CentOS 6.6使用 luci/ricci 安装配置 RHCS 集群
时间:2017-01-09 21:41 来源:linux.it.net.cn 作者:IT
1.配置 RHCS 集群的前提:
-
时间同步
-
名称解析,这里使用修改/etc/hosts 文件
-
配置好 yum 源,CentOS 6 的默认的就行
-
关闭防火墙(或者开放集群所需通信端口),和selinux,
-
关闭 NetworkManager 服务
2. RHCS 所需要的主要软件包为 cman 和 rgmanager
cman: 是集群基础信息层,在 CentOS 6中依赖 corosync
rgmanager: 是集群资源管理器, 类似于pacemaker 的功能
luci: 提供了管理 rhcs 集群的 web 界面, luci 管理集群主要是通过跟 ricci 通信来完成的。
ricci: 安装在集群的节点的接收来自 luci 管理请求的代理。
luci 跟 ricci 的关系就好像 ambari-server 跟 ambari-agent 一样。
3.环境说明:
luci : 192.168.6.31 cent1.test.com
ricci: 192.168.6.32 cent2.test.com
ricci: 192.168.6.33 cent3.test.com
ricci: 192.168.6.34 cent4.test.com
我这里已经配好了主机名了,但是其他的如时间同步,配置/etc/hosts/ 等都没执行,为了方便,所以写了个playbook 来进行初始化一下
---
- hosts:hdpservers
remote_user: root
vars:
tasks:
- name: add synctime cron
cron: name='sync time' minute='*/5'job='/usr/sbin/ntpdate 192.168.6.31'
- name: shutdown iptables
service: name={{item.name}}state={{item.state}} enabled={{item.enabled}}
with_items:
- { name: iptables, state: stopped,enabled: no}
- { name: NetworkManager, state: stopped,enabled: no}
tags: stop service
- name: copy selinux conf file
copy: src={{item.src}} dest={{item.dest}}owner={{item.owner}} group={{item.group}} mode={{item.mode}}
with_items:
- { src=\'#\'" /etc/selinux/config', dest:/etc/selinux/config, owner: root, group: root, mode: '0644'}
- { src=\'#\'" /etc/hosts', dest: /etc/hosts,owner: root, group: root, mode: '0644'}
- name: cmd off selinux
shell: setenforce 0
执行这个 playbook,进行初始化
[root@cent1 yaml]#ansible-playbook base.yml
4.在 cent1 上安装 luci, luci 是一个 python 程序,依赖很多python包
[root@cent1 ~]#yum install luci
启动 luci
[root@cent3 ~]#/etc/init.d/luci start
Adding followingauto-detected host IDs (IP addresses/domain names), corresponding to `cent3'address, to the configuration of self-managed certificate`/var/lib/luci/etc/cacert.config' (you can change them by editing`/var/lib/luci/etc/cacert.config', removing the generated certificate`/var/lib/luci/certs/host.pem' and restarting luci):
(none suitable found, you can still doit manually as mentioned above)
Generating a 2048bit RSA private key
writing newprivate key to '/var/lib/luci/certs/host.pem'
正在启动saslauthd: [确定]
Start luci... [确定]
