滴滴史上最严重服务故障,罪魁祸首是底层软件 or “降本增笑”?
时间:2023-12-05 11:23 来源:未知 作者:IT
2023 年 11 月 27 日晚间,滴滴因系统故障导致 App 服务异常,不显示定位且无法打车。11 月 27 日晚,滴滴出行进行了回复:非常抱歉,由于系统故障。
2023 年 11 月 28 日早间,滴滴出行消息称,网约车等服务已恢复,骑车等在陆续修复中。11 月 28 日,在滴滴发出公告的同时,记者在上海、深圳等地使用滴滴呼叫网约车,发现网约车功能并未恢复使用,网络加载异常,仍无法打车。11 月 28 日,滴滴向记者回应称,网约车服务已恢复,司机乘客权益陆续恢复补发。
11 月 29 日,滴滴再次发文致歉,称初步确定事故起因是底层系统软件发生故障。

来源:https://weibo.com/2838754010/NuMAAaUEl
在滴滴官方发布这份公告之前,已经有资深 IT 技术人士分析:“从表现上看,打车、共享单车全挂,不同的业务板块之间应该是有隔离的,说明问题出在更加底层的基础设施。攻击者一般只能访问到应用层,基础设施访问不到。要么是被攻击者打穿,要么是自己系统操作不慎挂了。即便是前者,也算是一种系统缺陷,才会被打穿。”
360 安全专家认为,滴滴闪崩背后的技术原因可能有六种:
第一,系统更新升级过程中出现了编程错误、逻辑错误或未处理的异常情况:一般情况下,互联网厂商发布更新都会在晚上,与滴滴发生故障的时间也能对应,当然业务升级维护是放量更新,但现在滴滴全平台、全业务都故障了,说明肯定是他 “家里” 的问题。
第二,服务器故障:比如滴滴的核心机房,可能恒温恒湿环境出了问题,导致服务器过热、CPU 烧了,或者核心机房所在地发生了自然灾害如地震、洪水、海啸等,这种情况下,硬件需要重新更换,里面的服务软件也需要重新配置,恢复周期相对较长,但这个可能性比较小。
第三,第三方服务故障:滴滴的后台架构可能使用了第三方服务或者组件。如果第三方出了问题,也可能会影响滴滴的正常运行。但出于安全性考虑,滴滴可能不会将核心业务托管给第三方,不过这个可能性也较小。
第四,DDOS 攻击:黑客采用分布式拒绝服务的方式,抢占了大量的服务器资源,导致用户无法访问,但这个不太可能,因为 DDos 不会导致数据出错,而且滴滴从体量上来说,有足够的成本和能力去对抗。
第五,其他网络攻击:某些黑灰产团伙可能会通过拖库盗取数据,然后在暗网上售卖,在这个过程中不排除会有误操作,破坏了数据库。
第六,勒索病毒:网络攻击黑客对滴滴的底层数据、业务代码进行了加密。据披露现象,用户的账单和打车数据都算错了,存在一定可能是滴滴为了避免更大损失主动暂停了业务。近期勒索攻击事件屡屡发生,月初,某金融机构就是因为遭遇勒索病毒攻击造成了业务停摆。
不过也有网络安全公司专家认为,如果是来自外部的黑客攻击,公司一般会在第一时间进行声明。他猜测更集中于滴滴发生了内部重大业务调整,或有新业务接入原系统,但没有做好预案,导致关联业务或关联系统出现重大故障,这是大公司系统故障最常见的原因。
因此对于滴滴此次大规模的长时间故障,有行业人士认为,降本增效可能也是原因之一。
该人士认为,互联网公司核心业务频繁宕机,且长时间宕机,是降本增效的附属品之一。系统投资少了,维护资源少了,程序员更换频繁了,BUG 就多。
他举例称,一般在业务上行阶段都有冗余,为了迎接随时爆发的订单,上行阶段要维持负载的上限不能过大,比如平时 70%,这样遇到一个小爆发不用担心会出问题,足以应对小高峰;但是下行期的逻辑就不同了,负载很高的时候抗一抗就行了,虽然后面遇到小高峰可能会难受,但是随着时间的推移总体负载会下降。
最后来看一下网传的消息,有同行说滴滴这次严重故障是升级 k8s 版本导致,当时 SRE 工程师定位了三个小时都没定位到问题。


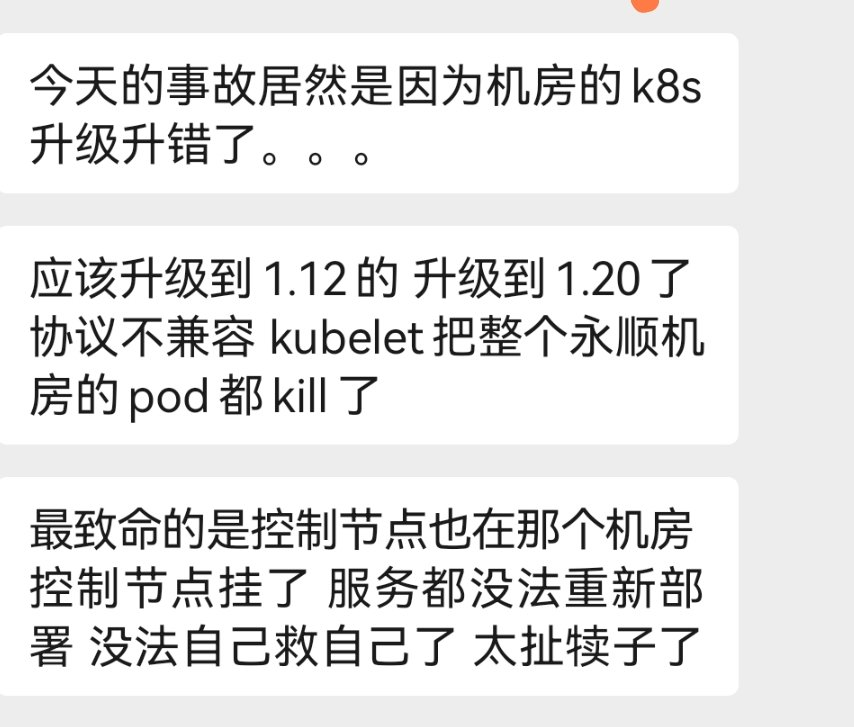
从滴滴公开的技术分享来看,滴滴弹性云在上个月升级了 k8s 版本:从 k8s 1.12 升级到 1.20。
-
K8s 1.12 发布于 2018 年:Kubernetes 1.12 正式发布,新增 VMSS 支持
-
K8s 1.20 发布于 2020 年:Kubernetes 1.20 发布:妙啊

