|
智谱宣布开源文生图模型 CogView3 及 CogView3-Plus-3B。CogView3 以及 CogView3-Plus 模型均使用 Apache 2.0 协议,目前该系列模型的能力已上线「智谱清言」(chatglm.cn)。 CogView3-Plus-3B 的效果:
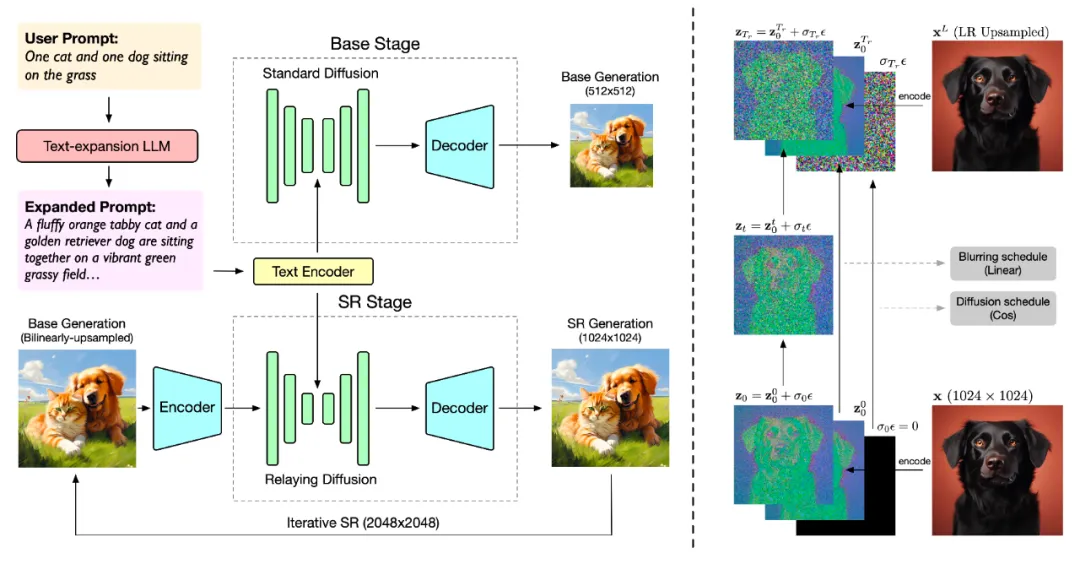
CogView3 是一个基于级联扩散的 text2img 模型,包含三个阶段:
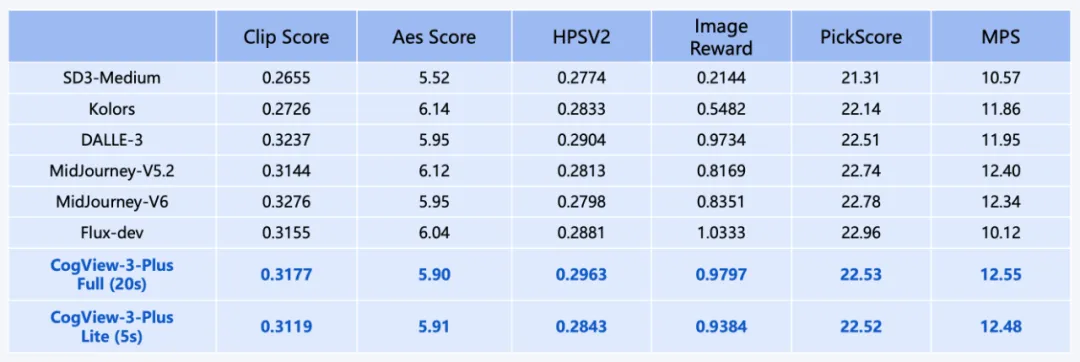
公告称,在实际效果上,CogView3 在人工评估中比目前最先进的开源文本到图像扩散模型 SDXL 高出 77.0%,同时只需要 SDXL 大约 1/10 的推理时间。
CogView-3-Plus 在 CogView3(ECCV'24) 的基础上引入了最新的 DiT 框架,以实现整体性能的进一步提升。其采用了 Zero-SNR 扩散噪声调度,并引入了文本 - 图像联合注意力机制。与常用的 MMDiT 结构相比,它在保持模型基本能力的同时,有效降低了训练和推理成本。CogView-3Plus 使用潜在维度为 16 的 VAE。 借由混合分辨率训练,CogView-3Plus 模型支持 512 ~ 2048 像素区间内分辨率的灵活生成。从效果上看,CogView3-plus 有着和最领先的 text2img 模型持平的水平。
|