Centos下安装hadoop并与Eclipse连接
时间:2014-11-19 12:13 来源:linux.it.net.cn 作者:IT
许久之前就计划学习hadoop了,直到最近才提上日程。花费了一些时间才把centos下的hadoop搭起来,前后经历的“挫折”绝对可以写成数千字的血泪史了。既有被网上教程坑了的苦逼遭遇,也有教研室大超师兄和实习公司的泡哥的爱心支援。今天终于可以坐下来说说如何在Centos下安装hadoop并与Eclipse连接这个问题。
先说一下要准备哪些软件和信息:
VMware-workstation;
CentOS-6.0-i386-bin-DVD;
eclipse-jee-luna-SR1-win32;
hadoop-0.20.2;
jdk-6u27-linux-i586;
(由于hadoop对版本的要求较高,大家还是不要轻易更换版本,这里列出来的各种软件都是稳定发布版,网上很容易可以download到的)。
整个教程分为这样5个部分来说:1)在Windows下安装虚拟机Vmware,并新建一个虚拟机装好centos系统;2)centos下设置ssh服务无密码登录;3)centos下安装jdk,并配置环境变量;4)centos下安装hadoop,并配置文件;5)windows下安装jdk和eclipse,并将eclipse与centos下的hadoop连接。可以说这5个部分每一个都很重要,尤其是第4)步。下面我们就详细说一下每一步该怎么做。
Step 0: 请大家先在windows下新建一个普通用户,用户名为hadoop,我们所有的软件全在这个下面安装,用户名最好要是hadoop,因为这个要和后面很多username相同,设为hadoop比较好记。
1)在Windows下安装虚拟机Vmware,并新建一个虚拟机装好centos系统;
首先,下载VMware-workstation并安装,这步骤和一般windows下安装软件的过程是一样的,入门小白也会熟练操作,这里就节省点儿空间给后面重要的步骤了~
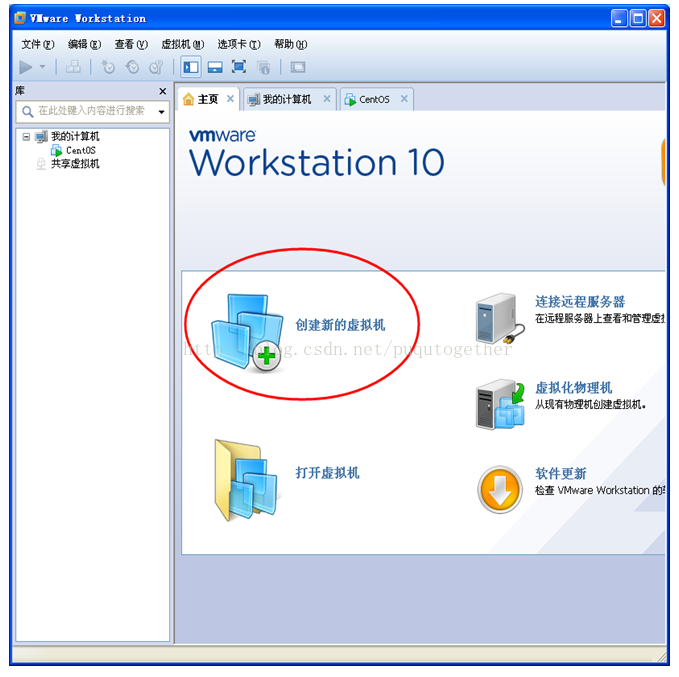
然后,在Vmware的主页上新建一个虚拟机,如下图:
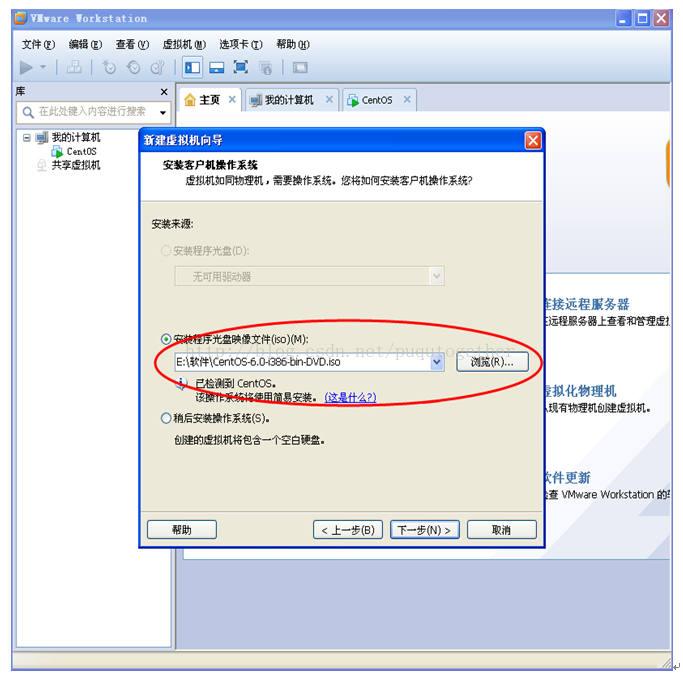
一路下一步,直到让你选择系统镜像路径,我们选择centos系统映像,如上图,点击下一步。然后,需要你输入linux的用户名,这个比较重要,最好填写hadoop,因为这个名字在后面要用到好多次!
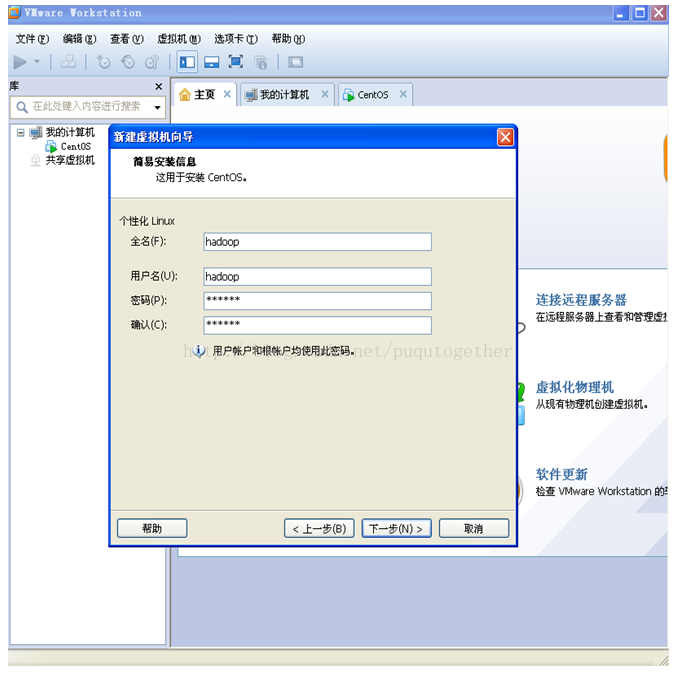
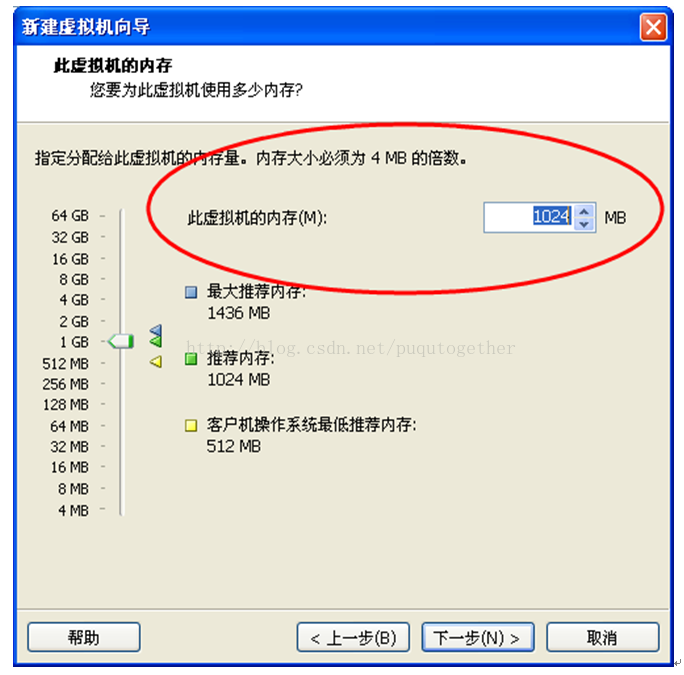
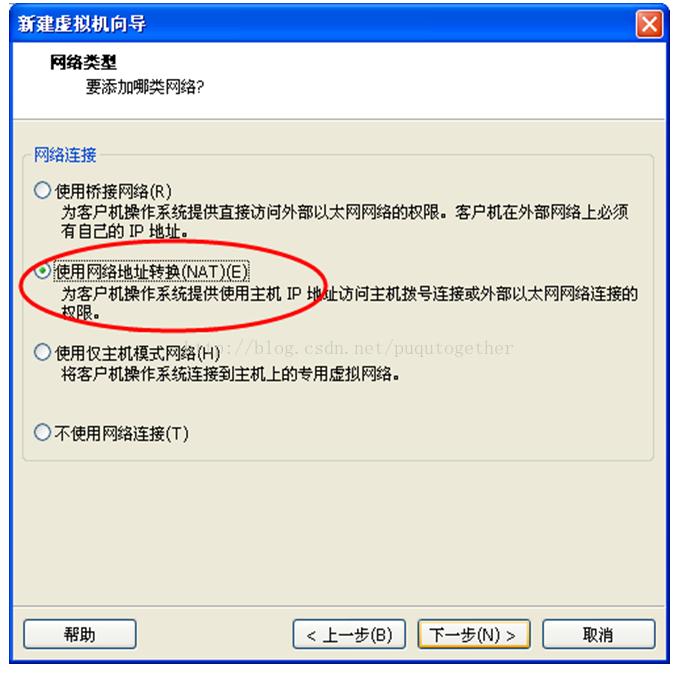
后面还是一路的“下一步”,直到让你设置虚拟机的内存大小,建议为1024M。如上图。后面就是要选择和虚拟机的网络类型有关的设置了,建议为“使用网络地址转换NAT”,如下图。这一步我当时选择了自动桥接的功能,找了一个晚上的错误。。。时间就这样白花花的没了~~
之后还是一路的“下一步”,几乎都是使用它推荐的设置,我们就可以新建一个centos,等待个几分钟然后就可以进入centos界面了。看到那一抹科技蓝,有没有让你心动了呢~~哈哈哈,你确实走好了第一步!
2)centos下设置ssh服务无密码登录;
在桌面右击,选择openin Terminal,这个就是linux的终端了。希望读者有一些linux操作系统的基础,这样子上手更快一些。不过要是没有的话,也没有关系,我们是面向新手的教程。