来源:滴滴弹性云基于 K8S 的调度实践
(责任编辑:IT)
2023 年 11 月 27 日晚间,滴滴因系统故障导致 App 服务异常,不显示定位且无法打车。11 月 27 日晚,滴滴出行进行了回复:非常抱歉,由于系统故障。 2023 年 11 月 28 日早间,滴滴出行消息称,网约车等服务已恢复,骑车等在陆续修复中。11 月 28 日,在滴滴发出公告的同时,记者在上海、深圳等地使用滴滴呼叫网约车,发现网约车功能并未恢复使用,网络加载异常,仍无法打车。11 月 28 日,滴滴向记者回应称,网约车服务已恢复,司机乘客权益陆续恢复补发。 11 月 29 日,滴滴再次发文致歉,称初步确定事故起因是底层系统软件发生故障。
在滴滴官方发布这份公告之前,已经有资深 IT 技术人士分析:“从表现上看,打车、共享单车全挂,不同的业务板块之间应该是有隔离的,说明问题出在更加底层的基础设施。攻击者一般只能访问到应用层,基础设施访问不到。要么是被攻击者打穿,要么是自己系统操作不慎挂了。即便是前者,也算是一种系统缺陷,才会被打穿。” 360 安全专家认为,滴滴闪崩背后的技术原因可能有六种: 第一,系统更新升级过程中出现了编程错误、逻辑错误或未处理的异常情况:一般情况下,互联网厂商发布更新都会在晚上,与滴滴发生故障的时间也能对应,当然业务升级维护是放量更新,但现在滴滴全平台、全业务都故障了,说明肯定是他 “家里” 的问题。 第二,服务器故障:比如滴滴的核心机房,可能恒温恒湿环境出了问题,导致服务器过热、CPU 烧了,或者核心机房所在地发生了自然灾害如地震、洪水、海啸等,这种情况下,硬件需要重新更换,里面的服务软件也需要重新配置,恢复周期相对较长,但这个可能性比较小。 第三,第三方服务故障:滴滴的后台架构可能使用了第三方服务或者组件。如果第三方出了问题,也可能会影响滴滴的正常运行。但出于安全性考虑,滴滴可能不会将核心业务托管给第三方,不过这个可能性也较小。 第四,DDOS 攻击:黑客采用分布式拒绝服务的方式,抢占了大量的服务器资源,导致用户无法访问,但这个不太可能,因为 DDos 不会导致数据出错,而且滴滴从体量上来说,有足够的成本和能力去对抗。 第五,其他网络攻击:某些黑灰产团伙可能会通过拖库盗取数据,然后在暗网上售卖,在这个过程中不排除会有误操作,破坏了数据库。 第六,勒索病毒:网络攻击黑客对滴滴的底层数据、业务代码进行了加密。据披露现象,用户的账单和打车数据都算错了,存在一定可能是滴滴为了避免更大损失主动暂停了业务。近期勒索攻击事件屡屡发生,月初,某金融机构就是因为遭遇勒索病毒攻击造成了业务停摆。 不过也有网络安全公司专家认为,如果是来自外部的黑客攻击,公司一般会在第一时间进行声明。他猜测更集中于滴滴发生了内部重大业务调整,或有新业务接入原系统,但没有做好预案,导致关联业务或关联系统出现重大故障,这是大公司系统故障最常见的原因。 因此对于滴滴此次大规模的长时间故障,有行业人士认为,降本增效可能也是原因之一。 该人士认为,互联网公司核心业务频繁宕机,且长时间宕机,是降本增效的附属品之一。系统投资少了,维护资源少了,程序员更换频繁了,BUG 就多。 他举例称,一般在业务上行阶段都有冗余,为了迎接随时爆发的订单,上行阶段要维持负载的上限不能过大,比如平时 70%,这样遇到一个小爆发不用担心会出问题,足以应对小高峰;但是下行期的逻辑就不同了,负载很高的时候抗一抗就行了,虽然后面遇到小高峰可能会难受,但是随着时间的推移总体负载会下降。 最后来看一下网传的消息,有同行说滴滴这次严重故障是升级 k8s 版本导致,当时 SRE 工程师定位了三个小时都没定位到问题。 从滴滴公开的技术分享来看,滴滴弹性云在上个月升级了 k8s 版本:从 k8s 1.12 升级到 1.20。
(责任编辑:IT) |