Apache SeaTunnel 2.3.8 АцБОе§ЪНЗЂВМЃЁ
ЪБМф:2024-10-16 10:11 РДдД:linux.it.net.cn зїеп:IT
Apache SeaTunnel 2.3.8 АцБОЯжвбе§ЪНЗЂВМЃЁДЫДЮАцБОКѓЃЌгУЛЇНЋПЩвдЪЙгУЦкД§вбОУЕФ Docker ОЕЯёЃЌЛЙПЩвдЬхбщ Job МЖБ№ШежОЙІФмЃЌвдМАЦфЫћИќаТгХЛЏЕФЙІФмЁЃБОЮФНЋЯъЯИНщЩм Apache SeaTunnel 2.3.8 АцБОжаЕФЙиМќИќаТФкШнЃЌЛЖгИќЖрПЊЗЂепКЭгУЛЇВЮгыЕНЮвУЧЕФПЊдДЩчЧјжаРДЁЃ
-
2.3.8 АцБОЯТдиЃК https://seatunnel.apache.org/download/
-
Release NoteЃКhttps://github.com/apache/seatunnel/releases/tag/2.3.8
жиЕуИќаТ
Job МЖБ№ШежО
ДЫДЮИќаТжаЃЌЮвУЧЖдШежОЙІФмНјааСЫгХЛЏЃЌдкжЎЧАЕФАцБОжаЃЌЖрИіШЮЮёЕФШежОЖМдквЛИіЮФМўжаДђгЁЃЌЕБЭЌЪБдЫааЖрИіШЮЮёКѓЃЌЖрИіШЮЮёЕФШежОНЛжЏдквЛЦ№ЃЌВЛБугкХХВщЮЪЬтЁЃ
ДЫДЮИќаТжЇГжСНжжЗНЪНЕФХфжУЃЌвдЪЕЯжИќМгИпаЇЕФШежОВщбЏЁЃ
ЕквЛжжЪЧдкУПааШежОжаЬэМг JobIdЃЌДгЖјПЩвдЙ§ТЫВщбЏГіУПИіШежОЕЅЖРЕФШежОЃЛ
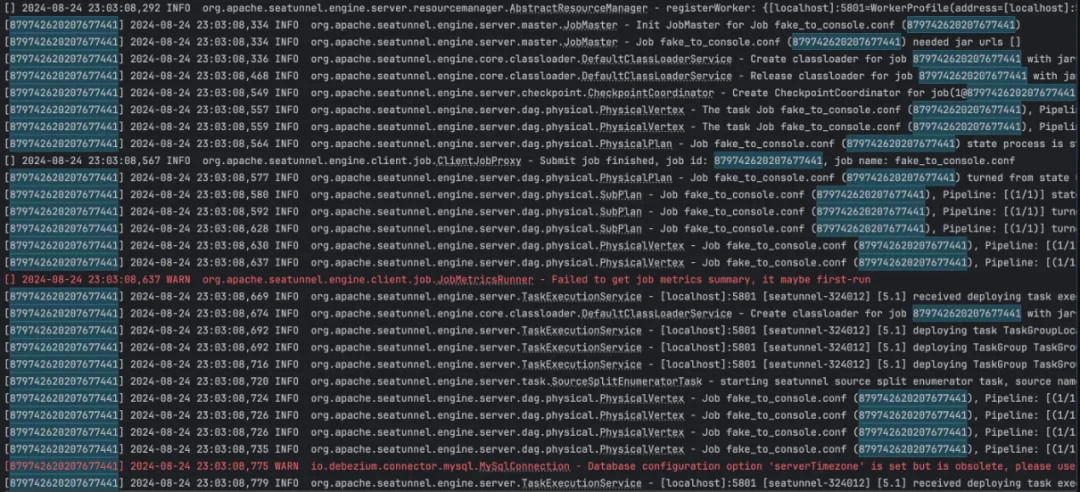
ЕкЖўжжЪЧИљОн JobId В№ЗжЮФМўЃЌжЛашаоИФШежОХфжУЮФМўЃЌОЭПЩвдУПвЛИі JobId ДђгЁЕЅЖРЕФШежОЮФМўЁЃ
аТді Docker ОЕЯё
ДЫДЮИќаТжаЃЌЬэМгСЫЙйЗНЕФОЕЯёжЇГжЃЌдкОЕЯёжаЬэМгСЫШЋВПЕФСЌНгЦїЃЌгУЛЇЮоашЯТдиАВзААќЃЌПЩвджБНгЭЈЙ§РШЁОЕЯёЃЌИќМгЗНБуЕидЫаа SeaTunnelЃЌМѕаЁВПЪ№ЕФИДдгЖШЃЌЭЌЪБОЋМђЪЙгУ K8S ВПЪ№ЕФгУЛЇВйзїСїГЬЁЃ
ЖјЖдгкгаЖЈжЦЛЏашЧѓЃЌашвЊЖўДЮПЊЗЂЕФгУЛЇЃЌаТАцБОвВЬсЙЉСЫвЛМќЪНДђАќЙЙНЈОЕЯёЕФУќСюЃК
Flink/Spark в§ЧцжЇГжЖрБэ
жЎЧАЕФАцБОжаЃЌЖрБэЖСШЁЃЌаДШыЕФЙІФмНідк Zeta в§ЧцЩЯНјааСЫжЇГжЃЌДЫДЮИќаТКѓЃЌSpark/Flink в§ЧцвВПЩвдНјааЖрБэЖСШЁКЭаДШыЁЃ
ЪЪХф Prometheus НјааМЏШКМрПи
ДЫЧАЃЌгУЛЇашвЊЭЈЙ§ API РДЛёШЁМЏШК / ШЮЮёЕФжИБъЁЃЯждкЃЌгУЛЇПЩвдНЋжИБъНјааЕМГіЕН Prometheus ЩЯЃЌPrometheus НЋЖЈЦкРШЁ SeaTunnel ЕФМЏШКШЮЮёзДЬЌЃЌВЂвдПЩЪгЛЏНчУцеЙЪОГіРДЃЌвдИќБуРћЕиМрПиМЏШКЕФзДЬЌЃЌМАЪБЗЂЯжЮЪЬтЁЃ

