|
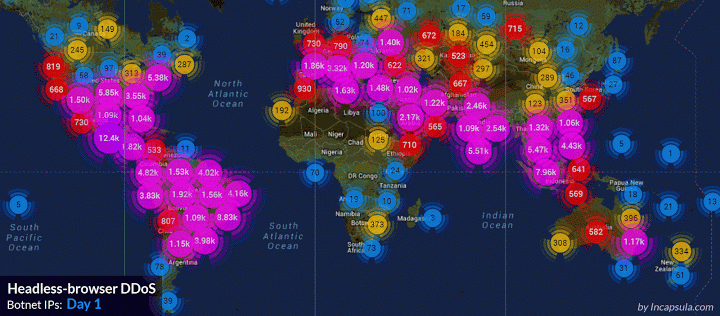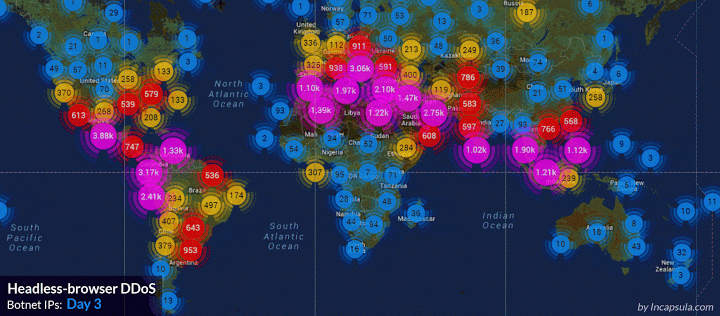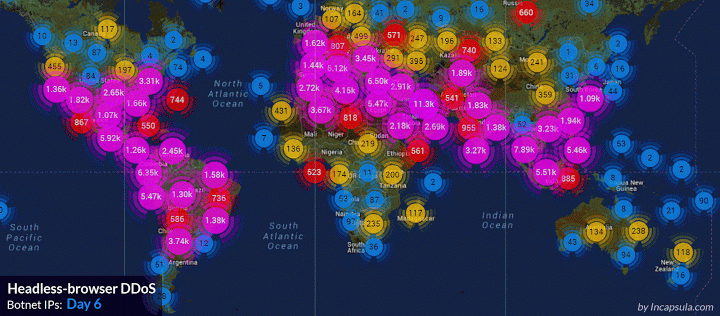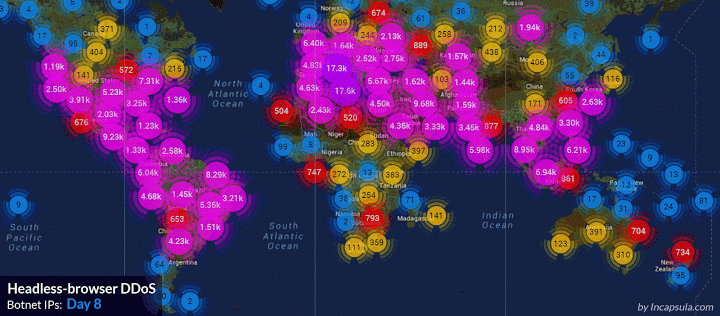
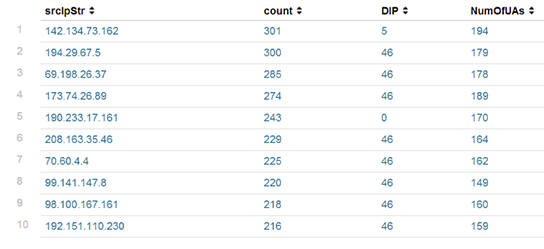
基于浏览器的僵尸网络就是DDoS世界里的T-1000s。他们之所以如此危险是因为他们就跟终结者里的反派一样,被设计的可以适应各种情况的攻击。当其他原始的网络僵尸还在暴力破解你的防御的时候,基于浏览器的僵尸就已经模拟真实的人类从前门进入了。 当你意识到情况不对时,他们已经突破边界,搞宕服务器,已经无力回天了。 那么应该怎么防御T-1000呢,怎么分辨一次访问是来自与真实的浏览器还是一个基于浏览器的僵尸?传统的过滤僵尸的策略在面对能够保存cookie和执行javascript的僵尸时都失效了。而不分青红皂白地让所有用户都填写验证码无异于自我毁灭,尤其是当这种攻击可能持续数个星期的时候。 为了研究防御方法,我们来看一个真实的案例: 这次攻击是一个未知的僵尸网络发起的。这些基于浏览器的僵尸可以保存cookie,执行javascript。攻击的早期我们识别出是PhantomJS无界面浏览器。 PhanomJS是一套开发无界面浏览器的工具。它提供所有浏览器的功能但是没有界面,没有按钮,没有地址栏。一般被用在自动化测试和网络监控上。 这次攻击持续了150个小时以上。这个过程中,我们记录了全球超过180000个恶意IP。高峰期每秒6000次攻击,平均一天有690000000次以上。攻击IP的数量和分布范围让我们觉得这应该不仅仅是一个僵尸网络,而是可能整合了多个。下图是攻击ip的地理分布。
攻击过程中我们截获了861个不同的user-agent。攻击者修改了头部的结构试图绕过我们的防御。 下图是攻击最多的ip:
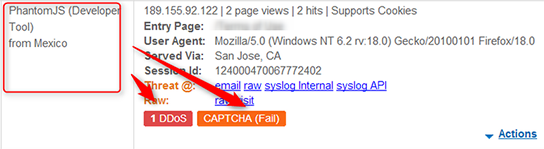
有趣的是攻击者除了使用模拟浏览器的僵尸,还试图模拟人类的行为来躲避基于行为检测的安全规则。这些僵尸会先访问不同的页面,然后像人类那样访问一些随机的页面,最后才会聚集在一起消耗资源。 尽管基于浏览器的僵尸能够突破传统的过滤。但是由于它使用了一个已知的无界面浏览器,这样子就可以通过我们的客户端分类机制检测到。 我们的客户端分类机制基于我们已经收集的大量信息总结出来的签名。发生这次攻击的时候,我们的信息库已经有超过10000000个签名。每一个签名都包括: User-agent IPs and ASN info HTTP Headers JavaScript footprint Cookie/Protocol support variations 我们不仅仅收集一些明显的信息,比如user-agent,还收集一些浏览器之间复杂的细微差别。安全的对抗是封闭的,所以不说一些技术细节的话很难把这个机制解释清楚。稍微说一点,我们会寻找浏览器处理编码方面细微的差别,比如,我们通过浏览器处理HTTP头里两次空格和特殊字符来区别不同的浏览器。 所以我们的数据库里有成千上万个已知的浏览器和僵尸签名,覆盖各种场景。在这个案例中,攻击者的武器PhantomJS webkit当然也是我们签名库中的一个。
当攻击者在规划如何让他的僵尸看起来更像人类的时候,我们的团队必须做的就是让我们的系统发现攻击者用的无界面浏览器是哪一种。之后我们做的就是简单的屏蔽了所有的PhantomJS的实例。我们甚至留了一个备选,让用户填一个验证码,以免屏蔽掉了真正的人类访问。 不出意料的,没有验证码被填写。
几天之后,当我们已经完全依靠机器识别,不需要人工干预了。攻击者依然在使用新的user-agent和新的ip试图绕过防御。但是所有残忍的T-1000s都已经被我们冰冻起来了。他们使用的方法,签名,模式都已经被记录下来作为将来的参考。 (责任编辑:IT) |