K8S集群基于heapster的HPA测试
时间:2018-05-09 11:13 来源:http://blog.51cto.com 作者:IT
本文将介绍基于heapster获取metric的HPA配置。在开始之前,有必要先了解一下K8S的HPA特性。
1、HPA全称Horizontal Pod Autoscaling,即pod的水平自动扩展。
自动扩展主要分为两种,其一为水平扩展,针对于实例数目的增减;其二为垂直扩展,即单个实例可以使用的资源的增减。HPA属于前者。
2、HPA是Kubernetes中实现POD水平自动伸缩的功能。
云计算具有水平弹性的特性,这个是云计算区别于传统IT技术架构的主要特性。对于Kubernetes中的POD集群来说,HPA可以实现很多自动化功能,比如当POD中业务负载上升的时候,可以创建新的POD来保证业务系统稳定运行,当POD中业务负载下降的时候,可以销毁POD来提高资源利用率。
3、HPA控制器默认每隔30秒就会运行一次。
如果要修改间隔时间,可以设置horizontal-pod-autoscaler-sync-period参数。
4、HPA的操作对象是RC、RS或Deployment对应的Pod
根据观察到的CPU等实际使用量与用户的期望值进行比对,做出是否需要增减实例数量的决策。
5、hpa的发展历程
在Kubernetes v1.1中首次引入了hpa特性。hpa第一个版本基于观察到的CPU利用率,后续版本支持基于内存使用。
在Kubernetes 1.6中引入了一个新的API自定义指标API,它允许HPA访问任意指标。
