|
本文着重介绍sharding的基本思想和理论上的切分策略,关于更加细致的实施策略和参考事例请参考我的另一篇博文:数据库分库分表(sharding)系列(一) 拆分实施策略和示例演示
一、基本思想
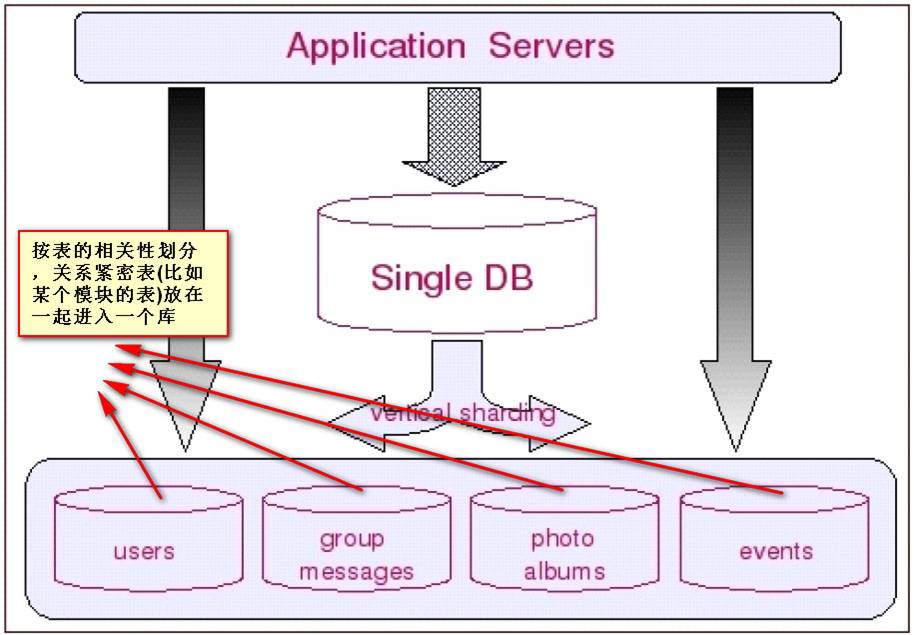
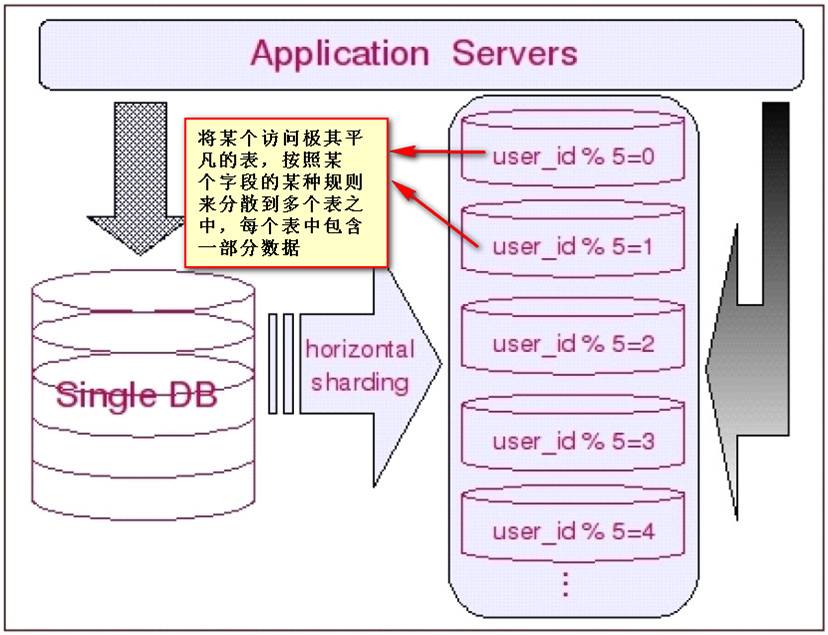
Sharding的基本思想就要把一个数据库切分成多个部分放到不同的数据库(server)上,从而缓解单一数据库的性能问题。不太严格的讲,对于海量数据的数据库,如果是因为表多而数据多,这时候适合使用垂直切分,即把关系紧密(比如同一模块)的表切分出来放在一个server上。如果表并不多,但每张表的数据非常多,这时候适合水平切分,即把表的数据按某种规则(比如按ID散列)切分到多个数据库(server)上。当然,现实中更多是这两种情况混杂在一起,这时候需要根据实际情况做出选择,也可能会综合使用垂直与水平切分,从而将原有数据库切分成类似矩阵一样可以无限扩充的数据库(server)阵列。下面分别详细地介绍一下垂直切分和水平切分.