2.1. 先在linux命令行中输入su,提示密码,输入你自己设置的密码,这样子你后面的操作都具有了linux系统下的最高权限——root权限。
2.2. 在设置ssh无密码登录之前,有一个特别重要的要先出好:关闭SELinux。这是因为centos会自动阻止你修改sshservice,我们只有关闭SELinux,重启才能生效。如何做,如下:
修改/etc/selinux/config文件
将SELINUX=enforcing改为SELINUX=disabled
重启机器即可
(note:在linux下修改文件,vi命令后会进入到文件窗口,按i进入insert,修改完毕之后再按esc推出insert,输入;:wq!保存并退出~这里要感谢泡哥,改了半天都不行,还是泡哥指点迷津了~~)
2.3. 在linux命令行里输入:ssh-keygen -t rsa,然后一路回车。
root@hadoopName-desktop:~$ssh-keygen -t rsa
Generating public/private rsakey pair.
Enterfile in which to save the key (/home/zhangtao/.ssh/id_rsa): //密钥保存位置,直接回车保持默认;
Createddirectory '/home/zhangtao/.ssh'.
Enter passphrase(empty for no passphrase): //设置密钥的密码,空密码直接回车即可;
Enter samepassphrase again: //确认上一步设置的密码。
然后进入 /root/.ssh/下面,会看到两个文件 id_rsa.pub,id_rsa,
然后执行cp id_rsa.pub authorized_keys
然后 ssh localhost 验证是否成功,第一次要你输入yes,以后就不需要了。
如下图,由于我又验证了一次,所以还需要输入y,如果你是第一次验证是不要的。

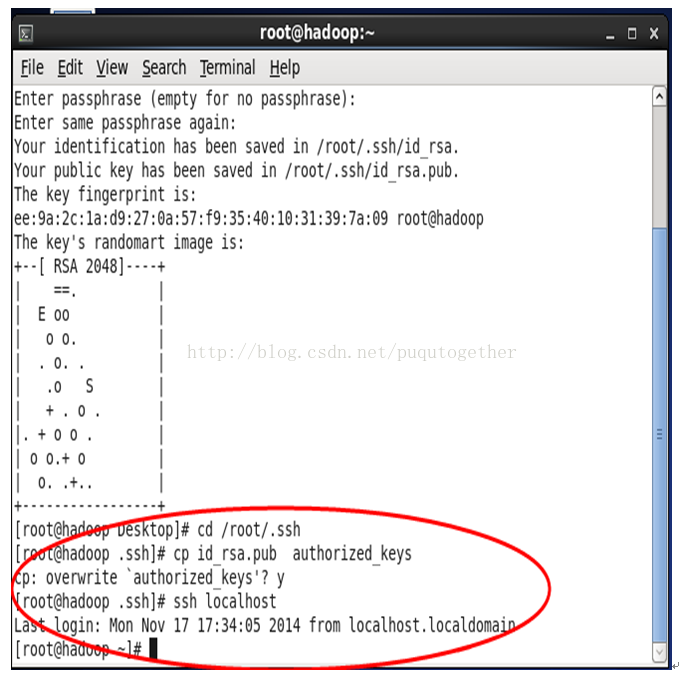
至此,ssh服务无密码登录设置完毕!
3)centos下安装jdk,并配置环境变量;
这一步中可以分为两步:安装jdk、配置jdk环境变量。
3.1. 第一步:root 用户登陆,使用命令mkdir /usr/program新建目录/usr/program ,下载 JDK 安装包jdk-6u13-linux-i586.bin,将其复制到目录/usr/program下,用cd命令进入该目录,执行命令“./ jdk-6u13-linux-i586.bin”,命令运行完毕即安装完成,将在目录下生成文件夹/jdk1.6.0_13,此即为jdk被成功安装到目录:/usr/program/jdk1.6.0_13下。
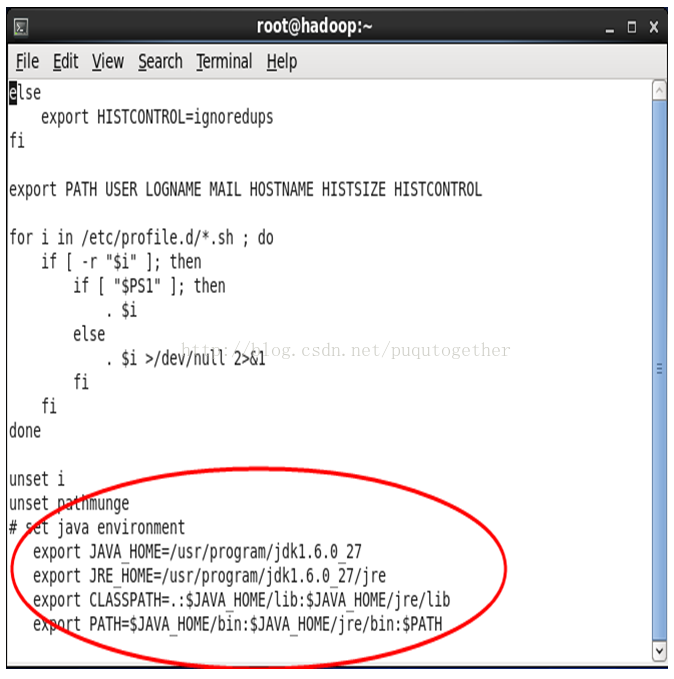
3.2. root 用户登陆,命令行中执行命令“vi/etc/profile”,并加入以下内容,配置环境变量(注意/etc/profile这个文件很重要,后面 Hadoop 的配置还会用到)。
# set java environment
exportJAVA_HOME=/usr/program/jdk1.6.0_27
exportJRE_HOME=/usr/program/jdk1.6.0_27/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
在vi编辑器增加以上内容后保存退出,并执行以下命令使配置生效!
