各版本 MySQL 并行复制的实现及优缺点
时间:2019-05-13 12:02 来源:linux.it.net.cn 作者:IT
MySQL并行复制已经是老生常谈,笔者从2010年开始就着手处理线上这个问题,刚开始两三年也乐此不疲分享,现在再提这个话题本来是难免“炒冷饭”嫌疑。
最近触发再谈这个话题,是因为有些同学觉得“5.7的并行复制终于彻底解决了复制并发性问题”, 感觉还是有必要分析一下。大家都说没有银弹,但是又期待银弹。。
既然要说5.7的并行复制,干脆顺手把各个版本的并行复制都说明一下,也好有个对比。便是本次分享的初衷。
【背景】
一句话说完,因为这几年太多这样文章了, 就是MySQL一直以来的备库复制都是单线程apply。
【解决基本思路】
改成多线程复制。
备库有两个线程与复制相关:io_thread 负责从主库拿binlog并写到relaylog, sql_thread 负责读relaylog并执行。
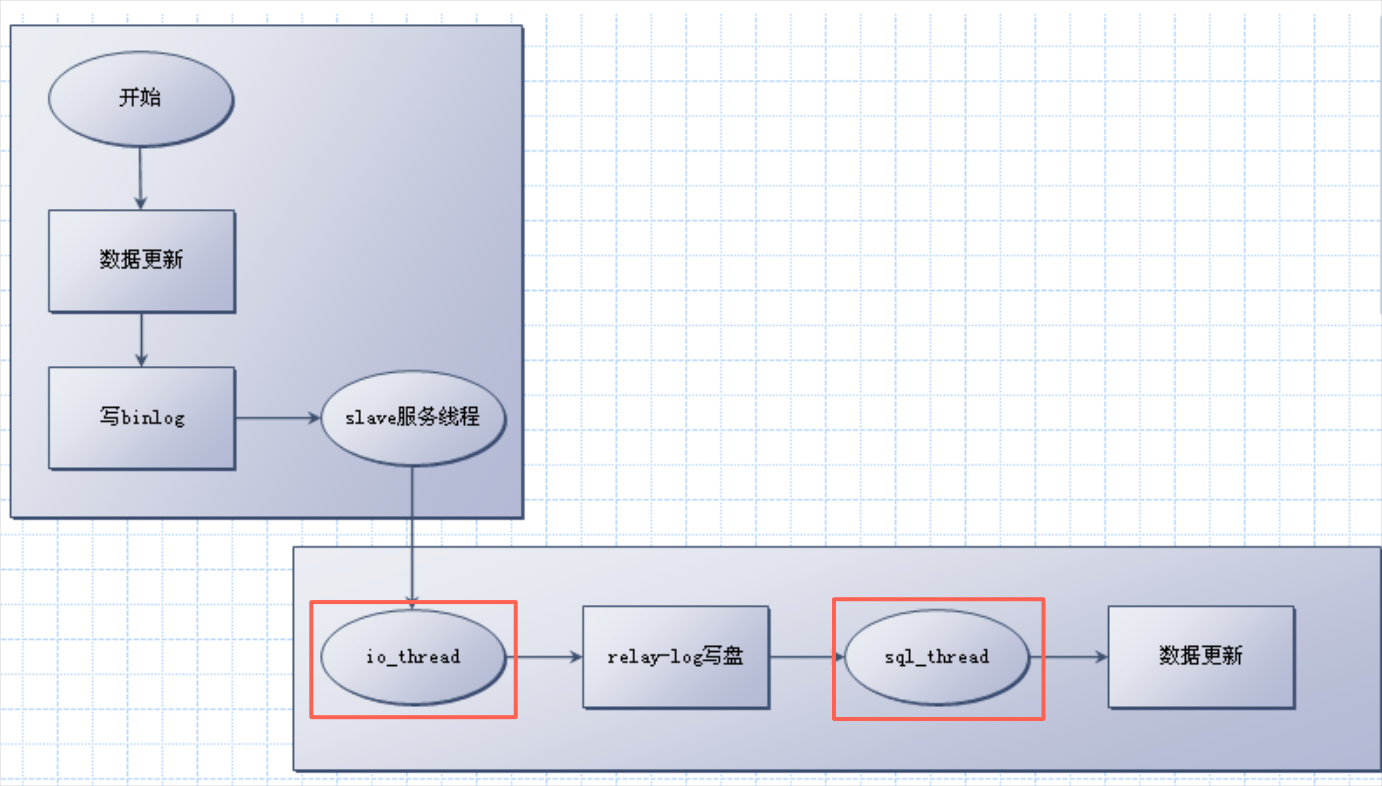
多线程的思路就是把sql_thread 变成分发线程,然后由一组worker_thread来负责执行。
几乎所有的并行复制都是这个思路,有不同的,便是sql_thread 的分发策略。
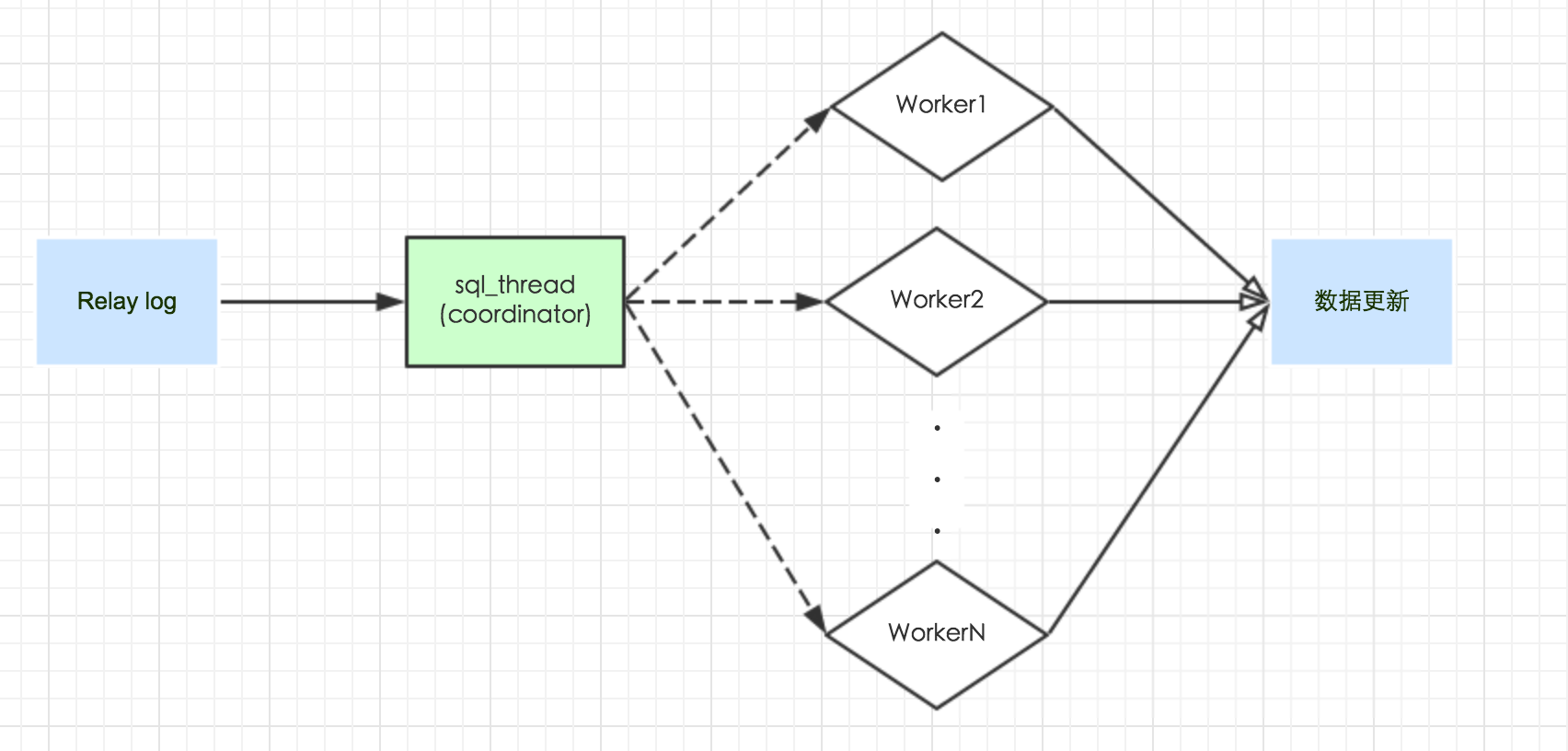
而这些策略里面又分成两类:利用传统binlog格式、修改binlog。
使用传统的binlog格式的几类,由于binlog里面的信息就那些,因此只能按照粒度来分,也就是:按库、按表、按行
另外有两个策略是修改了binlog格式的,在binlog里面增加了别的信息,用于体现提交分组。
下面我们分别介绍几个并行复制的实现。
【5.5】
