MapReduceЦРөДЧФ¶ЁТе¶аДҝВј/ОДјюГыКдіцHDFS
Кұјд:2016-11-27 02:37 АҙФҙ:linux.it.net.cn ЧчХЯ:IT
ЧоҪьҝјВЗөҪХвСщТ»ёцРиЗуЈә
РиТӘ°СФӯКјөДИХЦҫОДјюУГhadoopЧцЗеПҙәуЈ¬°ҙТөОсПЯКдіцөҪІ»Н¬өДДҝВјПВИҘЈ¬ТФ№©І»Н¬өДІҝГЕТөОсПЯК№УГЎЈ
ХвёцРиЗуРиТӘУГөҪMultipleOutputFormatәНMultipleOutputsАҙКөПЦЧФ¶ЁТе¶аДҝВјЎўОДјюөДКдіцЎЈ
РиТӘЧўТвөДКЗЈ¬ФЪhadoop 0.21.xЦ®З°әНЦ®әуөДК№УГ·ҪКҪКЗІ»Т»СщөДЈә
hadoop 0.21 Ц®З°өДAPI ЦРУР org.apache.hadoop.mapred.lib.MultipleOutputFormat әН org.apache.hadoop.mapred.lib.MultipleOutputsЈ¬¶шөҪБЛ 0.21 Ц®әу өДAPIОӘ org.apache.hadoop.mapreduce.lib.output.MultipleOutputs Ј¬
РВ°жөДAPI ХыәПБЛЙПГжҫЙAPIБҪёцөД№ҰДЬЈ¬Г»УРБЛMultipleOutputFormatЎЈ
ұҫОДҪ«ёшіцРВҫЙБҪёц°жұҫөДAPI codeЎЈ
1ЎўҫЙ°ж0.21.xЦ®З°өД°жұҫЈә
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.lib.MultipleTextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class MultiFile extends Configured implements Tool {
public static class MapClass extends MapReduceBase implements
Mapper<LongWritable, Text, NullWritable, Text> {
@Override
public void map(LongWritable key, Text value,
OutputCollector<NullWritable, Text> output, Reporter reporter)
throws IOException {
output.collect(NullWritable.get(), value);
}
}
// MultipleTextOutputFormat јМіРЧФMultipleOutputFormatЈ¬КөПЦКдіцОДјюөД·ЦАа
public static class PartitionByCountryMTOF extends
MultipleTextOutputFormat<NullWritable, Text> { // key is
// NullWritable,
// value is Text
protected String generateFileNameForKeyValue(NullWritable key,
Text value, String filename) {
String[] arr = value.toString().split(",", -1);
String country = arr[4].substring(1, 3); // »сИЎcountryөДГыіЖ
return country + "/" + filename;
}
}
// ҙЛҙҰІ»К№УГreducer
/*
* public static class Reducer extends MapReduceBase implements
* org.apache.hadoop.mapred.Reducer<LongWritable, Text, NullWritable, Text>
* {
*
* @Override public void reduce(LongWritable key, Iterator<Text> values,
* OutputCollector<NullWritable, Text> output, Reporter reporter) throws
* IOException { // TODO Auto-generated method stub
*
* }
*
* }
*/
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
JobConf job = new JobConf(conf, MultiFile.class);
Path in = new Path(args[0]);
Path out = new Path(args[1]);
FileInputFormat.setInputPaths(job, in);
FileOutputFormat.setOutputPath(job, out);
job.setJobName("MultiFile");
job.setMapperClass(MapClass.class);
job.setInputFormat(TextInputFormat.class);
job.setOutputFormat(PartitionByCountryMTOF.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
