MongoDB ·ЦЖ¬ОКМв»гЧЬ
Кұјд:2019-08-23 17:19 АҙФҙ:linux.it.net.cn ЧчХЯ:IT
·ЦЖ¬КЗMongoDBөДА©Х№·ҪКҪ,НЁ№э·ЦЖ¬ДЬ№»ФцјУёь¶аөД»ъЖчАҙУГ¶ФІ»¶ПФцјУөДёәФШәНКэҫЭ,»№І»У°ПмУҰУГ.
1.·ЦЖ¬јтҪй
·ЦЖ¬КЗЦёҪ«КэҫЭІр·Ц,Ҫ«Жд·ЦЙўҙжФЪІ»Н¬»ъЖчЙПөД№эіМ.УРКұТІҪР·ЦЗш.Ҫ«КэҫЭ·ЦЙўФЪІ»Н¬өД»ъЖчЙП,І»РиТӘ№ҰДЬ
ЗҝҙуөДҙуРНјЖЛг»ъҫНҝЙТФҙжҙўёь¶аөДКэҫЭ,ҙҰАнёьҙуөДёәФШ.
К№УГјёәхЛщУРКэҫЭҝвИнјю¶јДЬҪшРРКЦ¶Ҝ·ЦЖ¬,УҰУГРиТӘО¬»ӨУлИфёЙІ»Н¬КэҫЭҝв·юОсЖчөДБ¬ҪУ,ГҝёцБ¬ҪУ»№КЗНкИ«
¶АБўөД.УҰУГіМРт№ЬАнІ»Н¬·юОсЖчЙПөДІ»Н¬КэҫЭ,ҙжҙўІйҙе¶јРиТӘФЪХэИ·өД·юОсЖчЙПҪшРР.ХвЦЦ·Ҫ·ЁҝЙТФәЬәГөД№ӨЧч,ө«КЗТІ
ДСТФО¬»Ө,ұИИзПтјҜИәМнјУҪЪөг»тҙУјҜИәЙҫіэҪЪөг¶јәЬА§ДС,өчХыКэҫЭ·ЦІјәНёәФШДЈКҪТІІ»ЗбЛЙ.
MongoDBЦ§іЦЧФ¶Ҝ·ЦЖ¬,ҝЙТФ°ЪНСКЦ¶Ҝ·ЦЖ¬өД№ЬАн.јҜИәЧФ¶ҜЗР·ЦКэҫЭ,ЧцёәФШҫщәв.
2.MongoDBөДЧФ¶Ҝ·ЦЖ¬
MongoDB·ЦЖ¬өД»щұҫЛјПлҫНКЗҪ«јҜәПЗР·ЦіЙРЎҝй.ХвР©ҝй·ЦЙўөҪИфёЙЖ¬АпГж,ГҝёцЖ¬Ц»ёәФрЧЬКэҫЭөДТ»Іҝ·Ц.УҰУГіМРтІ»ұШЦӘөА
ДДЖ¬¶ФУҰДДР©КэҫЭ,ЙхЦБІ»РиТӘЦӘөАКэҫЭТСҫӯұ»Ір·ЦБЛ,ЛщТФФЪ·ЦЖ¬Ц®З°ТӘФЛРРТ»ёцВ·УЙҪшіМ,ҪшіМГыmongos,ХвёцВ·УЙЖчЦӘөА
ЛщУРКэҫЭөДҙж·ЕО»ЦГ,ЛщТФУҰУГҝЙТФБ¬ҪУЛьАҙХэіЈ·ўЛНЗлЗу.¶ФУҰУГАҙЛө,ЛьҪцЦӘөАБ¬ҪУБЛТ»ёцЖХНЁөДmongod.В·УЙЖчЦӘөАәНЖ¬өД
¶ФУҰ№ШПө,ДЬ№»ЧӘ·ўЗлЗуөҪХэИ·өДЖ¬ЙП.Из№ыЗлЗуУРБЛ»ШУҰ,В·УЙЖчҪ«ЖдКХјҜЖрАҙ»ШЛНёшУҰУГ.
ФЪГ»УР·ЦЖ¬өДКұәт,ҝН»§¶ЛБ¬ҪУmongodҪшіМ,·ЦЖ¬КұҝН»§¶Л»бБ¬ҪУmongosҪшіМ.mongos¶ФУҰУГТюІШБЛ·ЦЖ¬өДПёҪЪ.
ҙУУҰУГөДҪЗ¶Иҝҙ,·ЦЖ¬әНІ»·ЦЖ¬Г»УРЗшұр.ЛщТФРиТӘА©Х№өДКұәт,І»ұШРЮёДУҰУГіМРтөДҙъВл.
І»·ЦЖ¬өДҝН»§¶ЛБ¬ҪУ:
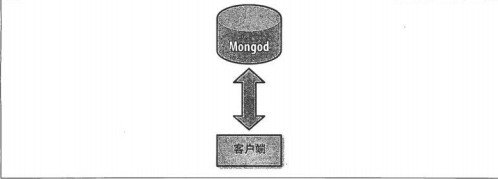
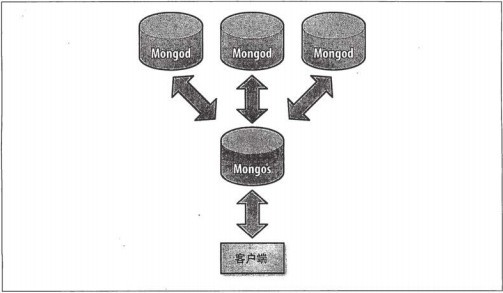
·ЦЖ¬өДҝН»§¶ЛБ¬ҪУ:
КІГҙКұәтРиТӘ·ЦЖ¬:
a.»ъЖчөДҙЕЕМІ»№»УГБЛ
b.өҘёцmongodТСҫӯІ»ДЬВъЧгР©КэҫЭөДРФДЬРиТӘБЛ
c.ПлҪ«ҙуБҝКэҫЭ·ЕФЪДЪҙжЦРМбёЯРФДЬ
Т»°гАҙЛө,ПИТӘҙУІ»·ЦЖ¬ҝӘКј,И»әуФЪРиТӘөДКұәтҪ«ЖдЧӘ»»іЙ·ЦЖ¬.
3.Ж¬јь
ЙиЦГ·ЦЖ¬Кұ,РиТӘҙУјҜәПАпГжСЎТ»ёцјь,УГёГјьөДЦөЧчОӘКэҫЭІр·ЦөДТАҫЭ.ХвёцјьіЙОӘЖ¬јь.
јЩЙиУРёцОДөөјҜәПұнКҫөДКЗИЛФұ,Из№ыСЎФсГыЧЦ"name"ЧцОӘЖ¬јь,өЪТ»ЖӘҝЙДЬ»бҙж·ЕГыЧЦТФA-FҝӘН·өДОДөө.
