英伟达官宣:CUDA 工具链将全面原生支持 Python
时间:2025-04-09 09:05 来源:未知 作者:IT
在近期的 GTC 2025 大会上,英伟达宣布其 CUDA 工具包将为 Python 提供原生支持并全面与之集成。

CUDA 架构师 Stephen Jones 在 GTC 技术演讲中对此表示,“我们一直在努力让加速计算与 Python 深度融合,使其成为 CUDA 技术栈中的‘一等公民’。”
据介绍,对于添加了原生 Python 支持的 CUDA,开发者可直接用 Python 编写算法,并在英伟达 GPU 上高效执行,无需手动调用底层内核或依赖 C++ 接口封装。
Stephen Jones 补充道:“这不仅仅是把原来的 C 语言翻译成 Python,而是要让 Python 保持本色,让 Python 开发者也感到自然。”
英伟达也强调,此次更新重新设计了一套真正符合 Python 编程习惯的 CUDA 开发模型,包括 API、库、执行方式和性能优化手段。开发者可以像使用 NumPy、PyTorch 那样,用 Python 脚本直接编写和调用 GPU 加速逻辑。
换句话说,英伟达对 CUDA 不是简单的语法包装,而是一次从运行时到编程模型的 Python 化重构。具体来看,英伟达提供了:
-
CUDA Core:重新设计的运行时系统,支持完全的 Python 编程体验,执行流程也更贴近 Python 风格;
-
cuPyNumeric:NumPy 的 GPU 加速替代品,修改一行 import 即可将代码从 CPU 迁移至 GPU;
-
NVMath Python:统一接口库,支持在 host 和 device 两端调用各种库函数,这些函数调用支持自动融合(fusing),可带来明显的性能提升;
-
采用 JIT 编译:几乎不依赖传统编译器,大幅减少依赖链复杂度,提高执行效率和可移植性;
-
全套的分析工具支持:包括性能分析器、代码静态分析器等,帮助开发者进行性能调优。
除此之外,传统 CUDA 强调线程(thread)、块(block)等显式控制方式,而 Python 工程师则更熟悉 “数组思维”—— 以矩阵、张量、向量等结构为基础组织计算。
为此,英伟达还推出了全新编程模型 CuTile,它更像是面向数组、张量的抽象,更贴近 Python 开发者的思维模式。
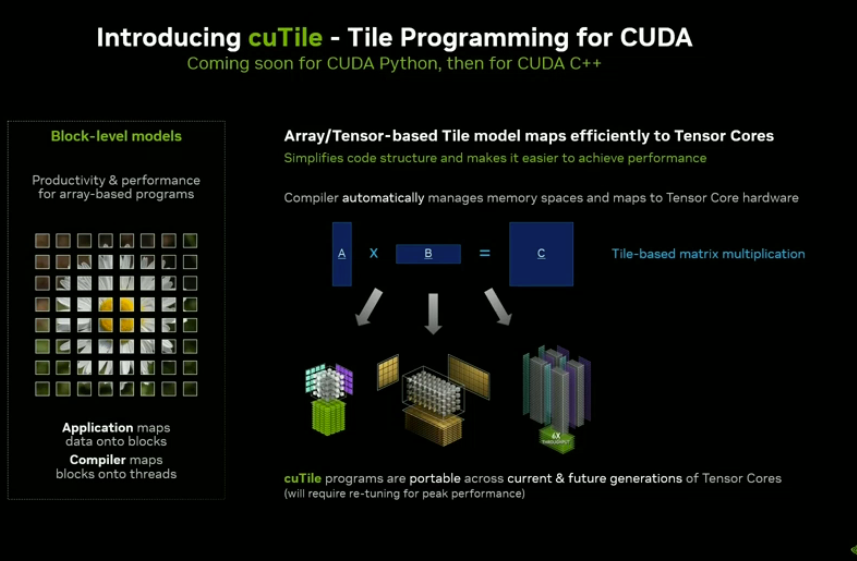
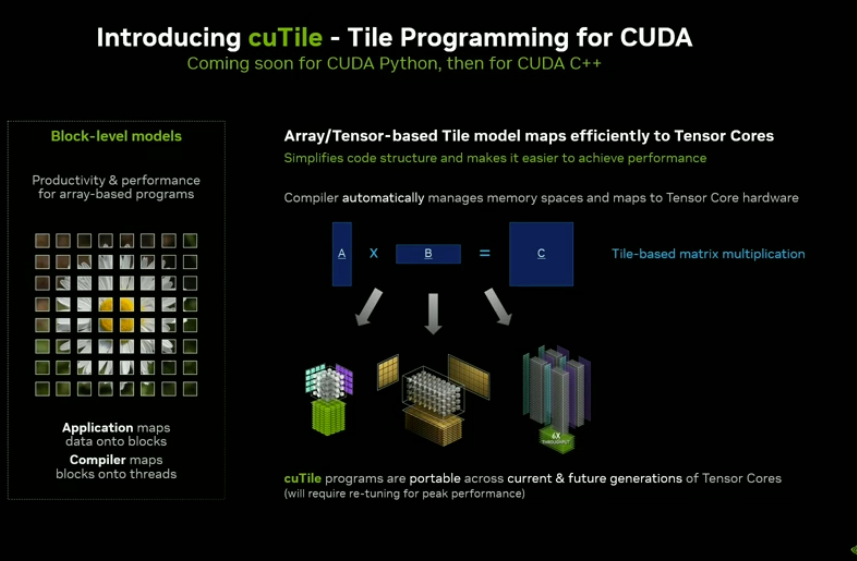
CuTile 模型强调以 tile(小块)为基本计算单元进行调度,每个 tile 包含若干数据元素,由编译器负责自动映射到底层线程执行,从而实现高效的 GPU 加速。