Kubernetes 1.7引入了聚合层,允许第三方应用程序通过注册为API附加组件来扩展Kubernetes API。自定义指标API以及聚合层使得像Prometheus这样的监控系统可以向HPA控制器公开特定于应用程序的指标。
一、准备工作
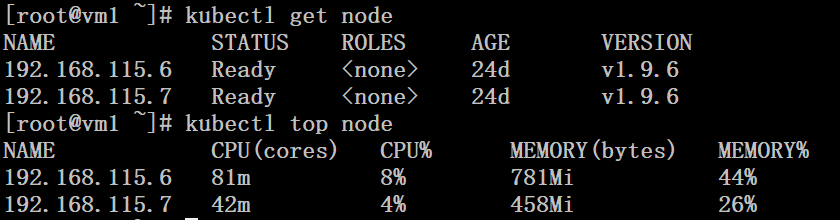
因为pod的metrics信息来源与heapster,所以在开始之前要保证heapster运行正常。heapster的配置可参考前文。我们可以通过运行kubectl top node来验证heapster是否运行正常。
二、针对CPU的HPA演示
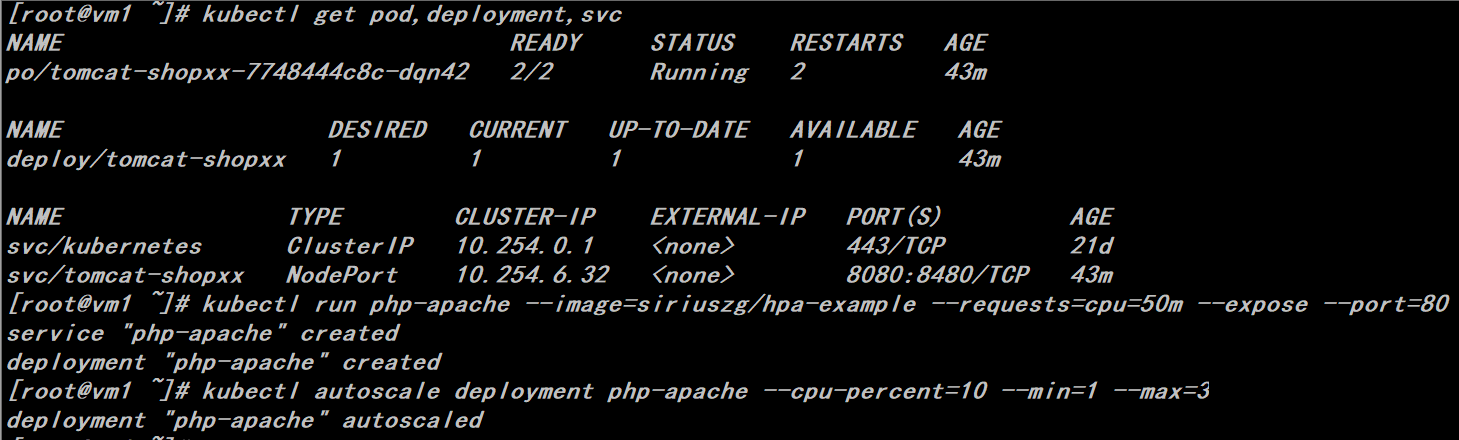
1、直接通过kubectl工具来创建hpa
# docker pull siriuszg/hpa-example
# kubectl get pod,deployment,svc
# kubectl run php-apache --image=siriuszg/hpa-example --requests=cpu=50m --expose --port=80
# kubectl autoscale deployment php-apache --cpu-percent=10 --min=1 --max=3
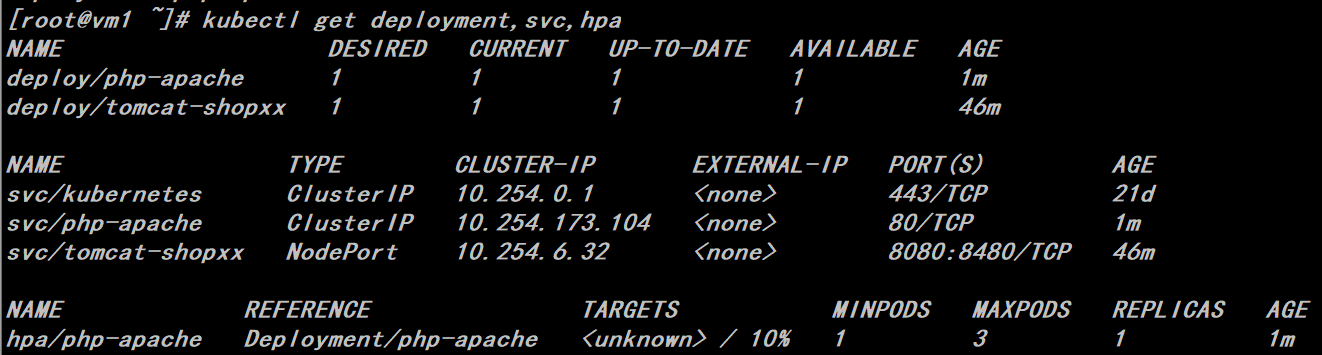
# kubectl get deployment,svc,hpa
2、运行一个deployment来制造压力
# kubectl run -i --tty load-generator --image=registry.59iedu.com/busybox /bin/sh
# nslookup php-apache
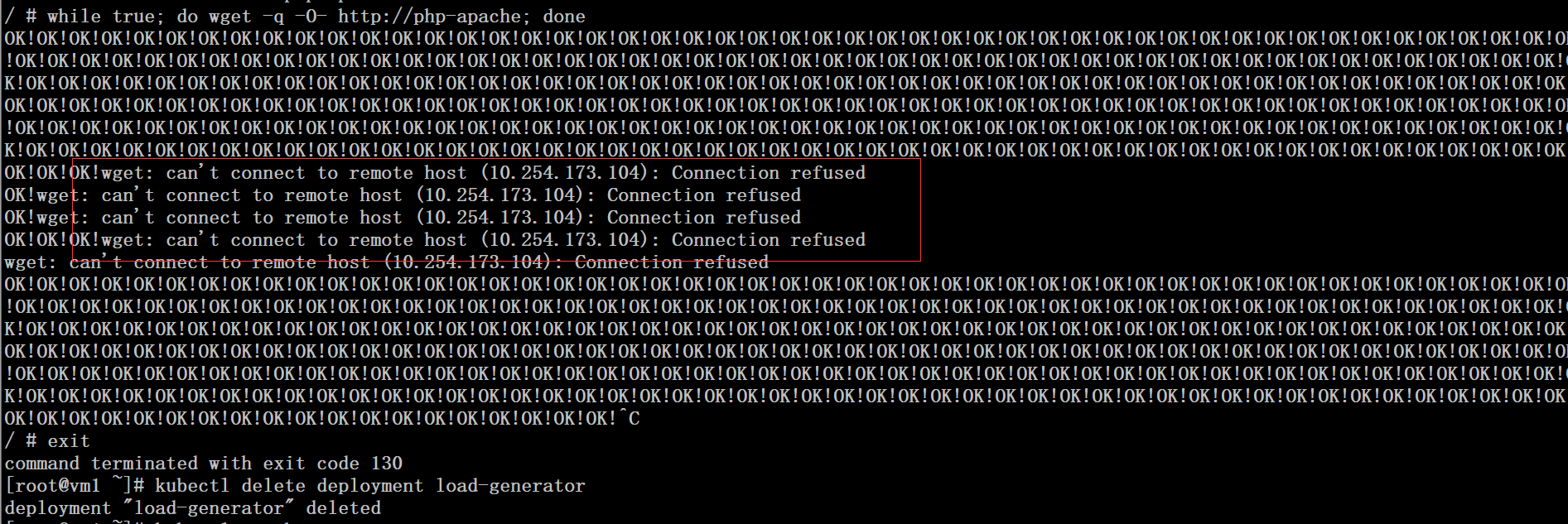