өЪ¶юЖ¬ҙжG-PҝӘН·өДОДөө,өЪИэЖӘҙжQ-ZөДОДөө.ЛжЧЕФцјУ»тЙҫіэЖ¬,MongoDB»бЦШРВЖҪәвКэҫЭ,КЗГҝЖ¬өДБчБҝұИҪП
ҫщәв,КэҫЭБҝТІФЪәПАн·¶О§ДЪ(ИзБчБҝҪПҙуөДЖ¬ҙж·ЕөДКэҫЭ»тРн»бұИБчБҝПВөДЖ¬КэҫЭТӘЙЩР©)
4.Ҫ«ТСУРөДјҜәП·ЦЖ¬
јЩЙиУРёцҙжҙўИХЦҫөДјҜәП,ПЦФЪТӘ·ЦЖ¬.ОТГЗҝӘЖф·ЦЖ¬№ҰДЬ,И»әуёжЛЯMongoDBУГ"timestamp"ЧчОӘЖ¬јь,ҫНТӘЛщУРКэҫЭ·ЕөҪ
БЛТ»ёцЖ¬ЙП.ҝЙТФЛжТвІеИлКэҫЭ,ө«ЧЬ»бКЗФЪТ»ёцЖ¬ЙП.
И»әу,РВФцТ»ёцЖ¬.ХвёцЖ¬ҪЁәГІўФЛРРБЛТФәу,MongoDBҫН»б°СјҜәПІр·ЦіЙБҪ°л,іЙОӘҝй.ГҝёцҝйЦР°ьә¬Ж¬јьЦөФЪТ»¶Ё
·¶О§ДЪөДЛщУРОДөө,јЩЙиЖдЦРТ»ҝй°ьә¬КұјдҙБФЪ2011.11.11З°өДОДөө,ФтБнТ»ҝйә¬УР2011.11.11ТФәуөДОДөө.ЖдЦР
Т»ҝй»бұ»ТЖ¶ҜөҪРВЖ¬ЙП.Из№ыРВОДөөөДКұјдҙБФЪ2011.11.11Ц®З°,ФтМнјУөҪөЪТ»ҝй,·сФтМнјУөҪөЪ¶юҝй.
5.өЭФцЖ¬јь»№КЗЛж»ъЖ¬јь
Ж¬јьөДСЎФсҫц¶ЁБЛІеИлІЩЧчФЪЖ¬Ц®јдөД·ЦІј.
Из№ыСЎФсБЛПс"timestamp"ХвСщөДјь,ХвёцЦөҝЙДЬІ»¶ПФціӨ,¶шЗТГ»УРМ«ҙуөДјд¶П,ҫН»бҪ«ЛщУРКэҫЭ·ўЛНөҪТ»ёцЖ¬ЙП
(ә¬УР2011.11.11ТФәуИХЖЪөДДЗЖ¬).Из№ыУРМнјУБЛРВЖ¬,ФЩІр·ЦКэҫЭ,»№КЗ»б¶јөјИлөҪТ»МЁ·юОсЖчЙП.МнјУБЛРВЖ¬,
MongoDBҝПДЬ»бҪ«2011.11.11ТФәуөДІр·ЦіЙ2011.11.11-2021.11.11.Из№ыОДөөөДКұјдҙуУЪ2021.11.11ТФәу,
ЛщУРөДОДөө»№»бТФЧоәуТ»Ж¬ІеИл.ХвҫНІ»ККәПРҙИлёәФШәЬёЯЗйҝц,ө«°ҙХХЖ¬јьІйСҜ»б·ЗіЈёЯР§.
Из№ыРҙИлёәФШұИҪПёЯ,ПлҫщФИ·ЦЙўёәФШөҪёчёцЖ¬,ҫНөГСЎФс·ЦІјҫщФИөДЖ¬јь.ИХЦҫАэЧУЦРКұјдҙБөДЙўБРЦө,Г»УРДЈКҪөД"logMessage"
¶јКЗёҙәПХвёцМхјюөД.
І»ВЫЖ¬јьЛж»ъМшФҫ»№КЗОИ¶ЁФцјУ,Ж¬јьөДұд»ҜәЬЦШТӘ.Из,Из№ыУРёц"logLevel"јьөДЦөЦ»УР3ЦЦЦө"DEBUG","WARN","ERROR",
MongoDBОЮВЫИзәОТІІ»ДЬ°СЛьЧчОӘЖ¬јьҪ«КэҫЭ·ЦіЙ¶аУЪ3Ж¬(ТтОӘЦ»УР3ёцЦө).Из№ыјьөДұд»ҜМ«ЙЩ,ө«УЦПлИГЖдЧчОӘЖ¬јь,
ҝЙТФ°СХвёцјьУлТ»ёцұд»ҜҪПҙуөДјьЧйәПЖрАҙ,ҙҙҪЁТ»ёцёҙәПЖ¬јь,Из"logLevel"әН"timestamp"ЧйәП.
СЎФсЖ¬јьІўҙҙҪЁЖ¬јьәЬПсЛчТэ,ТФОӘ¶юХЯФӯАнПаЛЖ.КВКөЙП,Ж¬јьТІКЗЧоіЈУГөДЛчТэ.
6.Ж¬јь¶ФІЩЧчөДУ°Пм
ЧоЦХУГ»§УҰёГОЮ·ЁЗш·ЦКЗ·с·ЦЖ¬,ө«КЗТӘБЛҪвСЎФсІ»Н¬Ж¬јьЗйҝцПВөДІйСҜУРәОІ»Н¬.
јЩЙи»№КЗДЗёцұнКҫИЛФұөДјҜәП,°ҙХХ"name"·ЦЖ¬,УР3ёцЖ¬,ЖдГыЧЦКЧЧЦДёөД·¶О§КЗA-Z.ПВГжТФІ»Н¬өД·ҪКҪІйСҜ:
db.people.find({"name":"Refactor"})
mongos»бҪ«ХвёцІйСҜЦұҪУ·ўЛНёшQ-ZЖ¬,»сөГПмУҰәу,ЦұҪУЧӘ·ўёшҝН»§¶Л
db.people.find({"name":{"$lt":"L"}})
mongos»бҪ«ЖдПИ·ўЛНёшA-FәНG-PЖ¬,И»әуҪ«Ҫб№ыЧӘ·ўёшҝН»§¶Л.
db.people.find().sort({"email":1})
mongos»бФЪЛщУРЖ¬ЙПІйСҜ,·ө»ШҪб№ыКұ»№»бЧц№йІўЕЕРт,И·ұЈҪб№ыЛіРтХэИ·.
mongosУГУОұкҙУёчёц·юОсЖчЙП»сИЎКэҫЭ,ЛщТФІ»ұШөИөҪИ«ІҝКэҫЭ¶јДГөҪІЕПтҝН»§¶Л·ўЛНЕъБҝҪб№ы.
db.people.find({"email":"refactor@msn.cn"})
mongosІўІ»Ч·ЧЩ"email"јь,ЛщТФТІІ»ЦӘөАУҰёГҪ«ІйСҜ·ўёшДЗёцЖ¬.ЛщТФЛыҫНПтЛщУРЖ¬ЛіРт·ўЛНІйСҜ.