job.setNumReduceTasks(0);
JobClient.runJob(job);
return 0;
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new MultiFile(), args);
System.exit(res);
}
}
ІвКФКэҫЭј°Ҫб№ыЈә
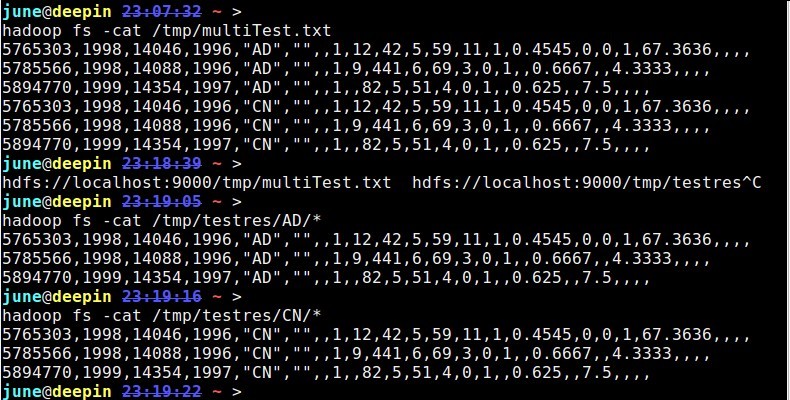
hadoop fs -cat /tmp/multiTest.txt
5765303,1998,14046,1996,"AD","",,1,12,42,5,59,11,1,0.4545,0,0,1,67.3636,,,,
5785566,1998,14088,1996,"AD","",,1,9,441,6,69,3,0,1,,0.6667,,4.3333,,,,
5894770,1999,14354,1997,"AD","",,1,,82,5,51,4,0,1,,0.625,,7.5,,,,
5765303,1998,14046,1996,"CN","",,1,12,42,5,59,11,1,0.4545,0,0,1,67.3636,,,,
5785566,1998,14088,1996,"CN","",,1,9,441,6,69,3,0,1,,0.6667,,4.3333,,,,
5894770,1999,14354,1997,"CN","",,1,,82,5,51,4,0,1,,0.625,,7.5,,,,
fromЈә
MultipleOutputFormat Example
http://mazd1002.blog.163.com/blog/static/665749652011102553947492/
2ЎўРВ°ж0.21.xј°Ц®әуөД°жұҫЈә
public class TestwithMultipleOutputs extends Configured implements Tool {
ЎЎЎЎpublic static class MapClass extends Mapper<LongWritable,Text,Text,IntWritable> {
ЎЎЎЎЎЎЎЎprivate MultipleOutputs<Text,IntWritable> mos;
ЎЎЎЎЎЎЎЎprotected void setup(Context context) throws IOException,InterruptedException {
ЎЎЎЎЎЎЎЎЎЎЎЎmos = new MultipleOutputs<Text,IntWritable>(context);
ЎЎЎЎЎЎЎЎ}
ЎЎЎЎЎЎЎЎpublic void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{
ЎЎЎЎЎЎЎЎЎЎЎЎString line = value.toString();
ЎЎЎЎЎЎЎЎЎЎЎЎString[] tokens = line.split("-");
ЎЎЎЎЎЎЎЎЎЎЎЎmos.write("MOSInt",new Text(tokens[0]), new IntWritable(Integer.parseInt(tokens[1]))); //ЈЁөЪТ»ҙҰЈ©
ЎЎЎЎЎЎЎЎЎЎЎЎmos.write("MOSText", new Text(tokens[0]),tokens[2]);ЎЎЎЎЎЎЎЎ //ЈЁөЪ¶юҙҰЈ©
ЎЎЎЎЎЎЎЎЎЎЎЎmos.write("MOSText", new Text(tokens[0]),line,tokens[0]+"/");ЎЎЎЎ//ЈЁөЪИэҙҰЈ©Н¬КұТІҝЙРҙөҪЦё¶ЁөДОДјю»тОДјюјРЦР
ЎЎЎЎЎЎЎЎ}
ЎЎЎЎЎЎЎЎprotected void cleanup(Context context) throws IOException,InterruptedException {
ЎЎЎЎЎЎЎЎЎЎЎЎmos.close();
ЎЎЎЎЎЎЎЎ}
ЎЎЎЎ}
ЎЎЎЎpublic int run(String[] args) throws Exception {
ЎЎЎЎЎЎЎЎConfiguration conf = getConf();
ЎЎЎЎЎЎЎЎJob job = new Job(conf,"word count with MultipleOutputs");
ЎЎЎЎЎЎЎЎjob.setJarByClass(TestwithMultipleOutputs.class);
ЎЎЎЎЎЎЎЎPath in = new Path(args[0]);
ЎЎЎЎЎЎЎЎPath out = new Path(args[1]);
ЎЎЎЎЎЎЎЎFileInputFormat.setInputPaths(job, in);
ЎЎЎЎЎЎЎЎFileOutputFormat.setOutputPath(job, out);
ЎЎЎЎЎЎЎЎjob.setMapperClass(MapClass.class);
ЎЎЎЎЎЎЎЎjob.setNumReduceTasks(0);ЎЎЎЎ
ЎЎЎЎЎЎЎЎMultipleOutputs.addNamedOutput(job,"MOSInt",TextOutputFormat.class,Text.class,IntWritable.class);