# while true; do wget -q -O- http://php-apache; done
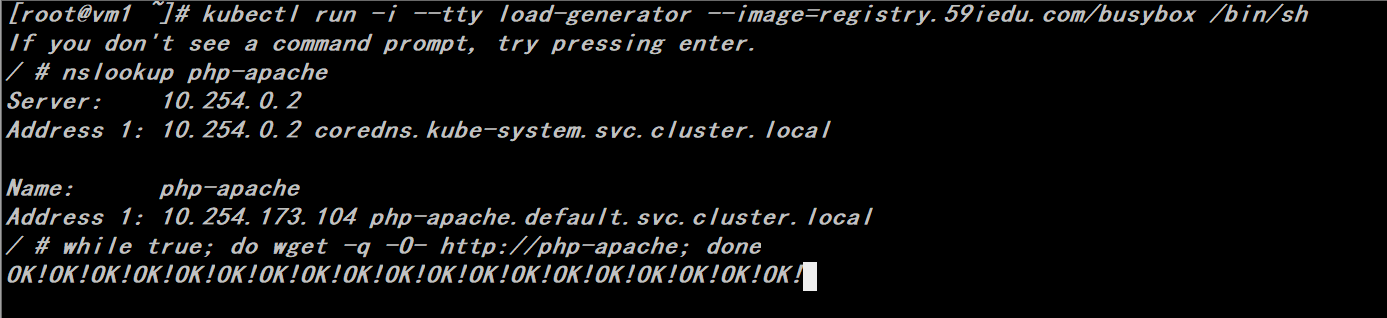
从输入的日志上看,可以看到自动扩展的过程中有出现“connection refused”,最后我们将制造压力的deployment删除
# kubectl delete deployment load-generator
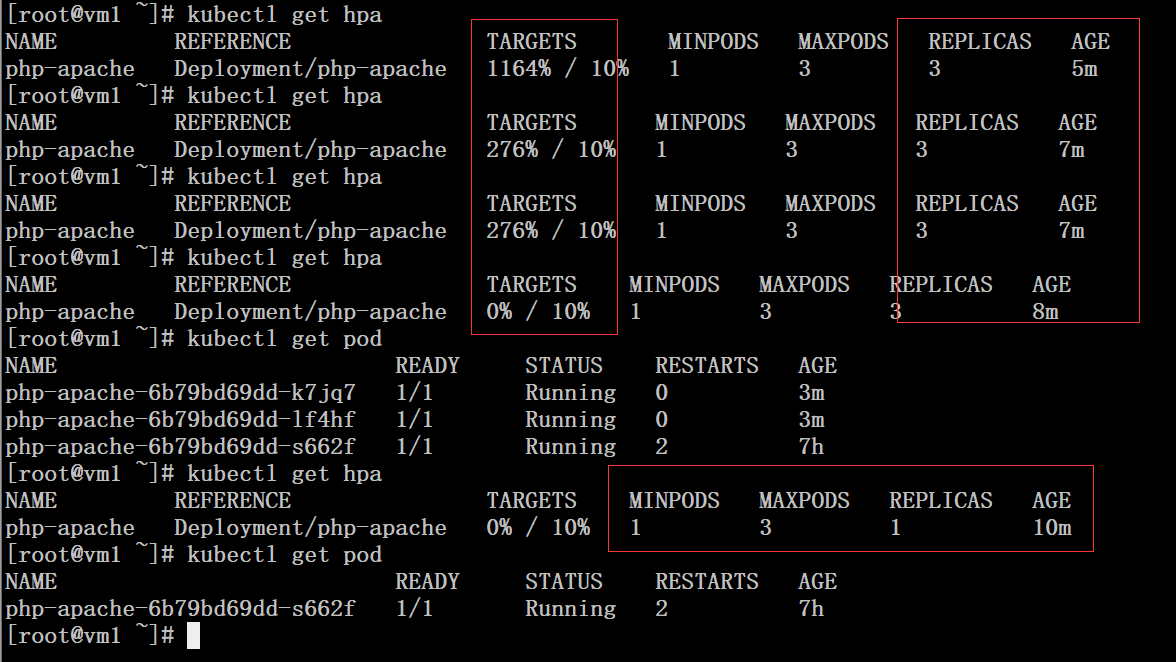
3、在整个过程中可以新开一个终端来观察hpa自动扩展和收缩的过程
4、排错
Warning FailedGetResourceMetric 12s (x41 over 20m) horizontal-pod-autoscaler unable to get metrics for resource cpu: unable to fetch metrics from API: the server could not find the requested resource (get pods.metrics.k8s.io)
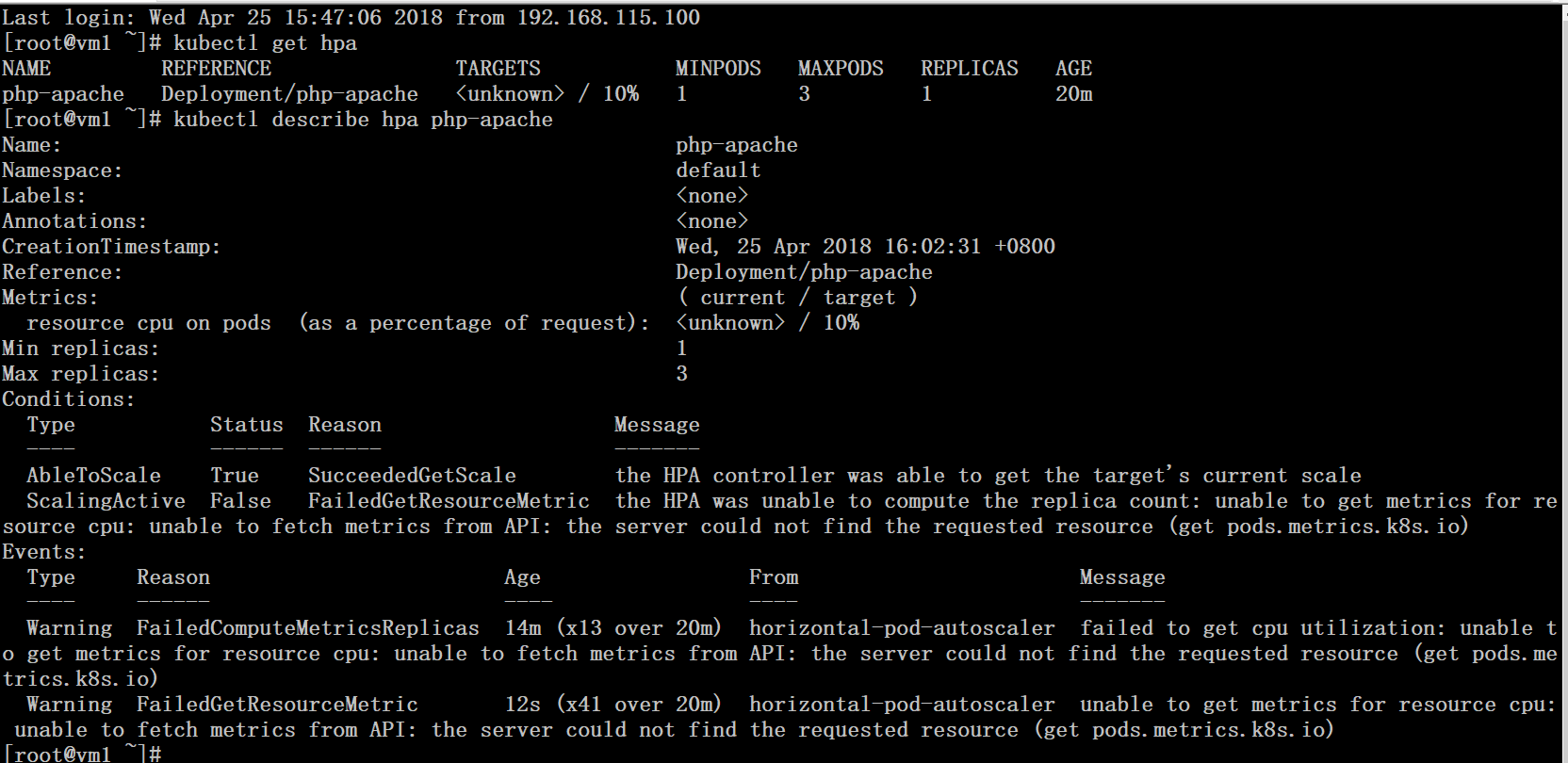
出现上述错误,需要修改kube-controller-manager的配置文件
# grep 'autoscaler' /usr/lib/systemd/system/kube-controller-manager.service
--horizontal-pod-autoscaler-use-rest-clients=false