MySQL官方5.5是不支持并行复制的。但是在阿里的业务需要并行复制的年份,还没有官方版本支持,只好自己实现。而且从兼容性角度说,不修改binlog格式,所以采用的是利用传统binlog格式的改造。
阿里的版本支持两种分发策略:按表和按行。
前情说明,由于MySQLbinlog日志还有用于别的系统的要求,因此阿里的binlog格式都是row----这也给并行复制的实现减少了难度。
按表分发策略:row格式的binlog,每个DML前面都是有Table_map event的。因此很容易拿到库名/表名。一个简单的思路是,不同表的更新之间是不需要严格按照顺序的。
因此按照表名hash,hash key是 库名+表名,相同的表的更新放到同一个worker上。这样就保证同一个表的更新顺序,跟主库上是一样的。
应用场景:对于多表更新的场景效果特别好。缺点是反之的,若是热点表更新,则本策略无效。而且由于hash表的维护,性能反而下降。
按行分发策略:row格式的binlog中,也不难拿到主键ID. 有同学说如果没有主键怎么办,答案是"起开,现在谁还没主键:)"。好吧,正经答案是没有主键就不支持这个策略。
同样的,我们认为不同行的更新,可以无序并发的。只要保证同一行的数据更新,在备库上的顺序与主库上的相同即可。
因此按照主键id hash,所以这个hash key更长,必须是 库名+表名+主键id。相同行的更新放到同一个worker上。
需要注意的是,上面的描述看上去都是对单个event的操作,实际上并不能!因为备库可能接受读,因此事务的原子性是要保证的,也就是说,对于涉及多个更新操作的事务,每次用于决策的不是一个hash key,而是一组。