ЎЎЎЎЎЎЎЎMultipleOutputs.addNamedOutput(job,"MOSText",TextOutputFormat.class,Text.class,Text.class);
ЎЎЎЎЎЎЎЎSystem.exit(job.waitForCompletion(true)?0:1);
ЎЎЎЎЎЎЎЎreturn 0;
ЎЎЎЎ}
ЎЎЎЎpublic static void main(String[] args) throws Exception {
ЎЎЎЎЎЎЎЎint res = ToolRunner.run(new Configuration(), new TestwithMultipleOutputs(), args);
ЎЎЎЎЎЎЎЎSystem.exit(res);
ЎЎЎЎ}
}
ІвКФөДКэҫЭЈә
abc-1232-hdf
abc-123-rtd
ioj-234-grjth
ntg-653-sdgfvd
kju-876-btyun
bhm-530-bhyt
hfter-45642-bhgf
bgrfg-8956-fmgh
jnhdf-8734-adfbgf
ntg-68763-nfhsdf
ntg-98634-dehuy
hfter-84567-drhuk
Ҫб№ыҪШНјЈәЈЁҪб№ыКдіцөҪ/test/testMOSoutЈ©

PSЈәУцөҪөДТ»ёцОКМвЈә
ЎЎЎЎИз№ыГ»УРmos.close(), іМРтФЛРРЦР»біцПЦТміЈЈә
ЎЎЎЎ12/05/21 20:12:47 WARN hdfs.DFSClient: DataStreamer Exception:
ЎЎЎЎorg.apache.hadoop.ipc.RemoteException:org.apache.hadoop.hdfs.server.namenode.LeaseExpiredException: No lease on
ЎЎЎЎ/test/mosreduce/_temporary/_attempt_local_0001_r_000000_0/h-r-00000 File does not exist. [Lease. Holder: DFSClient_-352105532, pendingcreates: 5]
fromЈә
MultipleOutputFormatәНMultipleOutputs
http://www.cnblogs.com/liangzh/archive/2012/05/22/2512264.html
HadoopАыУГPartitioner¶ФКдіцОДјю·ЦАаЈЁёДРҙpartitionЈ¬В·УЙөҪЦё¶ЁөДОДјюЦРЈ©
http://superlxw1234.iteye.com/blog/1495465
http://ghost-face.iteye.com/blog/1869926
ёь¶аІОҝј&НЖјцФД¶БЈә
1ЎўЎҫHadoopЎҝАыУГMultipleOutputs,MultiOutputFormatКөПЦТФІ»Н¬ёсКҪКдіцөҪ¶аёцОДјю
http://www.cnblogs.com/iDonal/archive/2012/08/07/2626588.html
2Ўўcdh3u3 hadoop 0.20.2 MultipleOutputs ¶аКдіцОДјюіхМҪ
http://my.oschina.net/wangjiankui/blog/49521
3ЎўК№УГMultipleOutputs
http://blog.163.com/ecy_fu/blog/static/444512620101274344951/
4ЎўHadoop reduce¶аёцКдіц
http://blog.csdn.net/inte_sleeper/article/details/7042020
5ЎўHadoop 0.20.2ЦРФхГҙК№УГMultipleOutputFormatКөПЦ¶аОДјюКдіцәННкИ«ЧФ¶ЁТеОДјюГы
http://www.cnblogs.com/flying5/archive/2011/05/04/2078407.html
6ЎўHadoop OutputFormatЗіОц
http://zhb-mccoy.iteye.com/blog/1591635
7ЎўothersЈә
https://sites.google.com/site/hadoopandhive/home/how-to-write-output-to-multiple-named-files-in-hadoop-using-multipletextoutputformat
https://issues.apache.org/jira/browse/HADOOP-3149
http://grokbase.com/t/hadoop/common-user/112ewx7s15/could-i-write-outputs-in-multiple-directories
8ЎўMultipleOutputs №Щ·Ҫ·¶Аэ
http://hadoop.apache.org/docs/stable/api/org/apache/hadoop/mapreduce/lib/output/MultipleOutputs.html
9Ўў¶аКэҫЭФҙКдИлЈәMultipleInputs
https://groups.google.com/forum/#!topic/nosql-databases/SH61smOV-mo
