 [MySQL] mysql 导入导出数据库以及函数、存储过程的介绍 日期:2019-05-30 16:48:06 点击:172 好评:0
[MySQL] mysql 导入导出数据库以及函数、存储过程的介绍 日期:2019-05-30 16:48:06 点击:172 好评:0
mysql常用导出数据命令: 1.mysql导出整个数据库 mysqldump -hhostname -uusername -ppassword databasename backupfile.sql mysqldump -hlocalhost -uroot hqgr hqgr.sql (如果root用户没用密码可以不写-p,当然导出的sql文件你可以制定一个路径,未指定则存...
[MySQL] 对表和库(DML,DDL)的基本操作以及联合查询 日期:2019-05-17 13:26:45 点击:63 好评:0
联合查询,DML,DDL(对表和库的操作大全) 这次把上次没有提到的联合查询补充一下,然后主要来讲DML和DDL,就是主要讲一下对表和库的基本操作,例如增删改这些,有针对不同情况的不同方法和例子,复习和速查用起来应该比较方便,继续往下看吧~ 联合查询 将多条...
[MySQL] MySQL 对于千万级的大表要怎么优化 日期:2019-05-17 13:25:48 点击:164 好评:0
很多人第一反应是各种切分;我给的顺序是: 第一优化你的sql和索引; 第二加缓存,memcached,redis; 第三以上都做了后,还是慢,就做主从复制或主主复制,读写分离,可以在应用层做,效率高,也可以用三方工具,第三方工具推荐360的atlas,其它的要么效率不高...
[MySQL] Mysql 运行时问题排查 日期:2019-05-17 13:23:23 点击:69 好评:0
前几天有位同学碰到这样一个问题:之前运行良好的一段程序,由于最近数据量变大了,经常报取不到数据库连接的错误。将问题的解决过程总结记录下来: 首先,查看数据库配置的最大连接数,没有发现任何配置问题 show VARIABLES like max_connections 然后,在问...
[MySQL] Mysql模糊查询like效率,以及更高效的写法 日期:2019-05-14 17:50:58 点击:63 好评:0
在使用msyql进行模糊查询的时候,很自然的会用到like语句,通常情况下,在数据量小的时候,不容易看出查询的效率,但在数据量达到百万级,千万级的时候,查询的效率就很容易显现出来。这个时候查询的效率就显得很重要! 一般情况下like模糊查询的写法为(fie...
 [MySQL] MySQL系列-优化之like关键字 日期:2019-05-14 17:47:40 点击:142 好评:0
[MySQL] MySQL系列-优化之like关键字 日期:2019-05-14 17:47:40 点击:142 好评:0
like关键字我们也是经常使用,用来模糊查询用户名,那么like如何进行优化呢?这篇博客就简单讨论一下like的优化,但是真实的生产环境要比这复杂多了。 1.%号不放最左边 先创建表和索引。 然后进行查询【explain select * from tb where name like e%;】 可以...
[MySQL] mysql中like模糊查询优化 日期:2019-05-14 17:46:35 点击:121 好评:0
这是我在一个百万级数据库遇到的问题 比如这个语句在这个数据库查询很慢: select a from news where b like %haha% order by time limit 100; 第一种优化方法(注意:这种方法只适用于haha开头的): //将haha字段和time字段加索引(联合索引还是普通索引自己...
 [MySQL] MySQL--更高效的mysql模糊查询的方法 日期:2019-05-14 17:41:23 点击:101 好评:0
[MySQL] MySQL--更高效的mysql模糊查询的方法 日期:2019-05-14 17:41:23 点击:101 好评:0
想起Mysql模糊查询正常情况下我们想到的一般都是like,但是使用like,格式正确了效率很快,当然这是在数据量比较小的情况下,问题是在数据量小的时候,不容易看出查询的效率,但在数据量达到百万级,千万级的时 mysql查询的效率是很关键的,也是很重要的。...
 [MySQL] MySQL模糊搜索优化 日期:2019-05-14 17:38:50 点击:89 好评:0
[MySQL] MySQL模糊搜索优化 日期:2019-05-14 17:38:50 点击:89 好评:0
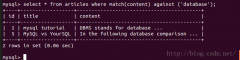
InnoDB引擎对FULLTEXT索引的支持是MySQL5.6新引入的特性,之前只有MyISAM引擎支持FULLTEXT索引。对于FULLTEXT索引的内容可以使用MATCH()AGAINST语法进行查询。 全文搜索的语法: MATCH(col1,col2,) AGAINST (expr[search_modifier])。 其中MATCH中的内容为已...
[MySQL] Mysql千万级大数据量查询优化 日期:2019-05-14 17:37:18 点击:119 好评:0
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:select id from t where num is null可以在num上设置默认...
Mysql命令行导入数据库: 1,将要导入的.sql文件移至bin文件下,这样的路径比较方便 2...
摘要: 利用Xtrabackup工具备份及恢复(MySQL DBA的必备工具) XtrabackupMySQL DBA的必...
MySQL 5.7.5后实现了对功能依赖的检测。默认启用了only_full_group_by 的SQL模式,会...
在部署实施过程工作中,我经常采取的是全量备份数据量或者增量备份数据库,对于mysql...
一、数据库事务隔离级别 数据库事务的隔离级别有4个,由低到高依次为Read uncommitted...
mysql的sql_mode合理设置 sql_mode是个很容易被忽视的变量,默认值是空值,在这种设置...