应用场景:热点表更新。缺点,hash key计算冲突的代价大。尤其是大事务,计算hash key的cpu消耗大,而且耗内存。这需要业务DBA做判断得失。
【5.6】
官方的5.6支持的是按库分发。有了上面的背景,大家就知道,这个feature出来以后,在中国并没有什么反响。
但是这个策略也要说也是有优点的:
1、对于可以按表分发的场景,可以通过将表迁到不同的库,来应用此策略,有可操作性
2、速度更快,因为hash key就一个库名
3、不要求binlog格式,大家知道不论是row还是statement格式,都是能够轻松获取库名的。
所以并不是完全没有用的。还是习惯问题。
【MariaDB】
MariaDB的并行复制策略看上去有好几个选项,然而生产上可用的也就是默认值的 CONSERVATIVE。
由于maraiaDB支持多主复制,一个domain_id字段是用来标示事务来源的。如果来自于不同的主,自然可以并行(这个其实也是通用概念,还得业务DBA自己判断)。
对于同一个主库来的binlog,用commit_id 来决定分组。
想法是这样的:在主库上同时提交的事务设置成相同的commit_id。在备库上apply时,相同的commit_id可以并行执行,因为这意味着这些事务之间是没有行冲突的(否则不可能同时提交)。
这个思路跟最初从单线程改成多线程一样,个人认为是划时代的。
但是也并没有解决了所有的问题。这个策略最怕的是,拖后腿事务。
设想一下这个场景,假设某个DB里面正在作大量小更新事务(比如每个事务更新一行),这样在备库就并行得很欢乐。
然后突然,在同一个实例,另外一个库下,或者同一个库的另外一个跟目前的更新无关的表,突然有一个delte操作删除了10w行。
delete事务在提交的时候,跟当时一起提交的事务都算同一个commit_id。假设为N.
