MySQL排序工作原理
时间:2019-05-31 17:56 来源:linux.it.net.cn 作者:IT
在程序设计当中,我们很多场景下都会用 group by 关键字。比如在分页读取数据时,为了避免重复扫描记录,这就是必须要使用 group by 了。
比如我们使用如下 DDL 创建表:
-
CREATE TABLE `user_info` (
-
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
-
`city` varchar(16) NOT NULL COMMENT '城市',
-
`name` varchar(16) NOT NULL COMMENT '姓名',
-
`age` int(11) NOT NULL COMMENT '年龄',
-
`addr` varchar(128) DEFAULT NULL COMMENT '地址',
-
PRIMARY KEY (`id`),
-
KEY `city` (`city`)
-
) ENGINE=InnoDB DEFAULT CHARSET=utf8
并且我们会执行如下查询语句
-
SELECT city,`name`,age FROM user_info WHERE city='上海' ORDER BY `name` LIMIT 1000;
全字段排序
因为上面的建表语句已经在 city 字段上面创建索引了,当我们使用 EXPLAIN 命令时,会有如下结果:

上面 Extra 字段中的 “Using filesort” 表示的就是需要排序,MySQL 会为每个线程分配一块内存用于排序,成为 sort_buffer。下面我们看一下 index(city) 的结构示意图。
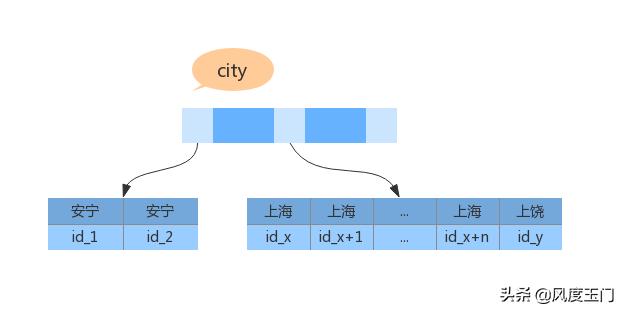
执行流程如下:
-
初始化 sort_buffer,确定放入 city name age 这 3 个字段;
-
从 city 索引中获取到第一个 city='上海' 的记录,也就是 id_x;
-
到主键索引中获取对应的记录,并取出 name city age 的值放入 sort_buffer;
-
取下一条符合条件的记录,重复 3 4 的操作,直至不符合条件为止;
-
对 sort_buffer 中的数据按照 name 做快速排序;
-
取出前 1000 条数据并返回。
我们暂时叫这种排序过程为“全字段排序”,如下所示:
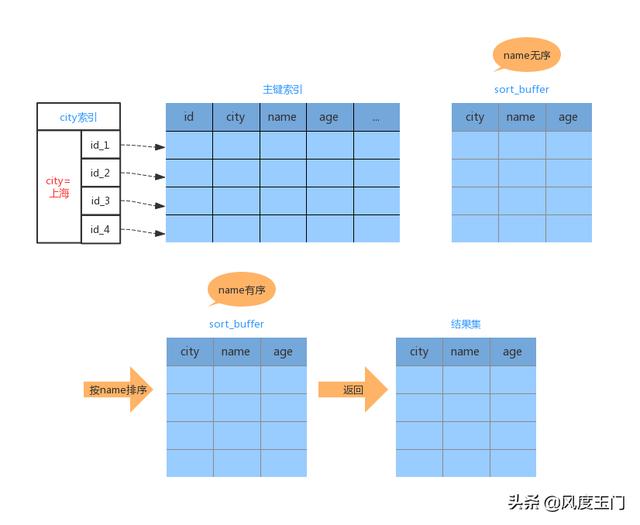
图中的“按 name 排序” 可能在内存中,也可能使用磁盘文件排序,这取决与排序所需要的内存和 sort_buffer_size 。sort_buffer_size 就是 MySQL 为排序开辟的内存大小,当所需内存小于 sort_buffer_size 时,就直接在内存中完成排序,如果所需要的内存 大于 sort_buffer_size ,就需要额外的磁盘空间辅助排序。
rowid 排序