#chmod +x /etc/profile ;增加执行权限
#source /etc/profile;使配置生效!
配置完毕后,在命令行中输入:java -version,就会出现安装jdk的信息。
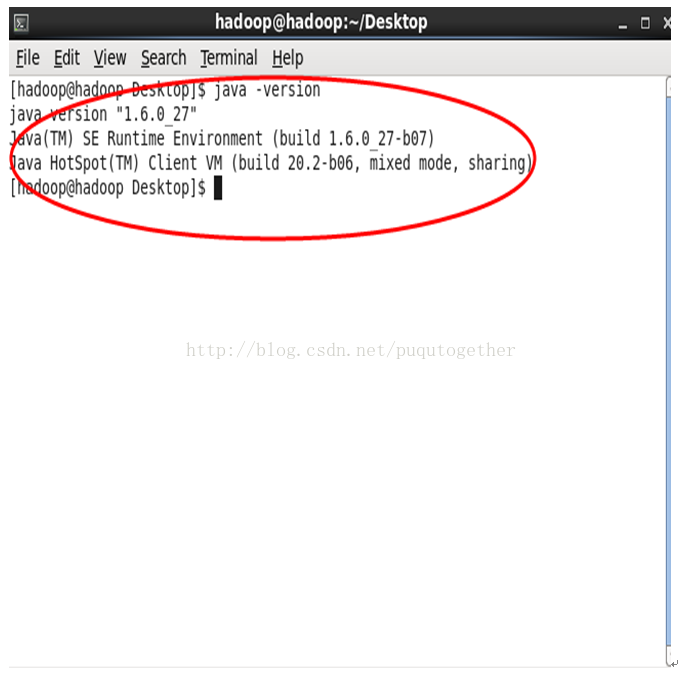
这时,jdk的安装和配置环境变量就成功了~
4)centos下安装hadoop,并配置文件;
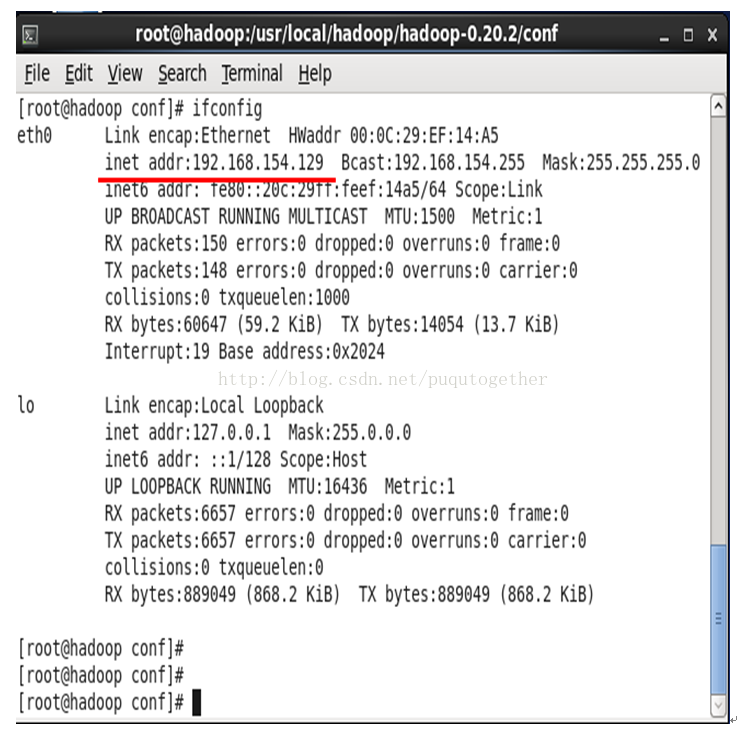
4.1.安装hadoop之前要先知道你的centos中的ip地址:在终端中输入ifconfig就可以查看ip地址了。如下图:(我的是192.168.154.129)
4.2.下载 hadoop-0.20.2.tar.gz,将其拷贝到/usr/local/hadoop 目录下,然后在该目录/usr/local/hadoop下解压安装生成文件/hadoop-0.20.2(即为hadoop被安装到/usr/local/hadoop/ hadoop-0. 20.2文件夹下)。
命令如下: tar -zxvf hadoop-0.20.2.tar.gz 解压安装一步完成!
4.3.首先配置hadoop的环境变量
命令“vi /etc/profile”
#set hadoop
export HADOOP_HOME=/usr/hadoop/hadoop-0.20.2
export PATH=$HADOOP_HOME/bin:$PATH
命令:source /etc/profile 使刚配置的文件生效!
