PolarDB-X V2.4 列存引擎开源正式发布
时间:2024-05-15 11:25 来源:未知 作者:IT
PolarDB 分布式版 (PolarDB for Xscale,以下简称 “PolarDB-X”) 是阿里云自主设计研发的高性能云原生分布式数据库产品,为用户提供高吞吐、大存储、低延时、易扩展和超高可用的云时代数据库服务。
架构简介
PolarDB-X 采用 Shared-nothing 与存储分离计算架构进行设计,系统由 5 个核心组件组成。
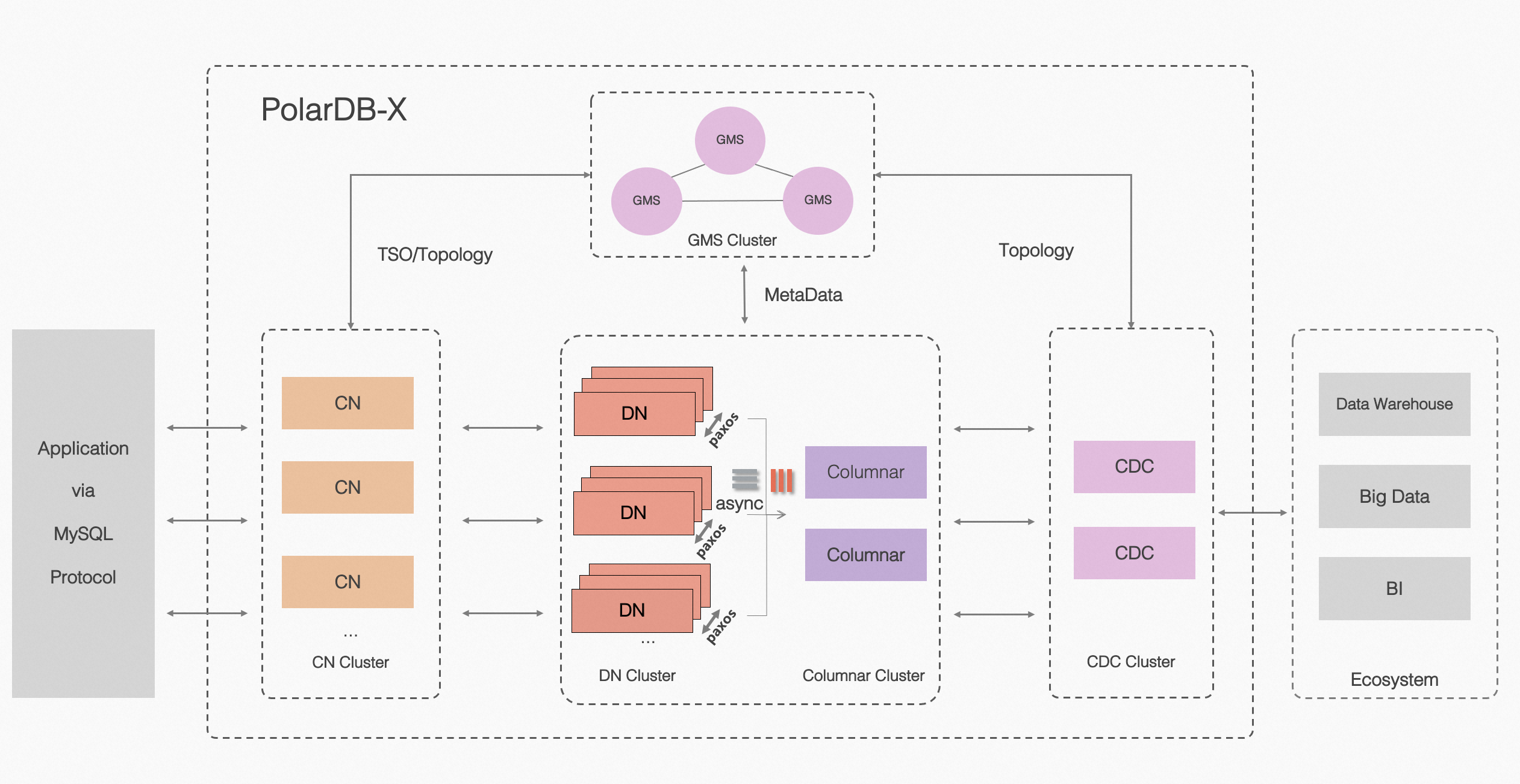
PolarDB 分布式 架构图
-
计算节点(CN, Compute Node) 计算节点是系统的入口,采用无状态设计,包括 SQL 解析器、优化器、执行器等模块。负责数据分布式路由、计算及动态调度,负责分布式事务 2PC 协调、全局二级索引维护等,同时提供 SQL 限流、三权分立等企业级特性。
-
存储节点(DN, Data Node) 存储节点负责数据的持久化,基于多数派 Paxos 协议提供数据高可靠、强一致保障,同时通过 MVCC 维护分布式事务可见性。
-
元数据服务(GMS, Global Meta Service) 元数据服务负责维护全局强一致的 Table/Schema, Statistics 等系统 Meta 信息,维护账号、权限等安全信息,同时提供全局授时服务(即 TSO)。
-
日志节点(CDC, Change Data Capture) 日志节点提供完全兼容 MySQL Binlog 格式和协议的增量订阅能力,提供兼容 MySQL Replication 协议的主从复制能力。
-
列存节点 (Columnar) 列存节点提供持久化列存索引,实时消费分布式事务的 binlog 日志,基于对象存储介质构建列存索引,能满足实时更新的需求、以及结合计算节点可提供列存的快照一致性查询能力
开源地址:https://github.com/polardb/polardbx-sql
版本说明
梳理下 PolarDB-X 开源脉络:
-
2021 年 10 月,在云栖大会上,阿里云正式对外开源了云原生分布式数据库 PolarDB-X,采用全内核开源的模式,开源内容包含计算引擎、存储引擎、日志引擎、Kube 等。
-
2022 年 1 月,PolarDB-X 正式发布 2.0.0 版本,继 2021 年 10 月 20 号云栖大会正式开源后的第一次版本更新,更新内容包括新增集群扩缩容、以及 binlog 生态兼容等特性,兼容 maxwell 和 debezium 增量日志订阅,以及新增其他众多新特性和修复若干问题。
-
2022 年 3 月,PolarDB-X 正式发布 2.1.0 版本,包含了四大核心特性,全面提升 PolarDB-X 稳定性和生态兼容性,其中包含基于 Paxos 的三副本共识协议。
-
2022 年 5 月,PolarDB-X 正式发布 2.1.1 版本,重点推出冷热数据新特性,可以支持业务表的数据按照数据特性分别存储在不同的存储介质上,比如将冷数据存储到 Aliyun OSS 对象存储上。
-
2022 年 10 月,PolarDB-X 正式发布 2.2.0 版本,这是一个重要的里程碑版本,重点推出符合分布式数据库金融标准下的企业级和国产 ARM 适配,共包括八大核心特性,全面提升 PolarDB-X 分布式数据库在金融、通讯、政务等行业的普适性。
-
2023 年 3 月,PolarDB-X 正式发布 2.2.1 版本,在分布式数据库金融标准能力基础上,重点加强了生产级关键能力,全面提升 PolarDB-X 面向数据库生产环境的易用性和安全性,比如:提供数据快速导入、性能测试验证、生产部署建议等。
-
2023 年 10 月份,PolarDB-X 正式发布 2.3.0 版本,重点推出 PolarDB-X 标准版(集中式形态),将 PolarDB-X 分布式中的 DN 节点提供单独服务,支持 paxos 协议的多副本模式、lizard 分布式事务引擎,同时可以 100% 兼容 MySQL,对应 PolarDB-X 公有云的标准版。
2024 年 4 月份,PolarDB-X 正式发布 2.4.0 版本,重点推出列存节点 Columnar,可以提供持久化列存索引(Clustered Columnar Index,CCI)。PolarDB-X 的行存表默认有主键索引和二级索引,列存索引是一份额外基于列式结构的二级索引(默认覆盖行存所有列),一张表可以同时具备行存和列存的数据,结合计算节点 CN 的向量化计算,可以满足分布式下的查询加速的诉求,实现 HTAP 一体化的体验和效果。
01 列存索引
随着云原生技术的不断普及,以 Snowflake 为代表的新一代云原生数仓、以及数据库 HTAP 架构不断创新,可见在未来一段时间后行列混存 HTAP 会成为一个数据库的标配能力,需要在当前数据库列存设计中面相未来的低成本、易用性、高性能上有更多的思考
PolarDB-X 在 V2.4 版本正式发布列存引擎,提供列存索引的形态(Clustered Columnar Index,CCI),行存表默认有主键索引和二级索引,列存索引是一份额外基于列式结构的二级索引(覆盖行存所有列),一张表可以同时具备行存和列存的数据。
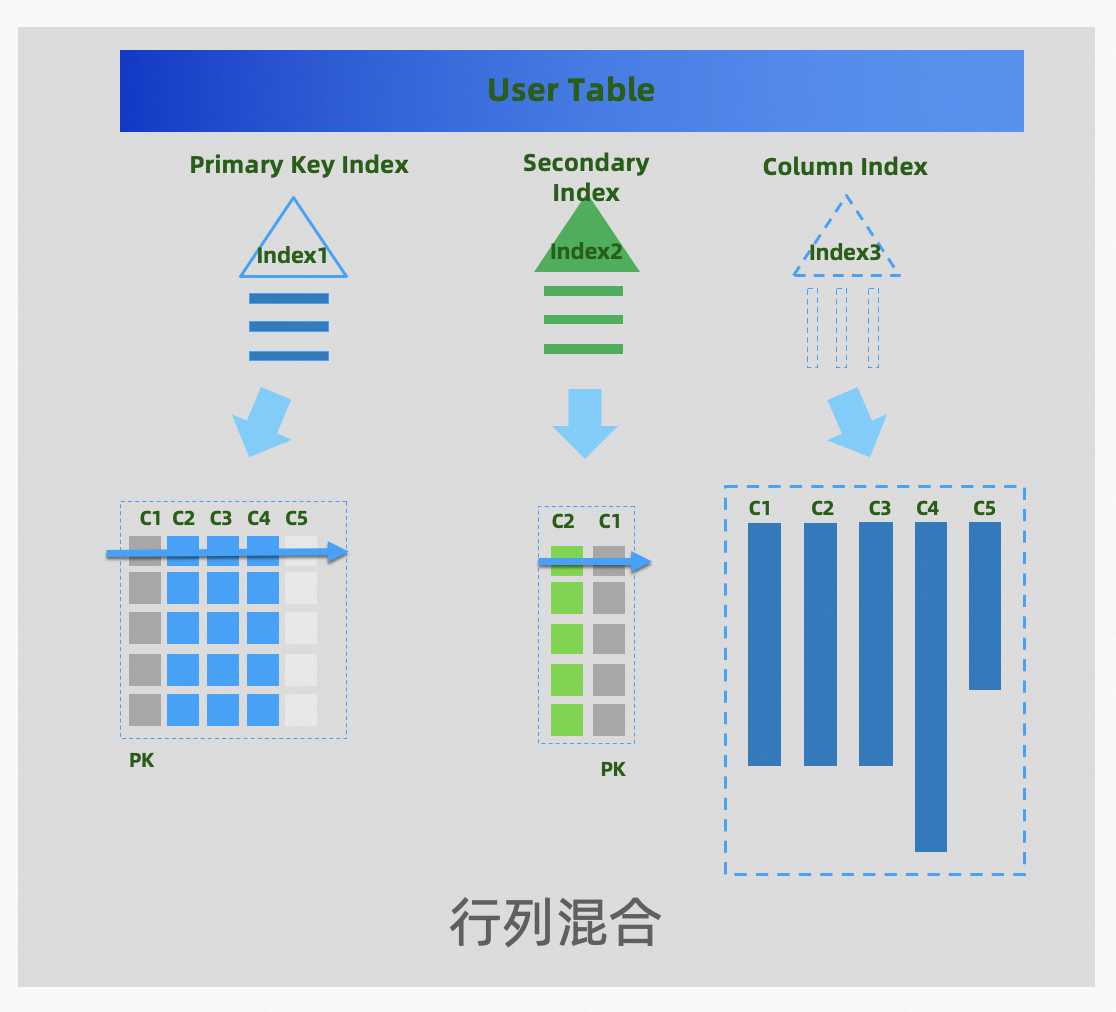
PolarDB-X 列存索引
相关语法
索引创建的语法:

列存索引创建的 DDL 语法
-
CLUSTERED COLUMNAR:关键字,用于指定添加的索引类型为 CCI。
-
索引名:索引表的名称,用于在 SQL 语句中指定该索引。
-
排序键:索引的排序键,即数据在索引文件中按照该列有序存储。
-
索引分区子句:索引的分区算法,与 CREATE TABLE 中分区子句的语法一致。
实际例子:
# 先创建表
CREATE TABLE t_order (
`id` bigint(11) NOT NULL AUTO_INCREMENT,
`order_id` varchar(20) DEFAULT NULL,
`buyer_id` varchar(20) DEFAULT NULL,
`seller_id` varchar(20) DEFAULT NULL,
`order_snapshot` longtext DEFAULT NULL,
`order_detail` longtext DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `l_i_order` (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 partition by hash(`order_id`) partitions 16;
