Mysql优化
时间:2016-07-29 03:19 来源:linux.it.net.cn 作者:IT
mysql的优化
一、 数据库(表)设计合理
我们的表设计要符合 3NF 3范式(规范的模式),有时我们需要适当的逆范式
二、sql语句的优化(索引,常用小技巧.)
三、数据的配置(缓存设大)
四、适当硬件配置和操作系统(读写分离.)
一、 数据库(表)设计合理
通俗地理解三个范式,对于数据库设计大有好处。在数据库设计中,为了更好地应用三个范式,就必须通俗地理解三个范式(通俗地理解是够用的理解,并不是最科学最准确的理解):
第一范式:1NF是对属性的原子性约束,要求属性具有原子性,不可再分解;(只要是关系型数据库都满足1NF)
第二范式:在满足1NF的基础上,我们考虑是否满足2NF,2NF是对记录的惟一性约束,要求记录有惟一标识,即实体的惟一性;
也就是说,你的同一张表,不可能出现相同的记录,一般说我们在表中设计一个主键即可。
第三范式:在满足2NF的基础上,我们考虑是否满足3NF,3NF是对字段冗余性的约束,即任何字段不能由其他字段派生出来,它要求字段没有冗余。 没有冗余的数据库设计可以做到。 也就是说,我们的字段信息可以通过关联的关系,派生即可(通常我们通过外键来处理)
但是,没有冗余的数据库未必是最好的数据库,有时为了提高运行效率,就必须降低范式标准,适当保留冗余数据。具体做法是: 在概念数据模型设计时遵守第三范式,降低范式标准的工作放到物理数据模型设计时考虑。降低范式就是增加字段,允许冗余。
二、sql语句的优化
面试题:sql语句有几类
ddl(数据定义语言) 【create alter drop】
dml(数据操作语言)【insert delete update】
select
dtl(数据事务语句)【commit rollback savepoint】
dcl(数据控制语句)【grant rework】
show status 命令
该命令可以显示你的mysql数据库的当前状况,我们主要关心的是“com”开头的指令
show status like 'Com%'; <=> show session status like 'Com%'; //显示当前控制台的情况
show global status like 'Com%'; // 显示数据库从启动到查询失败的次数
重点注意:Com_select,Com_insert,Com_update,Com_delete通过这几个参数,可以容易地了解到当前数据库的应用是以插入更新为主还是以查询操作为主,以及各类的SQL大致的执行比例是多少。
show status like Com_select'; // 统计数据库查询的次数
show status like 'Com_insert'; // 统计数据库插入的次数
show status like 'Com_update'; // 统计数据库修改的次数
show status like 'Com_delete'; // 统计数据库删除的次数
显示连接数据库次数
show status like 'Connections';
显示服务器工作的时间
show status like 'Uptime';
这里我们优化的重点是在慢查询(默认是10s为慢)
查询慢查询的时间为几秒
show variables like 'long_query_time';
修改慢查询的时间
set long_query_time=1;
显示慢查询的次数
show status like 'Slow_queries';
需求:如何在一个项目中,找到慢查询的select,mysql数据库支持把慢查询
语句记录到日志中,程序员分析(但是注意,默认情况下不启动)
步骤:
1.要这样启动mysql
2.启动 E:\wamp\bin\mysql\mysql5.0.51b\bin\mysqld.exe -slow-query-log
测试,比如我们把
select * from emp where empno=321456;
用了1.5秒,现在优化
在emp表的empno建立索引
alter table emp add primary key(empno);
查询速度明显提升
如果你的数据库的存储引擎是MyISAM的,则当创建一个表,后三个文件
*.frm记录表结构,*.myd数据 ,*.myi这个是索引
mysql5.5.19的版本,他的数据库文件默认放在(看my.ini文件中的配置)可以设置数据存放地址
#Path to the database root
datadir=E:/wamp/bin/mysql/mysql5.0.51b/data
说起提高数据库性能,索引是最物美价廉的东西了。不用加内存,不用改程序,
不用调sql,只要执行个正确的’create index’,查询速度就可能提高百倍千倍,
这可真有诱惑力。可是天下没有免费的午餐,查询速度的提高是以插入、更新、
删除的速度为代价的,这些写操作,增加了大量的I/O。
介绍一款非常重要工具 explain, 这个分析工具可以对 sql语句进行分析,可以预测你的sql执行的效率.
