centos安装配置hadoop超详细过程
时间:2014-11-21 12:09 来源:linux.it.net.cn 作者:IT
1、集群部署介绍
1.1 Hadoop简介

Hadoop是Apache软件基金会旗下的一个开源分布式计算平台。以Hadoop分布式文件系统(HDFS,Hadoop Distributed Filesystem)和MapReduce(Google MapReduce的开源实现)为核心的Hadoop为用户提供了系统底层细节透明的分布式基础架构。
对于Hadoop的集群来讲,可以分成两大类角色:Master和Salve。一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件系统的访问操作;集群中的DataNode管理存储的数据。MapReduce框架是由一个单独运行在主节点上的JobTracker和运行在每个集群从节点的TaskTracker共同组成的。主节点负责调度构成一个作业的所有任务,这些任务分布在不同的从节点上。主节点监控它们的执行情况,并且重新执行之前的失败任务;从节点仅负责由主节点指派的任务。当一个Job被提交时,JobTracker接收到提交作业和配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控TaskTracker的执行。
1.2 环境说明
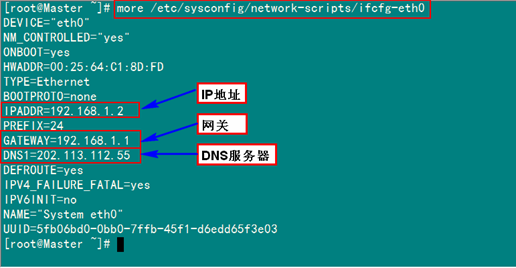
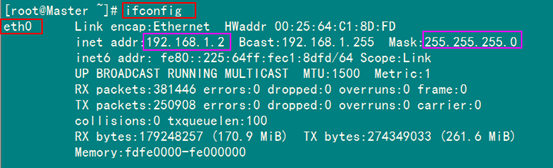
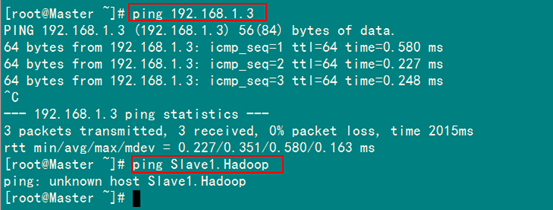
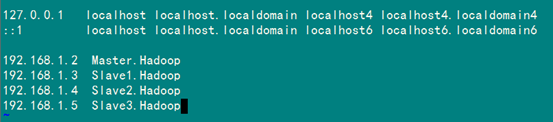
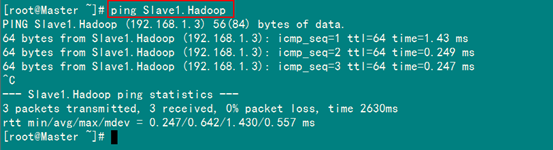
1.3 网络配置
1.4 所需软件
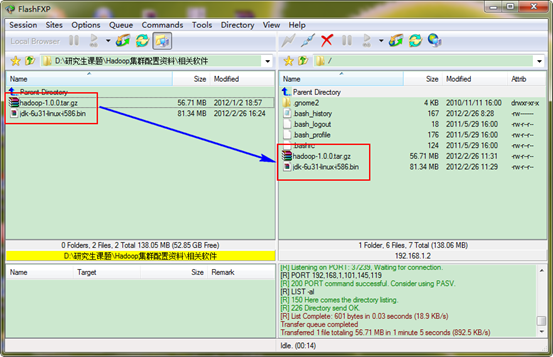
1.5 VSFTP上传
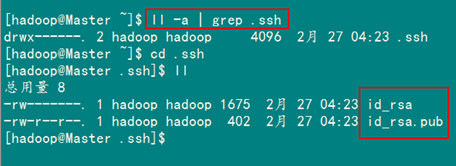
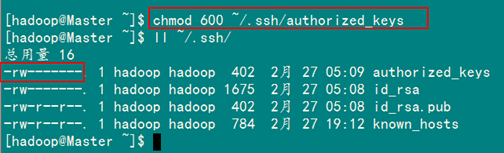
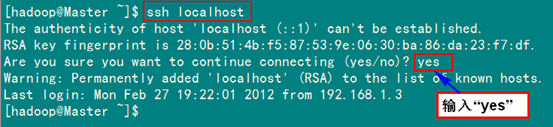
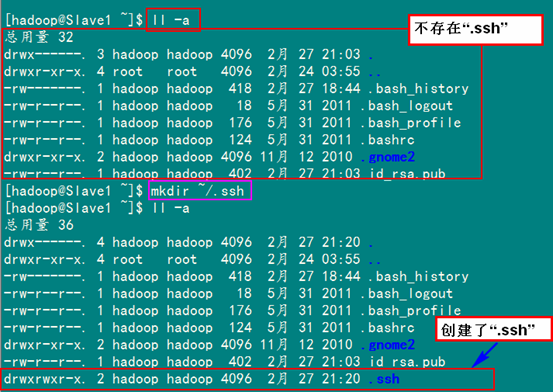
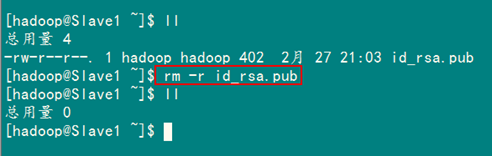
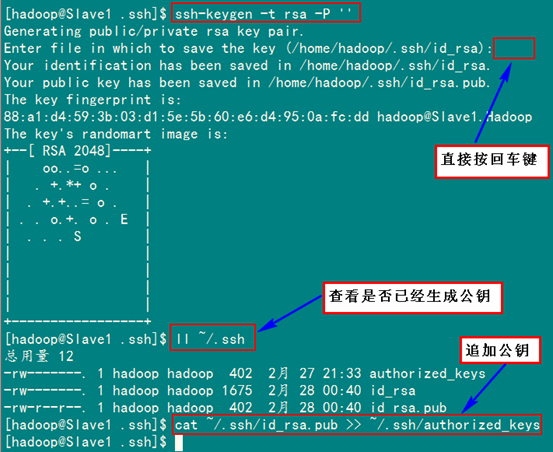
2、SSH无密码验证配置