Point your webbrowser to https://cent1.hfln.com:8084 (or equivalent) to access luci
现在可以在前台登录luci 了,看清是 https 哦
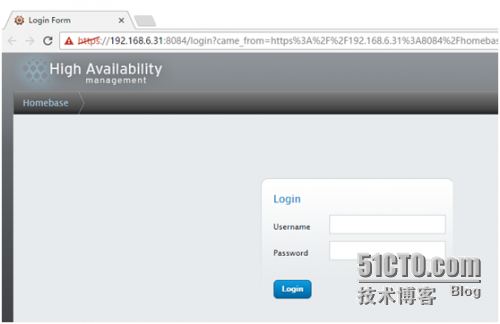
账号密码就是这台主机的账号和密码
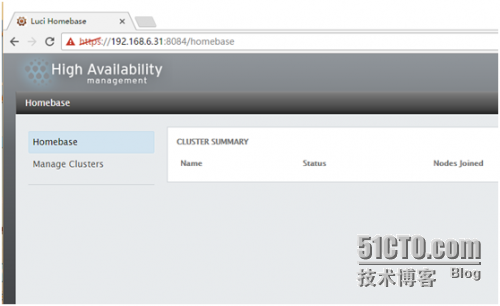
登录成功啦,现在来配置 rhcs 的集群,这个只是用来管理集群的,真正的集群还没开始装呢。
5.在 cnet2, cent3, cent4 中安装 ricci, ricci 也依赖很多软件,这里使用 ansible 直接在三个节点上装, 当然我已经配好了 cent1 到 其他节点的免密钥登录了
[root@cent1 ~]#ansible rhcs -m yum -a "name=ricci"
装好ricci 之后还要在 node 节点上给 ricci 用户设置密码,ricci用户就是运行 ricci进程的用户,这个密码一会要用,这里就简单粗暴了,这个密码还可以用 ccs命令来进行设置
[root@cent1 ~]#ansible rhcs -m shell -a "echo '123456' | passwd --stdin ricci"
启动 ricci
[root@cent1 ~]#ansible rhcs -m service -a "name=ricci state=started enabled=yes"
[root@cent2 ~]# ss-tunlp |grep ricci
tcp LISTEN 0 5 :::11111 :::* users:(("ricci",3237,3))
ricci 监听在 11111 端口,像这种操作当然也是可以写到 playbook 当中的
6. 现在可以在web 界面上配置集群了,比如创建/添加/删除一个集群,管理node, resource, fence device, servicegroups, Failover Domains 等等集群的全生命周期都可以在这里完成。
这里演示一个关于 web服务的高可用服务
Manage Clusters--> Create 是创建一个集群
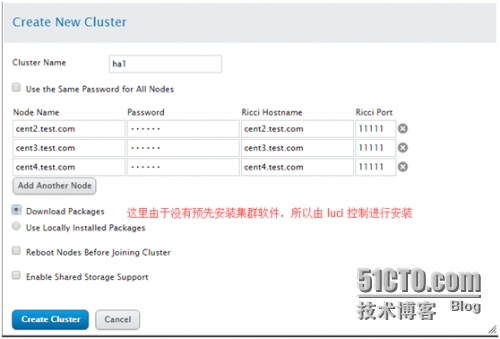
这个界面还算简单吧;
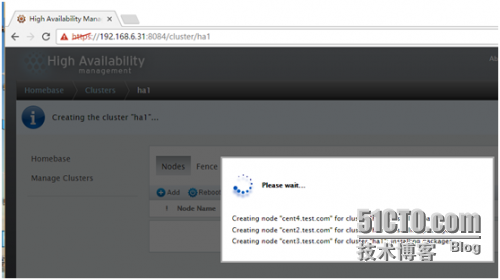
Create Cluster 之后,那么就开始尝试安装集群软件了.
在任意一个node上可以看到 ricci 的工作进程:
[root@cent2 ~]# psaux |grep ricci
ricci 3453 0.1 0.4 213664 4400 ? S<s 17:18 0:00 ricci -u ricci
ricci 3489 0.0 0.1 54912 1908 ? S<s 17:22 0:00 /usr/libexec/ricci/ricci-worker -f /var/lib/ricci/queue/1500004777
root 3490 0.2 0.5 48552 5136 ? S 17:22 0:00 ricci-modrpm
root 3567 0.0 0.0 103252 880 pts/0 S+ 17:24 0:00 grep ricci
/var/lib/ricci/queue/目录下存放的是 luci 发给 ricci 的任务文件,是 XML 格式的
[root@cent2 ~]#file /var/lib/ricci/queue/1500004777
/var/lib/ricci/queue/1500004777:XML document text
7. 安装成功了
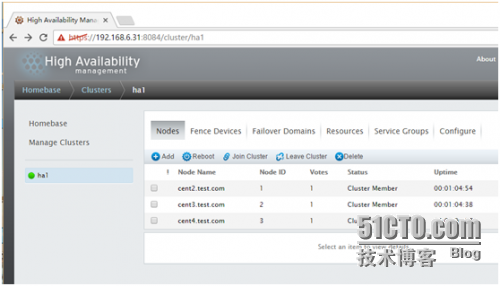
可以点任何一个node 进去看看
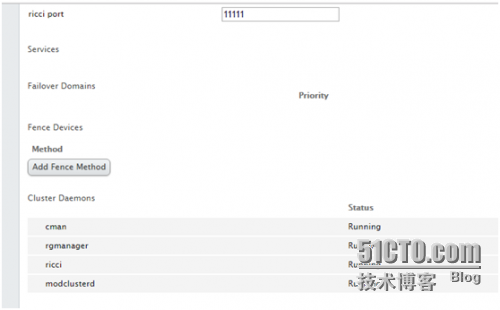
如果这底下的服务没启动的话,可以尝试手动起一下,一般来说是OK的。
8.添加资源
这里没有 fence 设备,不关注这个,添加两个公共资源,并添加一个服务,然后来启动服务
Resources -->Add : 添加一个资源

添加一个虚拟IP,这里的 mask 要写成上面这样,不能写成 255.255.255.0 这种,否则会导致无法添加IP
rgmanager Startingstopped service service:web1
rgmanager start onip "192.168.6.100/255.255.255.0" returned 1 (generic error)
rgmanager #68:Failed to start service:web1; return value: 1
再添加一个script资源
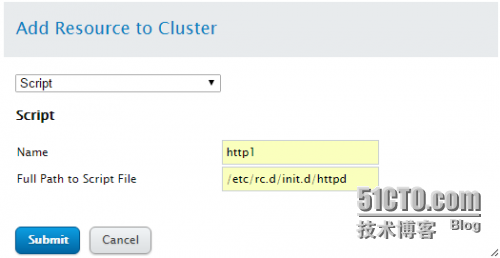
9.添加 Service
这里的资源是共公的,假如这个集群内有多个服务,那么都可以使用这些资源,也可以在