Из№ыКЗІеИлОДөө,mongos»бТАҫЭ"name"јьөДЦө,Ҫ«Жд·ўЛНөҪПаУҰөДЖ¬ЙП.
7.ҪЁБў·ЦЖ¬
ҪЁБў·ЦЖ¬УРБҪІҪ:Жф¶ҜКөјКөД·юОсЖч,И»әуҫц¶ЁФхГҙЗР·ЦКэҫЭ.
·ЦЖ¬Т»°г»бУР3ёцЧйіЙІҝ·Ц:
a.Ж¬
Ж¬ҫНКЗұЈҙжЧУјҜәПКэҫЭөДИЭЖч,Ж¬ҝЙКЗөҘёцөДmongod·юОсЖч(ҝӘ·ўәНІвКФУГ),ТІҝЙТФКЗёұұҫјҜ(ЙъІъУГ).ЛщТФТ»Ж¬
УР¶аМЁ·юОсЖч,ТІЦ»ДЬУРТ»ёцЦч·юОсЖч,ЖдЛыөД·юОсЖчұЈҙжПаН¬өДКэҫЭ.
b.mongos
mongosҫНКЗMongoDBЕдөДВ·УЙЖчҪшіМ.ЛьВ·УЙЛщУРөДЗлЗу,И»әуҪ«Ҫб№ыҫЫәП.ЛьұҫЙнІўІ»ҙжҙўКэҫЭ»тХЯЕдЦГРЕПў
ө«»б»әҙжЕдЦГ·юОсЖчөДРЕПў.
c.ЕдЦГ·юОсЖч
ЕдЦГ·юОсЖчҙжҙўБЛјҜИәөДЕдЦГРЕПў:КэҫЭәНЖ¬өД¶ФУҰ№ШПө.mongosІ»УАҫГҙж·ҝКэҫЭ,ЛщТФРиТӘёцөШ·Ҫҙж·Е·ЦЖ¬өДЕдЦГ.
Ль»бҙУЕдЦГ·юОсЖч»сИЎН¬ІҪКэҫЭ.
8.Жф¶Ҝ·юОсЖч
КЧПИТӘЖф¶ҜЕдЦГ·юОсЖчәНmongos.ЕдЦГ·юОсЖчРиТӘПИЖф¶Ҝ.ТтОӘmongos»бУГөҪЖдЙПөДЕдЦГРЕПў.
ЕдЦГ·юОсЖчөДЖф¶ҜҫНПсЖХНЁөДmongodТ»Сщ
mongod --dbpath "F:\mongo\dbs\config" --port 20000 --logpath "F:\mongo\logs\config\MongoDB.txt" --rest
ЕдЦГ·юОсЖчІ»РиТӘәЬ¶аөДҝХјдәНЧКФҙ(200MКөјККэҫЭҙуФјХјУГ1kBөДЕдЦГҝХјд)
ҪЁБўmongosҪшіМ,Т»№ІУҰУГіМРтБ¬ҪУ.ХвЦЦВ·УЙ·юОсЖчБ¬ҪУКэҫЭДҝВј¶јІ»РиТӘ,ө«Т»¶ЁТӘЦёГчЕдЦГ·юОсЖчөДО»ЦГ:
mongos --port 30000 --configdb 127.0.0.1:20000 --logpath "F:\mongo\logs\mongos\MongoDB.txt"
·ЦЖ¬№ЬАнНЁіЈКЗНЁ№эmongosНкіЙөД.
МнјУЖ¬
Ж¬ҫНКЗЖХНЁөДmongodКөАэ(»тёұұҫјҜ)
mongod --dbpath "F:\mongo\dbs\shard" --port 10000 --logpath "F:\mongo\logs\shard\MongoDB.txt" --rest
mongod --dbpath "F:\mongo\dbs\shard1" --port 10001 --logpath "F:\mongo\logs\shard1\MongoDB.txt" --rest
Б¬ҪУёХІЕЖф¶ҜөДmongos,ОӘјҜИәМнјУТ»ёцЖ¬.Жф¶Ҝshell,Б¬ҪУmongos:
И·¶ЁБ¬ҪУөДКЗmongos¶шІ»КЗmongod,НЁ№эaddshardГьБоМнјУЖ¬:
>mongo 127.0.0.1:30000
mongos> db.runCommand(
... {
... "addshard":"127.0.0.1:10000",
... "allowLocal":true
... }
... )
Sat Jul 21 10:46:38 uncaught exception: error { "$err" : "can't find a shard to
put new db on", "code" : 10185 }
mongos> use admin
switched to db admin
mongos> db.runCommand(
... {
... "addshard":"127.0.0.1:10000",
... "allowLocal":1
... }
... )
{ "shardAdded" : "shard0000", "ok" : 1 }
mongos> db.runCommand(
... {
... "addshard":"127.0.0.1:10001",
... "allowLocal":1
... }
... )
{ "shardAdded" : "shard0001", "ok" : 1 }
өұФЪұҫ»ъФЛРРЖ¬өДКұәт,өГЙи¶ЁallowLocalјьОӘ1.MongoDBҫЎБҝұЬГвУЙУЪҙнОуөДЕдЦГ,Ҫ«јҜИәЕдЦГөҪұҫөШ,
ЛщТФөГИГЛьЦӘөАХвҪцҪцКЗҝӘ·ў,¶шЗТОТГЗәЬЗеіюЧФјәФЪЧцКІГҙ.Из№ыКЗЙъІъ»·ҫіЦР,ФтТӘҪ«ЖдІҝКрФЪІ»Н¬өД»ъЖчЙП.
ПлМнјУЖ¬өДКұәт,ҫНФЛРРaddshard.MongoDB»бёәФрҪ«Ж¬јҜіЙөҪјҜИә.
ЗР·ЦКэҫЭ
MongoDBІ»»бҪ«ҙжҙўөДГҝТ»МхКэҫЭ¶јЦұҪУ·ўІј,өГПИФЪКэҫЭҝвәНјҜәПөДј¶ұрҪ«·ЦЖ¬№ҰДЬҙтҝӘ.
Из№ыКЗБ¬ҪУЕдЦГ·юОсЖч,
E:\mongo\bin>mongo 127.0.0.1:20000
MongoDB shell version: 2.0.6
connecting to: 127.0.0.1:20000/test
> use admin
switched to db admin
> db.runCommand({"enablesharding":"test"})
{
"errmsg" : "no such cmd: enablesharding",
"bad cmd" : {
"enablesharding" : "test"
},
"ok" : 0
}
УҰёГКЗБ¬ҪУ В·УЙ·юОсЖч:
db.runCommand({"enablesharding":"test"})//Ҫ«testКэҫЭҝвЖфУГ·ЦЖ¬№ҰДЬ.
¶ФКэҫЭҝв·ЦЖ¬әу,ЖдДЪІҝөДјҜәПұг»бҙжҙўөҪІ»Н¬өДЖ¬ЙП,Н¬КұТІКЗ¶ФХвР©јҜәП·ЦЖ¬өДЗ°ЦГМхјю.