http://bigdataprocessing.wordpress.com/2012/07/27/hadoop-hbase-mapreduce-examples/
http://hbase.apache.org/book/mapreduce.example.html
10ЎўHadoop¶аОДјюКдіцЈәMultipleOutputFormatәНMultipleOutputsЙоҫҝ
http://www.iteblog.com/archives/842 ЈЁТ»Ј©
http://www.iteblog.com/archives/848 ЈЁ¶юЈ©
(ФрИОұајӯЈәIT)
ЧоҪьҝјВЗөҪХвСщТ»ёцРиЗуЈә РиТӘ°СФӯКјөДИХЦҫОДјюУГhadoopЧцЗеПҙәуЈ¬°ҙТөОсПЯКдіцөҪІ»Н¬өДДҝВјПВИҘЈ¬ТФ№©І»Н¬өДІҝГЕТөОсПЯК№УГЎЈ ХвёцРиЗуРиТӘУГөҪMultipleOutputFormatәНMultipleOutputsАҙКөПЦЧФ¶ЁТе¶аДҝВјЎўОДјюөДКдіцЎЈ РиТӘЧўТвөДКЗЈ¬ФЪhadoop 0.21.xЦ®З°әНЦ®әуөДК№УГ·ҪКҪКЗІ»Т»СщөДЈә hadoop 0.21 Ц®З°өДAPI ЦРУР org.apache.hadoop.mapred.lib.MultipleOutputFormat әН org.apache.hadoop.mapred.lib.MultipleOutputsЈ¬¶шөҪБЛ 0.21 Ц®әу өДAPIОӘ org.apache.hadoop.mapreduce.lib.output.MultipleOutputs Ј¬ РВ°жөДAPI ХыәПБЛЙПГжҫЙAPIБҪёцөД№ҰДЬЈ¬Г»УРБЛMultipleOutputFormatЎЈ
ұҫОДҪ«ёшіцРВҫЙБҪёц°жұҫөДAPI codeЎЈ 1ЎўҫЙ°ж0.21.xЦ®З°өД°жұҫЈә
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.lib.MultipleTextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class MultiFile extends Configured implements Tool {
public static class MapClass extends MapReduceBase implements
Mapper<LongWritable, Text, NullWritable, Text> {
@Override
public void map(LongWritable key, Text value,
OutputCollector<NullWritable, Text> output, Reporter reporter)
throws IOException {
output.collect(NullWritable.get(), value);
}
}
// MultipleTextOutputFormat јМіРЧФMultipleOutputFormatЈ¬КөПЦКдіцОДјюөД·ЦАа
public static class PartitionByCountryMTOF extends
MultipleTextOutputFormat<NullWritable, Text> { // key is
// NullWritable,
// value is Text
protected String generateFileNameForKeyValue(NullWritable key,
Text value, String filename) {
String[] arr = value.toString().split(",", -1);
String country = arr[4].substring(1, 3); // »сИЎcountryөДГыіЖ
return country + "/" + filename;
}
}
// ҙЛҙҰІ»К№УГreducer
/*
* public static class Reducer extends MapReduceBase implements
* org.apache.hadoop.mapred.Reducer<LongWritable, Text, NullWritable, Text>
* {
*
* @Override public void reduce(LongWritable key, Iterator<Text> values,
* OutputCollector<NullWritable, Text> output, Reporter reporter) throws
* IOException { // TODO Auto-generated method stub
*
* }
*
* }
*/
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
JobConf job = new JobConf(conf, MultiFile.class);
Path in = new Path(args[0]);
Path out = new Path(args[1]);
FileInputFormat.setInputPaths(job, in);