ЬэМг Typesense СЌНгЦїжЇГж
аТдіМгЖд Typesense СЌНгЦїЕФжЇГжЁЃ
ИФНјКЭгХЛЏ
ЬэМг Embedding transform
ЭЈЙ§ Embedding transformЃЌSeaTunnel жЇГжНЋЛњЦїбЇЯАФЃаЭЧЖШыЕНЪ§ОнзЊЛЛЙ§ГЬжаЃЌАбдЪМзжЖЮзЊЛЛГЩЯђСПжЕЃЌдйДцДЂЕНЯргІЕФЛњЦїбЇЯАЪ§ОнПтЁЃФПЧАЃЌSeaTunnel жЇГжЕФЛњЦїбЇЯАФЃаЭЬсЙЉЩЬАќРЈЖЙАќЁЂЧЇЗЋЁЂOpenAIЃЌЮДРДЛЙНЋЬэМгИќЖрЛњЦїбЇЯАФЃаЭжЇГжЁЃ
Kafka жЇГжЖСШЁ / аДШы Protobuf РраЭЪ§Он
діЧПСЫ Kafka СЌНгЦїЖд Protobuf Ъ§ОнИёЪНЕФжЇГжЃЌдк Kafka СЌНгЦїЯТдіМгЖд Protobuf Ъ§ОнРраЭЕФЖЈвхЃЌПЩвдНјааЪ§ОнЖСШЁКЭаДШыЁЃ
ЮФМўжЇГжЖСШЁбЙЫѕАќ
діМгСЫЖдбЙЫѕЮФМўИёЪНЕФЖСШЁжЇГжЃЌЪЁШЅСЫНтбЙЫѕЕФВНжшЁЃ
ИќМгЯИСЃЖШЕФзЪдДМгдиИєРы
жЇГжНЋ ClassLoader ДгШЮЮёзщМЖБ№ЕФИєРыгХЛЏЮЊШЮЮёМЖБ№ЃЌДгЖјБмУт Source/Sink ЪЙгУЯрЭЌ ClassLoader ЪБПЩФмдьГЩЕФвРРЕГхЭЛЁЃ
ЦфЫћгХЛЏЛЙАќРЈЃК
-
Paimon СїЪЇЖСШЁКЭЖЏЬЌЭАЕФаДШыжЇГж
-
SQL ЧЖЬзВщбЏжЇГжВщбЏ Map НсЙЙзжЖЮ
-
Iceberg ЕФЯрЙигХЛЏ
-
жЇГж Kerberos ШЯжЄ
-
SaveMode ЬэМг IGNORE РраЭ
-
Ждгк Redis ВЛЭЌАцБОЕФЖСШЁЪЪХфгХЛЏ
-
MySQL 8.1/8.2/8/3 АцБОЕФЪЪХф
-
жЇГж TiDB ЕФ CDC ЖСШЁ
-
вЦГ§ JDBC ЯрЙиСЌНгЦїжаЯЕЭГБэЕФЯожЦ
-
ЮЊЫљгаСЌНгЦїЬэМгЪТМўЭЈжЊЙІФм
-
ES СЌНгЦїжЇГжЖрБэЖСШЁЕФЙІФм
-
HBase СЌНгЦїЬэМгЖрБэаДШыЕФЙІФм
ЙиМќЮЪЬтаоИД
-
аоИД Hazelcast дкЗЧ TCP СЌНгЪБЕФзщЭјЮЪЬт
-
аоИДзЪдДИєРыЕФЮЪЬт
-
аоИД Paimon Dynamic Bucket БэЃЌвдМА Decimal ОЋЖШЖЊЪЇЕФЯрЙиЮЪЬт
-
аоИД Iceberg ШЮЮёНсЪјзЪдДЮДЙиБеЕФЮЪЬт
ЯъЯИИќаТЧщПіЧыВЮПМ Release NoteЃКhttps://github.com/apache/seatunnel/releases/tag/2.3.8
жТаЛЙБЯзеп
ИааЛ @liunaijie ЖдБОДЮЗЂАцЙЄзїЕФжИЕМКЭАяжњЃЌЭЌЪБИааЛвдЯТЩчЧјГЩдБЕФЙВЭЌХЌСІЃЌШУБОДЮЗЂАцЙЄзїЫГРћЭъГЩЃК