# 再创建列存索引
CREATE CLUSTERED COLUMNAR INDEX `cc_i_seller` ON t_order (`seller_id`) partition by hash(`order_id`) partitions 16;
-
主表:"t_order" 是分区表,分区的拆分方式为按照 "order_id" 列进行哈希。
-
列存索引:"cc_i_seller" 按照 "seller_id" 列进行排序,按照 "order_id" 列进行哈希。
-
索引定义子句:CLUSTERED COLUMNAR INDEX cc_i_seller ON t_order (seller_id) partition by hash (order_id) partitions 16。
原理简介
列存索引的数据结构:
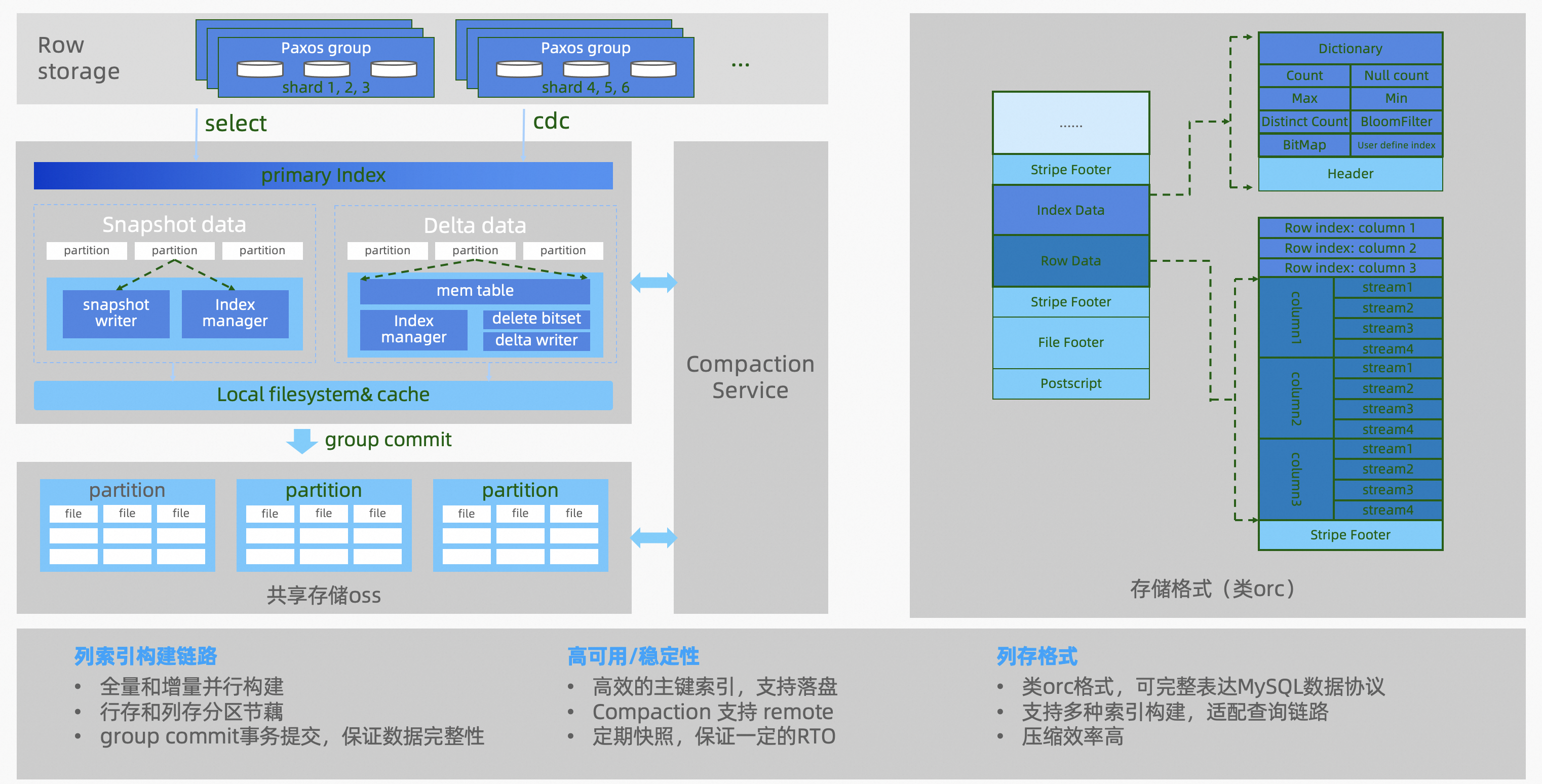
列存数据结构
列存索引是由列存引擎(Columnar)节点来构造的,数据结构基于 Delta+Main (类 LSM 结构) 二层模型,实时更新采用了标记删除的技术 (update 转化为 delete 标记 + insert),确保了行存和列存之间实现低延时的数据同步,可以保证秒级的实时更新。数据实时写入到 MemTable,在一个 group commit 的周期内,会将数据存储到一个本地 csv 文件,并追加到 OSS 上对应 csv 文件的尾部,这个文件称为 delta 文件。OSS 对象存储上的.csv 文件不会长期存在,而是由 compaction 线程不定期地转换成.orc 文件。
列存索引的数据流转:
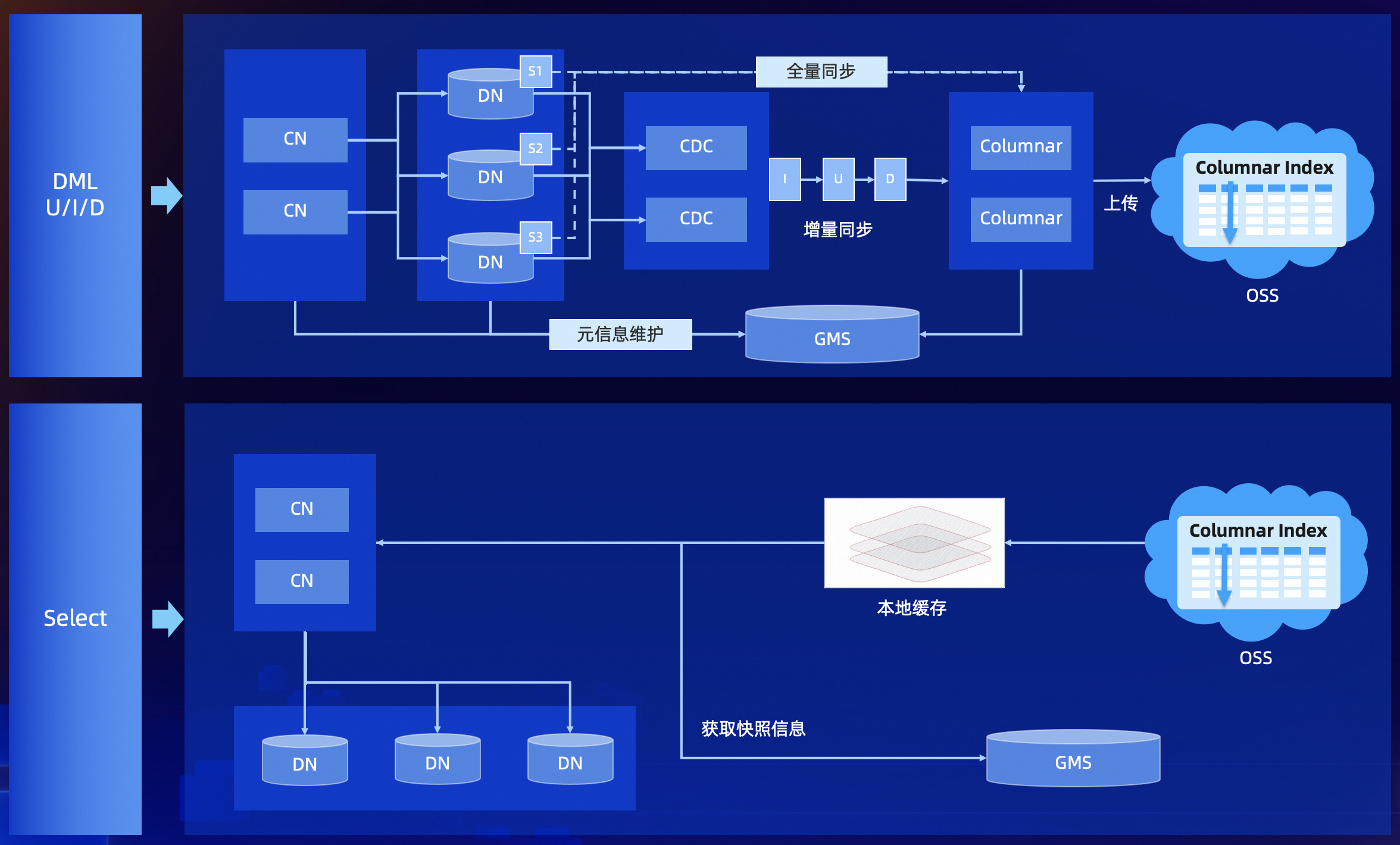
数据流转
列存索引,构建流程:
-
数据通过 CN 写入到 DN(正常的行存数据写入)
-
CDC 事务日志,提供实时提取逻辑 binlog(获取事务日志)
-
Columnar 实时消费 snapshot 数据和 cdc 增量 binlog 流,构建列存索引(异步实现行转列)
列存索引,查询流程:
-
CN 节点,基于一套 SQL 引擎提供了统一入口
-
CN 从 GMS 获取当前最新的 TSO (事务时间戳)
-
CN 基于 TSO 获取当前列存索引的快照信息(GMS 中存储了列存索引的元数据)
-
从 DN 或者 OSS 扫描数据,拉到 CN 做计算(行列混合计算)
tips. 更多列存引擎相关的技术原理文章,后续会逐步发布,欢迎大家持续关注。
性能体验
测试集:TPC-H 100GB 硬件环境:
机器用途
机型
规格
压力机
ecs.hfg7.6xlarge
24c96g
数据库机器
ecs.i4.8xlarge * 3
32c256g + 7TB 的存储,单价:7452 元 / 月
按照正常导入 TPC-H 100GB 数据后,执行 SQL 创建列存索引:
create clustered columnar index `nation_col_index` on nation(`n_nationkey`) partition by hash(`n_nationkey`) partitions 1;
create clustered columnar index `region_col_index` on region(`r_regionkey`) partition by hash(`r_regionkey`) partitions 1;
create clustered columnar index `customer_col_index` on customer(`c_custkey`) partition by hash(`c_custkey`) partitions 96;
create clustered columnar index `part_col_index` on part(`p_size`) partition by hash(`p_partkey`) partitions 96;
create clustered columnar index `partsupp_col_index` on partsupp(`ps_partkey`) partition by hash(`ps_partkey`) partitions 96;
create clustered columnar index `supplier_col_index` on supplier(`s_suppkey`) partition by hash(`s_suppkey`) partitions 96;
create clustered columnar index `orders_col_index` on orders(`o_orderdate`,`o_orderkey`) partition by hash(`o_orderkey`) partitions 96;
create clustered columnar index `lineitem_col_index` on lineitem(`l_shipdate`,`l_orderkey`) partition by hash(`l_orderkey`) partitions 96;
场景 1:单表聚合场景 (count 、 groupby)
场景
列存 (单位秒)
行存 (单位秒)
性能提升
tpch-Q1
2.98
105.95
35.5 倍
select count(*) from lineitem
0.52
19.85
38.1 倍
tpch-Q1 的行存和列存的效果对比图:
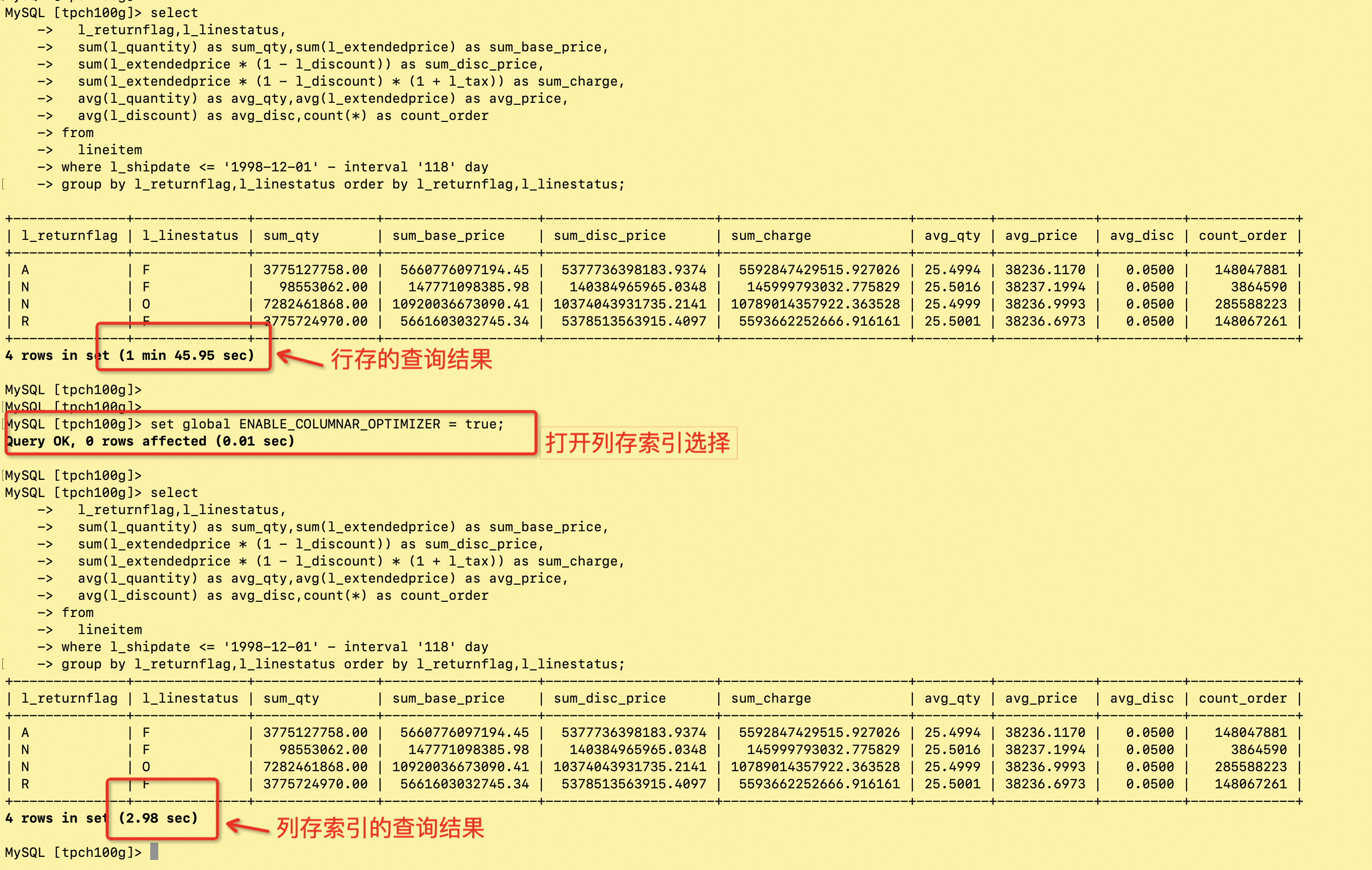
tpch-Q1
select count 的行存和列存的效果对比图:

count 查询
场景 2:TPC-H 22 条 query
基于列存索引的性能白皮书,开源版本可以参考:TPC-H 测试报告
TPC-H 100GB,22 条 query 总计 25.76 秒
详细数据如下:
查询语句
耗时(单位秒)
Q1
2.59
Q2
0.80
Q3
0.82
Q4
0.52
Q5
1.40
Q6
0.13
Q7
1.33
Q8
1.15
Q9
3.39
Q10
1.71
Q11
0.53
Q12
0.38
Q13
1.81
Q14
0.41
Q15
0.46
Q16
0.59
Q17
0.32
Q18
3.10
Q19
0.88
Q20
0.81
Q21
1.84
Q22
0.79
Total
25.76 秒
02 兼容 MySQL 8.0.32