他的基本用法是:
explain sql语句\G
//根据返回的信息,我们可知,该sql语句是否使用索引,从多少记录中取出,可以看到排序的方式.
如图1
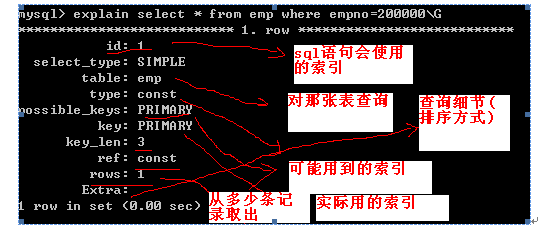
select_type:表示查询的类型。
table:输出结果集的表
type:表示表的连接类型
possible_keys:表示查询时,可能使用的索引
key:表示实际使用的索引
key_len:索引字段的长度
rows:扫描的行数
Extra:执行情况的描述和说明
在什么列上添加索引比较合适
①在经常查询的列上加索引.
②列的数据,内容就只有少数几个值,不太适合加索引.
③内容频繁变化,不合适加索引
索引的种类
①主键索引 (把某列设为主键,则就是主键索引)
②唯一索引(unique) (即该列具有唯一性,同时又是索引)
③index (普通索引)
④全文索引(FULLTEXT) (只有MyISAM存储引擎支持)
select * from article where content like ‘%李连杰%’;
hello, i am a boy
你好,我是一个男孩 =>注意:中文不适用 中文使用 sphinx技术
⑤复合索引(多列和在一起)
create index myind on 表名 (列1,列2);
如何创建索引
如果创建unique / 普通/fulltext 索引
1. create [unique|FULLTEXT] index 索引名 on 表名 (列名...)
2. alter table 表名 add index 索引名 (列名...)
//如果要添加主键索引
alter table 表名 add primary key (列...)
删除索引
1.drop index 索引名 on 表名
2.alter table 表名 drop index index_name;
3.alter table 表名 drop primary key 删除主键索引
显示索引
show index(es) from 表名
show keys from 表名
desc 表名
使用索引的注意事项
查询要使用索引最重要的条件是查询条件中需要使用索引。
下列几种情况下有可能使用到索引:
1,对于创建的多列索引,只要查询条件使用了最左边的列,索引一般就会被使用。
2,对于使用like的查询,查询如果是 ‘%aaa’ 不会使用到索引
‘aaa%’ 会使用到索引。
下列的表将不使用索引:
1,如果条件中有or,即使其中有条件带索引也不会使用。
2,对于多列索引,不是使用的第一部分,则不会使用索引。
3,like查询是以%开头
4,如果列类型是字符串,那一定要在条件中将数据使用引号引用起来。否则不使用索引。
5,如果mysql估计使用全表扫描要比使用索引快,则不使用索引。
如何检测你的索引是否有效
show status like 'Handler_read%';
如图:

大家可以注意:
handler_read_key:这个值越高越好,越高表示使用索引查询到的次数。 越大越好
handler_read_rnd_next:这个值越高,说明查询低效。 越小越好
MyISAM 和 Innodb区别是什么
1.MyISAM 不支持外键, Innodb支持
2.MyISAM 不支持事务,不支持外键.
