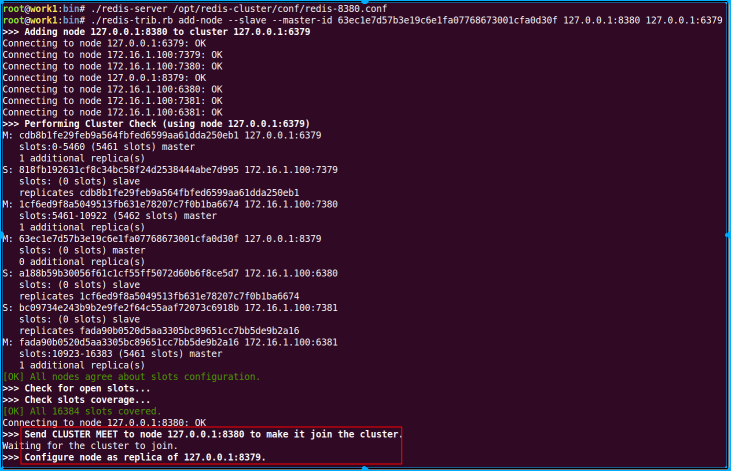
12 给8379添加一个slave节点
./redis-server /opt/redis-cluster/conf/redis-8380.conf
./redis-trib.rb add-node --slave --master-id 63ec1e7d57b3e19c6e1fa07768673001cfa0d30f 127.0.0.1:8380 127.0.0.1:6379
#或者
./redis-trib.rb add-node --slave 127.0.0.1:8380 127.0.0.1:6379
第一个添加slvae的命令是直接指定把该节点作为哪个master的slave加入cluster,而第二个命令redis-trib 会添加该新节点作为一个具有较少副本的随机的主服务器的副本(在本环境中显然是8379的副本了)。
再次检查cluster状态
./redis-trib.rb check 127.0.0.1:6379
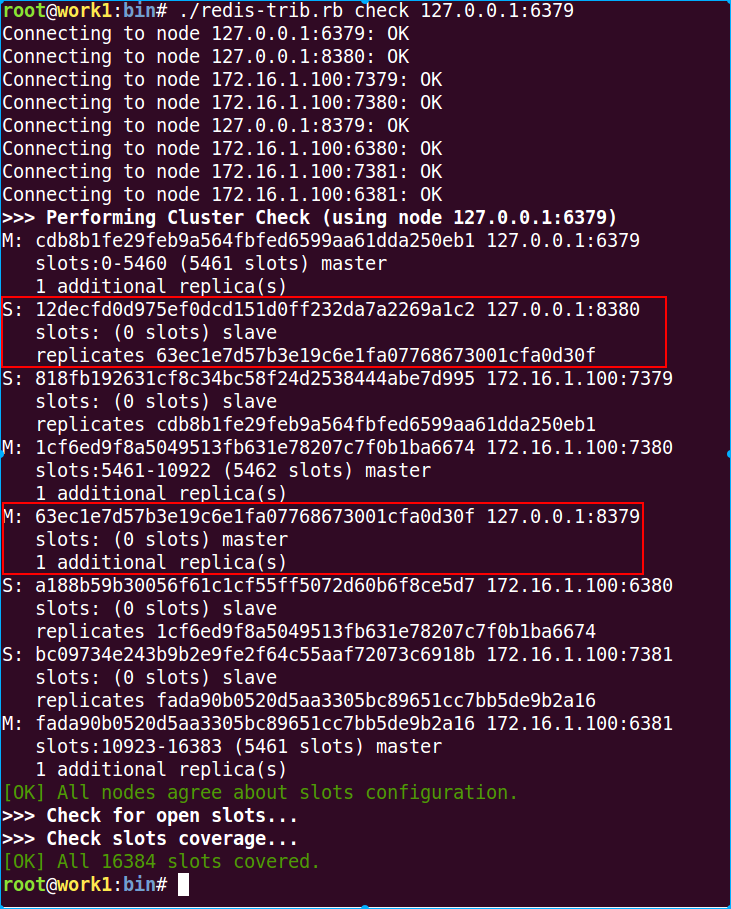
可以看到8379已经有一个slave了,但是它的slots还是0,因为我们一直没有给它迁移slots。
13 删除一个redis slave节点