PolarDB-X V2.3 版本,推出了集中式和分布式一体化架构(简称集分一体),在 2023 年 10 月公共云和开源同时新增集中式形态,将分布式中的 DN 多副本单独提供服务,支持 Paxos 多副本、lizard 分布式事务引擎,可以 100% 兼容 MySQL。 所谓集分一体化,就是兼具分布式数据库的扩展性和集中式数据库的功能和单机性能,两种形态可以无缝切换。在集分一体化数据库中,数据节点被独立出来作为集中式形态,完全兼容单机数据库形态。当业务增长到需要分布式扩展的时候,架构会原地升级成分布式形态,分布式组件无缝对接到原有的数据节点上进行扩展,不需要数据迁移,也不需要应用侧做改造。
回顾下 MySQL 8.0 的官方开源,8.0.11 版本在 2018 年正式 GA,历经 5 年左右的不断演进,修复和优化了众多稳定性和安全相关的问题,2023 年后的 8.0.3x 版本后逐步进入稳态。 PolarDB-X 在 V2.4 版本,跟进 MySQL 8.0 的官方演进,分布式的 DN 多副本中全面兼容 MySQL 8.0.32,快速继承了官方 MySQL 的众多代码优化:
-
更好用的 DDL 能力,比如:Instant DDL(加列、减列)、Parallel DDL(并行索引创建)
-
更完整的 SQL 执行能力,比如:Hash Join、窗口函数等
标准版架构
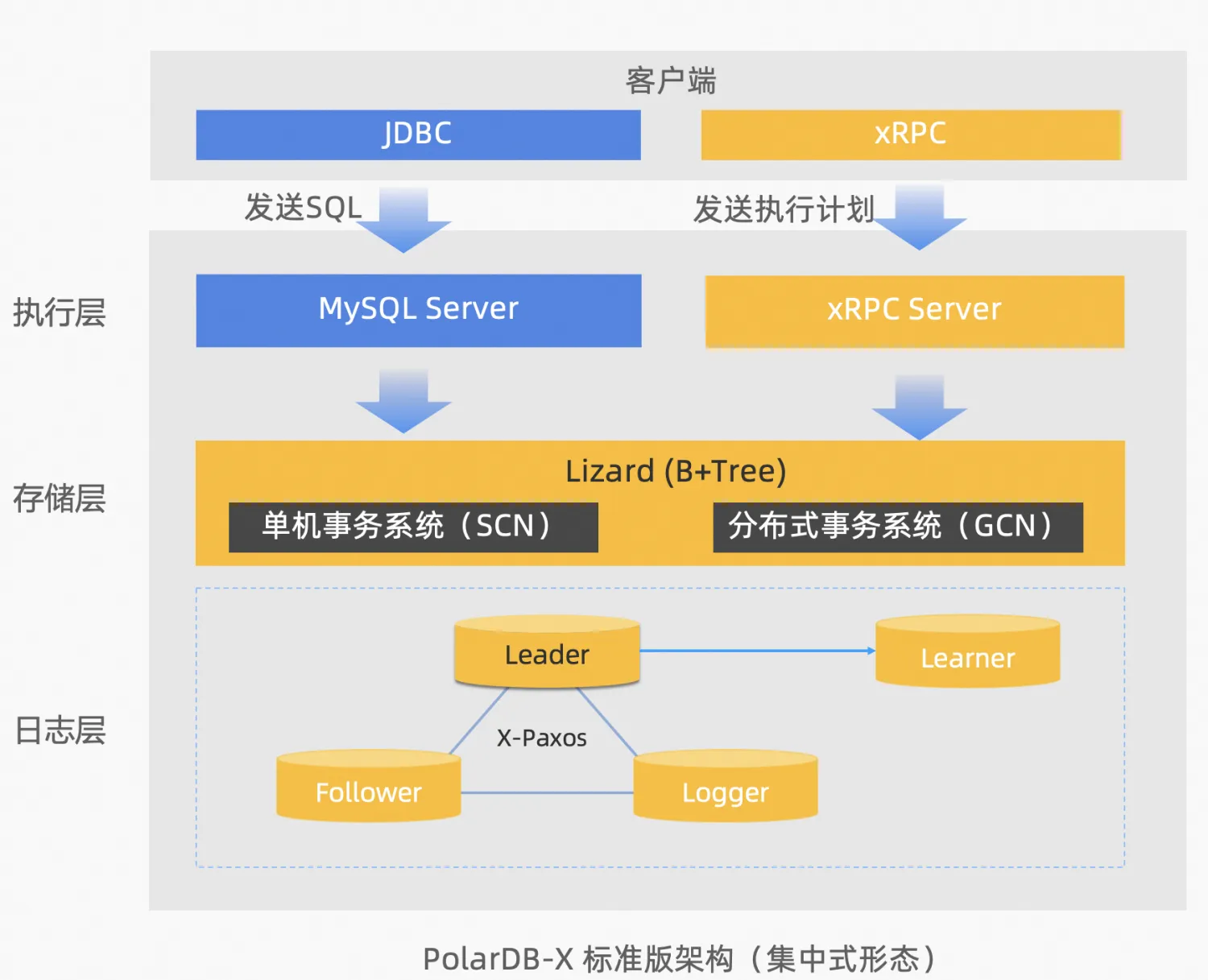
PolarDB-X 标准版,采用分层架构:
-
日志层:采用 Paxos 的多数派复制协议,基于 Paxos consensus 协议日志完全兼容 MySQL binlog 格式。相比于开源 MySQL 主备复制协议(基于 binlog 的异步或半同步),PolarDB-X 标准版可以金融级容灾能力,满足机房级故障时,不丢任何数据,简称 RPO=0。
-
存储层:自研 Lizard 事务系统,对接日志层,可以替换传统 MySQL InnoDB 的单机事务系统,分别设计了 SCN 单机事务系统和 GCN 分布式事务系统来解决这些弊端,可以满足集中式和分布式一体化的事务优化,同时 PolarDB-X 标准版基于 SCN 单机事务系统可以提供完全兼容 MySQL 的事务隔离级别。
-
执行层:类似于 MySQL 的 Server 层,自研 xRPC Server 可以对接 PolarDB-X 企业版的分布式查询。同时为完全兼容 MySQL,也提供兼容 MySQL Server 的 SQL 执行能力,对接存储层的事务系统来提供数据操作。
性能体验
硬件环境:
机器用途
机型
规格
压力机
ecs.hfg7.6xlarge
24c96g
数据库机器
ecs.i4.8xlarge * 3
32c256g + 7TB 的存储,单价:7452 元 / 月
TPCC 场景:对比开源 MySQL(采用相同的主机硬件部署)
场景
并发数
MySQL 8.0.34
主备异步复制
PolarDB-X 标准版 8.0.32
Paxos 多数派
性能提升
TPCC 1000 仓
300 并发
170882.38 tpmC
236036.8 tpmC
↑38%
03 全球数据库 GDN
数据库容灾架构设计是确保企业关键数据安全和业务连续性的核心。随着数据成为企业运营的命脉,任何数据丢失或服务中断都可能导致重大的财务损失。在规划容灾架构时,企业需要考虑数据的恢复时间目标(RTO)和数据恢复点目标(RPO),以及相关的成本和技术实现的复杂性。
03 全球数据库 GDN
数据库容灾架构设计是确保企业关键数据安全和业务连续性的核心。随着数据成为企业运营的命脉,任何数据丢失或服务中断都可能导致重大的财务损失。在规划容灾架构时,企业需要考虑数据的恢复时间目标(RTO)和数据恢复点目标(RPO),以及相关的成本和技术实现的复杂性。
常见容灾架构
异地多活,主要指跨地域的容灾能力,可以同时在多地域提供读写能力。金融行业下典型的两地三中心架构,更多的是提供异地容灾,日常情况下异地并不会直接提供写流量。但随着数字化形式的发展,越来越多的行业都面临着容灾需求。比如,运营商、互联网、游戏等行业,都对异地多活的容灾架构有比较强的诉求。 目前数据库业界常见的容灾架构:
-
同城 3 机房,一般是单地域多机房,无法满足多地域多活的诉求
-
两地三中心,分为主地域和异地灾备地域,流量主要在主地域,异地主要承担灾备容灾,异地机房日常不提供多活服务。
-
三地五中心,基于 Paxos/Raft 的多地域复制的架构
-
Geo-Partitioning,基于地域属性的 partition 分区架构,提供按用户地域属性的就近读写能力
-
Global Database,构建全球多活的架构,写发生在中心,各自地域提供就近读的能力
总结一下容灾架构的优劣势:
容灾架构
容灾范围
最少机房要求
数据复制
优缺点
同城 3 机房
单机房级别
3 机房
同步
比较通用,业务平均 RT 增加 1ms 左右
两地三中心
机房、地域
3 机房 + 2 地域
同步
比较通用,业务平均 RT 增加 1ms 左右
三地五中心
机房、地域
5 机房 + 3 地域
同步
机房建设成本比较高,业务平均 RT 会增加 5~10ms 左右(地域之间的物理距离)
Geo-Partitioning
机房、地域
3 机房 + 3 地域
同步
业务有适配成本(表分区增加地域属性),业务平均 RT 增加 1ms 左右
Global Database
机房、地域
2 机房 + 2 地域
异步
比较通用,业务就近读 + 远程转发写,适合异地读多写少的容灾场景
PolarDB-X 的容灾能力
PolarDB-X 采用数据多副本架构(比如 3 副本、5 副本),为了保证副本间的强一致性(RPO=0),采用 Paxos 的多数派复制协议,每次写入都要获得超过半数节点的确认,即便其中 1 个节点宕机,集群也仍然能正常提供服务。Paxos 算法能够保证副本间的强一致性,彻底解决副本不一致问题。
PolarDB-X V2.4 版本以前,主要提供的容灾形态:
-
单机房(3 副本),能够防范少数派 1 个节点的故障
-
同城 3 机房(3 副本),能够防范单机房故障
-
两地三中心(5 副本),能够防范城市级的故障
阿里集团的淘宝电商业务,在 2017 年左右开始建设异地多活的架构,构建了三地多中心的多活能力,因此在 PolarDB-X V2.4 我们推出了异地多活的容灾架构,我们称之为全球数据库(Global Database Network,简称 GDN)。 PolarDB-X GDN 是由分布在同一个国家内多个地域的多个 PolarDB-X 集群组成的网络,类似于传统 MySQL 跨地域的容灾(比如,两个地域的数据库采用单向复制、双向复制 , 或者多个地域组成一个中心 + 单元的双向复制等)。
常见的业务场景:
-
基于 GDN 的异地容灾
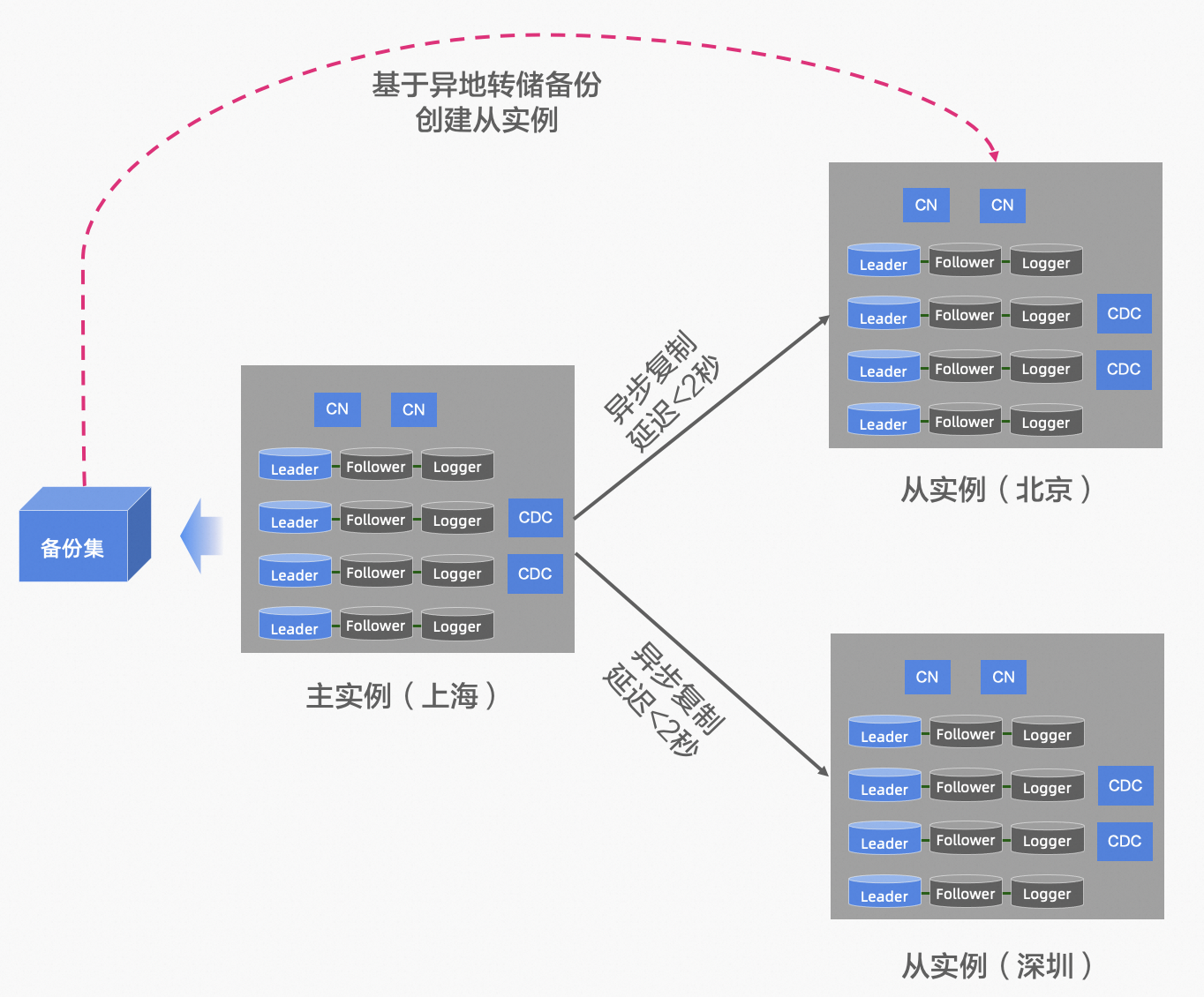
异地容灾