Stephen Jones 解释道,“相比线程,tile 更贴近 Python 语言的哲学;它足够高效,性能也不输 C++。”——tile 中的数据可以是向量、张量或数组,编译器可以更好地将整个数组操作映射到 GPU。
另外英伟达还计划在未来支持更多编程语言,早在 2024 年 GPU 技术大会上英伟达工程师就表示英伟达还在探索诸如 Rust 和 Julia 等编程开发语言,吸引更广泛的开发者群体。
相关链接:https://github.com/NVIDIA/cuda-python
(责任编辑:IT)
在近期的 GTC 2025 大会上,英伟达宣布其 CUDA 工具包将为 Python 提供原生支持并全面与之集成。
CUDA 架构师 Stephen Jones 在 GTC 技术演讲中对此表示,“我们一直在努力让加速计算与 Python 深度融合,使其成为 CUDA 技术栈中的‘一等公民’。” 据介绍,对于添加了原生 Python 支持的 CUDA,开发者可直接用 Python 编写算法,并在英伟达 GPU 上高效执行,无需手动调用底层内核或依赖 C++ 接口封装。 Stephen Jones 补充道:“这不仅仅是把原来的 C 语言翻译成 Python,而是要让 Python 保持本色,让 Python 开发者也感到自然。” 英伟达也强调,此次更新重新设计了一套真正符合 Python 编程习惯的 CUDA 开发模型,包括 API、库、执行方式和性能优化手段。开发者可以像使用 NumPy、PyTorch 那样,用 Python 脚本直接编写和调用 GPU 加速逻辑。 换句话说,英伟达对 CUDA 不是简单的语法包装,而是一次从运行时到编程模型的 Python 化重构。具体来看,英伟达提供了:
除此之外,传统 CUDA 强调线程(thread)、块(block)等显式控制方式,而 Python 工程师则更熟悉 “数组思维”—— 以矩阵、张量、向量等结构为基础组织计算。 为此,英伟达还推出了全新编程模型 CuTile,它更像是面向数组、张量的抽象,更贴近 Python 开发者的思维模式。
CuTile 模型强调以 tile(小块)为基本计算单元进行调度,每个 tile 包含若干数据元素,由编译器负责自动映射到底层线程执行,从而实现高效的 GPU 加速。 Stephen Jones 解释道,“相比线程,tile 更贴近 Python 语言的哲学;它足够高效,性能也不输 C++。”——tile 中的数据可以是向量、张量或数组,编译器可以更好地将整个数组操作映射到 GPU。 另外英伟达还计划在未来支持更多编程语言,早在 2024 年 GPU 技术大会上英伟达工程师就表示英伟达还在探索诸如 Rust 和 Julia 等编程开发语言,吸引更广泛的开发者群体。 相关链接:https://github.com/NVIDIA/cuda-python (责任编辑:IT) |