我们先删除8380 slave节点,第一个参数是cluster中的任意一个节点,第二个参数要删除的slave的ID
./redis-trib.rb del-node 172.16.1.100:6379 12decfd0d975ef0dcd151d0ff232da7a2269a1c2
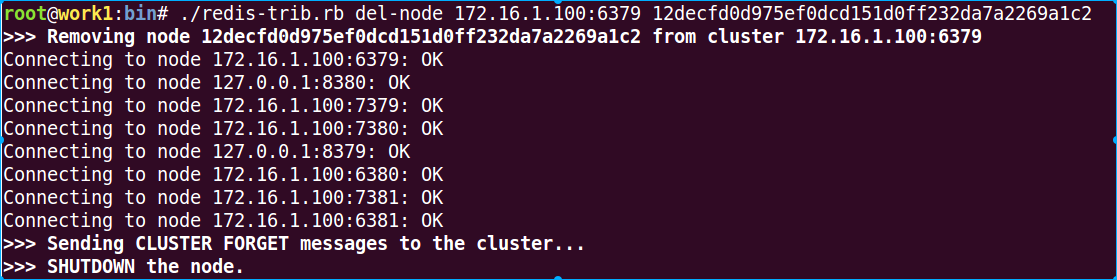
这时候再次检查cluster的状态
./redis-trib.rb check 127.0.0.1:6379
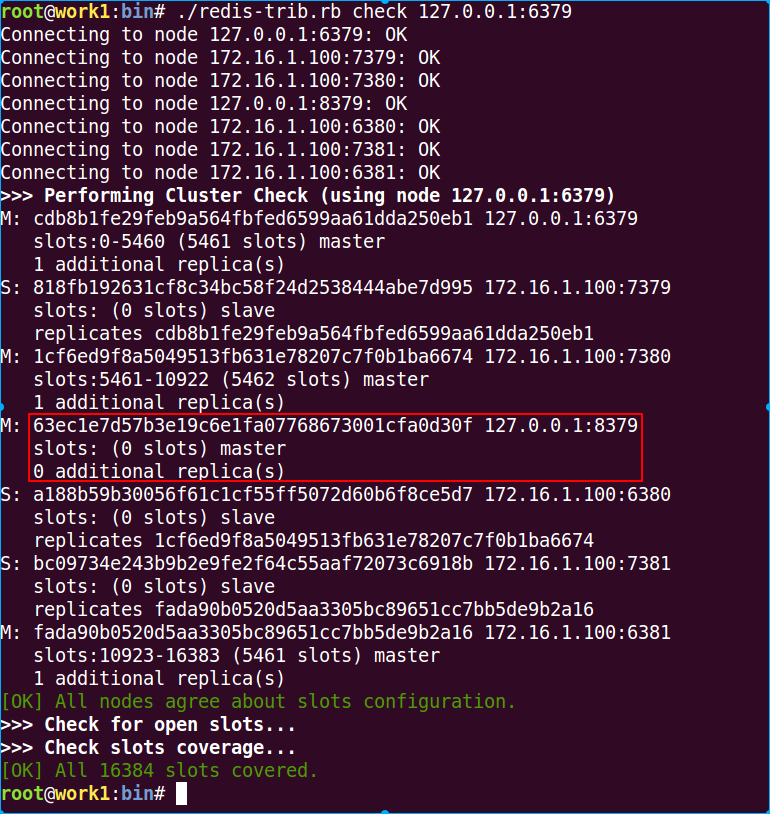
注意,红框中的8379的副本又变为0了。
14 删除一个redis master节点
删除master节点和删除slave节点操作一样,不过为了移除一个master节点,它必须是空的。如果master不是空的,你需要先将其数据重分片到其他的master节点。另一种移除master节点的方式,就是在其从服务器上执行一次手工故障转移,当它变为了新的master的slave以后将其移除。
因为我们还没操作slots重新分配,就先不删除8379了。
15 cluster重新分片
经过测试发现cluster的重新分片并不是在新的cluster内再次均匀的分配slots,而是需要是手动指定把哪个节点的多少slots迁移到另一个节点去.......