hailin0, hawk9821, cl0924, sunxiaojian, dailai, corgy-w, Hisoka-X, liunaijie, chl-wxp, zhangshenghang, ISADBA, loustler, chenqianwen, FuYouJ, xxsc0529, EricJoy2048, ZhangWeike2000, jw-itq, kevinjmh, Carl-Zhou-CN, FlechazoW, PeppaPage, liugddx, Cheun99, happyboy1024, CosmosNi, Anush008, BruceWong96, zqr10159, cloud456, Gxinge, xxsc0529, luzongzhu, jiamin13579, Zuhdan, yujian225
(д№ШЮБрМЃКIT)
Apache SeaTunnel 2.3.8 АцБОЯжвбе§ЪНЗЂВМЃЁДЫДЮАцБОКѓЃЌгУЛЇНЋПЩвдЪЙгУЦкД§вбОУЕФ Docker ОЕЯёЃЌЛЙПЩвдЬхбщ Job МЖБ№ШежОЙІФмЃЌвдМАЦфЫћИќаТгХЛЏЕФЙІФмЁЃБОЮФНЋЯъЯИНщЩм Apache SeaTunnel 2.3.8 АцБОжаЕФЙиМќИќаТФкШнЃЌЛЖгИќЖрПЊЗЂепКЭгУЛЇВЮгыЕНЮвУЧЕФПЊдДЩчЧјжаРДЁЃ
жиЕуИќаТJob МЖБ№ШежОДЫДЮИќаТжаЃЌЮвУЧЖдШежОЙІФмНјааСЫгХЛЏЃЌдкжЎЧАЕФАцБОжаЃЌЖрИіШЮЮёЕФШежОЖМдквЛИіЮФМўжаДђгЁЃЌЕБЭЌЪБдЫааЖрИіШЮЮёКѓЃЌЖрИіШЮЮёЕФШежОНЛжЏдквЛЦ№ЃЌВЛБугкХХВщЮЪЬтЁЃ ДЫДЮИќаТжЇГжСНжжЗНЪНЕФХфжУЃЌвдЪЕЯжИќМгИпаЇЕФШежОВщбЏЁЃ ЕквЛжжЪЧдкУПааШежОжаЬэМг JobIdЃЌДгЖјПЩвдЙ§ТЫВщбЏГіУПИіШежОЕЅЖРЕФШежОЃЛ
ЕкЖўжжЪЧИљОн JobId В№ЗжЮФМўЃЌжЛашаоИФШежОХфжУЮФМўЃЌОЭПЩвдУПвЛИі JobId ДђгЁЕЅЖРЕФШежОЮФМўЁЃ
аТді Docker ОЕЯёДЫДЮИќаТжаЃЌЬэМгСЫЙйЗНЕФОЕЯёжЇГжЃЌдкОЕЯёжаЬэМгСЫШЋВПЕФСЌНгЦїЃЌгУЛЇЮоашЯТдиАВзААќЃЌПЩвджБНгЭЈЙ§РШЁОЕЯёЃЌИќМгЗНБуЕидЫаа SeaTunnelЃЌМѕаЁВПЪ№ЕФИДдгЖШЃЌЭЌЪБОЋМђЪЙгУ K8S ВПЪ№ЕФгУЛЇВйзїСїГЬЁЃ ЖјЖдгкгаЖЈжЦЛЏашЧѓЃЌашвЊЖўДЮПЊЗЂЕФгУЛЇЃЌаТАцБОвВЬсЙЉСЫвЛМќЪНДђАќЙЙНЈОЕЯёЕФУќСюЃК