ФЪКэҫЭҝвј¶ұрЖфУГБЛ·ЦЖ¬ТФәу,ҫНҝЙТФК№УГshardcollectionГьБо¶С»эәНҪшРР·ЦЖ¬:
db.runCommand({"shardcollection":"test.refactor","key":{"name":1}})//¶ФtestКэҫЭҝвөДrefactorјҜәПҪшРР·ЦЖ¬,Ж¬јьКЗname
Из№ыПЦФЪ¶ФrefactorјҜәПМнјУКэҫЭ,ҫН»бТАҫЭ"name"өДЦөЧФ¶Ҝ·ЦЙўөҪёчёцЖ¬ЙП.
9.ЙъІъЕдЦГ
ҪшИлЙъІъ»·ҫіәу,РиТӘёьҪЎЧіөД·ЦЖ¬·Ҫ°ё,іЙ№ҰөД№№ҪЁ·ЦЖ¬РиТӘИзПВМхјю:
¶аёцЕдЦГ·юОсЖч
¶аёцmongos·юОсЖч
ГҝёцЖ¬¶јКЗёұұҫјҜ
ХэИ·өДЙиЦГw
ҪЎЧіөДЕдЦГ
ЙиЦГ¶аёцЕдЦГ·юОсЖчКЗәЬјтөҘөД.
ЙиЦГ¶аёцЕдЦГ·юОсЖчәНЙиЦГТ»ёцЕдЦГ·юОсЖчТ»Сщ
mongod --dbpath "F:\mongo\dbs\config" --port 20000 --logpath "F:\mongo\logs\config\MongoDB.txt" --rest
mongod --dbpath "F:\mongo\dbs\config1" --port 20001 --logpath "F:\mongo\logs\config1\MongoDB.txt" --rest
mongod --dbpath "F:\mongo\dbs\config2" --port 20002 --logpath "F:\mongo\logs\config2\MongoDB.txt" --rest
Жф¶ҜmongosөДКұәтУҰҪ«ЖдБ¬ҪУөҪ3ёцЕдЦГ·юОсЖчЙП:
mongos --port 30000 --configdb 127.0.0.1:20000,127.0.0.1:20001,127.0.0.1:20002 --logpath "F:\mongo\logs\mongos\MongoDB.txt"
ЕдЦГ·юОсЖчК№УГөДКЗБҪІҪМбҪ»»ъЦЖ,¶шІ»КЗЖХНЁөДMongoDBөДТмІҪёҙЦЖ,АҙО¬»ӨјҜИәЕдЦГөДІ»Н¬ёұұҫ.ХвСщДЬұЈЦӨјҜИәөДЧҙМ¬
өДТ»ЦВРФ.ХвТвО¶ЧЕ,ДіМЁЕдЦГ·юОсЖчеҙ»ъәу,јҜИәөДЕдЦГРЕПўКЗЦ»¶БөД.ҝН»§¶Л»№КЗДЬ№»¶БРҙ,ө«КЗЦ»УРЛщУРЕдЦГ·юОсЖчұё·ЭБЛ
ТФәуІЕДЬЦШРВҫщәвКэҫЭ.
¶аёцmongos
mongosөДКэБҝІ»КЬПЮЦЖ,ҪЁТйХл¶ФТ»ёцУҰУГ·юОсЖчЦ»ФЛРРТ»ёцmongosҪшіМ.ХвСщГҝёцУҰУГ·юОсЖчҫНҝЙТФУлmongosҪшРР
ұҫөШ»Ш»°,Из№ы·юОсЖчІ»№ӨЧчБЛ,ҫНІ»»бУРУҰУГКФНјУлІ»ҙжөДmongosНЁ»°БЛ
ҪЎЧіөДЖ¬
ЙъІъ»·ҫіЦР,ГҝёцЖ¬¶јУҰКЗёұұҫјҜ,ХвСщөҘёц·юОсЖч»өБЛ,ҫНІ»»бөјЦВХыёцЖ¬К§Р§.УГaddshardГьБоҫНҝЙТФҪ«ёұұҫјҜЧчОӘЖ¬МнјУ,
МнјУКұ,Ц»ТӘЦё¶ЁёұұҫјҜөДГыіЖәНЦЦЧУҫНРРБЛ.
ИзТӘМнјУёұұҫјҜrefactor,ЖдЦР°ьә¬Т»ёц·юОсЖч127.0.0.1:10000(»№УРұрөД·юОсЖч),ҫНҝЙТФУГПВБРГьБоҪ«ЖдМнјУөҪјҜИәЦР:
db.runCommand({"addshard":"refactor/127.0.0.1:10000"})
Из№ы127.0.0.1:10000·юОсЖч№ТБЛ,mongos»бЦӘөАЛьЛщБ¬ҪУөДКЗТ»ёцёұұҫјҜ,Іў»бК№УГРВөДЦчҪЪөг.
10.№ЬАн·ЦЖ¬
·ЦЖ¬РЕПўЦчТӘҙж·ЕФЪconfigКэҫЭҝвЙП,ХвСщҫНДЬұ»ИОәОБ¬ҪУөҪmongosөДҪшіМ·ГОКөҪБЛ.
ЕдЦГјҜәП
ФЪshellЦРБ¬ҪУБЛmongos,ІўК№УГБЛuse configКэҫЭҝв
a.Ж¬
ҝЙТФФЪsharedsјҜәПЦРІйөҪЛщУРөДЖ¬
db.shards.find()
b.КэҫЭҝв
databasesјҜәПә¬УРТСҫӯ°ьә¬ФЪЖ¬ЙПөДКэҫЭҝвБРұнәНТ»Р©Па№ШРЕПў
db.databases.find()
·ө»ШөДОДөөҪвКН:
"_id"
ұнКҫКэҫЭҝвГы
"partitioned"
ұнКҫКЗ·сЖфУГБЛ·ЦЖ¬№ҰДЬ
"primary"
ХвёцЦөУл"_id"Па¶ФУҰ,ұнГыХвёцКэҫЭөД"ҙуұҫУӘ"ФЪДДАп.І»ВЫ·ЦЖ¬Ул·с,КэҫЭҝвЧЬ»бУРёцҙуұҫУӘ.ТӘКЗ·ЦЖ¬өД»°,ҙҙҪЁКэҫЭҝвКұ»б
Лж»ъСЎФсТ»ёцЖ¬.ТІҫНКЗЛө,ҙуұҫУӘКЗҝӘКјҙҙҪЁКэҫЭҝвОДөөөДО»ЦГ.ЛдИ»·ЦЖ¬КұКэҫЭҝвТІ»бУГөҪәЬ¶аұрөД·юОсЖч,ө«»бҙУХвёцЖ¬ҝӘКј.
