基于Linux的集群系统(五)
时间:2014-08-14 23:19 来源:linux.it.net.cn 作者:许广斌
作者:许广斌
关键技术分析之 进程的放置和迁移
通过对本系列前面四篇文章的学习,您对于集群系统应该已经有了一个整体的认识。从本篇开始作者将对集群系统进行更深入的探讨。本篇作为《关键技术分析》的第一篇将向我们讲述进程放置和迁移的一些关键技术。
1. 进程的放置
在集群系统中,进程的到达时间和新到达进程所需的资源量都是不可预测的,因此进程的放置和迁移是非常重要的问题。由于集群系统中的不可预测性,进程有时就会被放置在不合适的机器上,进程迁移就给了系统一个弥补这样的错误的机会。通过较好的算法将新创建的进程放置到合适的节点上执行,并且对某些进程进行迁移可以缩短任务的平均执行时间,因此从整体上提高了系统的性能。
进程的放置问题是非常复杂的,因为集群中的资源是异构的,如:内存、CPU、进程间通讯等等。衡量这些资源耗费的方法也是不同的:内存的单位是字节,CPU的单位是循环、通讯资源的单位是带宽。
进程的放置策略分为静态放置策略和动态放置策略。静态放置策略通过预先定义的规则对新创建的进程进行分配,它不使用运行时的信息。而动态放置策略则根据系统状态的变化将进程重新放置到最适宜的节点上。
常见的静态放置策略由三种:Round Robin(RR)、Best-Fit(BF)、Round Robin Next-Fit (NF)。
Round Robin将新创建的进程以轮转的形式放置到集群中的各节点上。这种方法的缺陷在于如果新创建的进程所需的内存量大于将要分配到其上的节点的可用内存大小,则会导致算法的失败。
一种改进的方法是使用Best-Fit方法,进程将被放置到具有最大可用内存的节点上。
Round Robin Next-fit以Round Robin的方式扫描各节点,并且将进程发送到第一个有足够大内存的节点上。它的缺点就是可能会导致负载不均衡地分配到各个节点。
三种进程放置策略的性能如图1-1所示。(进程的平均大小是16MB)
从该图可以看出,NF算法能够最充分地利用内存资源。当集群中的节点数增加时,BF算法和RR的算法的性能也随之有明显的下降,之所以产生这种情况是因为当节点数增加时,集群中的内存总量也随之成比例地增加,而且新增加的节点也会创建新的进程,这也就意味着大进程的数量也会随之增多,这些大进程对于BF算法和RR算法而言是很难放置的,因此会导致它们的性能的下降。
一种动态的进程放置策略叫做MS(Migrate the Smallest process),它以Round Robin的形式扫描所有的节点,并且将新进程放置到下一个节点上。与Round Robin不同的是,如果要放置的节点的内存不足以提供给新来的进程使用,则MS算法将迁移走一个进程。将要被迁移的进程是该节点上所有进程中最小的一个但是迁移走它刚好能满足新进程所需内存,而且也有其它的节点能够容纳这个将被迁移的节点,这种方法有较小的网络开销,如果不存在这样的节点,如其它的所有节点都没有足够大的内存空间,则算法失败。MS算法和NF算法的比较如下图所示。当进程的平均大小为1M时,两种算法都取得了将近100%的内存利用率,但是如图1-2所示当进程的平均大小为16M时,MS 算法比NF 算法高了20多个百分点。
以上各种算法都是集中式的进程放置策略,都需要使用全局信息来决定放置策略,不利于可扩展性,不能有效地在拥有多个节点的集群上执行。一种基于MS的分布式进程放置算法(Windowed MS)是这样实现的:它将迁移的进程放置到从信息窗口中选出的具有最大可用内存的节点上。所谓信息窗口指的是一个缓冲区,里面保存着其它节点的可用内存的信息。每隔一定的时间就会将其它各节点的内存信息收集到信息窗口中,并对信息窗口进行更新。
: 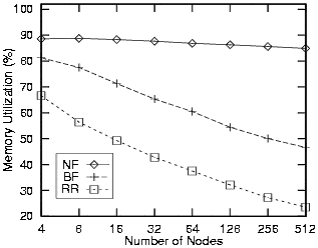
图1-1 进程放置策略性能比较图
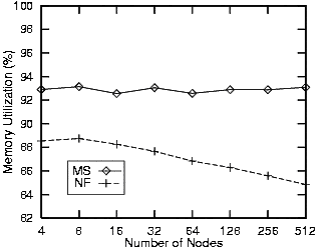
图1-2 进程放置策略性能比较图
2. 进程的迁移