业务默认的流量,读写都集中在中心的主实例,异地的从实例作为灾备节点,提供就近读的服务能力 PolarDB-X 主实例 和 从实例,采用双向复制的能力,复制延迟小于 2 秒,通过备份集的异地备份可以快速创建一个异地从实例。 当 PolarDB-X 中心的主实例出现地域级别的故障时,可以手动进行容灾切换,将读写流量切换到从实例
2. 基于 GDN 的异地多活
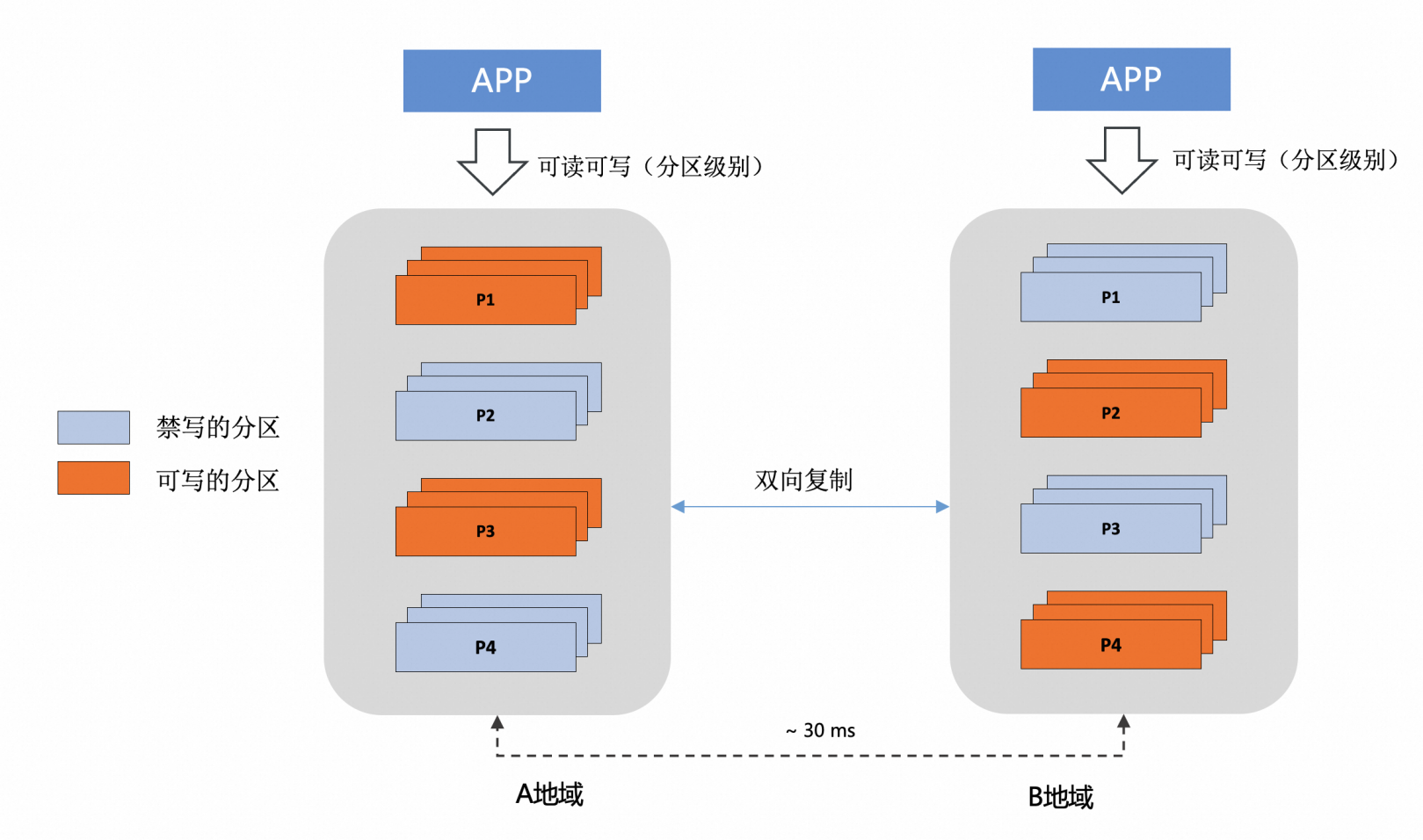
异地多活
业务适配单元化分片,按照数据分片的粒度的就近读和写,此时主实例和从实例,均承担读写流量 PolarDB-X 主实例 和 从实例,采用双向复制的能力,复制延迟小于 2 秒 当 PolarDB-X 中心的主实例出现地域级别的故障时,可以手动进行容灾切换,将读写流量切换到从实例
使用体验
PolarDB-X V2.4 版本,暂时仅提供基于 GDN 的异地容灾,支持跨地域的主备复制能力(异地多活形态会在后续版本中发布)。GDN 是一个产品形态,其基础和本质是数据复制,PolarDB-X 提供了高度兼容 MySQL Replica 的 SQL 命令来管理 GDN,简单来说,会配置 MySQL 主从同步,就能快速的配置 PolarDB-X GDN。
1. 可以使用兼容 MySQL 的 CHANGE MASTER 命令,搭建 GDN 复制链路
CHANGE MASTER TO option [, option] ... [ channel_option ]
option: {
MASTER_HOST = 'host_name'
| MASTER_USER = 'user_name'
| MASTER_PASSWORD = 'password'
| MASTER_PORT = port_num
| MASTER_LOG_FILE = 'source_log_name'
| MASTER_LOG_POS = source_log_pos
| MASTER_LOG_TIME_SECOND = source_log_time
| SOURCE_HOST_TYPE = {RDS|POLARDBX|MYSQL}
| STREAM_GROUP = 'stream_group_name'
| WRITE_SERVER_ID = write_server_id
| TRIGGER_AUTO_POSITION = {FALSE|TRUE}
| WRITE_TYPE = {SPLIT|SERIAL|TRANSACTION}
| MODE = {INCREMENTAL|IMAGE}
| CONFLICT_STRATEGY = {OVERWRITE|INTERRUPT|IGNORE|DIRECT_OVERWRITE}
| IGNORE_SERVER_IDS = (server_id_list)
}
channel_option:
FOR CHANNEL channel
server_id_list:
[server_id [, server_id] ... ]
2. 可以使用兼容 MySQL 的 SHOW SLAVE STATUS 命令,监控 GDN 复制链路
SHOW SLAVE STATUS [ channel_option ]
channel_option:
FOR CHANNEL channel
3. 可以使用兼容 MySQL 的 CHANGE REPLICATION FILTER 命令,配置数据复制策略
CHANGE REPLICATION FILTER option [, option] ... [ channel_option ]
option: {
REPLICATE_DO_DB = (do_db_list)
| REPLICATE_IGNORE_DB = (ignore_db_list)
| REPLICATE_DO_TABLE = (do_table_list)
| REPLICATE_IGNORE_TABLE = (ignore_table_list)
| REPLICATE_WILD_DO_TABLE = (wild_do_table_list)
| REPLICATE_WILD_IGNORE_TABLE = (wile_ignore_table_list)
| REPLICATE_SKIP_TSO = 'tso_num'
| REPLICATE_SKIP_UNTIL_TSO = 'tso_num'
| REPLICATE_ENABLE_DDL = {TRUE|FALSE}
}
channel_option:
FOR CHANNEL channel
4. 可以使用兼容 MySQL 的 START SLAVE 和 STOP SLAVE 命令,启动和停止 GDN 复制链路
START SLAVE [ channel_option ]
channel_option:
FOR CHANNEL channel
STOP SLAVE [ channel_option ]
channel_option:
FOR CHANNEL channel
5. 可以使用兼容 MySQL 的 RESET SLAVE,删除 GDN 复制链路
RESET SLAVE ALL [ channel_option ]
channel_option:
FOR CHANNEL channel
拥抱生态,提供兼容 MySQL 的使用方式,可以大大降低使用门槛,但 PolarDB-X 也需要做最好的自己,我们在兼容 MySQL 的基础上,还提供了很多定制化的功能特性。
功能特性
功能描述
一键创建多条 GDN 复制链路
在 CHANGE MASTER 语句中,指定 STREAM_GROUP 选项,即 PolarDB-X 多流 binlog 集群的流组名称,可以一键创建多条复制链路 (具体取决于 binlog 流的数量),带来极简的使用体验。什么是多流 binlog?参见 binlog 日志服务
基于时间戳的复制链路搭建
在 CHANGE MASTER 语句中,指定 MASTER_LOG_TIME_SECOND 选项,可以基于指定的时间点,来构建复制链路,相比通过指定 file name 和 file positiion 的方式,更加灵活。
比如在搭建 GDN 时,一般的流程为先通过全量复制或备份恢复的方式准备好从实例,然后启动增量复制链路,通过指定 MASTER_LOG_TIME_SECOND 显然更加简便。尤其是当对接的是 PolarDB-X 多流 binlog 时,为每条链路分别指定 file name 和 file position,相当繁琐,而结合 STREAM_GROUP 和 MASTER_LOG_TIME_SECOND,则相当简便。
多种模式的 DML 复制策略
在 CHANGE MASTER 语句中,指定 WRITE_TYPE 选项,可以指定 DML 的复制策略,可选策略如下
- TRANSACTION:严格按照 binlog 中的事务单元,进行原样回放,适用于对数据一致性、事务完整性有高要求的场景