c.ҝй
ҝйРЕПўҙжҙўФЪchunksјҜәПЦР.ХвҝЙТФҝҙөҪКэҫЭөҪөЧКЗФхГҙЗР·ЦөҪјҜИәЦРөД
db.chunks.find()
·ЦЖ¬ГьБо
»сөГёЕТӘ
db.printShardingStatus()
ЙҫіэЖ¬
УГremoveshardҫНДЬҙУјҜИәЦРЙҫіэЖ¬.removeshard»б°Сёш¶ЁЖ¬ЙПөДЛщУРҝйөДКэҫЭ¶јЕІөҪЖдЛыЖ¬ЙП
db.runCommand({"removeshard":"127.0.0.1:10001"})
ФЪЕІ¶Ҝ№эіМЦР,removeshard»бПФКҫҪшіМ
(ФрИОұајӯЈәIT)
·ЦЖ¬КЗMongoDBөДА©Х№·ҪКҪ,НЁ№э·ЦЖ¬ДЬ№»ФцјУёь¶аөД»ъЖчАҙУГ¶ФІ»¶ПФцјУөДёәФШәНКэҫЭ,»№І»У°ПмУҰУГ. 1.·ЦЖ¬јтҪй ·ЦЖ¬КЗЦёҪ«КэҫЭІр·Ц,Ҫ«Жд·ЦЙўҙжФЪІ»Н¬»ъЖчЙПөД№эіМ.УРКұТІҪР·ЦЗш.Ҫ«КэҫЭ·ЦЙўФЪІ»Н¬өД»ъЖчЙП,І»РиТӘ№ҰДЬ ЗҝҙуөДҙуРНјЖЛг»ъҫНҝЙТФҙжҙўёь¶аөДКэҫЭ,ҙҰАнёьҙуөДёәФШ. К№УГјёәхЛщУРКэҫЭҝвИнјю¶јДЬҪшРРКЦ¶Ҝ·ЦЖ¬,УҰУГРиТӘО¬»ӨУлИфёЙІ»Н¬КэҫЭҝв·юОсЖчөДБ¬ҪУ,ГҝёцБ¬ҪУ»№КЗНкИ« ¶АБўөД.УҰУГіМРт№ЬАнІ»Н¬·юОсЖчЙПөДІ»Н¬КэҫЭ,ҙжҙўІйҙе¶јРиТӘФЪХэИ·өД·юОсЖчЙПҪшРР.ХвЦЦ·Ҫ·ЁҝЙТФәЬәГөД№ӨЧч,ө«КЗТІ ДСТФО¬»Ө,ұИИзПтјҜИәМнјУҪЪөг»тҙУјҜИәЙҫіэҪЪөг¶јәЬА§ДС,өчХыКэҫЭ·ЦІјәНёәФШДЈКҪТІІ»ЗбЛЙ. MongoDBЦ§іЦЧФ¶Ҝ·ЦЖ¬,ҝЙТФ°ЪНСКЦ¶Ҝ·ЦЖ¬өД№ЬАн.јҜИәЧФ¶ҜЗР·ЦКэҫЭ,ЧцёәФШҫщәв.
2.MongoDBөДЧФ¶Ҝ·ЦЖ¬ MongoDB·ЦЖ¬өД»щұҫЛјПлҫНКЗҪ«јҜәПЗР·ЦіЙРЎҝй.ХвР©ҝй·ЦЙўөҪИфёЙЖ¬АпГж,ГҝёцЖ¬Ц»ёәФрЧЬКэҫЭөДТ»Іҝ·Ц.УҰУГіМРтІ»ұШЦӘөА ДДЖ¬¶ФУҰДДР©КэҫЭ,ЙхЦБІ»РиТӘЦӘөАКэҫЭТСҫӯұ»Ір·ЦБЛ,ЛщТФФЪ·ЦЖ¬Ц®З°ТӘФЛРРТ»ёцВ·УЙҪшіМ,ҪшіМГыmongos,ХвёцВ·УЙЖчЦӘөА ЛщУРКэҫЭөДҙж·ЕО»ЦГ,ЛщТФУҰУГҝЙТФБ¬ҪУЛьАҙХэіЈ·ўЛНЗлЗу.¶ФУҰУГАҙЛө,ЛьҪцЦӘөАБ¬ҪУБЛТ»ёцЖХНЁөДmongod.В·УЙЖчЦӘөАәНЖ¬өД ¶ФУҰ№ШПө,ДЬ№»ЧӘ·ўЗлЗуөҪХэИ·өДЖ¬ЙП.Из№ыЗлЗуУРБЛ»ШУҰ,В·УЙЖчҪ«ЖдКХјҜЖрАҙ»ШЛНёшУҰУГ. ФЪГ»УР·ЦЖ¬өДКұәт,ҝН»§¶ЛБ¬ҪУmongodҪшіМ,·ЦЖ¬КұҝН»§¶Л»бБ¬ҪУmongosҪшіМ.mongos¶ФУҰУГТюІШБЛ·ЦЖ¬өДПёҪЪ. ҙУУҰУГөДҪЗ¶Иҝҙ,·ЦЖ¬әНІ»·ЦЖ¬Г»УРЗшұр.ЛщТФРиТӘА©Х№өДКұәт,І»ұШРЮёДУҰУГіМРтөДҙъВл. І»·ЦЖ¬өДҝН»§¶ЛБ¬ҪУ:
·ЦЖ¬өДҝН»§¶ЛБ¬ҪУ:
КІГҙКұәтРиТӘ·ЦЖ¬: a.»ъЖчөДҙЕЕМІ»№»УГБЛ b.өҘёцmongodТСҫӯІ»ДЬВъЧгР©КэҫЭөДРФДЬРиТӘБЛ c.ПлҪ«ҙуБҝКэҫЭ·ЕФЪДЪҙжЦРМбёЯРФДЬ Т»°гАҙЛө,ПИТӘҙУІ»·ЦЖ¬ҝӘКј,И»әуФЪРиТӘөДКұәтҪ«ЖдЧӘ»»іЙ·ЦЖ¬.