Service Groups 里添加一个私有的资源。
现在添加一个Service:
Service Groups--> Add : 添加一个 Service,
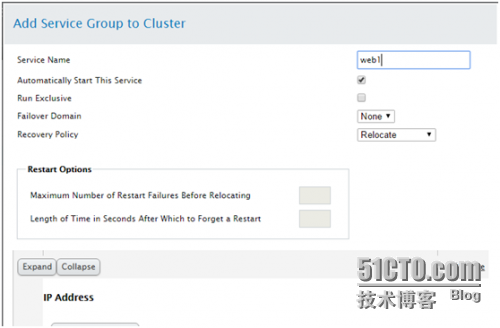
Add Resource 将刚才建立的两个资源添加进来;
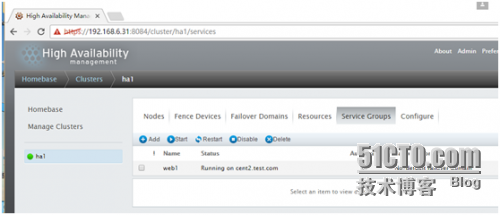
现在在集群的节点上用命令查看一下,集群内的任何节点都可以
[root@cent3 ~]#clustat
Cluster Status forha1 @ Sun Jan 8 17:47:40 2017
Member Status:Quorate
Member Name ID Status
------ ---- ---- ------
cent2.test.com 1 Online, rgmanager
cent3.test.com 2 Online, Local, rgmanager
cent4.test.com 3 Online, rgmanager
Service Name Owner (Last) State
------- ---- ----- ------ -----
service:web1 cent2.test.com started
在 cent2 上 ip 和httpd 服务都已经起来了
[root@cent2 ~]# ipa
1: lo:<LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0:<BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen1000
link/ether 00:0c:29:91:b3:11 brdff:ff:ff:ff:ff:ff
inet 192.168.6.32/24 brd 192.168.6.255scope global eth0
inet 192.168.6.100/24 scope global secondaryeth0
inet6 fe80::20c:29ff:fe91:b311/64 scopelink
valid_lft forever preferred_lft forever
[root@cent2 ~]#netstat -tunlp |grep 80
tcp 0 0 :::80 :::* LISTEN 34901/httpd
10.测试故障转移:
关于 rhcs 中 service 的健康状态检测, 可以通过 /var/log/cluster/rgmanager.log 日志来查看
Jan 08 18:56:59rgmanager [ip] Checking 192.168.6.100/24, Level 10
Jan 08 18:56:59rgmanager [ip] 192.168.6.100/24 present on eth0
Jan 08 18:56:59rgmanager [ip] Link for eth0: Detected
Jan 08 18:56:59rgmanager [ip] Link detected on eth0
Jan 08 18:56:59rgmanager [ip] Local ping to 192.168.6.100 succeeded
这里可以看到他会尝试查看和 ping 192.168.6.100 ,这是针对 IP 资源的检测方式
Jan 08 18:55:49rgmanager [script] Executing /etc/rc.d/init.d/httpd status
上面是 script 资源的检测方式则是仅仅去用脚本来执行 status 参数。
在我尝试将/etc/init.d/httpd/ stop 后,日志出现了如下:
Jan 08 18:56:59rgmanager [script] Executing /etc/rc.d/init.d/httpd status
Jan 08 18:56:59rgmanager [script] script:http1: status of /etc/rc.d/init.d/httpd failed(returned 3)
# 这里发现检测失败了
Jan 08 18:56:59rgmanager status on script "http1" returned 1 (generic error)
Jan 08 18:56:59rgmanager Stopping service service:web1
Jan 08 18:56:59rgmanager [script] Executing /etc/rc.d/init.d/httpd stop
Jan 08 18:56:59rgmanager [ip] Removing IPv4 address 192.168.6.100/24 from eth0
# 以上几步在这个节点停止了 web1 服务
Jan 08 18:57:09rgmanager Service service:web1 is recovering