3.对数据信息的存储处理方式不同.(如果存储引擎是MyISAM的,则创建一张表,对于三个文件..,如果是Innodb则只有一张文件 *.frm,数据存放到ibdata1)
对于 MyISAM 数据库,需要定时清理
optimize table 表名;
大批量插入数据
对于MyISAM:
alter table table_name disable keys;
loading data;
alter table table_name enable keys;
对于Innodb:
1,将要导入的数据按照主键排序
2,set unique_checks=0,关闭唯一性校验。
3,set autocommit=0,关闭自动提交。
常见的sql优化手法
1.使用order by null 禁用排序
group by默认是会排序的
比如 select * from dept group by ename order by null
2.有些情况下,可以使用连接来替代子查询。
因为使用join,MySQL不需要在内存中创建临时表。
如果想要在含有or的查询语句中利用索引,则or之间的每个条件列都必须用到索引,如果没有索引,
则应该考虑增加索引
select * from 表名 where 条件1='' or 条件2='tt';
3.在精度要求高的应用中,建议使用定点数(decimal)来存储数值,以保证结果的准确性
问?在php中 ,int 如果是一个有符号数,最大值. int- 4*8=32 2^31 -1 int型有符号最大表示2 147 483 647
对表进行水平划分
如果一个表的记录数太多了,比如上千万条,而且需要经常检索,那么我们就有必要化整为零了。
如果我拆成100个表,那么每个表只有10万条记当然这 需要数据在逻辑上可以划分。一个好的划分依据,
有利于程序的简单实现,也可以充分利用水平分录。表的优势。比如系统界面上只提供按月查询的功能,
那么把表按月 拆分成12个,每个查询只查询一个表就够了。如果非要按照地域来分,即使把表拆的再小,
查询还是要联合所有表来查,还不如不拆了。所以一个好的拆分依据是 最重要的
对表进行垂直划分
有些表记录数并不多,可能也就2、3万条,但是字段却很长,表占用空间很大,检索表时需要执行大量I/O,
严重降低了性能。这个时候需要把大的字段拆分到另一个表,并且该表与原表是一对一的关系。
三、数据的配置(缓存设大)
最重要的参数就是内存,我们主要用的innodb引擎,所以下面两个参数调的很大
innodb_additional_mem_pool_size = 64M
innodb_buffer_pool_size =1G
对于myisam,需要调整key_buffer_size
当然调整参数还是要看状态,用show status语句可以看到当前状态,以决定改调整哪些参数
(责任编辑:IT)
| mysql的优化 一、 数据库(表)设计合理 我们的表设计要符合 3NF 3范式(规范的模式),有时我们需要适当的逆范式 二、sql语句的优化(索引,常用小技巧.) 三、数据的配置(缓存设大) 四、适当硬件配置和操作系统(读写分离.) 一、 数据库(表)设计合理 通俗地理解三个范式,对于数据库设计大有好处。在数据库设计中,为了更好地应用三个范式,就必须通俗地理解三个范式(通俗地理解是够用的理解,并不是最科学最准确的理解): 第一范式:1NF是对属性的原子性约束,要求属性具有原子性,不可再分解;(只要是关系型数据库都满足1NF) 第二范式:在满足1NF的基础上,我们考虑是否满足2NF,2NF是对记录的惟一性约束,要求记录有惟一标识,即实体的惟一性; 也就是说,你的同一张表,不可能出现相同的记录,一般说我们在表中设计一个主键即可。 第三范式:在满足2NF的基础上,我们考虑是否满足3NF,3NF是对字段冗余性的约束,即任何字段不能由其他字段派生出来,它要求字段没有冗余。 没有冗余的数据库设计可以做到。 也就是说,我们的字段信息可以通过关联的关系,派生即可(通常我们通过外键来处理) 但是,没有冗余的数据库未必是最好的数据库,有时为了提高运行效率,就必须降低范式标准,适当保留冗余数据。具体做法是: 在概念数据模型设计时遵守第三范式,降低范式标准的工作放到物理数据模型设计时考虑。降低范式就是增加字段,允许冗余。 