- SERIAL:打破 binlog 中的事务单元,重新组织事务单元,进行串行回放,适用于对事务完整性要求不高,但仍需要串行复制的场景
- SPLIT:打破 binlog 中的事务单元,依赖内置的数据冲突检测算法,进行全并行回放,适用于高吞吐、高并发的场景
全量增量一体化复制搭建
谁说 CHANGE MASTER 只能创建增量同步?在 CHANGE MASTER 语句中,指定 MODE 选项,可以指定链路的搭建模式
- INCREMENTAL: 直接创建增量复制链路
- IMAGE: 先完成全量复制,再基于全量复制开始的时间点,启动增量复制链路
原生的轻量级双向复制能力
在 CHANGE MASTER 语句中,组合使用 WRITE_SERVER_ID 和 IGNORE_SERVER_IDS 选项,可配置基于 server_id 的防流量回环双向复制链路,相比需要额外引入事务表的方案,不仅使用简单,而且性能无损。
原生的轻量级双向复制能力,举例来说:
-
PolarDB-X 实例 R1 的 server_id 为 100
-
PolarDB-X 实例 R2 的 server_id 为 200
-
构建 R1 到 R2 的复制链路时,在 R2 上执行 CHANGE MASTER 并指定 WRITE_SERVER_ID = 300、IGNORE_SERVER_IDS = 400
-
构建 R2 到 R1 的复制链路时,在 R1 上执行 CHANGE MASTER 并指定 WRITE_SERVER_ID = 400、IGNORE_SERVER_IDS = 300
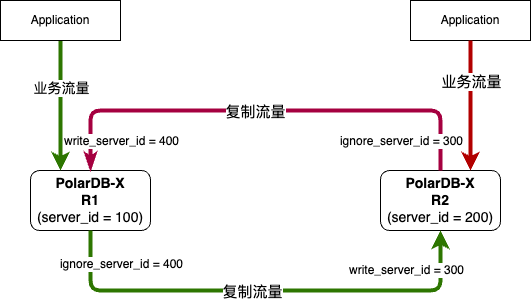
GDN 场景下,保证主从实例之间的数据一致性是最为关键的因素,提供便捷的数据校验能力则显得尤为关键,V2.4 版本不仅提供了完善的主从复制能力,还提供了原生的数据校验能力,在从实例上执行相关 SQL 命令,即可实现在线数据校验。V2.4 版本暂时只支持直接校验模式 (校验结果存在误报的可能),基于 sync point 的快照校验能力 (校验结果不会出现误报),会在下个版本进行开源。
#开启校验
CHECK REPLICA TABLE {`test_db`.`test_tb`} | {`test_db`}
[MODE='direct' | 'tso']
FOR CHANNEL xxx;
#查看校验进度
CHECK REPLICA TABLE [`test_db`.`test_tb`] | [`test_db`] SHOW PROGRESS;
#查看差异数据
CHECK REPLICA TABLE {`test_db`.`test_tb`} | {`test_db`} SHOW DIFFERENCE;
此外,数据的一致性不仅体现在数据内容的一致性上,还体现在 schema 的一致性上,只有二者都保证一致,才是真正的一致,比如即使丢失一个索引,当发生主从切换后,也可能引发严重的性能问题。PolarDB-X GDN 支持各种类型的 DDL 复制,基本覆盖了其所支持的全部 DDL 类型,尤其是针对 PolarDB-X 特有 schema 的 DDL 操作,更是实现了充分的支持,典型的例子如:sequenc、tablegroup 等 DDL 的同步。
除了数据一致性,考量 GDN 能力的另外两个核心指标为 RPO 和 RTO,复制延迟越低则 RPO 越小,同时也间接影响了 RTO,本次 V2.4 版本提供了 RPO <= 2s、RTO 分钟级的恢复能力,以 Sysbench 和 TPCC 场景为例,GDN 单条复制链路在不同网络延迟条件 (0.1ms ~ 20ms 之间) 下可以达到的最大 RPS 分布在 2w/s 到 5w/s 之间。当业务流量未触达单条复制链路的 RPS 瓶颈时,用单流 binlog + GDN 的组合来实现容灾即可,而当触达瓶颈后,则可以选择多流 binlog + GDN 的组合来提升扩展性,理论上只要网络带宽没有瓶颈,不管多大的业务流量,都可实现线性扩展,PolarDB-X GDN 具备高度的灵活性和扩展性,以及在此基础之上的高性能表现。
04 开源生态完善
快速运维部署能力
PolarDB-X 支持多种形态的快速部署能力,可以结合各自需求尽心选择
部署方式
说明
安装工具的快速安装
依赖项
RPM 包
零组件依赖,手工快速部署
RPM 下载、RPM 安装
rpm
PXD
自研快速部署工具,通过 yaml 文件配置快速部署
PXD 安装
python3、docker
K8S
基于 k8s operator 的快速部署工具
K8S 安装
k8s、docker
polardbx-operator 是基于 k8s operator 架构,正式发布 1.6.0 版本,提供了 polardb-x 数据库的部署和运维能力,生产环境优先推荐,可参考 polardbx-operator 运维指南。
polardbx-operator 1.6.0 新版本,围绕数据安全、HTAP、可观测性等方面完善集中式与分布式形态的运维能力,支持标准版的备份恢复,透明加密(TDE),列存只读(HTAP)、一键诊断工具、CPU 绑核等功能。同时兼容了 8.0.32 新版本内核,优化了备份恢复功能的稳定性。详见:Release Note。
pxd 是基于开源用户物理机裸机部署的需求,提供快速部署和运维的能力,可参考 pxd 运维。
发布 pxd 0.7 新版本,围绕版本升级、备库重搭,以及兼容 8.0.32 新版本内核。
标准版生态
V2.3 版本开始,为方便用户进行快速体验,提供 rpm 包的下载和部署能力,可以一键完成标准版的安装,参考链接:
-
基于 rpm 包部署 polardbx - 标准版 (https://doc.polardbx.com/zh/deployment/topics/deploy-by-rpm-std.html)
-
【PolarDB-X 开源】基于 Paxos 的 MySQL 三副本(https://zhuanlan.zhihu.com/p/669301230)
PolarDB-X 标准版,基于 Paxos 协议实现多副本,基于 Paxos 的选举心跳机制,MySQL 自动完成节点探活和 HA 切换,可以替换传统 MySQL 的 HA 机制。如果 PolarDB-X 替换 MySQL,作为生产部署使用,需要解决生产链路的 HA 切换适配问题,开发者们也有自己的一些尝试(比如 HAProxy 或 自定义 proxy)。 在 V2.4 版本,我们正式适配了一款开源 Proxy 组件。
ProxySQL 作为一款成熟的 MySQL 中间件,能够无缝对接 MySQL 协议支持 PolarDB-X,并且支持故障切换,动态路由等高可用保障,为我们提供了一个既可用又好用的代理选项,更多信息可参考文档:使用开源 ProxySQL 构建 PolarDB-X 标准版高可用路由服务