# systemctl daemon-reload
systemctl restart kube-controller-manager
三、针对内存的HPA演示
1、通过yaml文件创建hpa
# cat hpa-memory.yaml
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: tomcat-shopxx-hpa
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1beta1
kind: Deployment
name: tomcat-shopxx
minReplicas: 1
maxReplicas: 3
metrics:
- type: Resource
resource:
name: memory
targetAverageUtilization: 30
# kubectl create -f hpa-memory.yaml
2、修改deployment的yaml文件,添加资源的requests和limit限制
如果没有相应的资源限制,则describe查看hpa会有报错信息“missing request for memory on container xxxx”
# cat tomcat.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: tomcat-shopxx
namespace: default
spec:
replicas: 1
template:
metadata:
labels:
k8s-app: tomcat-shopxx
spec:
containers:
- image: registry.59iedu.com/filebeat:v5.4.0
imagePullPolicy: Always
resources:
requests:
cpu: "50m"
memory: "20Mi"
limits:
cpu: "100m"
memory: "50Mi"
name: filebeat
volumeMounts:
- name: app-logs
mountPath: /log
- name: filebeat-config
mountPath: /etc/filebeat/
- image: registry.59iedu.com/tomcat_shopxx:v1
name : tomcat-shopxx
imagePullPolicy: Always
resources:
requests:
cpu: "50m"
memory: "200Mi"
limits:
cpu: "100m"
memory: "250Mi"
env:
- name: JAVA_OPTS
value: "-Xmx128m -Xms128m"
ports:
- containerPort: 8080
volumeMounts:
- name: app-logs
mountPath: /home/tomcat/logs
volumes:
- name: app-logs
emptyDir: {}
- name: filebeat-config
configMap:
name: filebeat-config