二、sql语句的优化 面试题:sql语句有几类 ddl(数据定义语言) 【create alter drop】 dml(数据操作语言)【insert delete update】 select dtl(数据事务语句)【commit rollback savepoint】 dcl(数据控制语句)【grant rework】 show status 命令 该命令可以显示你的mysql数据库的当前状况,我们主要关心的是“com”开头的指令 show status like 'Com%'; <=> show session status like 'Com%'; //显示当前控制台的情况 show global status like 'Com%'; // 显示数据库从启动到查询失败的次数 重点注意:Com_select,Com_insert,Com_update,Com_delete通过这几个参数,可以容易地了解到当前数据库的应用是以插入更新为主还是以查询操作为主,以及各类的SQL大致的执行比例是多少。 show status like Com_select'; // 统计数据库查询的次数 show status like 'Com_insert'; // 统计数据库插入的次数 show status like 'Com_update'; // 统计数据库修改的次数 show status like 'Com_delete'; // 统计数据库删除的次数 显示连接数据库次数 show status like 'Connections'; 显示服务器工作的时间 show status like 'Uptime'; 这里我们优化的重点是在慢查询(默认是10s为慢) 查询慢查询的时间为几秒 show variables like 'long_query_time'; 修改慢查询的时间 set long_query_time=1; 显示慢查询的次数 show status like 'Slow_queries'; 需求:如何在一个项目中,找到慢查询的select,mysql数据库支持把慢查询 语句记录到日志中,程序员分析(但是注意,默认情况下不启动) 步骤: 1.要这样启动mysql 2.启动 E:\wamp\bin\mysql\mysql5.0.51b\bin\mysqld.exe -slow-query-log 测试,比如我们把 select * from emp where empno=321456; 用了1.5秒,现在优化 在emp表的empno建立索引 alter table emp add primary key(empno); 查询速度明显提升 如果你的数据库的存储引擎是MyISAM的,则当创建一个表,后三个文件 *.frm记录表结构,*.myd数据 ,*.myi这个是索引 mysql5.5.19的版本,他的数据库文件默认放在(看my.ini文件中的配置)可以设置数据存放地址 #Path to the database root datadir=E:/wamp/bin/mysql/mysql5.0.51b/data 说起提高数据库性能,索引是最物美价廉的东西了。不用加内存,不用改程序, 不用调sql,只要执行个正确的’create index’,查询速度就可能提高百倍千倍, 这可真有诱惑力。可是天下没有免费的午餐,查询速度的提高是以插入、更新、 删除的速度为代价的,这些写操作,增加了大量的I/O。 介绍一款非常重要工具 explain, 这个分析工具可以对 sql语句进行分析,可以预测你的sql执行的效率. 他的基本用法是: explain sql语句\G //根据返回的信息,我们可知,该sql语句是否使用索引,从多少记录中取出,可以看到排序的方式. 如图1 select_type:表示查询的类型。 table:输出结果集的表 type:表示表的连接类型 possible_keys:表示查询时,可能使用的索引 key:表示实际使用的索引 key_len:索引字段的长度 rows:扫描的行数 Extra:执行情况的描述和说明 在什么列上添加索引比较合适 ①在经常查询的列上加索引. ②列的数据,内容就只有少数几个值,不太适合加索引. ③内容频繁变化,不合适加索引 索引的种类 ①主键索引 (把某列设为主键,则就是主键索引) ②唯一索引(unique) (即该列具有唯一性,同时又是索引) ③index (普通索引) ④全文索引(FULLTEXT) (只有MyISAM存储引擎支持) select * from article where content like ‘%李连杰%’; hello, i am a boy 你好,我是一个男孩 =>注意:中文不适用 中文使用 sphinx技术 ⑤复合索引(多列和在一起) create index myind on 表名 (列1,列2); 如何创建索引 如果创建unique / 普通/fulltext 索引 1. create [unique|FULLTEXT] index 索引名 on 表名 (列名...) 2. alter table 表名 add index 索引名 (列名...) //如果要添加主键索引 alter table 表名 add primary key (列...) 