早在20世纪80年代,人们就开始了进程迁移的研究。大多数的研究主要着眼于如何用更好的方法在机器之间传送进程的状态。同构的进程迁移指的是进程迁移的原始和目标机器的体系结构相同,而异构的进程迁移指的是不同体系结构的机器之间的进程迁移。同构的进程迁移系统的例子有:V Charllote 、DEMOS/MP、 Sprite、 Condor、 Accent ;异构的进程迁移系统有:Tui、Emerald、HMF(Heterogeneous Migration Facility )等。进程迁移主要用于以下几种情况下。
当失效的机器修复了错误,重新进入集群系统时,需要将某些该机器上原来运行的进程重新迁移回来。
在集群系统中进行负载共享。为了让一个进程使用尽可能多的CPU时间,需要将它迁移到能提供大部分指令和I/O操作的机器上执行。但是有时候负载共享也有缺陷,因为大部分的进程只需一少部分的CPU时间,考虑到进程迁移的开销,如果对那些简单的可以在本地运行的进程进行迁移是得不偿失的,但是对于那些需要大量的处理时间的程序如仿真程序,迁移进程是非常有效的。
提高通讯性能。如果一个进程需要与其它进程频繁地进行通讯,这时将这些进程放置得近一些就会减少通讯的开销。具体的迁移方法就是将一个进程迁移到其它进程所在的CPU上。
可用性。当网络上的某台机器失效时,通过进程迁移可以将进程迁移到其它机器上继续执行,这样就保证了系统在遇到灾难时的可用性。
重新配置。当对集群进行管理时,有时需要将服务从一个节点移到另一个节点,透明的进程迁移可以在不停机的情况下迁移服务。
使用集群中的某些机器的特殊能力。如果某个进程能够从集群中的某台特定机器上受益,它就应该在那台机器上执行。如进行数值计算的程序能够通过使用数学协处理器或超级计算机中的多个处理器来大大缩短程序执行时间。
尽管进程迁移已经在实验环境中成功地实现了,但是它还没有被广泛地接受。一个原因是占主流的平台如MSDOS、 Microsoft Windows以及许多种类的UNIX操作系统都没有对进程迁移的支持。另一个原因是因为进程迁移开销可能比不迁移进程时的开销还要大。但是当前,两种新的计算领域又促进了进程迁移的发展,一个是移动计算,另一个是广域计算。移动计算指的是那些便携式的小型计算机的计算问题。而广域计算是指广域网中的机器的计算问题。
进程迁移将一个正在执行的进程从一个节点迁移到通过网络连接的另一个节点上(也就是说,不使用本地共享内存机制)。进程所在的原始节点上的操作系统应该将进程的所有状态都包装起来,这样目的机就可以继续执行此进程。
要完成进程迁移需要迁移进程的状态,尤其是进程的地址空间,对其它进程的访问(如套接口、管道等),代码(可以组成地址空间的一部分)以及执行状态(寄存器、堆栈等)。除了这些,还需要将那些对原始的进程所有访问都重新链接到新的进程拷贝上,不然迁移就不是无缝的,就会导致错误。整个进程迁移操作必须是原子操作,这样才能避免进程的丢失或者是有两个拷贝。
为了进行进程迁移需要再进行以下的修改:
必须对文件系统进行一定的修改使每个机器看到相同的名字空间。
必须传送足够的状态从而确保正常的核心调用能够在远端机器上正常执行。
一些特殊的核心系统调用如gettimeofday 、getpgrp应该发回到原始节点执行。
下面通过一个异构进程迁移的例子来说明进程迁移的整个过程。图1-3说明了进程是如何在Tui进程迁移系统中从一个机器上迁移到另一个机器上的。
首先是对一个程序进行编译,针对Tui支持的四种体系结构,将程序分别编译四次。
程序在原始机上以普通方式执行。(如命令行方式)
当选定一个迁移的进程时,migrout程序首先为进程设置检查点,然后挂起进程,然后进行内存映像,接着扫描全局变量、堆栈和堆来定位所有的数据。再把所有的这些都转化为一种中介的格式传送给目标机。最后,杀死原始机器上的进程。
在目标机上,migrin程序取得中介值并创建新的进程,由于程序已经根据目标机的体系结构进行了编译,因此正文段的信息和数据报的类型信息都是可用的。然后通过重新创建全局变量、堆和堆栈,程序从检查点处继续执行。
经过统计,选择空闲主机并且开始一个新的进程需要0.1秒的时间,平均迁移时间是330毫秒。通过进程迁移可以将性能提高近5倍。