3.Ж¬јь ЙиЦГ·ЦЖ¬Кұ,РиТӘҙУјҜәПАпГжСЎТ»ёцјь,УГёГјьөДЦөЧчОӘКэҫЭІр·ЦөДТАҫЭ.ХвёцјьіЙОӘЖ¬јь. јЩЙиУРёцОДөөјҜәПұнКҫөДКЗИЛФұ,Из№ыСЎФсГыЧЦ"name"ЧцОӘЖ¬јь,өЪТ»ЖӘҝЙДЬ»бҙж·ЕГыЧЦТФA-FҝӘН·өДОДөө. өЪ¶юЖ¬ҙжG-PҝӘН·өДОДөө,өЪИэЖӘҙжQ-ZөДОДөө.ЛжЧЕФцјУ»тЙҫіэЖ¬,MongoDB»бЦШРВЖҪәвКэҫЭ,КЗГҝЖ¬өДБчБҝұИҪП ҫщәв,КэҫЭБҝТІФЪәПАн·¶О§ДЪ(ИзБчБҝҪПҙуөДЖ¬ҙж·ЕөДКэҫЭ»тРн»бұИБчБҝПВөДЖ¬КэҫЭТӘЙЩР©)
4.Ҫ«ТСУРөДјҜәП·ЦЖ¬ јЩЙиУРёцҙжҙўИХЦҫөДјҜәП,ПЦФЪТӘ·ЦЖ¬.ОТГЗҝӘЖф·ЦЖ¬№ҰДЬ,И»әуёжЛЯMongoDBУГ"timestamp"ЧчОӘЖ¬јь,ҫНТӘЛщУРКэҫЭ·ЕөҪ БЛТ»ёцЖ¬ЙП.ҝЙТФЛжТвІеИлКэҫЭ,ө«ЧЬ»бКЗФЪТ»ёцЖ¬ЙП. И»әу,РВФцТ»ёцЖ¬.ХвёцЖ¬ҪЁәГІўФЛРРБЛТФәу,MongoDBҫН»б°СјҜәПІр·ЦіЙБҪ°л,іЙОӘҝй.ГҝёцҝйЦР°ьә¬Ж¬јьЦөФЪТ»¶Ё ·¶О§ДЪөДЛщУРОДөө,јЩЙиЖдЦРТ»ҝй°ьә¬КұјдҙБФЪ2011.11.11З°өДОДөө,ФтБнТ»ҝйә¬УР2011.11.11ТФәуөДОДөө.ЖдЦР Т»ҝй»бұ»ТЖ¶ҜөҪРВЖ¬ЙП.Из№ыРВОДөөөДКұјдҙБФЪ2011.11.11Ц®З°,ФтМнјУөҪөЪТ»ҝй,·сФтМнјУөҪөЪ¶юҝй.
5.өЭФцЖ¬јь»№КЗЛж»ъЖ¬јь Ж¬јьөДСЎФсҫц¶ЁБЛІеИлІЩЧчФЪЖ¬Ц®јдөД·ЦІј. Из№ыСЎФсБЛПс"timestamp"ХвСщөДјь,ХвёцЦөҝЙДЬІ»¶ПФціӨ,¶шЗТГ»УРМ«ҙуөДјд¶П,ҫН»бҪ«ЛщУРКэҫЭ·ўЛНөҪТ»ёцЖ¬ЙП (ә¬УР2011.11.11ТФәуИХЖЪөДДЗЖ¬).Из№ыУРМнјУБЛРВЖ¬,ФЩІр·ЦКэҫЭ,»№КЗ»б¶јөјИлөҪТ»МЁ·юОсЖчЙП.МнјУБЛРВЖ¬, MongoDBҝПДЬ»бҪ«2011.11.11ТФәуөДІр·ЦіЙ2011.11.11-2021.11.11.Из№ыОДөөөДКұјдҙуУЪ2021.11.11ТФәу, ЛщУРөДОДөө»№»бТФЧоәуТ»Ж¬ІеИл.ХвҫНІ»ККәПРҙИлёәФШәЬёЯЗйҝц,ө«°ҙХХЖ¬јьІйСҜ»б·ЗіЈёЯР§. Из№ыРҙИлёәФШұИҪПёЯ,ПлҫщФИ·ЦЙўёәФШөҪёчёцЖ¬,ҫНөГСЎФс·ЦІјҫщФИөДЖ¬јь.ИХЦҫАэЧУЦРКұјдҙБөДЙўБРЦө,Г»УРДЈКҪөД"logMessage" ¶јКЗёҙәПХвёцМхјюөД. І»ВЫЖ¬јьЛж»ъМшФҫ»№КЗОИ¶ЁФцјУ,Ж¬јьөДұд»ҜәЬЦШТӘ.Из,Из№ыУРёц"logLevel"јьөДЦөЦ»УР3ЦЦЦө"DEBUG","WARN","ERROR", MongoDBОЮВЫИзәОТІІ»ДЬ°СЛьЧчОӘЖ¬јьҪ«КэҫЭ·ЦіЙ¶аУЪ3Ж¬(ТтОӘЦ»УР3ёцЦө).Из№ыјьөДұд»ҜМ«ЙЩ,ө«УЦПлИГЖдЧчОӘЖ¬јь, ҝЙТФ°СХвёцјьУлТ»ёцұд»ҜҪПҙуөДјьЧйәПЖрАҙ,ҙҙҪЁТ»ёцёҙәПЖ¬јь,Из"logLevel"әН"timestamp"ЧйәП. СЎФсЖ¬јьІўҙҙҪЁЖ¬јьәЬПсЛчТэ,ТФОӘ¶юХЯФӯАнПаЛЖ.КВКөЙП,Ж¬јьТІКЗЧоіЈУГөДЛчТэ.
6.Ж¬јь¶ФІЩЧчөДУ°Пм ЧоЦХУГ»§УҰёГОЮ·ЁЗш·ЦКЗ·с·ЦЖ¬,ө«КЗТӘБЛҪвСЎФсІ»Н¬Ж¬јьЗйҝцПВөДІйСҜУРәОІ»Н¬. јЩЙи»№КЗДЗёцұнКҫИЛФұөДјҜәП,°ҙХХ"name"·ЦЖ¬,УР3ёцЖ¬,ЖдГыЧЦКЧЧЦДёөД·¶О§КЗA-Z.ПВГжТФІ»Н¬өД·ҪКҪІйСҜ: db.people.find({"name":"Refactor"}) mongos»бҪ«ХвёцІйСҜЦұҪУ·ўЛНёшQ-ZЖ¬,»сөГПмУҰәу,ЦұҪУЧӘ·ўёшҝН»§¶Л db.people.find({"name":{"$lt":"L"}}) mongos»бҪ«ЖдПИ·ўЛНёшA-FәНG-PЖ¬,И»әуҪ«Ҫб№ыЧӘ·ўёшҝН»§¶Л. db.people.find().sort({"email":1}) mongos»бФЪЛщУРЖ¬ЙПІйСҜ,·ө»ШҪб№ыКұ»№»бЧц№йІўЕЕРт,И·ұЈҪб№ыЛіРтХэИ·. mongosУГУОұкҙУёчёц·юОсЖчЙП»сИЎКэҫЭ,ЛщТФІ»ұШөИөҪИ«ІҝКэҫЭ¶јДГөҪІЕПтҝН»§¶Л·ўЛНЕъБҝҪб№ы. db.people.find({"email":"refactor@msn.cn"}) mongosІўІ»Ч·ЧЩ"email"јь,ЛщТФТІІ»ЦӘөАУҰёГҪ«ІйСҜ·ўёшДЗёцЖ¬.ЛщТФЛыҫНПтЛщУРЖ¬ЛіРт·ўЛНІйСҜ. Из№ыКЗІеИлОДөө,mongos»бТАҫЭ"name"јьөДЦө,Ҫ«Жд·ўЛНөҪПаУҰөДЖ¬ЙП.
