�ֽ�������Դ�����ֲܷ�ʽѵ����� BytePS������ TensorFlow ��
ʱ��:2019-06-28 15:17 ��Դ:linux.it.net.cn ����:IT
���գ��ֽ������˹�����ʵ����������Դһ������ֲܷ�ʽ���ѧϰѵ����� BytePS���������ϵ߸��˹�ȥ���� allreduce ����һֱռ���Ϸ�ľ��棬����Ŀǰ�������зֲ�ʽѵ�����һ�����ϵ����ܣ���ͬʱ�ܹ�֧�� Tensorflow��PyTorch��MXNet �ȿ�Դ�⡣
���ȷ��� BytePS ��Դ��Ŀ��ַ��https://github.com/bytedance/byteps
BytePS ������ֽ������˹�����ʵ���Ҽ��������Էֲ�ʽѵ��ͨ�ŵĶ���о����Ż��ɹ�������ͨ�����ȼ����ȡ�PS �� RDMA ʵ�֡���� PCIe switch �� NUMA ���Ż����Լ� BytePS �������ܵĴ��µȡ�
���ѧϰ��Ч��ȡ����ģ�������ݣ�Ŀǰ��ҵ�ڲ���ˢ�����ѧϰȷ�ʵ������о��������ڸ����ģ���Լ���������ݼ���Ȼ������ģ��������ݶ�ѵ��ʱ�ļ�����������˼���Ҫ���� GPU �������ߵ�̨�������ϵ� GPU �����Ѿ�ԶԶ���ܹ������ڲ�ѵ�������������ˣ��ֲ�ʽѵ����Ч�ʣ���ʹ�ö�̨������Эͬ����ѵ�������ڳ�Ϊ�����ѧϰϵͳ�ĺ��ľ�������
һֱ�������ڷֲ�ʽѵ�������������ɣ��ֱ��� allreduce �� PS��Parameter Server������ȥ�����У������ǰٶ���� allreduce���Լ� Uber ��Դ���� allreduce �� Horovod ֮����ҵ�ڵ���֪�У�allreduce ����õķֲ�ʽѵ��ͨ�ŷ�ʽ������ȥ�� PS ʵ�ֵ�����Ҳȷʵ�� allreduce ����һ����ࡣ
BytePS �߸��� allreduce �������ȵľ��棬BytePS ӵ���ų���Ŀǰ�������зֲ�ʽѵ�����һ�����ϵ����ܣ����� NVIDIA ��Դ�� NCCL��Uber ��Դ�� Horovod���Լ� Tensorflow��PyTorch��MXNet �Դ��ķֲ�ʽѵ�������ȡ�
BytePS �����Ŷӱ�ʾ���ڹ����ƻ���˽�����������Ⱥ�У�����������ƺ�����ʵ�ֵ� PS��PS �ܹ��������� allreduce �������һЩ�������ܵõ��� allreduce ����һ�����ٶȡ�
Ϊ����������Ƽ��������Ⱥ����������ѵ�����֣�BytePS �Ŷ�����˼�������ͨ�Ų��ԣ������ڻ�����ʹ�� NCCL��ͬʱҲ���²����˻������ͨ�ŷ�ʽ��
�ݽ��ܣ��ڷ������ڣ�GPU �Dz��ڲ�ͬ�� PCIe switch �ϵģ���ͬ PCIe switch �ڵ� GPU ͨ�Ŵ����ϸߣ��� PCIe switch ��ͨ�Ŵ����ͽ�С��NUMA ��ָ���������в�ֹһ�� CPU��CPU �ڴ�Ҳ���������⣺ͬ CPU ���ڴ���ʴ����ߣ��� CPU ���ڴ���ʴ����͡�BytePS �������Щ��Ϣ����ѡ��ط��������� CPU �� GPU �е��ڴ�λ�ã��Լ��Ŀ��ڴ���Ŀ��ڴ�ͨ�ţ��Ӷ����ͨ�Ŵ�����
BytePS ���ܱ���Ҳ����һЩ��Ҫ��ƣ�ʹ�� PS �ܹ������ϵ�DZ�ܵ���ʵ�֣�������Tensor �Զ��з֡��༶�����ˮ�ߴ���������ͨ�����ȼ����ȡ�ZeroMQ �Ż��������ڴ� zero-copy��RDMA ʵ�ֺ� PS �˶���ж��߳��Ż���
����ϸ��ʵ��ԭ���μ����
���ܱ���
�����У�BytePS �Ŷ�ʹ���˹������ϵ��������ÿ��������� 8 �� Tesla V100 16GB GPU��GPU ֮��ͨ�� NVLink ���и��ٻ�����ÿ�� GPU �ϵ� batch size ѡȡΪ 64�������֮��ͨ�� 20Gbps �� TCP/IP ����������ӡ�����������£����ڻ���֮�ڴ����㹻��TCP/IP ������������Ϊ����Ҫƿ����
BytePS ѡ���� Resnet50 �� VGG16 ����ģ�ͽ������⣬���� Resnet50 �Ǽ����ܼ��͵�ģ�ͣ���ͨ��Ҫ��ͣ��Ż��ռ�С����VGG16 ��ͨ���ܼ��͵�ģ�ͣ���ͨ��Ҫ��ߣ��Ż��ռ��������ѡ����Ŀǰ�����������е�ͨ�ſ��֮һ Horovod-NCCL������ allreduce �㷨ʵ�֣�������ָ��Ϊÿ����ѵ���� ImageNet ͼƬ������Խ�ߴ���Խ�á�
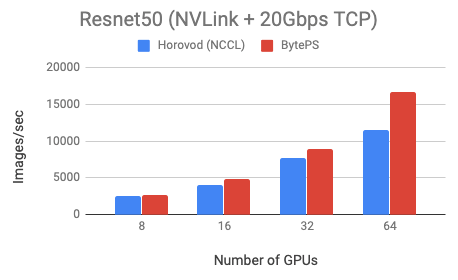
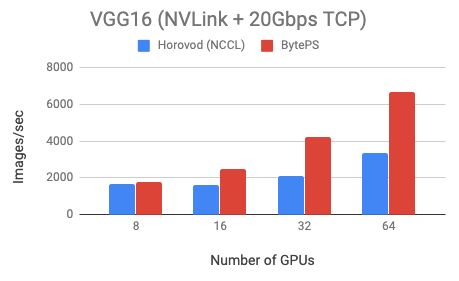
ͨ������ʵ�������Կ��������ڼ����ܼ��͵� Resnet50 ģ�ͣ�BytePS ���ܳ��� Horovod-NCCL �� 44%��������ͨ���ܼ��͵� VGG16 ģ�ͣ�BytePS ���ܿ��Գ��� Horovod-NCCL ���� 100%��
BytePS �Ŷ�Ҳ������ 100Gbps �� RDMA �����˽�м�Ⱥ���˲��ԣ�BytePS Ҳ��һ����������������������μ�Github��
�����������ϳ���Ŀǰ�������зֲ�ʽѵ������⣬BytePS ���Լ��� Tensorflow��PyTorch��MXNet ��ѵ����ܡ�BytePS �Ŷӱ�ʾ��������ֻ��Ҫ�dz��ٵĸĶ����Ϳ���ʹ�� BytePS ��ܽ��зֲ�ʽѵ�������� BytePS �����ĸ����ܡ�
��ǰ��ҵ��� PS ʵ�֣���������ض�ͨ�ÿ�ܣ�����ר��Ϊ TensorFlow ʵ�ֵ� PS��Ҳ��ר��Ϊ MXNet ʵ�ֵ� PS��
�ֽ������˹�����ʵ���ҿ�Դ�� BytePS��ͨ��ʵ��һ��ͨ�õij���㣬�������Ա�����ͨ�ÿ�����ã�ʵ����ͬʱ֧�ֶ����ܵĿ����ԣ�����ܹ�֧�� Tensorflow��PyTorch��MXNet ����ҵ����ѵ����ܡ�
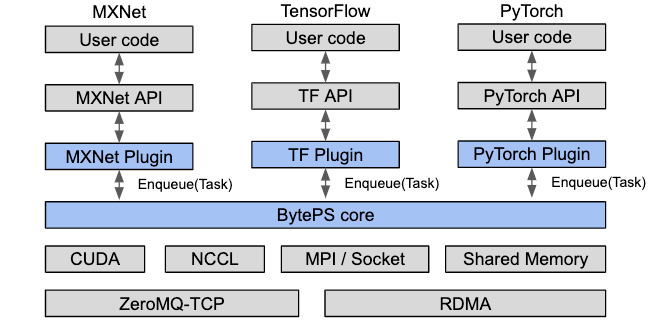
BytePS �ṩ�� TensorFlow��PyTorch�� MXNet �Լ� Keras �IJ�����û�ֻҪ�ڴ��������� BytePS �IJ�����Ϳ��Ի�ø����ܵķֲ�ʽѵ����BytePS �ĺ���������ʵ���� BytePS core ������ͨ��ϸ�ڣ���ȫ�� BytePS ��ɣ��û���ȫ����Ҫ���ġ�
�������� BytePS
ʹ�� BytePS ǰ���������Ѿ���װ������һ�ֻ�����ܣ�TensorFlow��Keras��PyTorch��MXNet �ȡ�BytePS ��Ҫ���� CUDA �� NCCL��
���� BytePS �͵�����������
�p���ƴ���
git clone --recurse-submodules https://github.com/bytedance/byteps