Jan 08 18:57:14rgmanager Service service:web1 is now running on member 2
# 将web1 服务在 member 2 上恢复了,member 2 也就是 cent3.test.com
查看转移后的集群状态:
[root@cent3 ~]# clustat
Cluster Status for ha1 @ Sun Jan 8 20:25:26 2017
Member Status: Quorate
Member Name ID Status
------ ---- ---- ------
cent2.test.com 1 Online, rgmanager
cent3.test.com 2 Online, Local, rgmanager
cent4.test.com 3 Online, rgmanager
Service Name Owner (Last) State
------- ---- ----- ------ -----
service:web1 cent3.test.com started
如果这种 script 的资源不符合你的需求,那么可以尝试 apache 资源。即使你认为这种 script 的资源检查方式过于简单,也可以在脚本里添加功能来达到你的目的。
11.尝试关闭节点,查看 Service 转移情况:
在关掉 cent3 之后,service 转移到了 cent4上
[root@cent2 ~]#clustat
Cluster Status forha1 @ Sun Jan 8 20:35:42 2017
Member Status:Quorate
Member Name ID Status
------ ---- ---- ------
cent2.test.com 1 Online, Local, rgmanager
cent3.test.com 2 Offline
cent4.test.com 3 Online, rgmanager
Service Name Owner (Last) State
------- ---- ----- ------ -----
service:web1 cent4.test.com started
接着关掉了 cent4,Service 又转移到了 cent2
[root@cent2 ~]#clustat
Cluster Status forha1 @ Sun Jan 8 20:36:27 2017
Member Status:Quorate
Member Name ID Status
------ ---- ---- ------
cent2.test.com 1 Online, Local, rgmanager
cent3.test.com 2 Offline
cent4.test.com 3 Online
Service Name Owner (Last) State
------- ---- ----- ------ -----
service:web1 cent2.test.com started
这里的 cent4.test.com 仍然显示 Online 是因为正在关机当中,尚未真正关闭。
过了几秒,弹出了以下提示信息:
[root@cent2 ~]#
Message fromsyslogd@cent2 at Jan 8 20:36:42 ...
rgmanager[5685]: #1: Quorum Dissolved
日志里显示:
Jan 08 20:35:01rgmanager Member 2 shutting down
Jan 08 20:36:18rgmanager Member 3 shutting down
Jan 08 20:36:18rgmanager Starting stopped service service:web1
Jan 08 20:36:18rgmanager [ip] Link for eth0: Detected
Jan 08 20:36:19rgmanager [ip] Adding IPv4 address 192.168.6.100/24 to eth0
Jan 08 20:36:19rgmanager [ip] Pinging addr 192.168.6.100 from dev eth0
Jan 08 20:36:21rgmanager [ip] Sending gratuitous ARP: 192.168.6.100 00:0c:29:91:b3:11 brdff:ff:ff:ff:ff:ff
Jan 08 20:36:22rgmanager [script] Executing /etc/rc.d/init.d/httpd start
Jan 08 20:36:22rgmanager Service service:web1 started
Jan 08 20:36:42rgmanager #1: Quorum Dissolved
Message fromsyslogd@cent2 at Jan 8 20:36:42 ...