FileOutputFormat.setOutputPath(job, out);
job.setJobName("MultiFile");
job.setMapperClass(MapClass.class);
job.setInputFormat(TextInputFormat.class);
job.setOutputFormat(PartitionByCountryMTOF.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
job.setNumReduceTasks(0);
JobClient.runJob(job);
return 0;
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new MultiFile(), args);
System.exit(res);
}
}
ІвКФКэҫЭј°Ҫб№ыЈә
hadoop fs -cat /tmp/multiTest.txt 5765303,1998,14046,1996,"AD","",,1,12,42,5,59,11,1,0.4545,0,0,1,67.3636,,,, 5785566,1998,14088,1996,"AD","",,1,9,441,6,69,3,0,1,,0.6667,,4.3333,,,, 5894770,1999,14354,1997,"AD","",,1,,82,5,51,4,0,1,,0.625,,7.5,,,, 5765303,1998,14046,1996,"CN","",,1,12,42,5,59,11,1,0.4545,0,0,1,67.3636,,,, 5785566,1998,14088,1996,"CN","",,1,9,441,6,69,3,0,1,,0.6667,,4.3333,,,, 5894770,1999,14354,1997,"CN","",,1,,82,5,51,4,0,1,,0.625,,7.5,,,,
fromЈә MultipleOutputFormat Example http://mazd1002.blog.163.com/blog/static/665749652011102553947492/
2ЎўРВ°ж0.21.xј°Ц®әуөД°жұҫЈә
public class TestwithMultipleOutputs extends Configured implements Tool {
ЎЎЎЎpublic static class MapClass extends Mapper<LongWritable,Text,Text,IntWritable> {
ЎЎЎЎЎЎЎЎprivate MultipleOutputs<Text,IntWritable> mos;
ЎЎЎЎЎЎЎЎprotected void setup(Context context) throws IOException,InterruptedException {
ЎЎЎЎЎЎЎЎЎЎЎЎmos = new MultipleOutputs<Text,IntWritable>(context);
ЎЎЎЎЎЎЎЎ}
ЎЎЎЎЎЎЎЎpublic void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{
ЎЎЎЎЎЎЎЎЎЎЎЎString line = value.toString();
ЎЎЎЎЎЎЎЎЎЎЎЎString[] tokens = line.split("-");
ЎЎЎЎЎЎЎЎЎЎЎЎmos.write("MOSInt",new Text(tokens[0]), new IntWritable(Integer.parseInt(tokens[1]))); //ЈЁөЪТ»ҙҰЈ©
ЎЎЎЎЎЎЎЎЎЎЎЎmos.write("MOSText", new Text(tokens[0]),tokens[2]);ЎЎЎЎЎЎЎЎ //ЈЁөЪ¶юҙҰЈ©
ЎЎЎЎЎЎЎЎЎЎЎЎmos.write("MOSText", new Text(tokens[0]),line,tokens[0]+"/");ЎЎЎЎ//ЈЁөЪИэҙҰЈ©Н¬КұТІҝЙРҙөҪЦё¶ЁөДОДјю»тОДјюјРЦР
ЎЎЎЎЎЎЎЎ}
ЎЎЎЎЎЎЎЎprotected void cleanup(Context context) throws IOException,InterruptedException {
ЎЎЎЎЎЎЎЎЎЎЎЎmos.close();
ЎЎЎЎЎЎЎЎ}
ЎЎЎЎ}
ЎЎЎЎpublic int run(String[] args) throws Exception {
ЎЎЎЎЎЎЎЎConfiguration conf = getConf();
ЎЎЎЎЎЎЎЎJob job = new Job(conf,"word count with MultipleOutputs");
ЎЎЎЎЎЎЎЎjob.setJarByClass(TestwithMultipleOutputs.class);
ЎЎЎЎЎЎЎЎPath in = new Path(args[0]);
ЎЎЎЎЎЎЎЎPath out = new Path(args[1]);
ЎЎЎЎЎЎЎЎFileInputFormat.setInputPaths(job, in);
ЎЎЎЎЎЎЎЎFileOutputFormat.setOutputPath(job, out);
ЎЎЎЎЎЎЎЎjob.setMapperClass(MapClass.class);