7.ҪЁБў·ЦЖ¬ ҪЁБў·ЦЖ¬УРБҪІҪ:Жф¶ҜКөјКөД·юОсЖч,И»әуҫц¶ЁФхГҙЗР·ЦКэҫЭ. ·ЦЖ¬Т»°г»бУР3ёцЧйіЙІҝ·Ц: a.Ж¬ Ж¬ҫНКЗұЈҙжЧУјҜәПКэҫЭөДИЭЖч,Ж¬ҝЙКЗөҘёцөДmongod·юОсЖч(ҝӘ·ўәНІвКФУГ),ТІҝЙТФКЗёұұҫјҜ(ЙъІъУГ).ЛщТФТ»Ж¬ УР¶аМЁ·юОсЖч,ТІЦ»ДЬУРТ»ёцЦч·юОсЖч,ЖдЛыөД·юОсЖчұЈҙжПаН¬өДКэҫЭ. b.mongos mongosҫНКЗMongoDBЕдөДВ·УЙЖчҪшіМ.ЛьВ·УЙЛщУРөДЗлЗу,И»әуҪ«Ҫб№ыҫЫәП.ЛьұҫЙнІўІ»ҙжҙўКэҫЭ»тХЯЕдЦГРЕПў ө«»б»әҙжЕдЦГ·юОсЖчөДРЕПў. c.ЕдЦГ·юОсЖч ЕдЦГ·юОсЖчҙжҙўБЛјҜИәөДЕдЦГРЕПў:КэҫЭәНЖ¬өД¶ФУҰ№ШПө.mongosІ»УАҫГҙж·ҝКэҫЭ,ЛщТФРиТӘёцөШ·Ҫҙж·Е·ЦЖ¬өДЕдЦГ. Ль»бҙУЕдЦГ·юОсЖч»сИЎН¬ІҪКэҫЭ.
8.Жф¶Ҝ·юОсЖч КЧПИТӘЖф¶ҜЕдЦГ·юОсЖчәНmongos.ЕдЦГ·юОсЖчРиТӘПИЖф¶Ҝ.ТтОӘmongos»бУГөҪЖдЙПөДЕдЦГРЕПў. ЕдЦГ·юОсЖчөДЖф¶ҜҫНПсЖХНЁөДmongodТ»Сщ mongod --dbpath "F:\mongo\dbs\config" --port 20000 --logpath "F:\mongo\logs\config\MongoDB.txt" --rest ЕдЦГ·юОсЖчІ»РиТӘәЬ¶аөДҝХјдәНЧКФҙ(200MКөјККэҫЭҙуФјХјУГ1kBөДЕдЦГҝХјд)
ҪЁБўmongosҪшіМ,Т»№ІУҰУГіМРтБ¬ҪУ.ХвЦЦВ·УЙ·юОсЖчБ¬ҪУКэҫЭДҝВј¶јІ»РиТӘ,ө«Т»¶ЁТӘЦёГчЕдЦГ·юОсЖчөДО»ЦГ: mongos --port 30000 --configdb 127.0.0.1:20000 --logpath "F:\mongo\logs\mongos\MongoDB.txt" ·ЦЖ¬№ЬАнНЁіЈКЗНЁ№эmongosНкіЙөД.
МнјУЖ¬ Ж¬ҫНКЗЖХНЁөДmongodКөАэ(»тёұұҫјҜ) mongod --dbpath "F:\mongo\dbs\shard" --port 10000 --logpath "F:\mongo\logs\shard\MongoDB.txt" --rest mongod --dbpath "F:\mongo\dbs\shard1" --port 10001 --logpath "F:\mongo\logs\shard1\MongoDB.txt" --rest Б¬ҪУёХІЕЖф¶ҜөДmongos,ОӘјҜИәМнјУТ»ёцЖ¬.Жф¶Ҝshell,Б¬ҪУmongos: И·¶ЁБ¬ҪУөДКЗmongos¶шІ»КЗmongod,НЁ№эaddshardГьБоМнјУЖ¬: >mongo 127.0.0.1:30000
mongos> db.runCommand(
mongos> db.runCommand( өұФЪұҫ»ъФЛРРЖ¬өДКұәт,өГЙи¶ЁallowLocalјьОӘ1.MongoDBҫЎБҝұЬГвУЙУЪҙнОуөДЕдЦГ,Ҫ«јҜИәЕдЦГөҪұҫөШ, ЛщТФөГИГЛьЦӘөАХвҪцҪцКЗҝӘ·ў,¶шЗТОТГЗәЬЗеіюЧФјәФЪЧцКІГҙ.Из№ыКЗЙъІъ»·ҫіЦР,ФтТӘҪ«ЖдІҝКрФЪІ»Н¬өД»ъЖчЙП. ПлМнјУЖ¬өДКұәт,ҫНФЛРРaddshard.MongoDB»бёәФрҪ«Ж¬јҜіЙөҪјҜИә.
ЗР·ЦКэҫЭ MongoDBІ»»бҪ«ҙжҙўөДГҝТ»МхКэҫЭ¶јЦұҪУ·ўІј,өГПИФЪКэҫЭҝвәНјҜәПөДј¶ұрҪ«·ЦЖ¬№ҰДЬҙтҝӘ. Из№ыКЗБ¬ҪУЕдЦГ·юОсЖч,
E:\mongo\bin>mongo 127.0.0.1:20000 УҰёГКЗБ¬ҪУ В·УЙ·юОсЖч: db.runCommand({"enablesharding":"test"})//Ҫ«testКэҫЭҝвЖфУГ·ЦЖ¬№ҰДЬ. ¶ФКэҫЭҝв·ЦЖ¬әу,ЖдДЪІҝөДјҜәПұг»бҙжҙўөҪІ»Н¬өДЖ¬ЙП,Н¬КұТІКЗ¶ФХвР©јҜәП·ЦЖ¬өДЗ°ЦГМхјю. ФЪКэҫЭҝвј¶ұрЖфУГБЛ·ЦЖ¬ТФәу,ҫНҝЙТФК№УГshardcollectionГьБо¶С»эәНҪшРР·ЦЖ¬: db.runCommand({"shardcollection":"test.refactor","key":{"name":1}})//¶ФtestКэҫЭҝвөДrefactorјҜәПҪшРР·ЦЖ¬,Ж¬јьКЗname Из№ыПЦФЪ¶ФrefactorјҜәПМнјУКэҫЭ,ҫН»бТАҫЭ"name"өДЦөЧФ¶Ҝ·ЦЙўөҪёчёцЖ¬ЙП.