进入/usr/local/hadoop/hadoop-0.20.2/conf,配置Hadoop配置文件
4.4. 配置hadoop-env.sh文件
打开文件命令:vihadoop-env.sh
添加 # set javaenvironment
export JAVA_HOME=/usr/program/jdk1.6.0_27
编辑后保存退出(提示,输入:wq!)。其实仔细找一下就会发现hadoop-env.sh文件中本身就有JAVA_HOME这行,我们只需要把前面的注释#取消,然后修改HOME的地址就好。如下图所示:
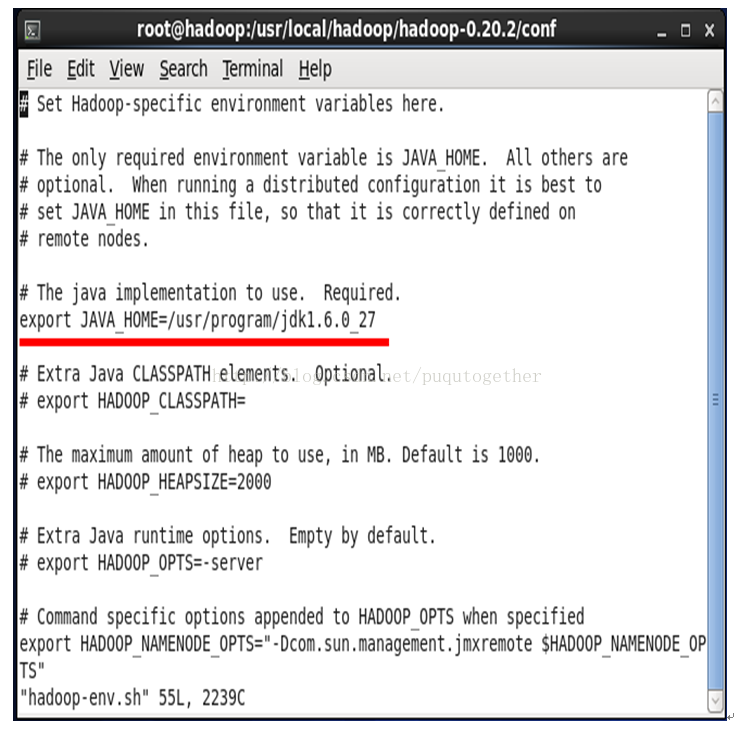
4.5. 配置core-site.xml
[root@master conf]# vi core-site.xml
<?xml version="1.0"?>
<?xml-stylesheettype="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overridesin this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.154.129:9000/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/hadoop-0.20.2/hadooptmp</value>
</property>
</configuration>
(note:hdfs后面的一定要是你的centos的IP地址,这就是为什么要在上面先ifconfig得到ip地址的原因。有些教程说的那种localhost,是不正确的!后面和eclipse会连接不上!!这里又消耗了一个晚上的时间。。。)
如下图所示:
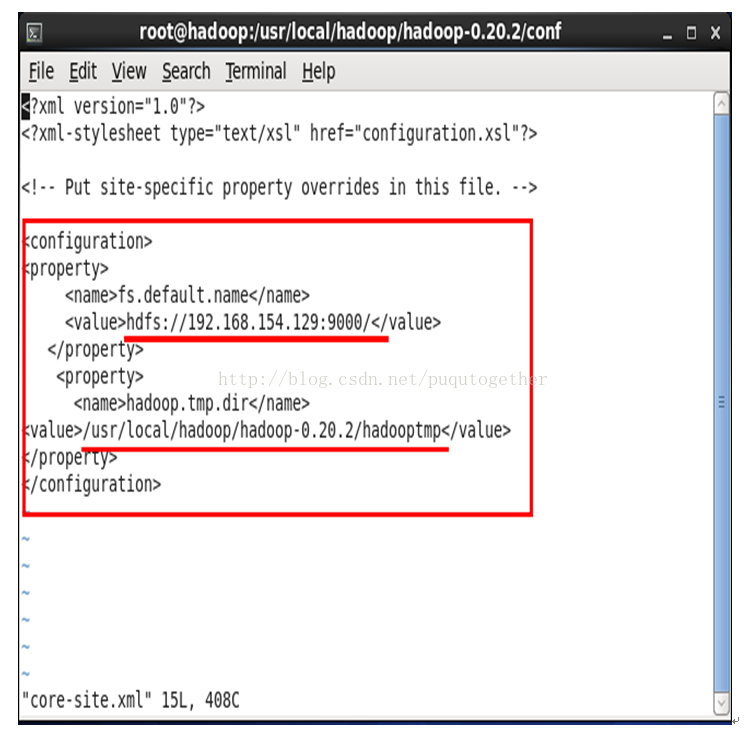
说明:hadoop分布式文件系统的两个重要的目录结构,一个是namenode上名字空间的存放地方,一个是datanode数据块的存放地方,还有一些其他的文件存放地方,这些存放地方都是基于hadoop.tmp.dir目录的,比如namenode的名字空间存放地方就是 ${hadoop.tmp.dir}/dfs/name,datanode数据块的存放地方就是${hadoop.tmp.dir}/dfs/data,所以设置好hadoop.tmp.dir目录后,其他的重要目录都是在这个目录下面,这是一个根目录。我设置的是 /usr/local/hadoop/hadoop-0.20.2/hadooptmp,当然这个目录必须是存在的。
4.6. 配置hdfs-site.xml
<?xml version="2.0"?>
<?xml-stylesheet type="text/xsl"href="configuration.xsl"?>
<!-- Put site-specific property overridesin this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
"hdfs-site.xml" 15L, 331C
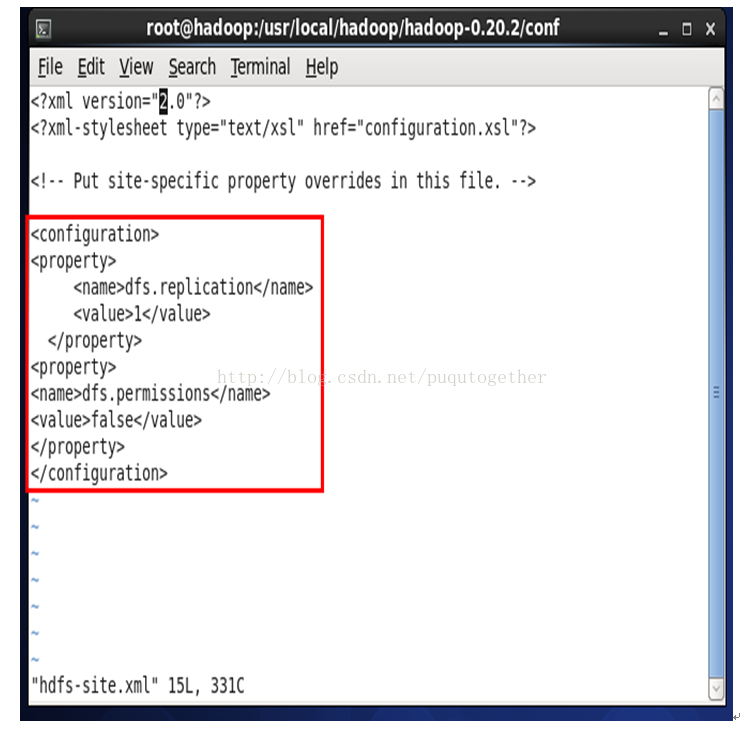
(note:其中dfs.replication的value为1是因为我们这里配置的是单机伪分布式,只有一台机子~后面的dfs.permissions是为了让用户有权限~)
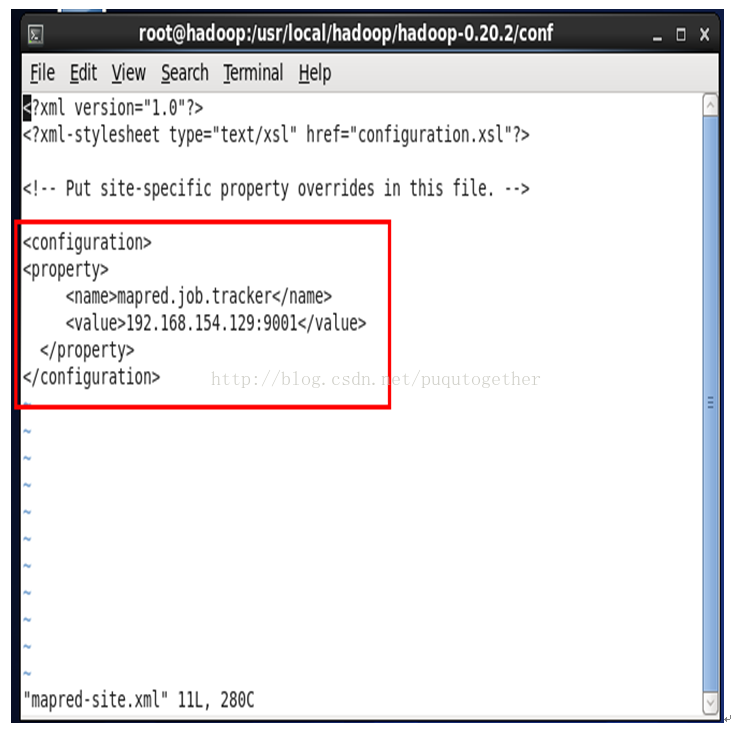
4.7. 配置mapred-site.xml
[root@master conf]# vi mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheettype="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overridesin this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>192.168.154.129:9001</value>
</property>
</configuration>
如下图:
4.8. masters文件和slaves文件(一般此二文件的默认内容即为下述内容,无需重新配置)
[root@hadoop conf]# vi masters
192.168.154
[root@hadoop conf]# vi slaves
192.168.154
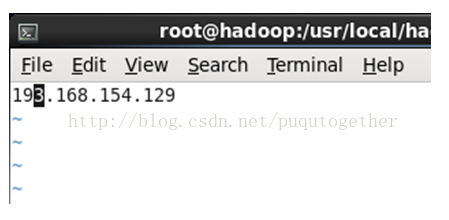
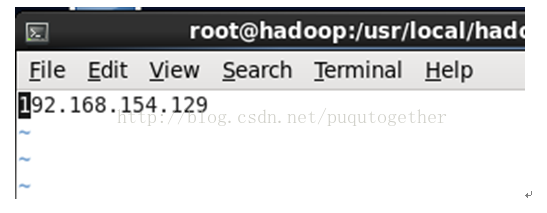
注:因为在伪分布模式下,作为master的namenode与作为slave的datanode是同一台服务器,所以配置文件中的ip是一样的。
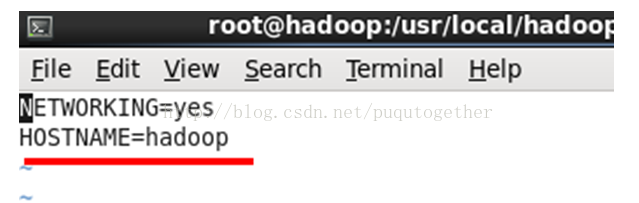
4.9. 主机名和IP解析配置 (这一步非常重要!!!)