ЎЎЎЎЎЎЎЎjob.setNumReduceTasks(0);ЎЎЎЎ
ЎЎЎЎЎЎЎЎMultipleOutputs.addNamedOutput(job,"MOSInt",TextOutputFormat.class,Text.class,IntWritable.class);
ЎЎЎЎЎЎЎЎMultipleOutputs.addNamedOutput(job,"MOSText",TextOutputFormat.class,Text.class,Text.class);
ЎЎЎЎЎЎЎЎSystem.exit(job.waitForCompletion(true)?0:1);
ЎЎЎЎЎЎЎЎreturn 0;
ЎЎЎЎ}
ЎЎЎЎpublic static void main(String[] args) throws Exception {
ЎЎЎЎЎЎЎЎint res = ToolRunner.run(new Configuration(), new TestwithMultipleOutputs(), args);
ЎЎЎЎЎЎЎЎSystem.exit(res);
ЎЎЎЎ}
}
ІвКФөДКэҫЭЈә
abc-1232-hdf Ҫб№ыҪШНјЈәЈЁҪб№ыКдіцөҪ/test/testMOSoutЈ©
PSЈәУцөҪөДТ»ёцОКМвЈә ЎЎЎЎИз№ыГ»УРmos.close(), іМРтФЛРРЦР»біцПЦТміЈЈә ЎЎЎЎ12/05/21 20:12:47 WARN hdfs.DFSClient: DataStreamer Exception:
ЎЎЎЎorg.apache.hadoop.ipc.RemoteException:org.apache.hadoop.hdfs.server.namenode.LeaseExpiredException: No lease on fromЈә MultipleOutputFormatәНMultipleOutputshttp://www.cnblogs.com/liangzh/archive/2012/05/22/2512264.html HadoopАыУГPartitioner¶ФКдіцОДјю·ЦАаЈЁёДРҙpartitionЈ¬В·УЙөҪЦё¶ЁөДОДјюЦРЈ© http://superlxw1234.iteye.com/blog/1495465 http://ghost-face.iteye.com/blog/1869926 ёь¶аІОҝј&НЖјцФД¶БЈә 1ЎўЎҫHadoopЎҝАыУГMultipleOutputs,MultiOutputFormatКөПЦТФІ»Н¬ёсКҪКдіцөҪ¶аёцОДјю http://www.cnblogs.com/iDonal/archive/2012/08/07/2626588.html 2Ўўcdh3u3 hadoop 0.20.2 MultipleOutputs ¶аКдіцОДјюіхМҪ http://my.oschina.net/wangjiankui/blog/49521 3ЎўК№УГMultipleOutputs http://blog.163.com/ecy_fu/blog/static/444512620101274344951/ 4ЎўHadoop reduce¶аёцКдіц http://blog.csdn.net/inte_sleeper/article/details/7042020 5ЎўHadoop 0.20.2ЦРФхГҙК№УГMultipleOutputFormatКөПЦ¶аОДјюКдіцәННкИ«ЧФ¶ЁТеОДјюГы http://www.cnblogs.com/flying5/archive/2011/05/04/2078407.html 6ЎўHadoop OutputFormatЗіОц http://zhb-mccoy.iteye.com/blog/1591635 7ЎўothersЈә
https://sites.google.com/site/hadoopandhive/home/how-to-write-output-to-multiple-named-files-in-hadoop-using-multipletextoutputformat 8ЎўMultipleOutputs №Щ·Ҫ·¶Аэ http://hadoop.apache.org/docs/stable/api/org/apache/hadoop/mapreduce/lib/output/MultipleOutputs.html 9Ўў¶аКэҫЭФҙКдИлЈәMultipleInputs https://groups.google.com/forum/#!topic/nosql-databases/SH61smOV-mo http://bigdataprocessing.wordpress.com/2012/07/27/hadoop-hbase-mapreduce-examples/ http://hbase.apache.org/book/mapreduce.example.html 10ЎўHadoop¶аОДјюКдіцЈәMultipleOutputFormatәНMultipleOutputsЙоҫҝ http://www.iteblog.com/archives/842 ЈЁТ»Ј© http://www.iteblog.com/archives/848 ЈЁ¶юЈ© (ФрИОұајӯЈәIT) |