./redis-trib.rb reshard 127.0.0.1:6379
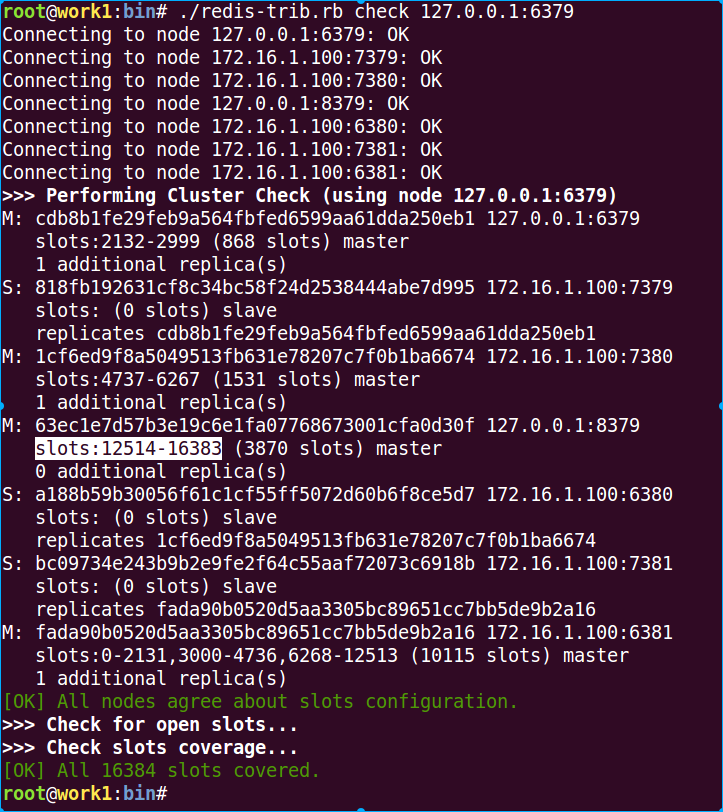
看看最终结果
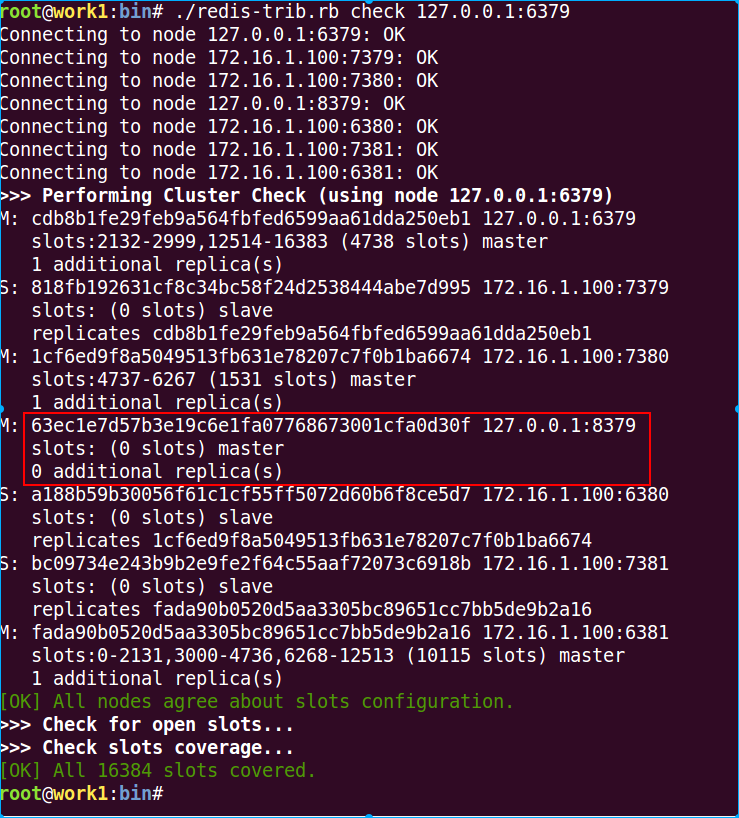
在经过我一番瞎迁移后,最终成为这样了。当然你也可以使用如下命令进行严格的迁移:
./redis-trib.rb reshard <host>:<port> --from <node-id> --to <node-id> --slots --yes
16 删除8379 master节点
因为8379的slots都被我迁移到其他节点去了,而删除一个master节点需要该节点的数据为空
./redis-trib.rb del-node 127.0.0.1:6379 63ec1e7d57b3e19c6e1fa07768673001cfa0d30f
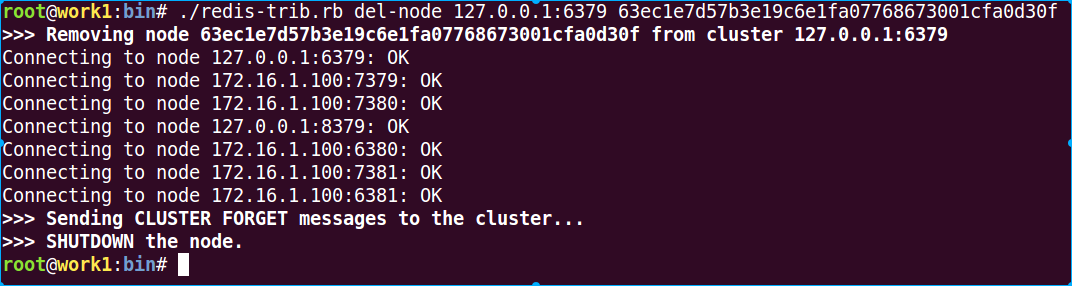
以上redis-trib的这些操作,在redis-cli中也是可以进行操作的:
CLUSTER INFO 打印集群的信息
CLUSTER NODES 列出集群当前已知的所有节点(node),以及这些节点的相关信息。
CLUSTER RESET reset
CLUSTER SAVECONFIG 强制节点保存集群当前状态到磁盘上。
CLUSTER SLOTS 获得slot在节点上的映射关系
CLUSTER MEET <ip> <port> 将 ip 和 port 所指定的节点添加到集群当中,让它成为集群的一份子。
CLUSTER FORGET <node_id> 从集群中移除 node_id 指定的节点。
CLUSTER REPLICATE <node_id> 将当前节点设置为 node_id 指定的节点的从节点。
CLUSTER SLAVES <node_id> 列出该slave节点的master节点
CLUSTER ADDSLOTS <slot> [slot ...] 将一个或多个槽(slot)指派(assign)给当前节点。
CLUSTER DELSLOTS <slot> [slot ...] 移除一个或多个槽对当前节点的指派。
CLUSTER FLUSHSLOTS 移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点。
CLUSTER SETSLOT <slot> NODE <node_id> 将槽 slot 指派给 node_id 指定的节点,如果槽已经指派给另一个节点,那么先让另一个节点删除该槽>,然后再进行指派。
CLUSTER SETSLOT <slot> MIGRATING <node_id> 将本节点的槽 slot 迁移到 node_id 指定的节点中。
CLUSTER SETSLOT <slot> IMPORTING <node_id> 从 node_id 指定的节点中导入槽 slot 到本节点。
CLUSTER SETSLOT <slot> STABLE 取消对槽 slot 的导入(import)或者迁移(migrate)。
CLUSTER KEYSLOT <key> 计算键 key 应该被放置在哪个槽上。
CLUSTER COUNTKEYSINSLOT <slot> 返回槽 slot 目前包含的键值对数量。
CLUSTER GETKEYSINSLOT <slot> <count> 返回 count 个 slot 槽中的键
READONLY 在集群中的salve节点开启只读模式
READWRITE 禁止读取请求跳转到集群中的salve节点上
(责任编辑:IT)
公司以一种错误的姿势使用了redis的功能,而且业务框架已经变得很大,虽然大家也都认为不合理,但是暂时看不到重构希望,可苦逼了后端人员,索性看看redis cluster能不能解决我的顾虑,redis 3出来也一段时间了,网上的文章也很多了,生产上大规模使用的公司不多,而且因为要对cluster的支持,导致很多原有lib库都无法使用了,不过这并不妨碍我们追索知识的步伐.... Redis很早的时候已经提供了Master-Slave功能,直到3.0版本的时候才提供了cluster功能,还是alpha版本,cluster并不支持多个键的操作,这样会导致需要在多个节点间移动数据,因为cluster中数据是被自动的分配到多个redis节点的。在cluster中部分节点出现不可用的时候,cluster还是可以继续提供正常服务的(当然要看你的集群配置)。