(责任编辑:IT)
PolarDB 分布式版 (PolarDB for Xscale,以下简称 “PolarDB-X”) 是阿里云自主设计研发的高性能云原生分布式数据库产品,为用户提供高吞吐、大存储、低延时、易扩展和超高可用的云时代数据库服务。 架构简介PolarDB-X 采用 Shared-nothing 与存储分离计算架构进行设计,系统由 5 个核心组件组成。
PolarDB 分布式 架构图
开源地址:https://github.com/polardb/polardbx-sql 版本说明梳理下 PolarDB-X 开源脉络:
2024 年 4 月份,PolarDB-X 正式发布 2.4.0 版本,重点推出列存节点 Columnar,可以提供持久化列存索引(Clustered Columnar Index,CCI)。PolarDB-X 的行存表默认有主键索引和二级索引,列存索引是一份额外基于列式结构的二级索引(默认覆盖行存所有列),一张表可以同时具备行存和列存的数据,结合计算节点 CN 的向量化计算,可以满足分布式下的查询加速的诉求,实现 HTAP 一体化的体验和效果。 01 列存索引随着云原生技术的不断普及,以 Snowflake 为代表的新一代云原生数仓、以及数据库 HTAP 架构不断创新,可见在未来一段时间后行列混存 HTAP 会成为一个数据库的标配能力,需要在当前数据库列存设计中面相未来的低成本、易用性、高性能上有更多的思考 PolarDB-X 在 V2.4 版本正式发布列存引擎,提供列存索引的形态(Clustered Columnar Index,CCI),行存表默认有主键索引和二级索引,列存索引是一份额外基于列式结构的二级索引(覆盖行存所有列),一张表可以同时具备行存和列存的数据。
PolarDB-X 列存索引 相关语法索引创建的语法:
列存索引创建的 DDL 语法
实际例子: # 先创建表 CREATE TABLE t_order ( `id` bigint(11) NOT NULL AUTO_INCREMENT, `order_id` varchar(20) DEFAULT NULL, `buyer_id` varchar(20) DEFAULT NULL, `seller_id` varchar(20) DEFAULT NULL, `order_snapshot` longtext DEFAULT NULL, `order_detail` longtext DEFAULT NULL, PRIMARY KEY (`id`), KEY `l_i_order` (`order_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 partition by hash(`order_id`) partitions 16; # 再创建列存索引 CREATE CLUSTERED COLUMNAR INDEX `cc_i_seller` ON t_order (`seller_id`) partition by hash(`order_id`) partitions 16;
原理简介列存索引的数据结构:
列存数据结构 列存索引是由列存引擎(Columnar)节点来构造的,数据结构基于 Delta+Main (类 LSM 结构) 二层模型,实时更新采用了标记删除的技术 (update 转化为 delete 标记 + insert),确保了行存和列存之间实现低延时的数据同步,可以保证秒级的实时更新。数据实时写入到 MemTable,在一个 group commit 的周期内,会将数据存储到一个本地 csv 文件,并追加到 OSS 上对应 csv 文件的尾部,这个文件称为 delta 文件。OSS 对象存储上的.csv 文件不会长期存在,而是由 compaction 线程不定期地转换成.orc 文件。 列存索引的数据流转:
数据流转 列存索引,构建流程:
列存索引,查询流程:
tips. 更多列存引擎相关的技术原理文章,后续会逐步发布,欢迎大家持续关注。 性能体验测试集:TPC-H 100GB 硬件环境:
按照正常导入 TPC-H 100GB 数据后,执行 SQL 创建列存索引: create clustered columnar index `nation_col_index` on nation(`n_nationkey`) partition by hash(`n_nationkey`) partitions 1; create clustered columnar index `region_col_index` on region(`r_regionkey`) partition by hash(`r_regionkey`) partitions 1; create clustered columnar index `customer_col_index` on customer(`c_custkey`) partition by hash(`c_custkey`) partitions 96; create clustered columnar index `part_col_index` on part(`p_size`) partition by hash(`p_partkey`) partitions 96; create clustered columnar index `partsupp_col_index` on partsupp(`ps_partkey`) partition by hash(`ps_partkey`) partitions 96; create clustered columnar index `supplier_col_index` on supplier(`s_suppkey`) partition by hash(`s_suppkey`) partitions 96; create clustered columnar index `orders_col_index` on orders(`o_orderdate`,`o_orderkey`) partition by hash(`o_orderkey`) partitions 96; create clustered columnar index `lineitem_col_index` on lineitem(`l_shipdate`,`l_orderkey`) partition by hash(`l_orderkey`) partitions 96; 场景 1:单表聚合场景 (count 、 groupby)
tpch-Q1 的行存和列存的效果对比图:
tpch-Q1 select count 的行存和列存的效果对比图:
count 查询 场景 2:TPC-H 22 条 query 基于列存索引的性能白皮书,开源版本可以参考:TPC-H 测试报告 TPC-H 100GB,22 条 query 总计 25.76 秒 详细数据如下:
02 兼容 MySQL 8.0.32PolarDB-X V2.3 版本,推出了集中式和分布式一体化架构(简称集分一体),在 2023 年 10 月公共云和开源同时新增集中式形态,将分布式中的 DN 多副本单独提供服务,支持 Paxos 多副本、lizard 分布式事务引擎,可以 100% 兼容 MySQL。 所谓集分一体化,就是兼具分布式数据库的扩展性和集中式数据库的功能和单机性能,两种形态可以无缝切换。在集分一体化数据库中,数据节点被独立出来作为集中式形态,完全兼容单机数据库形态。当业务增长到需要分布式扩展的时候,架构会原地升级成分布式形态,分布式组件无缝对接到原有的数据节点上进行扩展,不需要数据迁移,也不需要应用侧做改造。 回顾下 MySQL 8.0 的官方开源,8.0.11 版本在 2018 年正式 GA,历经 5 年左右的不断演进,修复和优化了众多稳定性和安全相关的问题,2023 年后的 8.0.3x 版本后逐步进入稳态。 PolarDB-X 在 V2.4 版本,跟进 MySQL 8.0 的官方演进,分布式的 DN 多副本中全面兼容 MySQL 8.0.32,快速继承了官方 MySQL 的众多代码优化:
标准版架构
PolarDB-X 标准版,采用分层架构:
性能体验硬件环境:
TPCC 场景:对比开源 MySQL(采用相同的主机硬件部署)
03 全球数据库 GDN数据库容灾架构设计是确保企业关键数据安全和业务连续性的核心。随着数据成为企业运营的命脉,任何数据丢失或服务中断都可能导致重大的财务损失。在规划容灾架构时,企业需要考虑数据的恢复时间目标(RTO)和数据恢复点目标(RPO),以及相关的成本和技术实现的复杂性。 03 全球数据库 GDN数据库容灾架构设计是确保企业关键数据安全和业务连续性的核心。随着数据成为企业运营的命脉,任何数据丢失或服务中断都可能导致重大的财务损失。在规划容灾架构时,企业需要考虑数据的恢复时间目标(RTO)和数据恢复点目标(RPO),以及相关的成本和技术实现的复杂性。 常见容灾架构异地多活,主要指跨地域的容灾能力,可以同时在多地域提供读写能力。金融行业下典型的两地三中心架构,更多的是提供异地容灾,日常情况下异地并不会直接提供写流量。但随着数字化形式的发展,越来越多的行业都面临着容灾需求。比如,运营商、互联网、游戏等行业,都对异地多活的容灾架构有比较强的诉求。 目前数据库业界常见的容灾架构:
总结一下容灾架构的优劣势:
PolarDB-X 的容灾能力PolarDB-X 采用数据多副本架构(比如 3 副本、5 副本),为了保证副本间的强一致性(RPO=0),采用 Paxos 的多数派复制协议,每次写入都要获得超过半数节点的确认,即便其中 1 个节点宕机,集群也仍然能正常提供服务。Paxos 算法能够保证副本间的强一致性,彻底解决副本不一致问题。 PolarDB-X V2.4 版本以前,主要提供的容灾形态:
阿里集团的淘宝电商业务,在 2017 年左右开始建设异地多活的架构,构建了三地多中心的多活能力,因此在 PolarDB-X V2.4 我们推出了异地多活的容灾架构,我们称之为全球数据库(Global Database Network,简称 GDN)。 PolarDB-X GDN 是由分布在同一个国家内多个地域的多个 PolarDB-X 集群组成的网络,类似于传统 MySQL 跨地域的容灾(比如,两个地域的数据库采用单向复制、双向复制 , 或者多个地域组成一个中心 + 单元的双向复制等)。 常见的业务场景:
异地容灾 业务默认的流量,读写都集中在中心的主实例,异地的从实例作为灾备节点,提供就近读的服务能力 PolarDB-X 主实例 和 从实例,采用双向复制的能力,复制延迟小于 2 秒,通过备份集的异地备份可以快速创建一个异地从实例。 当 PolarDB-X 中心的主实例出现地域级别的故障时,可以手动进行容灾切换,将读写流量切换到从实例 2. 基于 GDN 的异地多活
异地多活 业务适配单元化分片,按照数据分片的粒度的就近读和写,此时主实例和从实例,均承担读写流量 PolarDB-X 主实例 和 从实例,采用双向复制的能力,复制延迟小于 2 秒 当 PolarDB-X 中心的主实例出现地域级别的故障时,可以手动进行容灾切换,将读写流量切换到从实例 使用体验PolarDB-X V2.4 版本,暂时仅提供基于 GDN 的异地容灾,支持跨地域的主备复制能力(异地多活形态会在后续版本中发布)。GDN 是一个产品形态,其基础和本质是数据复制,PolarDB-X 提供了高度兼容 MySQL Replica 的 SQL 命令来管理 GDN,简单来说,会配置 MySQL 主从同步,就能快速的配置 PolarDB-X GDN。 1. 可以使用兼容 MySQL 的 CHANGE MASTER 命令,搭建 GDN 复制链路
CHANGE MASTER TO option [, option] ... [ channel_option ]
option: {
MASTER_HOST = 'host_name'
| MASTER_USER = 'user_name'
| MASTER_PASSWORD = 'password'
| MASTER_PORT = port_num
| MASTER_LOG_FILE = 'source_log_name'
| MASTER_LOG_POS = source_log_pos
| MASTER_LOG_TIME_SECOND = source_log_time
| SOURCE_HOST_TYPE = {RDS|POLARDBX|MYSQL}
| STREAM_GROUP = 'stream_group_name'
| WRITE_SERVER_ID = write_server_id
| TRIGGER_AUTO_POSITION = {FALSE|TRUE}
| WRITE_TYPE = {SPLIT|SERIAL|TRANSACTION}
| MODE = {INCREMENTAL|IMAGE}
| CONFLICT_STRATEGY = {OVERWRITE|INTERRUPT|IGNORE|DIRECT_OVERWRITE}
| IGNORE_SERVER_IDS = (server_id_list)
}
channel_option:
FOR CHANNEL channel
server_id_list:
[server_id [, server_id] ... ]
2. 可以使用兼容 MySQL 的 SHOW SLAVE STATUS 命令,监控 GDN 复制链路