rgmanager[5685]: #1: Quorum Dissolved
Jan 08 20:36:42rgmanager [script] Executing /etc/rc.d/init.d/httpd stop
Jan 08 20:36:42rgmanager [ip] Removing IPv4 address 192.168.6.100/24 from eth0
服务停止了,这是因为 法定票数不足的原因
[root@cent2 ~]#clustat
Service statesunavailable: Operation requires quorum
Cluster Status forha1 @ Sun Jan 8 20:37:00 2017
Member Status:Inquorate
Member Name ID Status
------ ---- ---- ------
cent2.test.com 1 Online, Local
cent3.test.com 2 Offline
cent4.test.com 3 Offline
(责任编辑:IT)
1.配置 RHCS 集群的前提:
2. RHCS 所需要的主要软件包为 cman 和 rgmanager
cman: 是集群基础信息层,在 CentOS 6中依赖 corosync rgmanager: 是集群资源管理器, 类似于pacemaker 的功能
luci: 提供了管理 rhcs 集群的 web 界面, luci 管理集群主要是通过跟 ricci 通信来完成的。 ricci: 安装在集群的节点的接收来自 luci 管理请求的代理。
luci 跟 ricci 的关系就好像 ambari-server 跟 ambari-agent 一样。
3.环境说明:
我这里已经配好了主机名了,但是其他的如时间同步,配置/etc/hosts/ 等都没执行,为了方便,所以写了个playbook 来进行初始化一下
执行这个 playbook,进行初始化
4.在 cent1 上安装 luci, luci 是一个 python 程序,依赖很多python包
启动 luci
现在可以在前台登录luci 了,看清是 https 哦
账号密码就是这台主机的账号和密码
登录成功啦,现在来配置 rhcs 的集群,这个只是用来管理集群的,真正的集群还没开始装呢。 5.在 cnet2, cent3, cent4 中安装 ricci, ricci 也依赖很多软件,这里使用 ansible 直接在三个节点上装, 当然我已经配好了 cent1 到 其他节点的免密钥登录了
装好ricci 之后还要在 node 节点上给 ricci 用户设置密码,ricci用户就是运行 ricci进程的用户,这个密码一会要用,这里就简单粗暴了,这个密码还可以用 ccs命令来进行设置
启动 ricci
ricci 监听在 11111 端口,像这种操作当然也是可以写到 playbook 当中的
6. 现在可以在web 界面上配置集群了,比如创建/添加/删除一个集群,管理node, resource, fence device, servicegroups, Failover Domains 等等集群的全生命周期都可以在这里完成。
这里演示一个关于 web服务的高可用服务 Manage Clusters--> Create 是创建一个集群
这个界面还算简单吧;
Create Cluster 之后,那么就开始尝试安装集群软件了. 在任意一个node上可以看到 ricci 的工作进程:
/var/lib/ricci/queue/目录下存放的是 luci 发给 ricci 的任务文件,是 XML 格式的
7. 安装成功了
可以点任何一个node 进去看看
如果这底下的服务没启动的话,可以尝试手动起一下,一般来说是OK的。
8.添加资源
这里没有 fence 设备,不关注这个,添加两个公共资源,并添加一个服务,然后来启动服务 Resources -->Add : 添加一个资源
添加一个虚拟IP,这里的 mask 要写成上面这样,不能写成 255.255.255.0 这种,否则会导致无法添加IP
再添加一个script资源
9.添加 Service 这里的资源是共公的,假如这个集群内有多个服务,那么都可以使用这些资源,也可以在 Service Groups 里添加一个私有的资源。 现在添加一个Service:
Service Groups--> Add : 添加一个 Service,
Add Resource 将刚才建立的两个资源添加进来;
现在在集群的节点上用命令查看一下,集群内的任何节点都可以
在 cent2 上 ip 和httpd 服务都已经起来了
10.测试故障转移:
关于 rhcs 中 service 的健康状态检测, 可以通过 /var/log/cluster/rgmanager.log 日志来查看
这里可以看到他会尝试查看和 ping 192.168.6.100 ,这是针对 IP 资源的检测方式
上面是 script 资源的检测方式则是仅仅去用脚本来执行 status 参数。 在我尝试将/etc/init.d/httpd/ stop 后,日志出现了如下:
查看转移后的集群状态:
如果这种 script 的资源不符合你的需求,那么可以尝试 apache 资源。即使你认为这种 script 的资源检查方式过于简单,也可以在脚本里添加功能来达到你的目的。
11.尝试关闭节点,查看 Service 转移情况: 在关掉 cent3 之后,service 转移到了 cent4上
接着关掉了 cent4,Service 又转移到了 cent2
这里的 cent4.test.com 仍然显示 Online 是因为正在关机当中,尚未真正关闭。 过了几秒,弹出了以下提示信息:
日志里显示:
服务停止了,这是因为 法定票数不足的原因
(责任编辑:IT) |