下面聊聊关于redis cluster的一些信息,每个在cluster中的redis节点都会监听两个端口,一个是和客户端通讯的TCP端口(6379),一个是用作cluster内部数据传输的,比如错误检测、cluster配置更新、故障转移等等(16379)。这样cluster的通讯问题就解决了,但数据是怎么在cluster中存放的?redis cluster没有采用一致性哈希,而是采用hash slot 其实个人觉得redis之前也有单独的数据分片功能和主从功能,cluster只是把这些功能合并在一起,外加一些集群的状态检测。下面看看redis cluster的集群架构图:
客户端连接在cluster中的任何一个节点上都可以获取到其他节点的数据,不过这幅图看着有点乱,一般cluster内部不会这么多节点互为主从的。 下面我们简单的使用一下,操作系统是一台ubuntu14.04系统(启动6个实例,3 Master/3 Slave): 1 下载最新版redis
wget 'http://download.redis.io/releases/redis-3.0.4.tar.gz'2 编译安装
#安装到/opt/redis-cluster目录
tar zxvf redis-3.0.4.tar.gz
cd redis-3.0.4/
make
make PREFIX=/opt/redis-cluster install
#创建配置目录,拷贝相关文件
mkdir /opt/redis-cluster/{log conf rdb run}
cp src/redis-trib.rb /opt/redis-cluster/bin/
3 安装其他依赖包
apt-get install ruby1.9.1 gem install redis4 创建配置文件
看看6379的具体信息:grep -v -E '(^#|^$)' redis-6379.conf
daemonize yes pidfile /opt/redis-cluster/run/redis-6379.pid port 6379 tcp-backlog 511 timeout 0 tcp-keepalive 0 loglevel notice logfile "/opt/redis-cluster/log/redis-6379.log" databases 16 save 900 1 save 300 10 save 60 10000 stop-writes-on-bgsave-error yes rdbcompression yes rdbchecksum yes dbfilename dump-6379.rdb dir /opt/redis-cluster/rdb slave-serve-stale-data yes slave-read-only yes repl-diskless-sync no repl-diskless-sync-delay 5 repl-disable-tcp-nodelay no slave-priority 100 appendonly yes appendfilename "redis-6379.aof" appendfsync everysec no-appendfsync-on-rewrite no auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb aof-load-truncated yes lua-time-limit 5000 cluster-enabled yes cluster-config-file nodes-6379.conf cluster-node-timeout 15000 slowlog-log-slower-than 10000 slowlog-max-len 128 latency-monitor-threshold 0 notify-keyspace-events "" hash-max-ziplist-entries 512 hash-max-ziplist-value 64 list-max-ziplist-entries 512 list-max-ziplist-value 64 set-max-intset-entries 