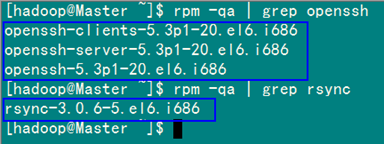
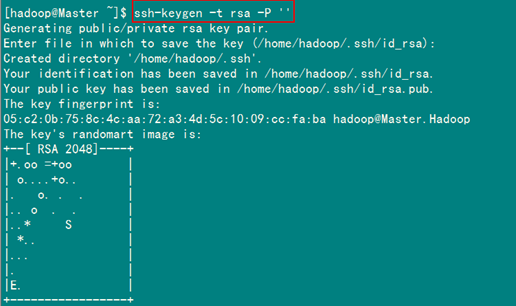
2.1 安装和启动SSH协议
2.2 配置Master无密码登录所有Salve
2.3 配置所有Slave无密码登录Master
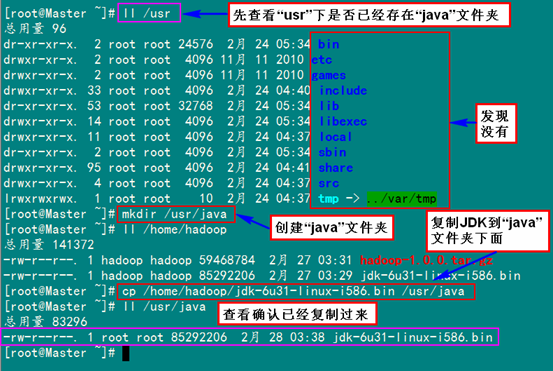
3、Java环境安装
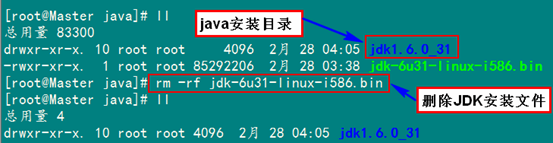
3.1 安装JDK
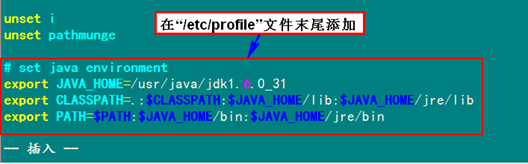
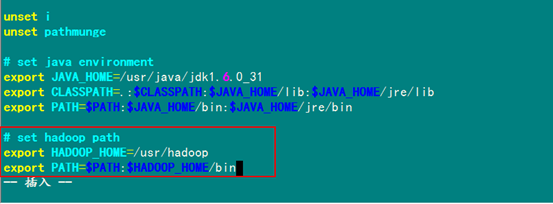
3.2 配置环境变量
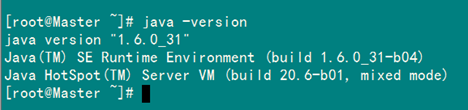
3.3 验证安装成功
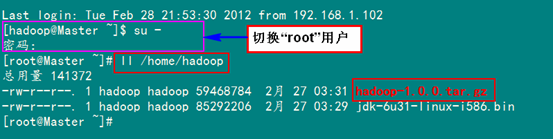
3.4 安装剩余机器
4、Hadoop集群安装
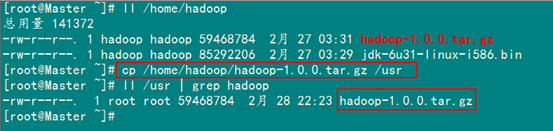
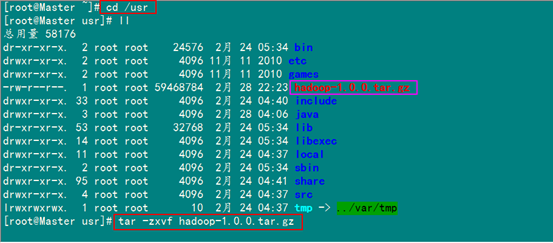
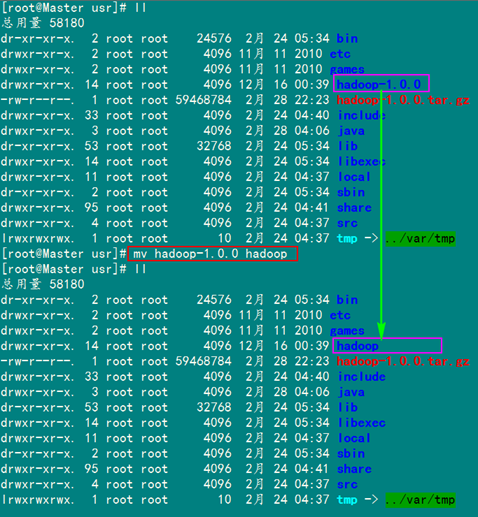
