Git LFS 的性能提升Git 是一个分布式版本控制系统,意味着整个仓库的历史会在克隆阶段被传送到客户端。对包含大文件的项目——尤其是大文件经常被修改——初始克隆会非常耗时,因为每一个版本的每一个文件都必须下载到客户端。Git LFS(大文件存储 )是一个 Git 拓展包,由 Atlassian、GitHub 和其他一些开源贡献者开发,通过需要时才下载大文件的相对版本来减少仓库中大文件的影响。更明确地说,大文件是在检出过程中按需下载的而不是在克隆或抓取过程中。 在 Git 2016 年的五大发布中,Git LFS 自身就有四个功能版本的发布:v1.2 到 v1.5。你可以仅对 Git LFS 这一项来写一系列回顾文章,但是就这篇文章而言,我将专注于 2016 年解决的一项最重要的主题:速度。一系列针对 Git 和 Git LFS 的改进极大程度地优化了将文件传入/传出服务器的性能。
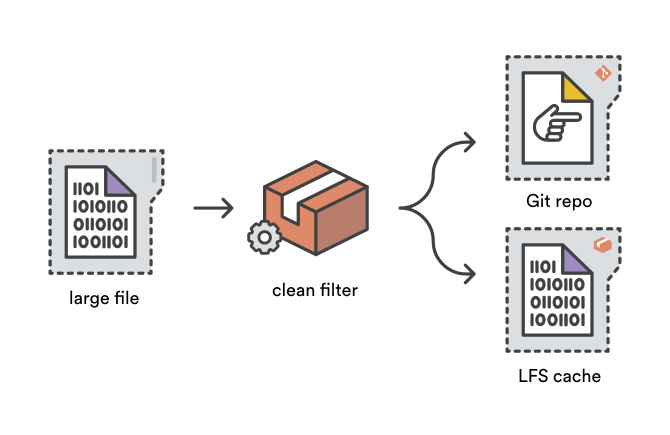
长期过滤进程当你 git add 一个文件时,Git 的净化过滤系统会被用来在文件被写入 Git 目标存储之前转化文件的内容。Git LFS 通过使用净化过滤器将大文件内容存储到 LFS 缓存中以缩减仓库的大小,并且增加一个小“指针”文件到 Git 目标存储中作为替代。
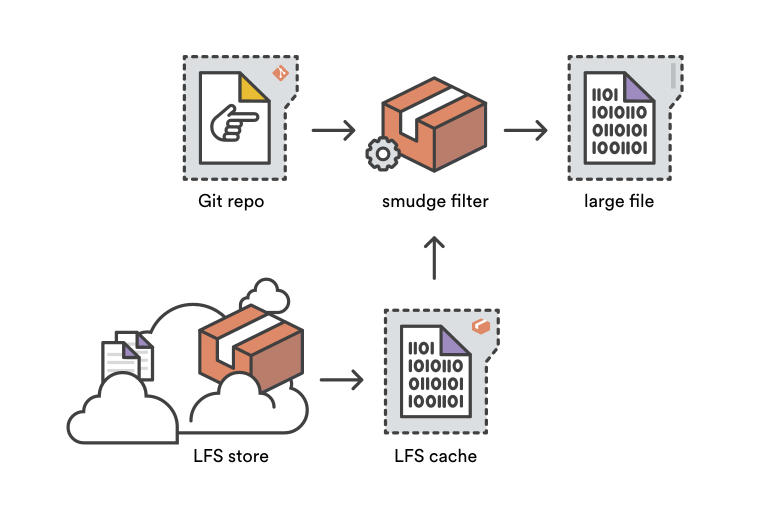
污化过滤器是净化过滤器的对立面——正如其名。在 git checkout 过程中从一个 Git 目标仓库读取文件内容时,污化过滤系统有机会在文件被写入用户的工作区前将其改写。Git LFS 污化过滤器通过将指针文件替代为对应的大文件将其转化,可以是从 LFS 缓存中获得或者通过读取存储在 Bitbucket 的 Git LFS。
传统上,污化和净化过滤进程在每个文件被增加和检出时只能被唤起一次。所以,一个项目如果有 1000 个文件在被 Git LFS 追踪 ,做一次全新的检出需要唤起 git-lfs-smudge 命令 1000 次。尽管单次操作相对很迅速,但是经常执行 1000 次独立的污化进程总耗费惊人。、 针对 Git v2.11(和 Git LFS v1.5),污化和净化过滤器可以被定义为长期进程,为第一个需要过滤的文件调用一次,然后为之后的文件持续提供污化或净化过滤直到父 Git 操作结束。Lars Schneider,Git 的长期过滤系统的贡献者,简洁地总结了对 Git LFS 性能改变带来的影响。
这真是一个让人印象深刻的性能增强!