512 zset-max-ziplist-entries 128 zset-max-ziplist-value 64 hll-sparse-max-bytes 3000 activerehashing yes client-output-buffer-limit normal 0 0 0 client-output-buffer-limit slave 256mb 64mb 60 client-output-buffer-limit pubsub 32mb 8mb 60 hz 10 aof-rewrite-incremental-fsync yes其实大部分都是原有的配置信息,不需要做大的改动,与端口相关的都需要调整,与集群相关的配置如下:
cluster-enabled yes cluster-config-file nodes-6379.conf cluster-node-timeout 15000 注意其中的nodes-6379.conf这个文件不需要创建,在初始化集群的时候会自动创建的。 5 在启动redis实例前先修改一些系统级别的配置
echo never > /sys/kernel/mm/transparent_hugepage/enabled # 打开/etc/sysctl.conf,追加如下内容 vm.overcommit_memory = 1 #使配置生效 sysctl -p6 启动所有redis实例
cd /opt/redis-cluster/bin ./redis-server /opt/redis-cluster/conf/redis-6379.conf ./redis-server /opt/redis-cluster/conf/redis-6380.conf ./redis-server /opt/redis-cluster/conf/redis-6381.conf ./redis-server /opt/redis-cluster/conf/redis-7379.conf ./redis-server /opt/redis-cluster/conf/redis-7380.conf ./redis-server /opt/redis-cluster/conf/redis-7381.conf7 redis-trib.rb redis-trib.rb是一个官方提供的用来操作cluster的ruby脚本,我们后面管理cluster会经常使用到这个脚本
Usage: redis-trib <command> <options> <arguments ...>
create host1:port1 ... hostN:portN
--replicas <arg>
check host:port
fix host:port
reshard host:port
--from <arg>
--to <arg>
--slots <arg>
--yes
add-node new_host:new_port existing_host:existing_port
--slave
--master-id <arg>
del-node host:port node_id
set-timeout host:port milliseconds
call host:port command arg arg .. arg
import host:port
--from <arg>
help (show this help)
For check, fix, reshard, del-node, set-timeout you can specify the host and port of any working node in the cluster.
8 初始化启动cluster