首先[root@hadoop~]# vi /etc/hosts,
然后[root@hadoop~]# vi /etc/hostname,
最后[root@hadoop~]# vi /etc/sysconfig/network。
说明:这三个位置的配置必须协调一致,Hadpoop才能正常工作!主机名的配置非常重要!
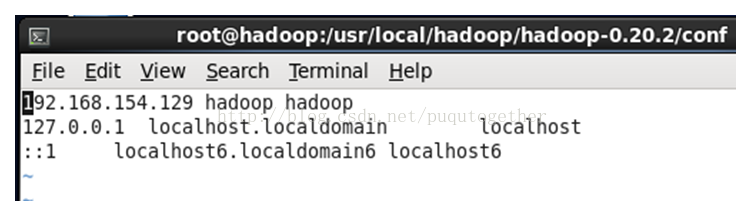
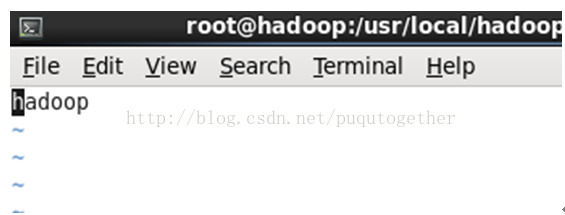
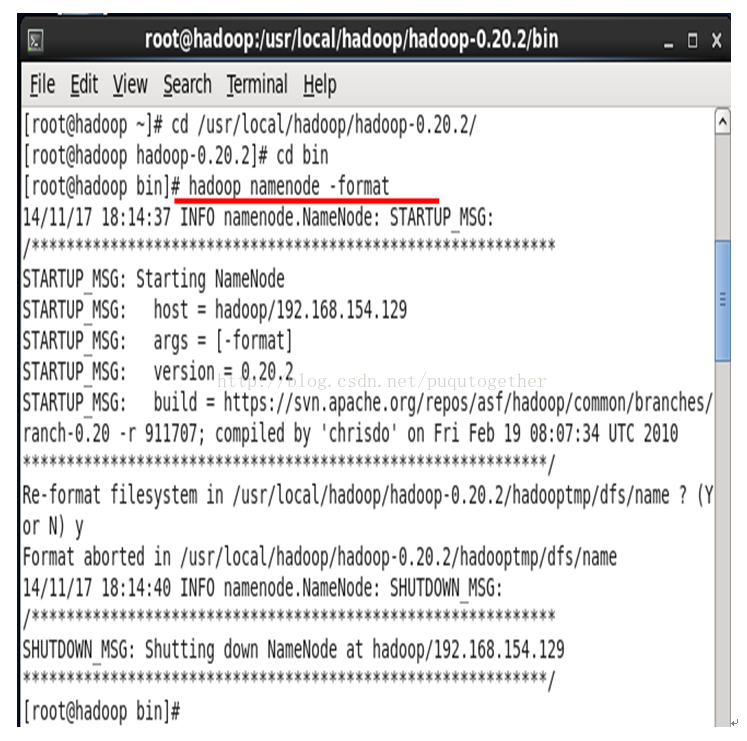
4.9. 启动hadoop
进入 /usr/local/hadoop/hadoop-0.20.2/bin目录下,输入hadoop namenode -format格式化namenode。
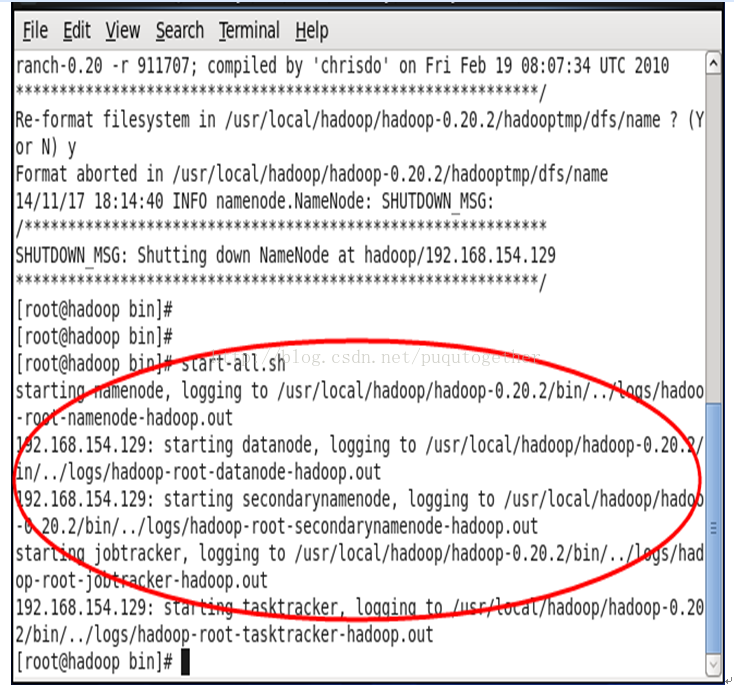
启动hadoop所有进程,输入start-all.sh:
验证hadoop有没有起来,输入jps:
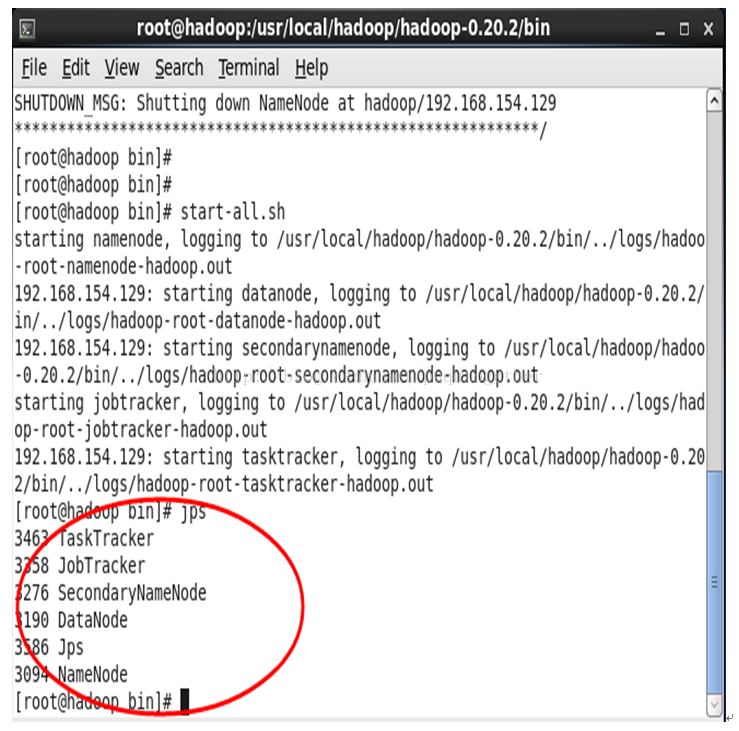
如果红圈中的Tasktracker, JobTracker, DataNode, Namenode都起来了,说明你的hadoop安装成功!