# kubectl apply -f tomcat..yaml
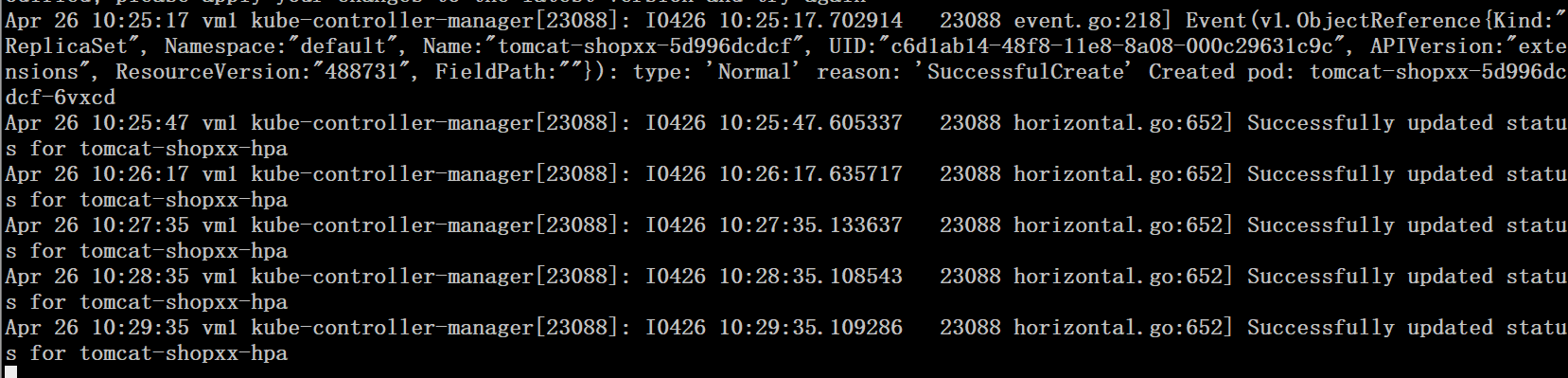
3、观察hpa过程
# journalctl -u kube-controller-manager.service -f
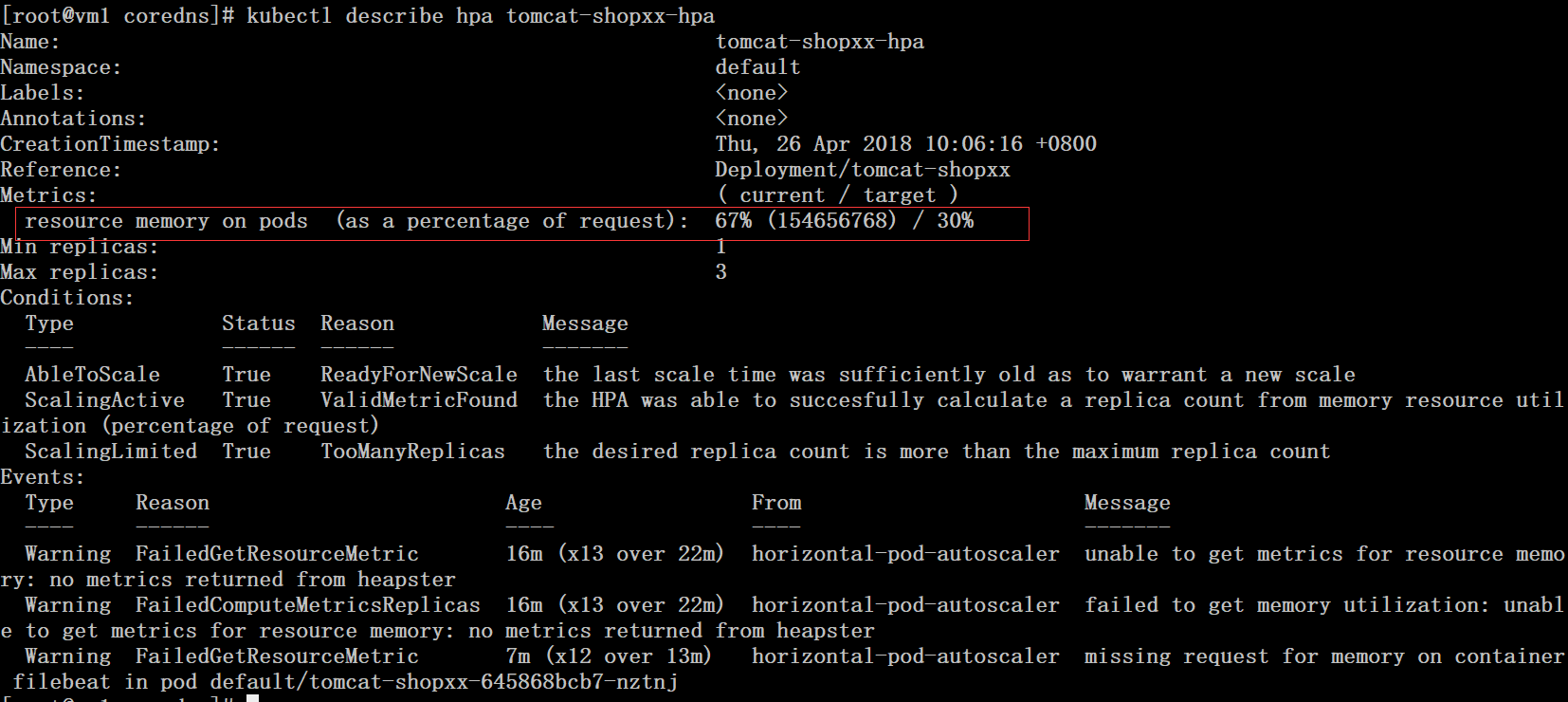
# kubectl describe hpa tomcat-shopxx-hpa
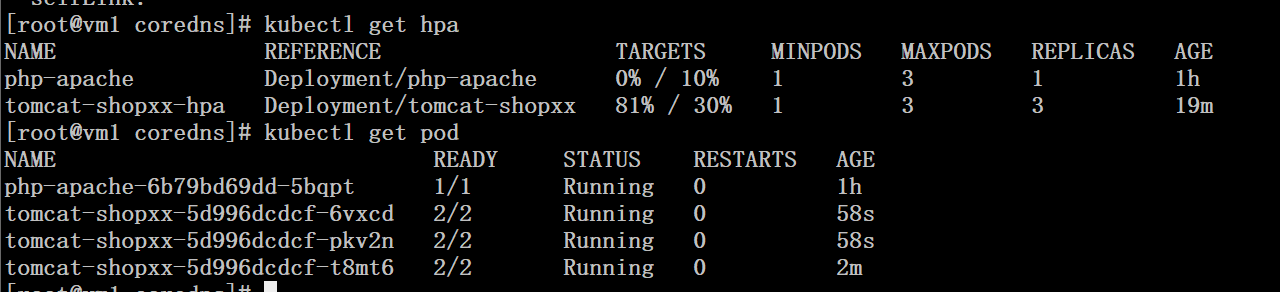
# kubectl get hpa
# kubectl get pod
下文将会介绍基于metric-server的hpa,尽请关注!
参考:
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
https://github.com/kubernetes/kubernetes/issues/57673
(责任编辑:IT)
| 本文将介绍基于heapster获取metric的HPA配置。在开始之前,有必要先了解一下K8S的HPA特性。 1、HPA全称Horizontal Pod Autoscaling,即pod的水平自动扩展。 自动扩展主要分为两种,其一为水平扩展,针对于实例数目的增减;其二为垂直扩展,即单个实例可以使用的资源的增减。HPA属于前者。 2、HPA是Kubernetes中实现POD水平自动伸缩的功能。 云计算具有水平弹性的特性,这个是云计算区别于传统IT技术架构的主要特性。