./redis-trib.rb create --replicas 1 172.16.1.100:6379 172.16.1.100:6380 172.16.1.100:6381 172.16.1.100:7379 172.16.1.100:7380 172.16.1.100:7381 结果如下: >>> Creating cluster Connecting to node 172.16.1.100:6379: OK Connecting to node 172.16.1.100:6380: OK Connecting to node 172.16.1.100:6381: OK Connecting to node 172.16.1.100:7379: OK Connecting to node 172.16.1.100:7380: OK Connecting to node 172.16.1.100:7381: OK >>> Performing hash slots allocation on 6 nodes... Using 3 masters: ###注意三个6xxx的都被定义为master的了 172.16.1.100:6379 172.16.1.100:6380 172.16.1.100:6381 Adding replica 172.16.1.100:7379 to 172.16.1.100:6379 ###注意三个7xxx的都被定义为相关的slave了 Adding replica 172.16.1.100:7380 to 172.16.1.100:6380 Adding replica 172.16.1.100:7381 to 172.16.1.100:6381 M: cdb8b1fe29feb9a564fbfed6599aa61dda250eb1 172.16.1.100:6379 slots:0-5460 (5461 slots) master ###6379被分配了0-5460个slots M: a188b59b30056f61c1cf55ff5072d60b6f8ce5d7 172.16.1.100:6380 slots:5461-10922 (5462 slots) master ###6380被分配了5461-10922个slots M: fada90b0520d5aa3305bc89651cc7bb5de9b2a16 172.16.1.100:6381 slots:10923-16383 (5461 slots) master ###6381被分配了10923-16383个slots S: 818fb192631cf8c34bc58f24d2538444abe7d995 172.16.1.100:7379 ###剩余的三个slave replicates cdb8b1fe29feb9a564fbfed6599aa61dda250eb1 S: 1cf6ed9f8a5049513fb631e78207c7f0b1ba6674 172.16.1.100:7380 replicates a188b59b30056f61c1cf55ff5072d60b6f8ce5d7 S: bc09734e243b9b2e9fe2f64c55aaf72073c6918b 172.16.1.100:7381 replicates fada90b0520d5aa3305bc89651cc7bb5de9b2a16 Can I set the above configuration? (type 'yes' to accept): yes ###是否在nodes配置文件中保存更新配置 >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join..... >>> Performing Cluster Check (using node 172.16.1.100:6379) M: cdb8b1fe29feb9a564fbfed6599aa61dda250eb1 172.16.1.100:6379 slots:0-5460 (5461 slots) master M: a188b59b30056f61c1cf55ff5072d60b6f8ce5d7 172.16.1.100:6380 slots:5461-10922 (5462 slots) master M: fada90b0520d5aa3305bc89651cc7bb5de9b2a16 172.16.1.100:6381 slots:10923-16383 (5461 slots) master M: 818fb192631cf8c34bc58f24d2538444abe7d995 172.16.1.100:7379 slots: (0 slots) master replicates cdb8b1fe29feb9a564fbfed6599aa61dda250eb1 M: 1cf6ed9f8a5049513fb631e78207c7f0b1ba6674 172.16.1.100:7380 slots: (0 slots) master replicates a188b59b30056f61c1cf55ff5072d60b6f8ce5d7 M: bc09734e243b9b2e9fe2f64c55aaf72073c6918b 172.16.1.100:7381 slots: (0 slots) master replicates fada90b0520d5aa3305bc89651cc7bb5de9b2a16 [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.