4.1 安装hadoop
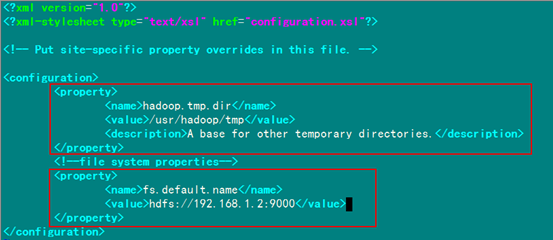
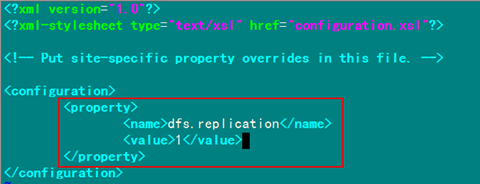
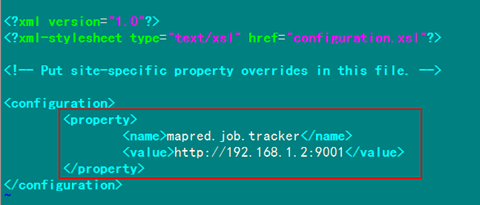
4.2 配置hadoop
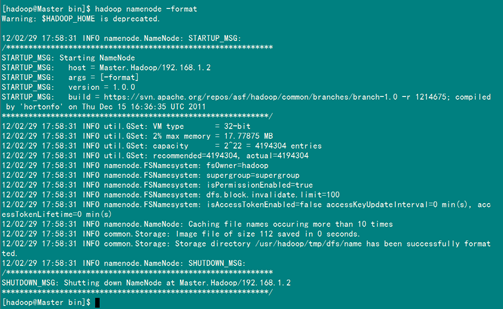
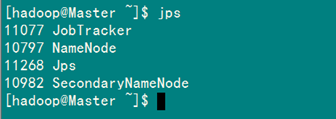
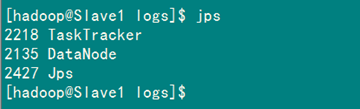
4.3 启动及验证
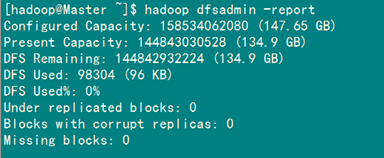
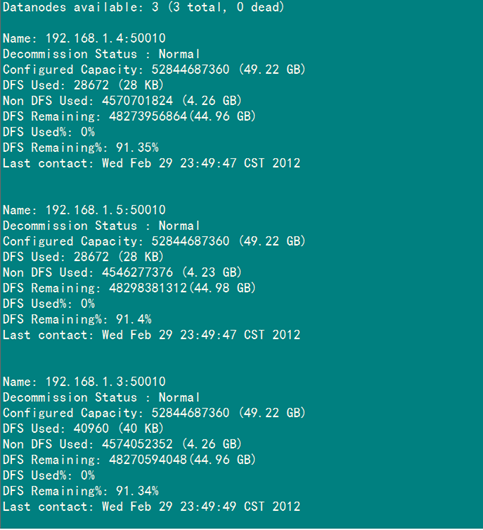
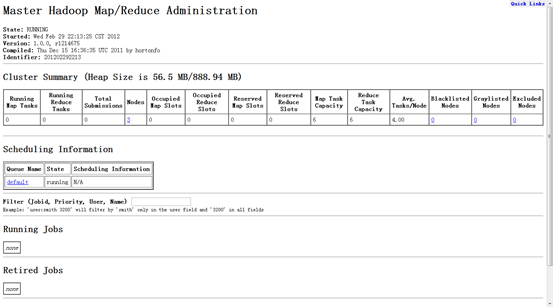
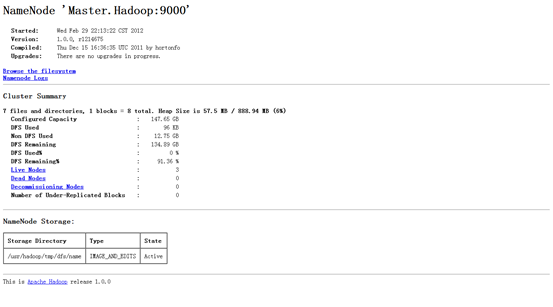
4.4 网页查看集群
5、常见问题FAQ
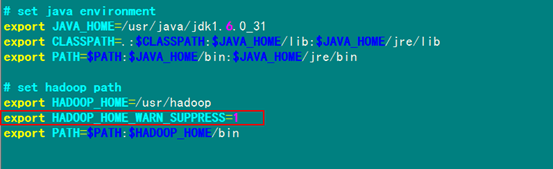
5.1 关于 Warning: $HADOOP_HOME is deprecated.