���� BytePS �ļ�Ŀ¼������װ��
�p���ƴ���
python setup.py install
ע�⣺�������Ҫ���� BYTEPS_USE_RDMA=1 ����װ RDMA ֧�֡�
��������������������е�ʾ����������ʹ�� MXNet�����볢�� Resnet50 ѵ������
�p���ƴ���
export NVIDIA_VISIBLE_DEVICES=0,1 \
DMLC_NUM_WORKER=1 \
DMLC_NUM_SERVER=1 \
DMLC_WORKER_ID=0 \
DMLC_ROLE=worker \
DMLC_PS_ROOT_URI=10.0.0.1 \
DMLC_PS_ROOT_PORT=1234 \
DMLC_INTERFACE=eth0
python byteps/launcher/launch.py byteps/example/mxnet/train_imagenet_byteps.py --benchmark 1 --batch-size=32
���ڷֲ�ʽѵ�����������Ҫ����һ�������������з��Ŷ��ṩ�� Docker �ļ���Ϊ���ӡ�����Խ�ͬ���ľ������ڵ��Ⱥͷ�������
������������ֲ�ʽ��������ݺ������ֽ̳̿ɲο�����ĵ���
��������д�����ʹ�� BytePS
��Ȼ�ں����������ͬ���� BytePS �� Horovod �ӿڸ߶ȼ��ݣ�����ϣ��ͨ�� Horovod �ӿڼ����û����� BytePS �Ĺ�������
����������ֻ������ Horovod �� allreduce �㲥���������һ�������л��� BytePS��ֻ��Ҫ�� import byteps.tensorflow as bps �滻 import horovod.tensorflow as hvd���������������е� hvd �滻�� bps ���ɡ�
BytePS �ľ���δ���ƻ�
BytePS Ŀǰ��֧�ֵ����� CPU ѵ��������һ��ԭ���� BytePS �IJ��ֵײ���������֧�֡��������Ҫʹ�� CUDA �� NCCL ������������ BytePS��
δ�� BytePS �ƻ������������ԣ�
-
ϡ��ģ��ѵ��
-
�첽ѵ��
-
�ݴ�����
-
�ӳټ���
BytePS �Ŷӱ�ʾ�����ѧϰ������Ȼ�зdz���Ŀռ�Ϳ�����ֵ����ҵͬ����һ��̽������Դ BytePS����ϣ������ BytePS �����ܺ����ϵ��Ƚ��ԣ����Ϳ����ߺ����ѧϰ����������ǵ��ż�����������ͬ������һ��̽�����ѧϰ������ AI Ӧ��Ч�ʡ�
(���α༭��IT)
���ȷ��� BytePS ��Դ��Ŀ��ַ��https://github.com/bytedance/byteps BytePS ������ֽ������˹�����ʵ���Ҽ��������Էֲ�ʽѵ��ͨ�ŵĶ���о����Ż��ɹ�������ͨ�����ȼ����ȡ�PS �� RDMA ʵ�֡���� PCIe switch �� NUMA ���Ż����Լ� BytePS �������ܵĴ��µȡ� ���ѧϰ��Ч��ȡ����ģ�������ݣ�Ŀǰ��ҵ�ڲ���ˢ�����ѧϰȷ�ʵ������о��������ڸ����ģ���Լ���������ݼ���Ȼ������ģ��������ݶ�ѵ��ʱ�ļ�����������˼���Ҫ���� GPU �������ߵ�̨�������ϵ� GPU �����Ѿ�ԶԶ���ܹ������ڲ�ѵ�������������ˣ��ֲ�ʽѵ����Ч�ʣ���ʹ�ö�̨������Эͬ����ѵ�������ڳ�Ϊ�����ѧϰϵͳ�ĺ��ľ������� һֱ�������ڷֲ�ʽѵ�������������ɣ��ֱ��� allreduce �� PS��Parameter Server������ȥ�����У������ǰٶ���� allreduce���Լ� Uber ��Դ���� allreduce �� Horovod ֮����ҵ�ڵ���֪�У�allreduce ����õķֲ�ʽѵ��ͨ�ŷ�ʽ������ȥ�� PS ʵ�ֵ�����Ҳȷʵ�� allreduce ����һ����ࡣ BytePS �߸��� allreduce �������ȵľ��棬BytePS ӵ���ų���Ŀǰ�������зֲ�ʽѵ�����һ�����ϵ����ܣ����� NVIDIA ��Դ�� NCCL��Uber ��Դ�� Horovod���Լ� Tensorflow��PyTorch��MXNet �Դ��ķֲ�ʽѵ�������ȡ� BytePS �����Ŷӱ�ʾ���ڹ����ƻ���˽�����������Ⱥ�У�����������ƺ�����ʵ�ֵ� PS��PS �ܹ��������� allreduce �������һЩ�������ܵõ��� allreduce ����һ�����ٶȡ� Ϊ����������Ƽ��������Ⱥ����������ѵ�����֣�BytePS �Ŷ�����˼�������ͨ�Ų��ԣ������ڻ�����ʹ�� NCCL��ͬʱҲ���²����˻������ͨ�ŷ�ʽ�� �ݽ��ܣ��ڷ������ڣ�GPU �Dz��ڲ�ͬ�� PCIe switch �ϵģ���ͬ PCIe switch �ڵ� GPU ͨ�Ŵ����ϸߣ��� PCIe switch ��ͨ�Ŵ����ͽ�С��NUMA ��ָ���������в�ֹһ�� CPU��CPU �ڴ�Ҳ���������⣺ͬ CPU ���ڴ���ʴ����ߣ��� CPU ���ڴ���ʴ����͡�BytePS �������Щ��Ϣ����ѡ��ط��������� CPU �� GPU �е��ڴ�λ�ã��Լ��Ŀ��ڴ���Ŀ��ڴ�ͨ�ţ��Ӷ����ͨ�Ŵ����� BytePS ���ܱ���Ҳ����һЩ��Ҫ��ƣ�ʹ�� PS �ܹ������ϵ�DZ�ܵ���ʵ�֣�������Tensor �Զ��з֡��༶�����ˮ�ߴ���������ͨ�����ȼ����ȡ�ZeroMQ �Ż��������ڴ� zero-copy��RDMA ʵ�ֺ� PS �˶���ж��߳��Ż��� ����ϸ��ʵ��ԭ���μ���� ���ܱ��������У�BytePS �Ŷ�ʹ���˹������ϵ��������ÿ��������� 8 �� Tesla V100 16GB GPU��GPU ֮��ͨ�� NVLink ���и��ٻ�����ÿ�� GPU �ϵ� batch size ѡȡΪ 64�������֮��ͨ�� 20Gbps �� TCP/IP ����������ӡ�����������£����ڻ���֮�ڴ����㹻��TCP/IP ������������Ϊ����Ҫƿ���� BytePS ѡ���� Resnet50 �� VGG16 ����ģ�ͽ������⣬���� Resnet50 �Ǽ����ܼ��͵�ģ�ͣ���ͨ��Ҫ��ͣ��Ż��ռ�С����VGG16 ��ͨ���ܼ��͵�ģ�ͣ���ͨ��Ҫ��ߣ��Ż��ռ��������ѡ����Ŀǰ�����������е�ͨ�ſ��֮һ Horovod-NCCL������ allreduce �㷨ʵ�֣�������ָ��Ϊÿ����ѵ���� ImageNet ͼƬ������Խ�ߴ���Խ�á�
ͨ������ʵ�������Կ��������ڼ����ܼ��͵� Resnet50 ģ�ͣ�BytePS ���ܳ��� Horovod-NCCL �� 44%��������ͨ���ܼ��͵� VGG16 ģ�ͣ�BytePS ���ܿ��Գ��� Horovod-NCCL ���� 100%�� BytePS �Ŷ�Ҳ������ 100Gbps �� RDMA �����˽�м�Ⱥ���˲��ԣ�BytePS Ҳ��һ����������������������μ�Github�� �����������ϳ���Ŀǰ�������зֲ�ʽѵ������⣬BytePS ���Լ��� Tensorflow��PyTorch��MXNet ��ѵ����ܡ�BytePS �Ŷӱ�ʾ��������ֻ��Ҫ�dz��ٵĸĶ����Ϳ���ʹ�� BytePS ��ܽ��зֲ�ʽѵ�������� BytePS �����ĸ����ܡ� ��ǰ��ҵ��� PS ʵ�֣���������ض�ͨ�ÿ�ܣ�����ר��Ϊ TensorFlow ʵ�ֵ� PS��Ҳ��ר��Ϊ MXNet ʵ�ֵ� PS�� �ֽ������˹�����ʵ���ҿ�Դ�� BytePS��ͨ��ʵ��һ��ͨ�õij���㣬�������Ա�����ͨ�ÿ�����ã�ʵ����ͬʱ֧�ֶ����ܵĿ����ԣ�����ܹ�֧�� Tensorflow��PyTorch��MXNet ����ҵ����ѵ����ܡ�
BytePS �ṩ�� TensorFlow��PyTorch�� MXNet �Լ� Keras �IJ�����û�ֻҪ�ڴ��������� BytePS �IJ�����Ϳ��Ի�ø����ܵķֲ�ʽѵ����BytePS �ĺ���������ʵ���� BytePS core ������ͨ��ϸ�ڣ���ȫ�� BytePS ��ɣ��û���ȫ����Ҫ���ġ� �������� BytePSʹ�� BytePS ǰ���������Ѿ���װ������һ�ֻ�����ܣ�TensorFlow��Keras��PyTorch��MXNet �ȡ�BytePS ��Ҫ���� CUDA �� NCCL�� ���� BytePS �͵�����������
�p���ƴ���
���� BytePS �ļ�Ŀ¼������װ��
�p���ƴ���
��������������������е�ʾ����������ʹ�� MXNet�����볢�� Resnet50 ѵ������
�p���ƴ���
���ڷֲ�ʽѵ�����������Ҫ����һ�������������з��Ŷ��ṩ�� Docker �ļ���Ϊ���ӡ�����Խ�ͬ���ľ������ڵ��Ⱥͷ������� ������������ֲ�ʽ��������ݺ������ֽ̳̿ɲο�����ĵ��� ��������д�����ʹ�� BytePS��Ȼ�ں����������ͬ���� BytePS �� Horovod �ӿڸ߶ȼ��ݣ�����ϣ��ͨ�� Horovod �ӿڼ����û����� BytePS �Ĺ������� ����������ֻ������ Horovod �� allreduce �㲥���������һ�������л��� BytePS��ֻ��Ҫ�� import byteps.tensorflow as bps �滻 import horovod.tensorflow as hvd���������������е� hvd �滻�� bps ���ɡ� BytePS �ľ���δ���ƻ�BytePS Ŀǰ��֧�ֵ����� CPU ѵ��������һ��ԭ���� BytePS �IJ��ֵײ���������֧�֡��������Ҫʹ�� CUDA �� NCCL ������������ BytePS�� δ�� BytePS �ƻ������������ԣ�
BytePS �Ŷӱ�ʾ�����ѧϰ������Ȼ�зdz���Ŀռ�Ϳ�����ֵ����ҵͬ����һ��̽������Դ BytePS����ϣ������ BytePS �����ܺ����ϵ��Ƚ��ԣ����Ϳ����ߺ����ѧϰ����������ǵ��ż�����������ͬ������һ��̽�����ѧϰ������ AI Ӧ��Ч�ʡ� (���α༭��IT) |