检查一下cluster的状态:redis-trib.rb check 127.0.0.1:6379
9 接入cluster,并存入一个key/value (name/guo)
redis-cli -c -h 127.0.0.1 -p 6379注意:redis-cli在接入集群模式时,要使用-c参数
可以看到我在6379接入cluster中,并存入可一个name/guodalu键值对,但是cluster却把我保存的值定位到7380去了,而我使用6381接入cluster中后,再次获取name值时,会被自动的定位到7380上。我们来看看是我是怎么被定位到7380的。 1 先计算guodalu的CRC16值是0xA36B,转化成10进制是41835 2 41835对16384取模是9067,9067 slot是落在6380上的,而7380是6380的slave。 下面我们把7380停止,可以看到再次检查cluster的时候,并不会报错。
我们在6381上接入cluster,获取name
10 恢复7380,停止6380
可以看到这时候check cluster的时候,会提示一个节点已经故障,我们这时候再尝试获取key
可以看到还是可以获取到的。如果把6380和7380同时停止呢?
如果cluster中的master和slave全部故障的话,则这部分数据还是不可用的。 11 在cluster中新增一个redis master节点 启动redis 8379实例
./redis-server /opt/redis-cluster/conf/redis-8379.conf 然后把该实例加入cluster中:第一个参数是新加入的redis节点,第二个参数是cluster中的任何一个已有的节点
./redis-trib.rb add-node 127.0.0.1:8379 127.0.0.1:6379 这时候检查一下cluster状态
./redis-trib.rb check 127.0.0.1:6379 可以看到8379已经加入cluster中了,默认是以master加入cluster的,而且副本为1,但是这个新的master却没有被cluster分配slots,所以它里面是没有数据的,当有slave服务器要升级为master服务器时,它不能参与选举。这时候我们可以使用重新划分slots的特性给新加入的8379迁移其他节点上的slots,这个后面操作。 12 给8379添加一个slave节点
./redis-server /opt/redis-cluster/conf/redis-8380.conf ./redis-trib.rb add-node --slave --master-id 63ec1e7d57b3e19c6e1fa07768673001cfa0d30f 127.0.0.1:8380 127.0.0.1:6379 #或者 ./redis-trib.rb add-node --slave 127.0.0.1:8380 127.0.0.1:6379第一个添加slvae的命令是直接指定把该节点作为哪个master的slave加入cluster,而第二个命令redis-trib 会添加该新节点作为一个具有较少副本的随机的主服务器的副本(在本环境中显然是8379的副本了)。
再次检查cluster状态
./redis-trib.rb check 127.0.0.1:6379 可以看到8379已经有一个slave了,但是它的slots还是0,因为我们一直没有给它迁移slots。 13 删除一个redis slave节点 我们先删除8380 slave节点,第一个参数是cluster中的任意一个节点,第二个参数要删除的slave的ID