之后的小事务更新提交组commit_id为N+1。
到备库apply时,就会发现N这个组里面,其他小事务都执行完了,线程进入空闲状态,但是不能继续执行N+1这个commit_id的事务,因为N里面还有一个大事务没有执行完成,这个我们认为是拖后腿的。
而基于传统binlog格式的上面三个策略,反而没有这个问题。只要是策略上能够判断不冲突,大事务自己有个线程跑,其他事务继续并行。
【5.7】
MySQL官方5.7版本也是及时跟进,先引入了上述MariaDB的策略。当然从版权安全上,oracle是不会允许直接port代码的。
实际上按组直接分段这个策略略显粗暴。实际上事务提交并不是一个点,而是一个阶段。至少我们可以分成:准备提交、提交中、提交完成。
这三个阶段都是在事务已经完成了主要操作逻辑,进入commit状态了。
同时进入“提交中”状态的算同一个commit_id. 但是实际上,在任意时刻,处于”准备提交”的事务,与“提交中”的事务,也是可以并行的。但是明显他们会被分成两个不同的commit_id。
这意味着这个策略还有提升并发度的空间。
我们来看一下两种策略的对比差别。
假设主库有如下面示意图的事务序列。每个事务提交过程看成两个阶段,prepare ... commit. 分别给不同的编号。其中commit对应的数字是自然数递增,sequence_no。而prepare是对应的数字是X+1,这个X表示的是当前已经提交完成的sequence_no。
trx1 1…..2
trx2 1………….3
trx3 1…………………….4
trx4 2………………………….5
trx5 3………………………………..6
trx6 3………………………………………………7
trx7 6……………………..8
分析:
在MariaDB的策略里面,并发执行序列如下:
trx1, trx2, trx3 ----group 1
trx4 -----group 2
trx 5, trx6 ----group 3
trx 7 ----group 4
每个group 执行完成后,下一个group 才可以开始。
完全执行完成的时间是每个group的最大事务时间之和,即 trx3 + trx4+trx6+trx7。
因此,如果某个group里面有一个很大的事务,则整个序列的执行时间就会被拖久。
再来看5.7的改进策略:
虽然也是group1先启动,但是在trx1完成后, trx4就可以开始执行;
同样的,trx7可以在trx4执行完成后就开始执行,与trx5和trx6并发。
因此可以说上面这个例子中,备库apply过程完全达到了主库执行的并发度。
但是对于大事务,比如trx2 commit 非常久的情况,仍然存在拖后腿的问题。
【小结】
按粒度区分的三个策略,粒度从粗到细是按库、按表、按行。
这三个的对比中,并行度越来越大,额外损耗也是。无关大事务不会影响并发度。
按照commit_id 的两个策略,适用范围更广,额外消耗也低。
5.7的改进策略并发性更优。但出现大事务会拖后腿。
另外,很重要的一点,5.7的策略目的是“模拟主库并发”,所以对于主库单线程更新是无加速作用的。而基于冲突的前三个策略,若满足并发条件,会出现备库比主库执行速度快的情况。这种需求在搭备库或者延迟复制的场景中可能触发。
实际上策略的选择取决于应用场景,这是架构师的工作之一。
(责任编辑:IT)
MySQL并行复制已经是老生常谈,笔者从2010年开始就着手处理线上这个问题,刚开始两三年也乐此不疲分享,现在再提这个话题本来是难免“炒冷饭”嫌疑。 最近触发再谈这个话题,是因为有些同学觉得“5.7的并行复制终于彻底解决了复制并发性问题”, 感觉还是有必要分析一下。大家都说没有银弹,但是又期待银弹。。 既然要说5.7的并行复制,干脆顺手把各个版本的并行复制都说明一下,也好有个对比。便是本次分享的初衷。 【背景】 一句话说完,因为这几年太多这样文章了, 就是MySQL一直以来的备库复制都是单线程apply。 【解决基本思路】 改成多线程复制。 备库有两个线程与复制相关:io_thread 负责从主库拿binlog并写到relaylog, sql_thread 负责读relaylog并执行。