对于Kubernetes中的POD集群来说,HPA可以实现很多自动化功能,比如当POD中业务负载上升的时候,可以创建新的POD来保证业务系统稳定运行,当POD中业务负载下降的时候,可以销毁POD来提高资源利用率。 3、HPA控制器默认每隔30秒就会运行一次。 如果要修改间隔时间,可以设置horizontal-pod-autoscaler-sync-period参数。 4、HPA的操作对象是RC、RS或Deployment对应的Pod 根据观察到的CPU等实际使用量与用户的期望值进行比对,做出是否需要增减实例数量的决策。 5、hpa的发展历程 在Kubernetes v1.1中首次引入了hpa特性。hpa第一个版本基于观察到的CPU利用率,后续版本支持基于内存使用。 在Kubernetes 1.6中引入了一个新的API自定义指标API,它允许HPA访问任意指标。 Kubernetes 1.7引入了聚合层,允许第三方应用程序通过注册为API附加组件来扩展Kubernetes API。自定义指标API以及聚合层使得像Prometheus这样的监控系统可以向HPA控制器公开特定于应用程序的指标。 一、准备工作因为pod的metrics信息来源与heapster,所以在开始之前要保证heapster运行正常。heapster的配置可参考前文。我们可以通过运行kubectl top node来验证heapster是否运行正常。
二、针对CPU的HPA演示1、直接通过kubectl工具来创建hpa
三、针对内存的HPA演示1、通过yaml文件创建hpa
2、修改deployment的yaml文件,添加资源的requests和limit限制
3、观察hpa过程
下文将会介绍基于metric-server的hpa,尽请关注! (责任编辑:IT) |