./redis-trib.rb del-node 172.16.1.100:6379 12decfd0d975ef0dcd151d0ff232da7a2269a1c2 这时候再次检查cluster的状态
./redis-trib.rb check 127.0.0.1:6379 注意,红框中的8379的副本又变为0了。 14 删除一个redis master节点 删除master节点和删除slave节点操作一样,不过为了移除一个master节点,它必须是空的。如果master不是空的,你需要先将其数据重分片到其他的master节点。另一种移除master节点的方式,就是在其从服务器上执行一次手工故障转移,当它变为了新的master的slave以后将其移除。 因为我们还没操作slots重新分配,就先不删除8379了。 15 cluster重新分片 经过测试发现cluster的重新分片并不是在新的cluster内再次均匀的分配slots,而是需要是手动指定把哪个节点的多少slots迁移到另一个节点去.......
./redis-trib.rb reshard 127.0.0.1:6379
看看最终结果 在经过我一番瞎迁移后,最终成为这样了。当然你也可以使用如下命令进行严格的迁移:
./redis-trib.rb reshard <host>:<port> --from <node-id> --to <node-id> --slots --yes16 删除8379 master节点 因为8379的slots都被我迁移到其他节点去了,而删除一个master节点需要该节点的数据为空
./redis-trib.rb del-node 127.0.0.1:6379 63ec1e7d57b3e19c6e1fa07768673001cfa0d30f 以上redis-trib的这些操作,在redis-cli中也是可以进行操作的:
CLUSTER INFO 打印集群的信息 CLUSTER NODES 列出集群当前已知的所有节点(node),以及这些节点的相关信息。 CLUSTER RESET reset CLUSTER SAVECONFIG 强制节点保存集群当前状态到磁盘上。 CLUSTER SLOTS 获得slot在节点上的映射关系 CLUSTER MEET <ip> <port> 将 ip 和 port 所指定的节点添加到集群当中,让它成为集群的一份子。 CLUSTER FORGET <node_id> 从集群中移除 node_id 指定的节点。 CLUSTER REPLICATE <node_id> 将当前节点设置为 node_id 指定的节点的从节点。 CLUSTER SLAVES <node_id> 列出该slave节点的master节点 CLUSTER ADDSLOTS <slot> [slot ...] 将一个或多个槽(slot)指派(assign)给当前节点。 CLUSTER DELSLOTS <slot> [slot ...] 移除一个或多个槽对当前节点的指派。 CLUSTER FLUSHSLOTS 移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点。 CLUSTER SETSLOT <slot> NODE <node_id> 将槽 slot 指派给 node_id 指定的节点,如果槽已经指派给另一个节点,那么先让另一个节点删除该槽>,然后再进行指派。 CLUSTER SETSLOT <slot> MIGRATING <node_id> 将本节点的槽 slot 迁移到 node_id 指定的节点中。 CLUSTER SETSLOT <slot> IMPORTING <node_id> 从 node_id 指定的节点中导入槽 slot 到本节点。 CLUSTER SETSLOT <slot> STABLE 取消对槽 slot 的导入(import)或者迁移(migrate)。 CLUSTER KEYSLOT <key> 计算键 key 应该被放置在哪个槽上。 CLUSTER COUNTKEYSINSLOT <slot> 返回槽 slot 目前包含的键值对数量。 CLUSTER GETKEYSINSLOT <slot> <count> 返回 count 个 slot 槽中的键 READONLY 在集群中的salve节点开启只读模式 READWRITE 禁止读取请求跳转到集群中的salve节点上 (责任编辑:IT) |