说明:1.secondaryname是namenode的一个备份,里面同样保存了名字空间和文件到文件块的map关系。建议运行在另外一台机器上,这样master死掉之后,还可以通过secondaryname所在的机器找回名字空间,和文件到文件块得map关系数据,恢复namenode。
2.启动之后,在/usr/local/hadoop/hadoop-1.0.1/hadooptmp 下的dfs文件夹里会生成 data目录,这里面存放的是datanode上的数据块数据,因为笔者用的是单机,所以name 和 data 都在一个机器上,如果是集群的话,namenode所在的机器上只会有name文件夹,而datanode上只会有data文件夹。
5)windows下安装jdk和eclipse,并将eclipse与centos下的hadoop连接;
在windows下安装jdk这个很简单,之间下载windows下的jdk安装即可。Eclipse直接把安装包解压即可使用。我们主要说一下如何将eclipse与hadoop连接。
5.1.首先在要关闭linux的防火墙;
连接之前要关闭linux的防火墙,不然在eclipse的project中会一直提示“listing folder content…”,导致连接不上。关闭防火墙的方法如下:
输入命令:chkconfig iptables off,然后reboot重启即可。
重启之后,输入命令:/etc.init.d/iptables status就可以查看防火墙关闭的状态了。(显示“iptables: Firewall is not running.”)
5.2.插件安装和配置eclipse参数
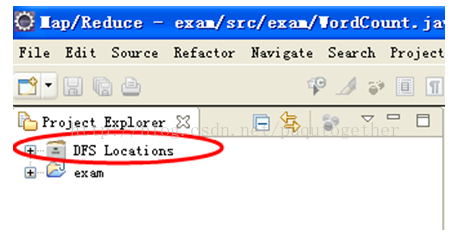
下载插件hadoop-eclipse-plugin-0.20.3-SNAPSHOT,放到eclipse下的plugins文件夹中,重启eclipse就可以找到project explorer一栏中的DFS locations。如下图:
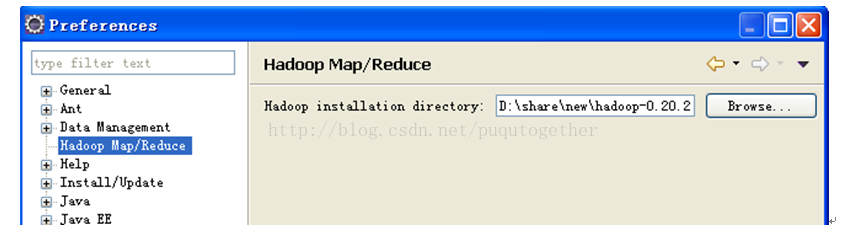
在windows- preferences中会多出一个hadoopmap/reduce选项,选中这个选项,然后把下载的hadoop根目录选中。
在视图中打开map/reducelocation,你会发现在下面的Location区域会出现黄色大象图标。在Loctaion空白区域,右击:New Hadoop Location…
配置general的参数,具体如下:
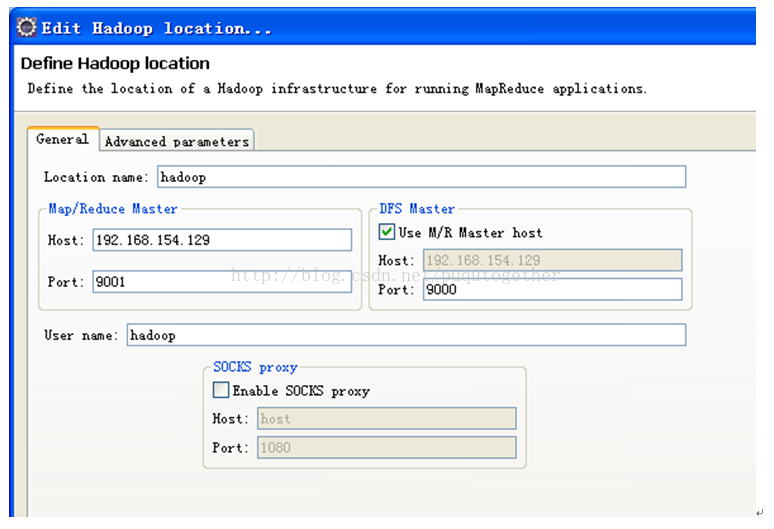
点击finish,关闭eclipse,再重启eclipse,会发现在Location区域有一个紫色的大象,右击它edit,配置Advanced parameters的参数。(注意,这儿不断关闭、重启eclipse的过程一定要严格执行,不然在advanced parameters页会有一些参数不出来~)
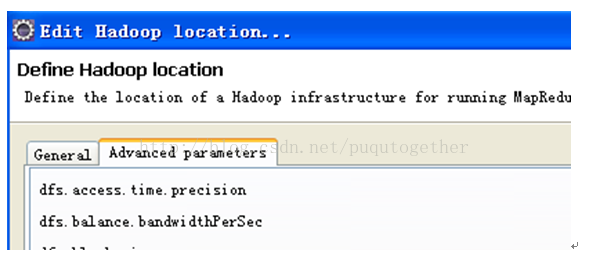
设置advancedparameters页的参数是最耗费时间的,总共需要修改3个参数,当时一开始的时候发现它的页面下找不到:
第一个参数:hadoop.tmp.dir。这个默认是/tmp/hadoop-{user.name},因为我们在ore-defaulte.xml 里hadoop.tmp.dir设置的是/usr/local/hadoop/hadoop-0.20.2/hadooptmp,所以这里我们也改成/usr/local/hadoop/hadoop-0.20.2/hadooptmp,其他基于这个目录属性也会自动改;
第二个参数:dfs.replication。这个这里默认是3,因为我们再hdfs-site.xml里面设置成了1,所以这里也要设置成1;
第三个参数:hadoop.job.ugi。这里要填写:hadoop,Tardis,逗号前面的是连接的hadoop的用户,逗号后面就写Tardis。
(note:这里要说一下,一般而言第一个参数hadoop.tmp.dir很好出来,你按照前面的步骤重启eclipse,在advanced paramters页面就可以直接找到它,修改即可;后面两个参数比较难出来,其中hadoop.job.ugi参数,一定要保证linux的用户名和windows的用户名相同才会有,不然是找不到的。直到现在我也不知道为什么有的时候就是找不到这两个参数,只有多关闭-重启eclipse几次,多试一试,网上的教程一直没有涉及到这个情况)
5.3.project目录下会展示hadoop的hdfs的文件目录
按照上面设置好之后,我们会在project中发现hadoop中最重要的hdfs目录已经展示出来了。如下图:
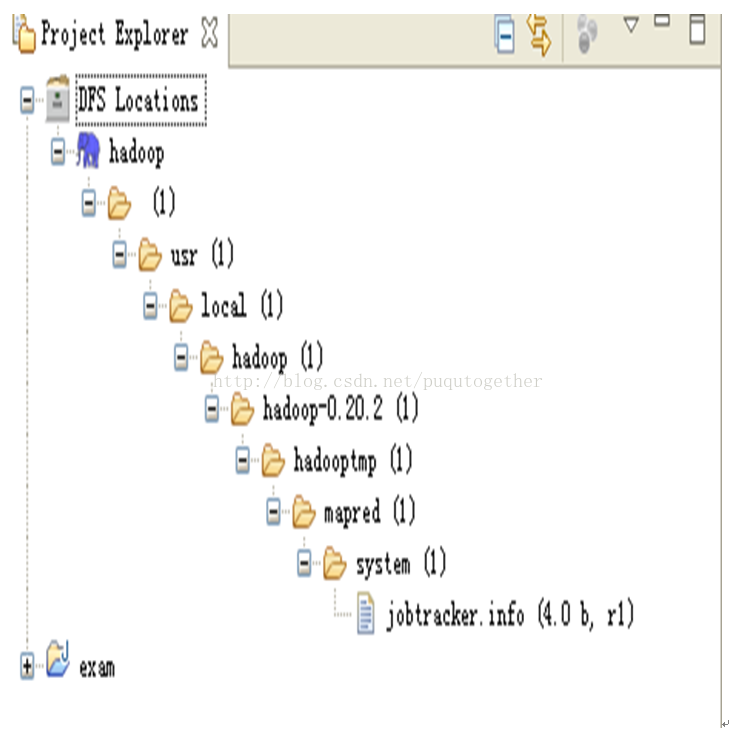
至此,hadoop与eclipse就成功的连接上了。我们的教程也就完整结束,下一次我们再说说怎么让eclipse上的WordCount程序,放在hadoop中运行。
(责任编辑:IT)
许久之前就计划学习hadoop了,直到最近才提上日程。花费了一些时间才把centos下的hadoop搭起来,前后经历的“挫折”绝对可以写成数千字的血泪史了。既有被网上教程坑了的苦逼遭遇,也有教研室大超师兄和实习公司的泡哥的爱心支援。今天终于可以坐下来说说如何在Centos下安装hadoop并与Eclipse连接这个问题。 先说一下要准备哪些软件和信息: VMware-workstation; CentOS-6.0-i386-bin-DVD; eclipse-jee-luna-SR1-win32; hadoop-0.20.2; jdk-6u27-linux-i586; (由于hadoop对版本的要求较高,大家还是不要轻易更换版本,这里列出来的各种软件都是稳定发布版,网上很容易可以download到的)。
整个教程分为这样5个部分来说:1)在Windows下安装虚拟机Vmware,并新建一个虚拟机装好centos系统;2)centos下设置ssh服务无密码登录;3)centos下安装jdk,并配置环境变量;4)centos下安装hadoop,并配置文件;5)windows下安装jdk和eclipse,并将eclipse与centos下的hadoop连接。可以说这5个部分每一个都很重要,尤其是第4)步。下面我们就详细说一下每一步该怎么做。 Step 0: 请大家先在windows下新建一个普通用户,用户名为hadoop,我们所有的软件全在这个下面安装,用户名最好要是hadoop,因为这个要和后面很多username相同,设为hadoop比较好记。
1)在Windows下安装虚拟机Vmware,并新建一个虚拟机装好centos系统;首先,下载VMware-workstation并安装,这步骤和一般windows下安装软件的过程是一样的,入门小白也会熟练操作,这里就节省点儿空间给后面重要的步骤了~ 然后,在Vmware的主页上新建一个虚拟机,如下图:
一路下一步,直到让你选择系统镜像路径,我们选择centos系统映像,如上图,点击下一步。然后,需要你输入linux的用户名,这个比较重要,最好填写hadoop,因为这个名字在后面要用到好多次!
后面还是一路的“下一步”,直到让你设置虚拟机的内存大小,建议为1024M。如上图。后面就是要选择和虚拟机的网络类型有关的设置了,建议为“使用网络地址转换NAT”,如下图。这一步我当时选择了自动桥接的功能,找了一个晚上的错误。。。时间就这样白花花的没了~~