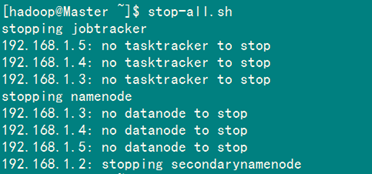
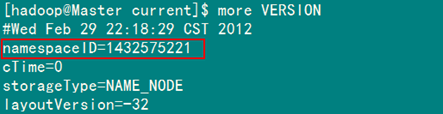
5.2 解决"no datanode to stop"问题
5.3 Slave服务器中datanode启动后又自动关闭
5.4 从本地往hdfs文件系统上传文件
5.5 安全模式导致的错误
5.6 解决Exceeded MAX_FAILED_UNIQUE_FETCHES
5.7 解决"Too many fetch-failures"
5.8 处理速度特别的慢
5.9解决hadoop OutOfMemoryError问题
5.10 Namenode in safe mode
5.11 IO写操作出现问题
5.12 status of 255 error
6、用到的Linux命令
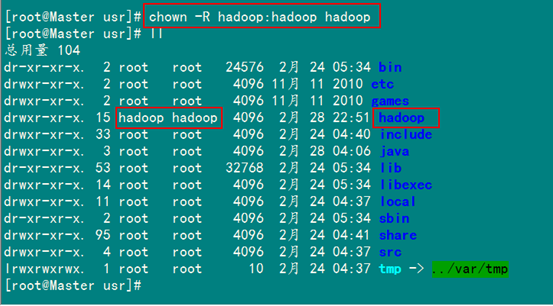
6.1 chmod命令详解
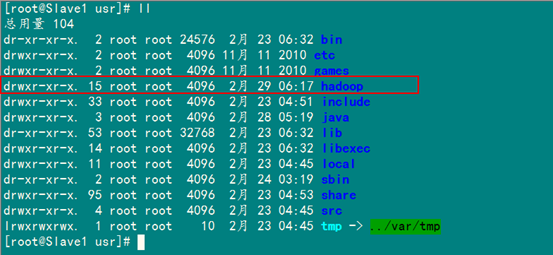
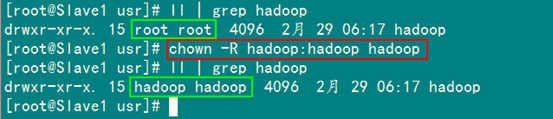
6.2 chown命令详解
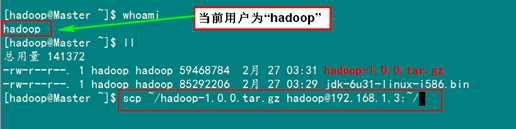
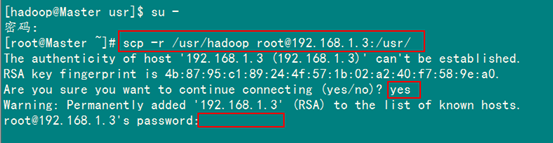
6.3 scp命令详解
(责任编辑:IT)
1、集群部署介绍
1.1 Hadoop简介
对于Hadoop的集群来讲,可以分成两大类角色:Master和Salve。一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件系统的访问操作;集群中的DataNode管理存储的数据。MapReduce框架是由一个单独运行在主节点上的JobTracker和运行在每个集群从节点的TaskTracker共同组成的。主节点负责调度构成一个作业的所有任务,这些任务分布在不同的从节点上。主节点监控它们的执行情况,并且重新执行之前的失败任务;从节点仅负责由主节点指派的任务。当一个Job被提交时,JobTracker接收到提交作业和配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控TaskTracker的执行。 1.2 环境说明1.3 网络配置
(责任编辑:IT) |