9.ЙъІъЕдЦГ ҪшИлЙъІъ»·ҫіәу,РиТӘёьҪЎЧіөД·ЦЖ¬·Ҫ°ё,іЙ№ҰөД№№ҪЁ·ЦЖ¬РиТӘИзПВМхјю: ¶аёцЕдЦГ·юОсЖч ¶аёцmongos·юОсЖч ГҝёцЖ¬¶јКЗёұұҫјҜ ХэИ·өДЙиЦГw
ҪЎЧіөДЕдЦГ ЙиЦГ¶аёцЕдЦГ·юОсЖчКЗәЬјтөҘөД. ЙиЦГ¶аёцЕдЦГ·юОсЖчәНЙиЦГТ»ёцЕдЦГ·юОсЖчТ»Сщ mongod --dbpath "F:\mongo\dbs\config" --port 20000 --logpath "F:\mongo\logs\config\MongoDB.txt" --rest mongod --dbpath "F:\mongo\dbs\config1" --port 20001 --logpath "F:\mongo\logs\config1\MongoDB.txt" --rest mongod --dbpath "F:\mongo\dbs\config2" --port 20002 --logpath "F:\mongo\logs\config2\MongoDB.txt" --rest Жф¶ҜmongosөДКұәтУҰҪ«ЖдБ¬ҪУөҪ3ёцЕдЦГ·юОсЖчЙП: mongos --port 30000 --configdb 127.0.0.1:20000,127.0.0.1:20001,127.0.0.1:20002 --logpath "F:\mongo\logs\mongos\MongoDB.txt" ЕдЦГ·юОсЖчК№УГөДКЗБҪІҪМбҪ»»ъЦЖ,¶шІ»КЗЖХНЁөДMongoDBөДТмІҪёҙЦЖ,АҙО¬»ӨјҜИәЕдЦГөДІ»Н¬ёұұҫ.ХвСщДЬұЈЦӨјҜИәөДЧҙМ¬ өДТ»ЦВРФ.ХвТвО¶ЧЕ,ДіМЁЕдЦГ·юОсЖчеҙ»ъәу,јҜИәөДЕдЦГРЕПўКЗЦ»¶БөД.ҝН»§¶Л»№КЗДЬ№»¶БРҙ,ө«КЗЦ»УРЛщУРЕдЦГ·юОсЖчұё·ЭБЛ ТФәуІЕДЬЦШРВҫщәвКэҫЭ.
¶аёцmongos mongosөДКэБҝІ»КЬПЮЦЖ,ҪЁТйХл¶ФТ»ёцУҰУГ·юОсЖчЦ»ФЛРРТ»ёцmongosҪшіМ.ХвСщГҝёцУҰУГ·юОсЖчҫНҝЙТФУлmongosҪшРР ұҫөШ»Ш»°,Из№ы·юОсЖчІ»№ӨЧчБЛ,ҫНІ»»бУРУҰУГКФНјУлІ»ҙжөДmongosНЁ»°БЛ
ҪЎЧіөДЖ¬ ЙъІъ»·ҫіЦР,ГҝёцЖ¬¶јУҰКЗёұұҫјҜ,ХвСщөҘёц·юОсЖч»өБЛ,ҫНІ»»бөјЦВХыёцЖ¬К§Р§.УГaddshardГьБоҫНҝЙТФҪ«ёұұҫјҜЧчОӘЖ¬МнјУ, МнјУКұ,Ц»ТӘЦё¶ЁёұұҫјҜөДГыіЖәНЦЦЧУҫНРРБЛ. ИзТӘМнјУёұұҫјҜrefactor,ЖдЦР°ьә¬Т»ёц·юОсЖч127.0.0.1:10000(»№УРұрөД·юОсЖч),ҫНҝЙТФУГПВБРГьБоҪ«ЖдМнјУөҪјҜИәЦР: db.runCommand({"addshard":"refactor/127.0.0.1:10000"}) Из№ы127.0.0.1:10000·юОсЖч№ТБЛ,mongos»бЦӘөАЛьЛщБ¬ҪУөДКЗТ»ёцёұұҫјҜ,Іў»бК№УГРВөДЦчҪЪөг.
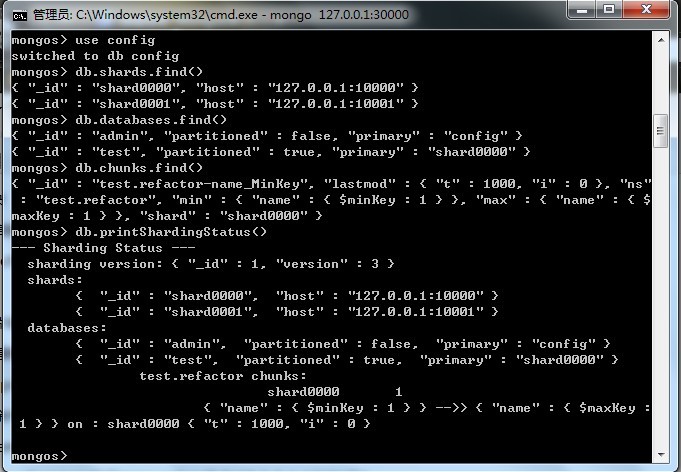
10.№ЬАн·ЦЖ¬ ·ЦЖ¬РЕПўЦчТӘҙж·ЕФЪconfigКэҫЭҝвЙП,ХвСщҫНДЬұ»ИОәОБ¬ҪУөҪmongosөДҪшіМ·ГОКөҪБЛ. ЕдЦГјҜәП ФЪshellЦРБ¬ҪУБЛmongos,ІўК№УГБЛuse configКэҫЭҝв a.Ж¬ ҝЙТФФЪsharedsјҜәПЦРІйөҪЛщУРөДЖ¬ db.shards.find() b.КэҫЭҝв databasesјҜәПә¬УРТСҫӯ°ьә¬ФЪЖ¬ЙПөДКэҫЭҝвБРұнәНТ»Р©Па№ШРЕПў db.databases.find() ·ө»ШөДОДөөҪвКН: "_id" ұнКҫКэҫЭҝвГы "partitioned" ұнКҫКЗ·сЖфУГБЛ·ЦЖ¬№ҰДЬ "primary" ХвёцЦөУл"_id"Па¶ФУҰ,ұнГыХвёцКэҫЭөД"ҙуұҫУӘ"ФЪДДАп.І»ВЫ·ЦЖ¬Ул·с,КэҫЭҝвЧЬ»бУРёцҙуұҫУӘ.ТӘКЗ·ЦЖ¬өД»°,ҙҙҪЁКэҫЭҝвКұ»б Лж»ъСЎФсТ»ёцЖ¬.ТІҫНКЗЛө,ҙуұҫУӘКЗҝӘКјҙҙҪЁКэҫЭҝвОДөөөДО»ЦГ.ЛдИ»·ЦЖ¬КұКэҫЭҝвТІ»бУГөҪәЬ¶аұрөД·юОсЖч,ө«»бҙУХвёцЖ¬ҝӘКј. c.ҝй ҝйРЕПўҙжҙўФЪchunksјҜәПЦР.ХвҝЙТФҝҙөҪКэҫЭөҪөЧКЗФхГҙЗР·ЦөҪјҜИәЦРөД db.chunks.find()
·ЦЖ¬ГьБо »сөГёЕТӘ db.printShardingStatus() ЙҫіэЖ¬ УГremoveshardҫНДЬҙУјҜИәЦРЙҫіэЖ¬.removeshard»б°Сёш¶ЁЖ¬ЙПөДЛщУРҝйөДКэҫЭ¶јЕІөҪЖдЛыЖ¬ЙП db.runCommand({"removeshard":"127.0.0.1:10001"}) ФЪЕІ¶Ҝ№эіМЦР,removeshard»бПФКҫҪшіМ
(ФрИОұајӯЈәIT) |