多线程的思路就是把sql_thread 变成分发线程,然后由一组worker_thread来负责执行。 几乎所有的并行复制都是这个思路,有不同的,便是sql_thread 的分发策略。
而这些策略里面又分成两类:利用传统binlog格式、修改binlog。 使用传统的binlog格式的几类,由于binlog里面的信息就那些,因此只能按照粒度来分,也就是:按库、按表、按行 另外有两个策略是修改了binlog格式的,在binlog里面增加了别的信息,用于体现提交分组。 下面我们分别介绍几个并行复制的实现。 【5.5】 MySQL官方5.5是不支持并行复制的。但是在阿里的业务需要并行复制的年份,还没有官方版本支持,只好自己实现。而且从兼容性角度说,不修改binlog格式,所以采用的是利用传统binlog格式的改造。 阿里的版本支持两种分发策略:按表和按行。 前情说明,由于MySQLbinlog日志还有用于别的系统的要求,因此阿里的binlog格式都是row----这也给并行复制的实现减少了难度。 按表分发策略:row格式的binlog,每个DML前面都是有Table_map event的。因此很容易拿到库名/表名。一个简单的思路是,不同表的更新之间是不需要严格按照顺序的。 因此按照表名hash,hash key是 库名+表名,相同的表的更新放到同一个worker上。这样就保证同一个表的更新顺序,跟主库上是一样的。 应用场景:对于多表更新的场景效果特别好。缺点是反之的,若是热点表更新,则本策略无效。而且由于hash表的维护,性能反而下降。 按行分发策略:row格式的binlog中,也不难拿到主键ID. 有同学说如果没有主键怎么办,答案是"起开,现在谁还没主键:)"。好吧,正经答案是没有主键就不支持这个策略。 同样的,我们认为不同行的更新,可以无序并发的。只要保证同一行的数据更新,在备库上的顺序与主库上的相同即可。 因此按照主键id hash,所以这个hash key更长,必须是 库名+表名+主键id。相同行的更新放到同一个worker上。
需要注意的是,上面的描述看上去都是对单个event的操作,实际上并不能!因为备库可能接受读,因此事务的原子性是要保证的,也就是说,对于涉及多个更新操作的事务,每次用于决策的不是一个hash key,而是一组。 应用场景:热点表更新。缺点,hash key计算冲突的代价大。尤其是大事务,计算hash key的cpu消耗大,而且耗内存。这需要业务DBA做判断得失。 【5.6】 官方的5.6支持的是按库分发。有了上面的背景,大家就知道,这个feature出来以后,在中国并没有什么反响。 但是这个策略也要说也是有优点的: 1、对于可以按表分发的场景,可以通过将表迁到不同的库,来应用此策略,有可操作性 2、速度更快,因为hash key就一个库名 3、不要求binlog格式,大家知道不论是row还是statement格式,都是能够轻松获取库名的。 所以并不是完全没有用的。还是习惯问题。 【MariaDB】 MariaDB的并行复制策略看上去有好几个选项,然而生产上可用的也就是默认值的 CONSERVATIVE。 由于maraiaDB支持多主复制,一个domain_id字段是用来标示事务来源的。如果来自于不同的主,自然可以并行(这个其实也是通用概念,还得业务DBA自己判断)。 对于同一个主库来的binlog,用commit_id 来决定分组。 想法是这样的:在主库上同时提交的事务设置成相同的commit_id。在备库上apply时,相同的commit_id可以并行执行,因为这意味着这些事务之间是没有行冲突的(否则不可能同时提交)。 