二、切分策略
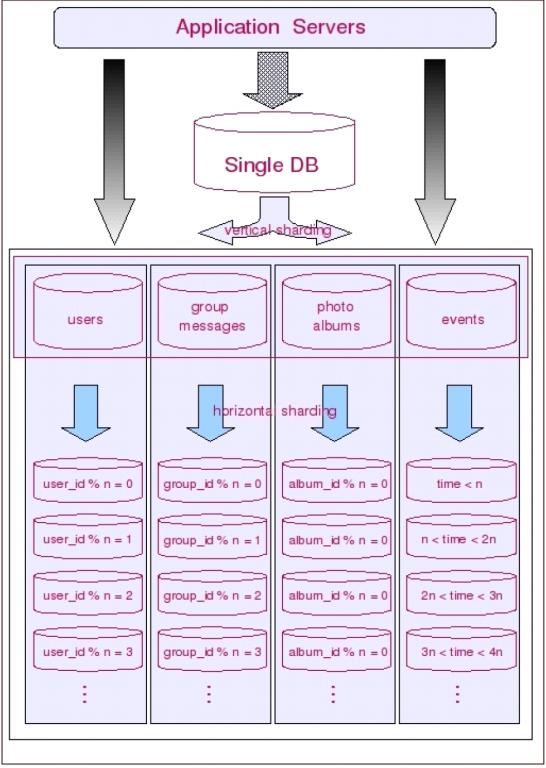
如前面所提到的,切分是按先垂直切分再水平切分的步骤进行的。垂直切分的结果正好为水平切分做好了铺垫。垂直切分的思路就是分析表间的聚合关系,把关系紧密的表放在一起。多数情况下可能是同一个模块,或者是同一“聚集”。这里的“聚集”正是领域驱动设计里所说的聚集。在垂直切分出的表聚集内,找出“根元素”(这里的“根元素”就是领域驱动设计里的“聚合根”),按“根元素”进行水平切分,也就是从“根元素”开始,把所有和它直接与间接关联的数据放入一个shard里。这样出现跨shard关联的可能性就非常的小。应用程序就不必打断既有的表间关联。比如:对于社交网站,几乎所有数据最终都会关联到某个用户上,基于用户进行切分就是最好的选择。再比如论坛系统,用户和论坛两个模块应该在垂直切分时被分在了两个shard里,对于论坛模块来说,Forum显然是聚合根,因此按Forum进行水平切分,把Forum里所有的帖子和回帖都随Forum放在一个shard里是很自然的。
需要特别说明的是:当同时进行垂直和水平切分时,切分策略会发生一些微妙的变化。比如:在只考虑垂直切分的时候,被划分到一起的表之间可以保持任意的关联关系,因此你可以按“功能模块”划分表格,但是一旦引入水平切分之后,表间关联关系就会受到很大的制约,通常只能允许一个主表(以该表ID进行散列的表)和其多个次表之间保留关联关系,也就是说:当同时进行垂直和水平切分时,在垂直方向上的切分将不再以“功能模块”进行划分,而是需要更加细粒度的垂直切分,而这个粒度与领域驱动设计中的“聚合”概念不谋而合,甚至可以说是完全一致,每个shard的主表正是一个聚合中的聚合根!这样切分下来你会发现数据库分被切分地过于分散了(shard的数量会比较多,但是shard里的表却不多),为了避免管理过多的数据源,充分利用每一个数据库服务器的资源,可以考虑将业务上相近,并且具有相近数据增长速率(主表数据量在同一数量级上)的两个或多个shard放到同一个数据源里,每个shard依然是独立的,它们有各自的主表,并使用各自主表ID进行散列,不同的只是它们的散列取模(即节点数量)必需是一致的。( 本文着重介绍sharding的基本思想和理论上的切分策略,关于更加细致的实施策略和参考事例请参考我的另一篇博文:数据库分库分表(sharding)系列(一) 拆分实施策略和示例演示 )
参考资料: 《MySQL性能调优与架构设计》
注:本文图片摘自《MySQL性能调优与架构设计》一 书 (责任编辑:IT) |