: 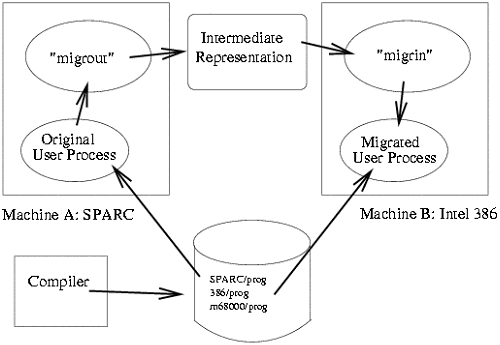
图1-3 进程迁移过程示意图
(责任编辑:IT)
| 作者:许广斌 关键技术分析之 进程的放置和迁移 通过对本系列前面四篇文章的学习,您对于集群系统应该已经有了一个整体的认识。从本篇开始作者将对集群系统进行更深入的探讨。本篇作为《关键技术分析》的第一篇将向我们讲述进程放置和迁移的一些关键技术。 1. 进程的放置 在集群系统中,进程的到达时间和新到达进程所需的资源量都是不可预测的,因此进程的放置和迁移是非常重要的问题。由于集群系统中的不可预测性,进程有时就会被放置在不合适的机器上,进程迁移就给了系统一个弥补这样的错误的机会。通过较好的算法将新创建的进程放置到合适的节点上执行,并且对某些进程进行迁移可以缩短任务的平均执行时间,因此从整体上提高了系统的性能。 进程的放置问题是非常复杂的,因为集群中的资源是异构的,如:内存、CPU、进程间通讯等等。衡量这些资源耗费的方法也是不同的:内存的单位是字节,CPU的单位是循环、通讯资源的单位是带宽。 进程的放置策略分为静态放置策略和动态放置策略。静态放置策略通过预先定义的规则对新创建的进程进行分配,它不使用运行时的信息。而动态放置策略则根据系统状态的变化将进程重新放置到最适宜的节点上。 常见的静态放置策略由三种:Round Robin(RR)、Best-Fit(BF)、Round Robin Next-Fit (NF)。 Round Robin将新创建的进程以轮转的形式放置到集群中的各节点上。这种方法的缺陷在于如果新创建的进程所需的内存量大于将要分配到其上的节点的可用内存大小,则会导致算法的失败。 一种改进的方法是使用Best-Fit方法,进程将被放置到具有最大可用内存的节点上。 Round Robin Next-fit以Round Robin的方式扫描各节点,并且将进程发送到第一个有足够大内存的节点上。它的缺点就是可能会导致负载不均衡地分配到各个节点。 三种进程放置策略的性能如图1-1所示。(进程的平均大小是16MB) 从该图可以看出,NF算法能够最充分地利用内存资源。当集群中的节点数增加时,BF算法和RR的算法的性能也随之有明显的下降,之所以产生这种情况是因为当节点数增加时,集群中的内存总量也随之成比例地增加,而且新增加的节点也会创建新的进程,这也就意味着大进程的数量也会随之增多,这些大进程对于BF算法和RR算法而言是很难放置的,因此会导致它们的性能的下降。 一种动态的进程放置策略叫做MS(Migrate the Smallest process),它以Round Robin的形式扫描所有的节点,并且将新进程放置到下一个节点上。与Round Robin不同的是,如果要放置的节点的内存不足以提供给新来的进程使用,则MS算法将迁移走一个进程。将要被迁移的进程是该节点上所有进程中最小的一个但是迁移走它刚好能满足新进程所需内存,而且也有其它的节点能够容纳这个将被迁移的节点,这种方法有较小的网络开销,如果不存在这样的节点,如其它的所有节点都没有足够大的内存空间,则算法失败。MS算法和NF算法的比较如下图所示。当进程的平均大小为1M时,两种算法都取得了将近100%的内存利用率,但是如图1-2所示当进程的平均大小为16M时,MS 算法比NF 算法高了20多个百分点。 以上各种算法都是集中式的进程放置策略,都需要使用全局信息来决定放置策略,不利于可扩展性,不能有效地在拥有多个节点的集群上执行。一种基于MS的分布式进程放置算法(Windowed MS)是这样实现的:它将迁移的进程放置到从信息窗口中选出的具有最大可用内存的节点上。所谓信息窗口指的是一个缓冲区,里面保存着其它节点的可用内存的信息。每隔一定的时间就会将其它各节点的内存信息收集到信息窗口中,并对信息窗口进行更新。 : 图1-1 进程放置策略性能比较图 图1-2 进程放置策略性能比较图 2. 进程的迁移 早在20世纪80年代,人们就开始了进程迁移的研究。大多数的研究主要着眼于如何用更好的方法在机器之间传送进程的状态。