Flink/Spark в§ЧцжЇГжЖрБэжЎЧАЕФАцБОжаЃЌЖрБэЖСШЁЃЌаДШыЕФЙІФмНідк Zeta в§ЧцЩЯНјааСЫжЇГжЃЌДЫДЮИќаТКѓЃЌSpark/Flink в§ЧцвВПЩвдНјааЖрБэЖСШЁКЭаДШыЁЃ ЪЪХф Prometheus НјааМЏШКМрПиДЫЧАЃЌгУЛЇашвЊЭЈЙ§ API РДЛёШЁМЏШК / ШЮЮёЕФжИБъЁЃЯждкЃЌгУЛЇПЩвдНЋжИБъНјааЕМГіЕН Prometheus ЩЯЃЌPrometheus НЋЖЈЦкРШЁ SeaTunnel ЕФМЏШКШЮЮёзДЬЌЃЌВЂвдПЩЪгЛЏНчУцеЙЪОГіРДЃЌвдИќБуРћЕиМрПиМЏШКЕФзДЬЌЃЌМАЪБЗЂЯжЮЪЬтЁЃ
ЬэМг Typesense СЌНгЦїжЇГжаТдіМгЖд Typesense СЌНгЦїЕФжЇГжЁЃ ИФНјКЭгХЛЏЬэМг Embedding transformЭЈЙ§ Embedding transformЃЌSeaTunnel жЇГжНЋЛњЦїбЇЯАФЃаЭЧЖШыЕНЪ§ОнзЊЛЛЙ§ГЬжаЃЌАбдЪМзжЖЮзЊЛЛГЩЯђСПжЕЃЌдйДцДЂЕНЯргІЕФЛњЦїбЇЯАЪ§ОнПтЁЃФПЧАЃЌSeaTunnel жЇГжЕФЛњЦїбЇЯАФЃаЭЬсЙЉЩЬАќРЈЖЙАќЁЂЧЇЗЋЁЂOpenAIЃЌЮДРДЛЙНЋЬэМгИќЖрЛњЦїбЇЯАФЃаЭжЇГжЁЃ Kafka жЇГжЖСШЁ / аДШы Protobuf РраЭЪ§ОндіЧПСЫ Kafka СЌНгЦїЖд Protobuf Ъ§ОнИёЪНЕФжЇГжЃЌдк Kafka СЌНгЦїЯТдіМгЖд Protobuf Ъ§ОнРраЭЕФЖЈвхЃЌПЩвдНјааЪ§ОнЖСШЁКЭаДШыЁЃ ЮФМўжЇГжЖСШЁбЙЫѕАќдіМгСЫЖдбЙЫѕЮФМўИёЪНЕФЖСШЁжЇГжЃЌЪЁШЅСЫНтбЙЫѕЕФВНжшЁЃ ИќМгЯИСЃЖШЕФзЪдДМгдиИєРыжЇГжНЋ ClassLoader ДгШЮЮёзщМЖБ№ЕФИєРыгХЛЏЮЊШЮЮёМЖБ№ЃЌДгЖјБмУт Source/Sink ЪЙгУЯрЭЌ ClassLoader ЪБПЩФмдьГЩЕФвРРЕГхЭЛЁЃ ЦфЫћгХЛЏЛЙАќРЈЃК
ЙиМќЮЪЬтаоИД
ЯъЯИИќаТЧщПіЧыВЮПМ Release NoteЃКhttps://github.com/apache/seatunnel/releases/tag/2.3.8 жТаЛЙБЯзепИааЛ @liunaijie ЖдБОДЮЗЂАцЙЄзїЕФжИЕМКЭАяжњЃЌЭЌЪБИааЛвдЯТЩчЧјГЩдБЕФЙВЭЌХЌСІЃЌШУБОДЮЗЂАцЙЄзїЫГРћЭъГЩЃК hailin0, hawk9821, cl0924, sunxiaojian, dailai, corgy-w, Hisoka-X, liunaijie, chl-wxp, zhangshenghang, ISADBA, loustler, chenqianwen, FuYouJ, xxsc0529, EricJoy2048, ZhangWeike2000, jw-itq, kevinjmh, Carl-Zhou-CN, FlechazoW, PeppaPage, liugddx, Cheun99, happyboy1024, CosmosNi, Anush008, BruceWong96, zqr10159, cloud456, Gxinge, xxsc0529, luzongzhu, jiamin13579, Zuhdan, yujian225 (д№ШЮБрМЃКIT) |