这个思路跟最初从单线程改成多线程一样,个人认为是划时代的。 但是也并没有解决了所有的问题。这个策略最怕的是,拖后腿事务。 设想一下这个场景,假设某个DB里面正在作大量小更新事务(比如每个事务更新一行),这样在备库就并行得很欢乐。 然后突然,在同一个实例,另外一个库下,或者同一个库的另外一个跟目前的更新无关的表,突然有一个delte操作删除了10w行。 delete事务在提交的时候,跟当时一起提交的事务都算同一个commit_id。假设为N. 之后的小事务更新提交组commit_id为N+1。 到备库apply时,就会发现N这个组里面,其他小事务都执行完了,线程进入空闲状态,但是不能继续执行N+1这个commit_id的事务,因为N里面还有一个大事务没有执行完成,这个我们认为是拖后腿的。 而基于传统binlog格式的上面三个策略,反而没有这个问题。只要是策略上能够判断不冲突,大事务自己有个线程跑,其他事务继续并行。 【5.7】 MySQL官方5.7版本也是及时跟进,先引入了上述MariaDB的策略。当然从版权安全上,oracle是不会允许直接port代码的。 实际上按组直接分段这个策略略显粗暴。实际上事务提交并不是一个点,而是一个阶段。至少我们可以分成:准备提交、提交中、提交完成。 这三个阶段都是在事务已经完成了主要操作逻辑,进入commit状态了。 同时进入“提交中”状态的算同一个commit_id. 但是实际上,在任意时刻,处于”准备提交”的事务,与“提交中”的事务,也是可以并行的。但是明显他们会被分成两个不同的commit_id。 这意味着这个策略还有提升并发度的空间。 我们来看一下两种策略的对比差别。 假设主库有如下面示意图的事务序列。每个事务提交过程看成两个阶段,prepare ... commit. 分别给不同的编号。其中commit对应的数字是自然数递增,sequence_no。而prepare是对应的数字是X+1,这个X表示的是当前已经提交完成的sequence_no。 trx1 1…..2 trx2 1………….3 trx3 1…………………….4 trx4 2………………………….5 trx5 3………………………………..6 trx6 3………………………………………………7 trx7 6……………………..8
分析: 在MariaDB的策略里面,并发执行序列如下: trx1, trx2, trx3 ----group 1 trx4 -----group 2 trx 5, trx6 ----group 3 trx 7 ----group 4 每个group 执行完成后,下一个group 才可以开始。 完全执行完成的时间是每个group的最大事务时间之和,即 trx3 + trx4+trx6+trx7。 因此,如果某个group里面有一个很大的事务,则整个序列的执行时间就会被拖久。
再来看5.7的改进策略: 虽然也是group1先启动,但是在trx1完成后, trx4就可以开始执行; 同样的,trx7可以在trx4执行完成后就开始执行,与trx5和trx6并发。 因此可以说上面这个例子中,备库apply过程完全达到了主库执行的并发度。 但是对于大事务,比如trx2 commit 非常久的情况,仍然存在拖后腿的问题。 【小结】 按粒度区分的三个策略,粒度从粗到细是按库、按表、按行。 这三个的对比中,并行度越来越大,额外损耗也是。无关大事务不会影响并发度。 按照commit_id 的两个策略,适用范围更广,额外消耗也低。 5.7的改进策略并发性更优。但出现大事务会拖后腿。 另外,很重要的一点,5.7的策略目的是“模拟主库并发”,所以对于主库单线程更新是无加速作用的。而基于冲突的前三个策略,若满足并发条件,会出现备库比主库执行速度快的情况。这种需求在搭备库或者延迟复制的场景中可能触发。 实际上策略的选择取决于应用场景,这是架构师的工作之一。 (责任编辑:IT) |