同构的进程迁移指的是进程迁移的原始和目标机器的体系结构相同,而异构的进程迁移指的是不同体系结构的机器之间的进程迁移。同构的进程迁移系统的例子有:V Charllote 、DEMOS/MP、 Sprite、 Condor、 Accent ;异构的进程迁移系统有:Tui、Emerald、HMF(Heterogeneous Migration Facility )等。进程迁移主要用于以下几种情况下。 当失效的机器修复了错误,重新进入集群系统时,需要将某些该机器上原来运行的进程重新迁移回来。 在集群系统中进行负载共享。为了让一个进程使用尽可能多的CPU时间,需要将它迁移到能提供大部分指令和I/O操作的机器上执行。但是有时候负载共享也有缺陷,因为大部分的进程只需一少部分的CPU时间,考虑到进程迁移的开销,如果对那些简单的可以在本地运行的进程进行迁移是得不偿失的,但是对于那些需要大量的处理时间的程序如仿真程序,迁移进程是非常有效的。 提高通讯性能。如果一个进程需要与其它进程频繁地进行通讯,这时将这些进程放置得近一些就会减少通讯的开销。具体的迁移方法就是将一个进程迁移到其它进程所在的CPU上。 可用性。当网络上的某台机器失效时,通过进程迁移可以将进程迁移到其它机器上继续执行,这样就保证了系统在遇到灾难时的可用性。 重新配置。当对集群进行管理时,有时需要将服务从一个节点移到另一个节点,透明的进程迁移可以在不停机的情况下迁移服务。 使用集群中的某些机器的特殊能力。如果某个进程能够从集群中的某台特定机器上受益,它就应该在那台机器上执行。如进行数值计算的程序能够通过使用数学协处理器或超级计算机中的多个处理器来大大缩短程序执行时间。 尽管进程迁移已经在实验环境中成功地实现了,但是它还没有被广泛地接受。一个原因是占主流的平台如MSDOS、 Microsoft Windows以及许多种类的UNIX操作系统都没有对进程迁移的支持。另一个原因是因为进程迁移开销可能比不迁移进程时的开销还要大。但是当前,两种新的计算领域又促进了进程迁移的发展,一个是移动计算,另一个是广域计算。移动计算指的是那些便携式的小型计算机的计算问题。而广域计算是指广域网中的机器的计算问题。 进程迁移将一个正在执行的进程从一个节点迁移到通过网络连接的另一个节点上(也就是说,不使用本地共享内存机制)。进程所在的原始节点上的操作系统应该将进程的所有状态都包装起来,这样目的机就可以继续执行此进程。 要完成进程迁移需要迁移进程的状态,尤其是进程的地址空间,对其它进程的访问(如套接口、管道等),代码(可以组成地址空间的一部分)以及执行状态(寄存器、堆栈等)。除了这些,还需要将那些对原始的进程所有访问都重新链接到新的进程拷贝上,不然迁移就不是无缝的,就会导致错误。整个进程迁移操作必须是原子操作,这样才能避免进程的丢失或者是有两个拷贝。 为了进行进程迁移需要再进行以下的修改: 必须对文件系统进行一定的修改使每个机器看到相同的名字空间。 必须传送足够的状态从而确保正常的核心调用能够在远端机器上正常执行。 一些特殊的核心系统调用如gettimeofday 、getpgrp应该发回到原始节点执行。 下面通过一个异构进程迁移的例子来说明进程迁移的整个过程。图1-3说明了进程是如何在Tui进程迁移系统中从一个机器上迁移到另一个机器上的。 首先是对一个程序进行编译,针对Tui支持的四种体系结构,将程序分别编译四次。 程序在原始机上以普通方式执行。(如命令行方式) 当选定一个迁移的进程时,migrout程序首先为进程设置检查点,然后挂起进程,然后进行内存映像,接着扫描全局变量、堆栈和堆来定位所有的数据。再把所有的这些都转化为一种中介的格式传送给目标机。最后,杀死原始机器上的进程。 在目标机上,migrin程序取得中介值并创建新的进程,由于程序已经根据目标机的体系结构进行了编译,因此正文段的信息和数据报的类型信息都是可用的。然后通过重新创建全局变量、堆和堆栈,程序从检查点处继续执行。 经过统计,选择空闲主机并且开始一个新的进程需要0.1秒的时间,平均迁移时间是330毫秒。通过进程迁移可以将性能提高近5倍。 : 图1-3 进程迁移过程示意图 (责任编辑:IT) |