SHOW SLAVE STATUS [ channel_option ]
channel_option:
FOR CHANNEL channel
3. 可以使用兼容 MySQL 的 CHANGE REPLICATION FILTER 命令,配置数据复制策略
CHANGE REPLICATION FILTER option [, option] ... [ channel_option ]
option: {
REPLICATE_DO_DB = (do_db_list)
| REPLICATE_IGNORE_DB = (ignore_db_list)
| REPLICATE_DO_TABLE = (do_table_list)
| REPLICATE_IGNORE_TABLE = (ignore_table_list)
| REPLICATE_WILD_DO_TABLE = (wild_do_table_list)
| REPLICATE_WILD_IGNORE_TABLE = (wile_ignore_table_list)
| REPLICATE_SKIP_TSO = 'tso_num'
| REPLICATE_SKIP_UNTIL_TSO = 'tso_num'
| REPLICATE_ENABLE_DDL = {TRUE|FALSE}
}
channel_option:
FOR CHANNEL channel
4. 可以使用兼容 MySQL 的 START SLAVE 和 STOP SLAVE 命令,启动和停止 GDN 复制链路
START SLAVE [ channel_option ]
channel_option:
FOR CHANNEL channel
STOP SLAVE [ channel_option ]
channel_option:
FOR CHANNEL channel
5. 可以使用兼容 MySQL 的 RESET SLAVE,删除 GDN 复制链路
RESET SLAVE ALL [ channel_option ]
channel_option:
FOR CHANNEL channel
拥抱生态,提供兼容 MySQL 的使用方式,可以大大降低使用门槛,但 PolarDB-X 也需要做最好的自己,我们在兼容 MySQL 的基础上,还提供了很多定制化的功能特性。
原生的轻量级双向复制能力,举例来说:
GDN 场景下,保证主从实例之间的数据一致性是最为关键的因素,提供便捷的数据校验能力则显得尤为关键,V2.4 版本不仅提供了完善的主从复制能力,还提供了原生的数据校验能力,在从实例上执行相关 SQL 命令,即可实现在线数据校验。V2.4 版本暂时只支持直接校验模式 (校验结果存在误报的可能),基于 sync point 的快照校验能力 (校验结果不会出现误报),会在下个版本进行开源。
#开启校验
CHECK REPLICA TABLE {`test_db`.`test_tb`} | {`test_db`}
[MODE='direct' | 'tso']
FOR CHANNEL xxx;
#查看校验进度
CHECK REPLICA TABLE [`test_db`.`test_tb`] | [`test_db`] SHOW PROGRESS;
#查看差异数据
CHECK REPLICA TABLE {`test_db`.`test_tb`} | {`test_db`} SHOW DIFFERENCE;
此外,数据的一致性不仅体现在数据内容的一致性上,还体现在 schema 的一致性上,只有二者都保证一致,才是真正的一致,比如即使丢失一个索引,当发生主从切换后,也可能引发严重的性能问题。PolarDB-X GDN 支持各种类型的 DDL 复制,基本覆盖了其所支持的全部 DDL 类型,尤其是针对 PolarDB-X 特有 schema 的 DDL 操作,更是实现了充分的支持,典型的例子如:sequenc、tablegroup 等 DDL 的同步。 除了数据一致性,考量 GDN 能力的另外两个核心指标为 RPO 和 RTO,复制延迟越低则 RPO 越小,同时也间接影响了 RTO,本次 V2.4 版本提供了 RPO <= 2s、RTO 分钟级的恢复能力,以 Sysbench 和 TPCC 场景为例,GDN 单条复制链路在不同网络延迟条件 (0.1ms ~ 20ms 之间) 下可以达到的最大 RPS 分布在 2w/s 到 5w/s 之间。当业务流量未触达单条复制链路的 RPS 瓶颈时,用单流 binlog + GDN 的组合来实现容灾即可,而当触达瓶颈后,则可以选择多流 binlog + GDN 的组合来提升扩展性,理论上只要网络带宽没有瓶颈,不管多大的业务流量,都可实现线性扩展,PolarDB-X GDN 具备高度的灵活性和扩展性,以及在此基础之上的高性能表现。 04 开源生态完善快速运维部署能力PolarDB-X 支持多种形态的快速部署能力,可以结合各自需求尽心选择
polardbx-operator 是基于 k8s operator 架构,正式发布 1.6.0 版本,提供了 polardb-x 数据库的部署和运维能力,生产环境优先推荐,可参考 polardbx-operator 运维指南。 polardbx-operator 1.6.0 新版本,围绕数据安全、HTAP、可观测性等方面完善集中式与分布式形态的运维能力,支持标准版的备份恢复,透明加密(TDE),列存只读(HTAP)、一键诊断工具、CPU 绑核等功能。同时兼容了 8.0.32 新版本内核,优化了备份恢复功能的稳定性。详见:Release Note。 pxd 是基于开源用户物理机裸机部署的需求,提供快速部署和运维的能力,可参考 pxd 运维。 发布 pxd 0.7 新版本,围绕版本升级、备库重搭,以及兼容 8.0.32 新版本内核。 标准版生态V2.3 版本开始,为方便用户进行快速体验,提供 rpm 包的下载和部署能力,可以一键完成标准版的安装,参考链接:
PolarDB-X 标准版,基于 Paxos 协议实现多副本,基于 Paxos 的选举心跳机制,MySQL 自动完成节点探活和 HA 切换,可以替换传统 MySQL 的 HA 机制。如果 PolarDB-X 替换 MySQL,作为生产部署使用,需要解决生产链路的 HA 切换适配问题,开发者们也有自己的一些尝试(比如 HAProxy 或 自定义 proxy)。 在 V2.4 版本,我们正式适配了一款开源 Proxy 组件。
ProxySQL 作为一款成熟的 MySQL 中间件,能够无缝对接 MySQL 协议支持 PolarDB-X,并且支持故障切换,动态路由等高可用保障,为我们提供了一个既可用又好用的代理选项,更多信息可参考文档:使用开源 ProxySQL 构建 PolarDB-X 标准版高可用路由服务 |