删除索引 1.drop index 索引名 on 表名 2.alter table 表名 drop index index_name; 3.alter table 表名 drop primary key 删除主键索引 显示索引 show index(es) from 表名 show keys from 表名 desc 表名 使用索引的注意事项 查询要使用索引最重要的条件是查询条件中需要使用索引。 下列几种情况下有可能使用到索引: 1,对于创建的多列索引,只要查询条件使用了最左边的列,索引一般就会被使用。 2,对于使用like的查询,查询如果是 ‘%aaa’ 不会使用到索引 ‘aaa%’ 会使用到索引。 下列的表将不使用索引: 1,如果条件中有or,即使其中有条件带索引也不会使用。 2,对于多列索引,不是使用的第一部分,则不会使用索引。 3,like查询是以%开头 4,如果列类型是字符串,那一定要在条件中将数据使用引号引用起来。否则不使用索引。 5,如果mysql估计使用全表扫描要比使用索引快,则不使用索引。 如何检测你的索引是否有效 show status like 'Handler_read%'; 如图: 大家可以注意: handler_read_key:这个值越高越好,越高表示使用索引查询到的次数。 越大越好 handler_read_rnd_next:这个值越高,说明查询低效。 越小越好 MyISAM 和 Innodb区别是什么 1.MyISAM 不支持外键, Innodb支持 2.MyISAM 不支持事务,不支持外键. 3.对数据信息的存储处理方式不同.(如果存储引擎是MyISAM的,则创建一张表,对于三个文件..,如果是Innodb则只有一张文件 *.frm,数据存放到ibdata1) 对于 MyISAM 数据库,需要定时清理 optimize table 表名; 大批量插入数据 对于MyISAM: alter table table_name disable keys; loading data; alter table table_name enable keys; 对于Innodb: 1,将要导入的数据按照主键排序 2,set unique_checks=0,关闭唯一性校验。 3,set autocommit=0,关闭自动提交。 常见的sql优化手法 1.使用order by null 禁用排序 group by默认是会排序的 比如 select * from dept group by ename order by null 2.有些情况下,可以使用连接来替代子查询。 因为使用join,MySQL不需要在内存中创建临时表。 如果想要在含有or的查询语句中利用索引,则or之间的每个条件列都必须用到索引,如果没有索引, 则应该考虑增加索引 select * from 表名 where 条件1='' or 条件2='tt'; 3.在精度要求高的应用中,建议使用定点数(decimal)来存储数值,以保证结果的准确性 问?在php中 ,int 如果是一个有符号数,最大值. int- 4*8=32 2^31 -1 int型有符号最大表示2 147 483 647 对表进行水平划分 如果一个表的记录数太多了,比如上千万条,而且需要经常检索,那么我们就有必要化整为零了。 如果我拆成100个表,那么每个表只有10万条记当然这 需要数据在逻辑上可以划分。一个好的划分依据, 有利于程序的简单实现,也可以充分利用水平分录。表的优势。比如系统界面上只提供按月查询的功能, 那么把表按月 拆分成12个,每个查询只查询一个表就够了。如果非要按照地域来分,即使把表拆的再小, 查询还是要联合所有表来查,还不如不拆了。所以一个好的拆分依据是 最重要的 对表进行垂直划分 有些表记录数并不多,可能也就2、3万条,但是字段却很长,表占用空间很大,检索表时需要执行大量I/O, 严重降低了性能。这个时候需要把大的字段拆分到另一个表,并且该表与原表是一对一的关系。 三、数据的配置(缓存设大) 最重要的参数就是内存,我们主要用的innodb引擎,所以下面两个参数调的很大 innodb_additional_mem_pool_size = 64M innodb_buffer_pool_size =1G 对于myisam,需要调整key_buffer_size 当然调整参数还是要看状态,用show status语句可以看到当前状态,以决定改调整哪些参数 (责任编辑:IT) |