上面的算法在数据量比较大的时候,可能会出现一些问题。因为在排序的时候,存放了所有的返回字段,增加了 排序空间 (sort_buffer)的压力。
-
SET max_length_for_sort_data=16;
max_length_for_sort_data 是MySQL 限制排序行大小的参数。意思是,如果排序行大小超过了这个值,就会另选排序算法。上面 name city age 3 个字段的大小为 36,大于 16 ,在新的算法中将只有 name (排序字段) 和id 参与 sort_buffer 中的排序。过程如下
-
初始化 sort_buffer,确定放入 name id 这 2 个字段;
-
从 city 索引中获取到第一个 city='上海' 的记录,也就是 id_x;
-
到主键索引中获取对应的记录,并取出 name id 的值放入 sort_buffer;
-
取下一条符合条件的记录,重复 3 4 的操作,直至不符合条件为止;
-
对 sort_buffer 中的数据按照 name 做快速排序;
-
取出前 1000 条数据,然后根据 id 取出对应记录的 name city age 3 个字段并返回结果。
这种排序过程,我们称为 rowid 排序,过程如下所示:
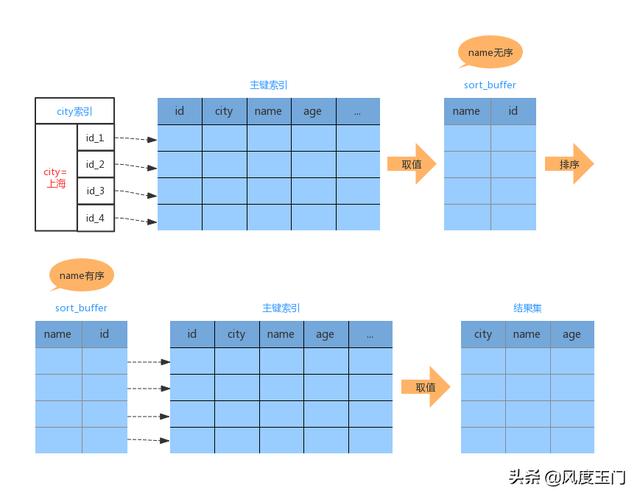
全字段排序 VS rowid 排序
从上面 2 个流程看来,如果内存足够时,MySQL 会让返回值中所有字段存放在排序空间。当MySQL 内存过小时,才会考虑使用rowid 排序。但是从上面的流程看来,rowid 排序在返回结果前,还会再一次的回表。因此MySQL 认为内存充足的时候,会优先采用 全字段排序。
上面的场景是:city 字段过滤后,name 字段不是有序的。其实我们可以通过联合索引来规避掉 name 字段的排序。
-
alter table user_info add index idx_city_user(city, name);
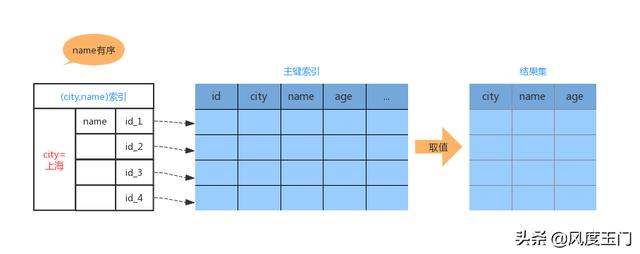
下面我们看一下联合索引的示意图:
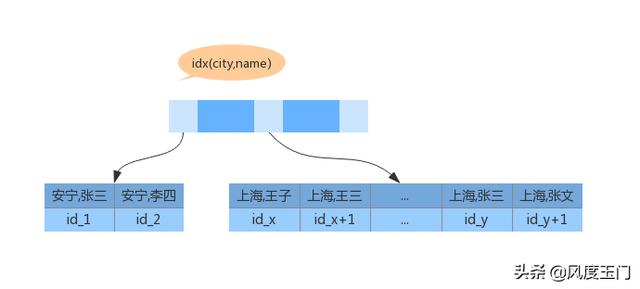
从上面流程图可以看出,当我们取出 city='上海' 的记录时,name的字段也是有序的。过程如下
-
从 (city, name)索引中获取到第一个 city='上海' 的记录 id_x;
-
到主键索引中获取对应的记录,并取出 name city age 的值作为结果集的一部分直接返回;
-
取下一条符合条件的记录,重复 2 3 的操作,直至不符合条件或者达到 1000 条为止;
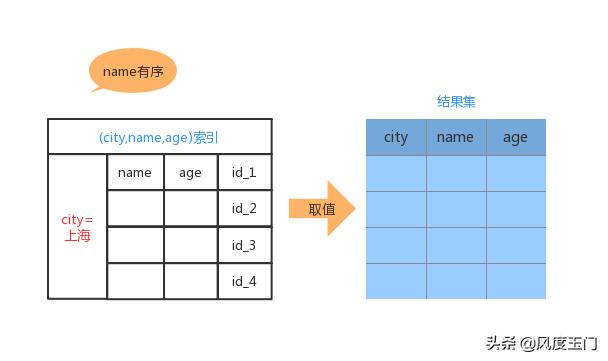
从联合索引看来,我们是可以不用排序操作了,那么我们是否可以直接通过 索引就直接返回结果呢?也就是不要回表操作。答案是有的,那就是覆盖索引。
-
alter table user_info add index idx_city_user_age(city, name, age);
当执行查询语句时,不仅 name 中的字段是有序的,并且 索引中已经包含了结果集中的所有字段,过程如下:
-
从 (city, name,age)索引中获取到第一个 city='上海' 的记录,并取出 name city age 的值作为结果集的一部分直接返回;
-
取下一条符合条件的记录,重复 1 2 的操作,直至不符合条件或者达到 1000 条为止;
(责任编辑:IT)
在程序设计当中,我们很多场景下都会用 group by 关键字。比如在分页读取数据时,为了避免重复扫描记录,这就是必须要使用 group by 了。 比如我们使用如下 DDL 创建表:
并且我们会执行如下查询语句
全字段排序因为上面的建表语句已经在 city 字段上面创建索引了,当我们使用 EXPLAIN 命令时,会有如下结果: 上面 Extra 字段中的 “Using filesort” 表示的就是需要排序,MySQL 会为每个线程分配一块内存用于排序,成为 sort_buffer。下面我们看一下 index(city) 的结构示意图。
执行流程如下:
我们暂时叫这种排序过程为“全字段排序”,如下所示:
图中的“按 name 排序” 可能在内存中,也可能使用磁盘文件排序,这取决与排序所需要的内存和 sort_buffer_size 。sort_buffer_size 就是 MySQL 为排序开辟的内存大小,当所需内存小于 sort_buffer_size 时,就直接在内存中完成排序,如果所需要的内存 大于 sort_buffer_size ,就需要额外的磁盘空间辅助排序。 rowid 排序上面的算法在数据量比较大的时候,可能会出现一些问题。因为在排序的时候,存放了所有的返回字段,增加了 排序空间 (sort_buffer)的压力。
max_length_for_sort_data 是MySQL 限制排序行大小的参数。意思是,如果排序行大小超过了这个值,就会另选排序算法。上面 name city age 3 个字段的大小为 36,大于 16 ,在新的算法中将只有 name (排序字段) 和id 参与 sort_buffer 中的排序。过程如下
这种排序过程,我们称为 rowid 排序,过程如下所示:
全字段排序 VS rowid 排序从上面 2 个流程看来,如果内存足够时,MySQL 会让返回值中所有字段存放在排序空间。当MySQL 内存过小时,才会考虑使用rowid 排序。但是从上面的流程看来,rowid 排序在返回结果前,还会再一次的回表。因此MySQL 认为内存充足的时候,会优先采用 全字段排序。 上面的场景是:city 字段过滤后,name 字段不是有序的。其实我们可以通过联合索引来规避掉 name 字段的排序。
下面我们看一下联合索引的示意图:
从上面流程图可以看出,当我们取出 city='上海' 的记录时,name的字段也是有序的。过程如下
从联合索引看来,我们是可以不用排序操作了,那么我们是否可以直接通过 索引就直接返回结果呢?也就是不要回表操作。答案是有的,那就是覆盖索引。
当执行查询语句时,不仅 name 中的字段是有序的,并且 索引中已经包含了结果集中的所有字段,过程如下:
(责任编辑:IT) |