之后还是一路的“下一步”,几乎都是使用它推荐的设置,我们就可以新建一个centos,等待个几分钟然后就可以进入centos界面了。看到那一抹科技蓝,有没有让你心动了呢~~哈哈哈,你确实走好了第一步! 2)centos下设置ssh服务无密码登录;在桌面右击,选择openin Terminal,这个就是linux的终端了。希望读者有一些linux操作系统的基础,这样子上手更快一些。不过要是没有的话,也没有关系,我们是面向新手的教程。
2.1. 先在linux命令行中输入su,提示密码,输入你自己设置的密码,这样子你后面的操作都具有了linux系统下的最高权限——root权限。 2.2. 在设置ssh无密码登录之前,有一个特别重要的要先出好:关闭SELinux。这是因为centos会自动阻止你修改sshservice,我们只有关闭SELinux,重启才能生效。如何做,如下: 修改/etc/selinux/config文件 将SELINUX=enforcing改为SELINUX=disabled 重启机器即可 (note:在linux下修改文件,vi命令后会进入到文件窗口,按i进入insert,修改完毕之后再按esc推出insert,输入;:wq!保存并退出~这里要感谢泡哥,改了半天都不行,还是泡哥指点迷津了~~)
2.3. 在linux命令行里输入:ssh-keygen -t rsa,然后一路回车。 root@hadoopName-desktop:~$ssh-keygen -t rsa Generating public/private rsakey pair. Enterfile in which to save the key (/home/zhangtao/.ssh/id_rsa): //密钥保存位置,直接回车保持默认; Createddirectory '/home/zhangtao/.ssh'. Enter passphrase(empty for no passphrase): //设置密钥的密码,空密码直接回车即可; Enter samepassphrase again: //确认上一步设置的密码。 然后进入 /root/.ssh/下面,会看到两个文件 id_rsa.pub,id_rsa, 然后执行cp id_rsa.pub authorized_keys 然后 ssh localhost 验证是否成功,第一次要你输入yes,以后就不需要了。 如下图,由于我又验证了一次,所以还需要输入y,如果你是第一次验证是不要的。
至此,ssh服务无密码登录设置完毕! 3)centos下安装jdk,并配置环境变量;这一步中可以分为两步:安装jdk、配置jdk环境变量。 3.1. 第一步:root 用户登陆,使用命令mkdir /usr/program新建目录/usr/program ,下载 JDK 安装包jdk-6u13-linux-i586.bin,将其复制到目录/usr/program下,用cd命令进入该目录,执行命令“./ jdk-6u13-linux-i586.bin”,命令运行完毕即安装完成,将在目录下生成文件夹/jdk1.6.0_13,此即为jdk被成功安装到目录:/usr/program/jdk1.6.0_13下。 3.2. root 用户登陆,命令行中执行命令“vi/etc/profile”,并加入以下内容,配置环境变量(注意/etc/profile这个文件很重要,后面 Hadoop 的配置还会用到)。 # set java environment exportJAVA_HOME=/usr/program/jdk1.6.0_27 exportJRE_HOME=/usr/program/jdk1.6.0_27/jre export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH 在vi编辑器增加以上内容后保存退出,并执行以下命令使配置生效! #chmod +x /etc/profile ;增加执行权限 #source /etc/profile;使配置生效! 配置完毕后,在命令行中输入:java -version,就会出现安装jdk的信息。
这时,jdk的安装和配置环境变量就成功了~ 4)centos下安装hadoop,并配置文件;4.1.安装hadoop之前要先知道你的centos中的ip地址:在终端中输入ifconfig就可以查看ip地址了。如下图:(我的是192.168.154.129)
4.2.下载 hadoop-0.20.2.tar.gz,将其拷贝到/usr/local/hadoop 目录下,然后在该目录/usr/local/hadoop下解压安装生成文件/hadoop-0.20.2(即为hadoop被安装到/usr/local/hadoop/ hadoop-0. 20.2文件夹下)。 命令如下: tar -zxvf hadoop-0.20.2.tar.gz 解压安装一步完成! 4.3.首先配置hadoop的环境变量 命令“vi /etc/profile” #set hadoop export HADOOP_HOME=/usr/hadoop/hadoop-0.20.2 export PATH=$HADOOP_HOME/bin:$PATH 命令:source /etc/profile 使刚配置的文件生效! 进入/usr/local/hadoop/hadoop-0.20.2/conf,配置Hadoop配置文件 4.4. 配置hadoop-env.sh文件 打开文件命令:vihadoop-env.sh 添加 # set javaenvironment export JAVA_HOME=/usr/program/jdk1.6.0_27 编辑后保存退出(提示,输入:wq!)。其实仔细找一下就会发现hadoop-env.sh文件中本身就有JAVA_HOME这行,我们只需要把前面的注释#取消,然后修改HOME的地址就好。如下图所示:
4.5. 配置core-site.xml [root@master conf]# vi core-site.xml <?xml version="1.0"?> <?xml-stylesheettype="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overridesin this file. --> <configuration> <property> <name>fs.default.name</name> <value>hdfs://192.168.154.129:9000/</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/hadoop-0.20.2/hadooptmp</value> </property> </configuration> (note:hdfs后面的一定要是你的centos的IP地址,这就是为什么要在上面先ifconfig得到ip地址的原因。有些教程说的那种localhost,是不正确的!后面和eclipse会连接不上!!这里又消耗了一个晚上的时间。。。) 如下图所示:
说明:hadoop分布式文件系统的两个重要的目录结构,一个是namenode上名字空间的存放地方,一个是datanode数据块的存放地方,还有一些其他的文件存放地方,这些存放地方都是基于hadoop.tmp.dir目录的,比如namenode的名字空间存放地方就是 ${hadoop.tmp.dir}/dfs/name,datanode数据块的存放地方就是${hadoop.tmp.dir}/dfs/data,所以设置好hadoop.tmp.dir目录后,其他的重要目录都是在这个目录下面,这是一个根目录。我设置的是 /usr/local/hadoop/hadoop-0.20.2/hadooptmp,当然这个目录必须是存在的。 4.6. 配置hdfs-site.xml <?xml version="2.0"?> <?xml-stylesheet type="text/xsl"href="configuration.xsl"?> <!-- Put site-specific property overridesin this file. --> <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration> "hdfs-site.xml" 15L, 331C
(note:其中dfs.replication的value为1是因为我们这里配置的是单机伪分布式,只有一台机子~后面的dfs.permissions是为了让用户有权限~) 4.7. 配置mapred-site.xml [root@master conf]# vi mapred-site.xml <?xml version="1.0"?> <?xml-stylesheettype="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overridesin this file. --> <configuration> <property> <name>mapred.job.tracker</name> <value>192.168.154.129:9001</value> </property> </configuration> 如下图:
4.8. masters文件和slaves文件(一般此二文件的默认内容即为下述内容,无需重新配置) [root@hadoop conf]# vi masters 192.168.154 [root@hadoop conf]# vi slaves 192.168.154
注:因为在伪分布模式下,作为master的namenode与作为slave的datanode是同一台服务器,所以配置文件中的ip是一样的。 4.9. 主机名和IP解析配置 (这一步非常重要!!!) 首先[root@hadoop~]# vi /etc/hosts, 然后[root@hadoop~]# vi /etc/hostname, 最后[root@hadoop~]# vi /etc/sysconfig/network。 说明:这三个位置的配置必须协调一致,Hadpoop才能正常工作!主机名的配置非常重要!
4.9. 启动hadoop 进入 /usr/local/hadoop/hadoop-0.20.2/bin目录下,输入hadoop namenode -format格式化namenode。
启动hadoop所有进程,输入start-all.sh:
验证hadoop有没有起来,输入jps:
如果红圈中的Tasktracker, JobTracker, DataNode, Namenode都起来了,说明你的hadoop安装成功! 说明:1.secondaryname是namenode的一个备份,里面同样保存了名字空间和文件到文件块的map关系。建议运行在另外一台机器上,这样master死掉之后,还可以通过secondaryname所在的机器找回名字空间,和文件到文件块得map关系数据,恢复namenode。 2.启动之后,在/usr/local/hadoop/hadoop-1.0.1/hadooptmp 下的dfs文件夹里会生成 data目录,这里面存放的是datanode上的数据块数据,因为笔者用的是单机,所以name 和 data 都在一个机器上,如果是集群的话,namenode所在的机器上只会有name文件夹,而datanode上只会有data文件夹。
5)windows下安装jdk和eclipse,并将eclipse与centos下的hadoop连接;在windows下安装jdk这个很简单,之间下载windows下的jdk安装即可。Eclipse直接把安装包解压即可使用。我们主要说一下如何将eclipse与hadoop连接。 5.1.首先在要关闭linux的防火墙; 连接之前要关闭linux的防火墙,不然在eclipse的project中会一直提示“listing folder content…”,导致连接不上。关闭防火墙的方法如下: 输入命令:chkconfig iptables off,然后reboot重启即可。 重启之后,输入命令:/etc.init.d/iptables status就可以查看防火墙关闭的状态了。(显示“iptables: Firewall is not running.”) 5.2.插件安装和配置eclipse参数 下载插件hadoop-eclipse-plugin-0.20.3-SNAPSHOT,放到eclipse下的plugins文件夹中,重启eclipse就可以找到project explorer一栏中的DFS locations。如下图:
在windows- preferences中会多出一个hadoopmap/reduce选项,选中这个选项,然后把下载的hadoop根目录选中。 在视图中打开map/reducelocation,你会发现在下面的Location区域会出现黄色大象图标。在Loctaion空白区域,右击:New Hadoop Location… 配置general的参数,具体如下:
点击finish,关闭eclipse,再重启eclipse,会发现在Location区域有一个紫色的大象,右击它edit,配置Advanced parameters的参数。(注意,这儿不断关闭、重启eclipse的过程一定要严格执行,不然在advanced parameters页会有一些参数不出来~)
设置advancedparameters页的参数是最耗费时间的,总共需要修改3个参数,当时一开始的时候发现它的页面下找不到: 第一个参数:hadoop.tmp.dir。这个默认是/tmp/hadoop-{user.name},因为我们在ore-defaulte.xml 里hadoop.tmp.dir设置的是/usr/local/hadoop/hadoop-0.20.2/hadooptmp,所以这里我们也改成/usr/local/hadoop/hadoop-0.20.2/hadooptmp,其他基于这个目录属性也会自动改; 第二个参数:dfs.replication。这个这里默认是3,因为我们再hdfs-site.xml里面设置成了1,所以这里也要设置成1;
第三个参数:hadoop.job.ugi。这里要填写:hadoop,Tardis,逗号前面的是连接的hadoop的用户,逗号后面就写Tardis。
(note:这里要说一下,一般而言第一个参数hadoop.tmp.dir很好出来,你按照前面的步骤重启eclipse,在advanced paramters页面就可以直接找到它,修改即可;后面两个参数比较难出来,其中hadoop.job.ugi参数,一定要保证linux的用户名和windows的用户名相同才会有,不然是找不到的。直到现在我也不知道为什么有的时候就是找不到这两个参数,只有多关闭-重启eclipse几次,多试一试,网上的教程一直没有涉及到这个情况) 5.3.project目录下会展示hadoop的hdfs的文件目录 按照上面设置好之后,我们会在project中发现hadoop中最重要的hdfs目录已经展示出来了。如下图:
至此,hadoop与eclipse就成功的连接上了。我们的教程也就完整结束,下一次我们再说说怎么让eclipse上的WordCount程序,放在hadoop中运行。 (责任编辑:IT) |