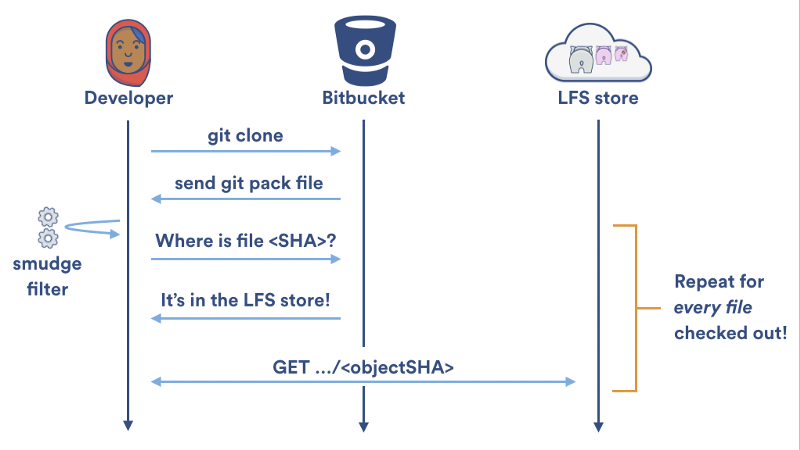
LFS 专有克隆长期运行的污化和净化过滤器在对向本地缓存读写的加速做了很多贡献,但是对大目标传入/传出 Git LFS 服务器的速度提升贡献很少。 每次 Git LFS 污化过滤器在本地 LFS 缓存中无法找到一个文件时,它不得不使用两次 HTTP 请求来获得该文件:一个用来定位文件,另外一个用来下载它。在一次 git clone 过程中,你的本地 LFS 缓存是空的,所以 Git LFS 会天真地为你的仓库中每个 LFS 所追踪的文件创建两个 HTTP 请求:
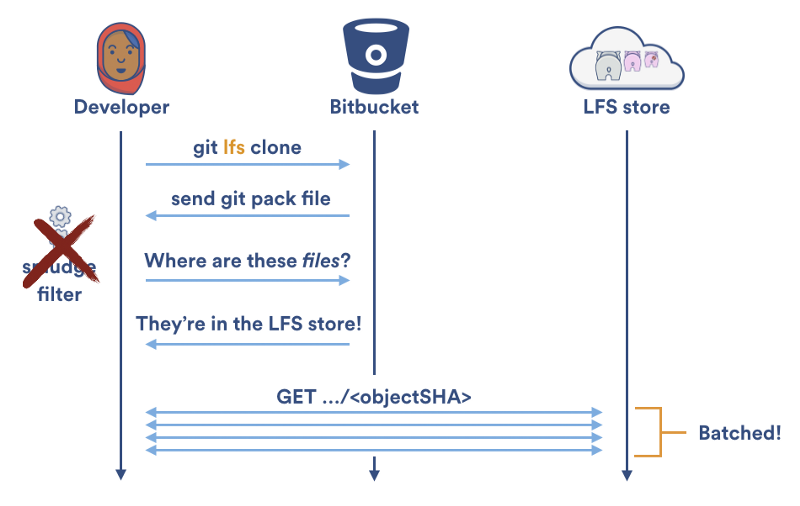
幸运的是,Git LFS v1.2 提供了专门的 git lfs clone 命令。不再是一次下载一个文件; git lfs clone 禁止 Git LFS 污化过滤器,等待检出结束,然后从 Git LFS 存储中按批下载任何需要的文件。这允许了并行下载并且将需要的 HTTP 请求数量减半。
自定义传输路由器正如之前讨论过的,Git LFS 在 v1.5 中提供对长期过滤进程的支持。不过,对另外一种类型的可插入进程的支持早在今年年初就发布了。 Git LFS 1.3 包含了对可插拔传输路由器的支持,因此不同的 Git LFS 托管服务可以定义属于它们自己的协议来向或从 LFS 存储中传输文件。 直到 2016 年底,Bitbucket 是唯一一个执行专属 Git LFS 传输协议 Bitbucket LFS Media Adapter 的托管服务商。这是为了从 Bitbucket 的一个被称为 chunking 的 LFS 存储 API 独特特性中获益。Chunking 意味着在上传或下载过程中,大文件被分解成 4MB 的文件块。
分块给予了 Bitbucket 支持的 Git LFS 三大优势:
可自定义的传输路由器是 Git LFS 的一个伟大的特性,它们使得不同服务商在不重载核心项目的前提下体验适合其服务器的优化后的传输协议。
更佳的 git diff 算法与默认值不像其他的版本控制系统,Git 不会明确地存储文件被重命名了的事实。例如,如果我编辑了一个简单的 Node.js 应用并且将 index.js 重命名为 app.js,然后运行 git diff,我会得到一个看起来像一个文件被删除另一个文件被新建的结果。
我猜测移动或重命名一个文件从技术上来讲是一次删除后跟着一次新建,但这不是对人类最友好的描述方式。其实,你可以使用 -M 标志来指示 Git 在计算差异时同时尝试检测是否是文件重命名。对之前的例子,git diff -M 给我们如下结果:
第二行显示的 similarity index 告诉我们文件内容经过比较后的相似程度。默认地,-M 会处理任意两个超过 50% 相似度的文件。这意味着,你需要编辑少于 50% 的行数来确保它们可以被识别成一个重命名后的文件。你可以通过加上一个百分比来选择你自己的 similarity index,如,-M80%。 到 Git v2.9 版本,无论你是否使用了 -M 标志, git diff 和 git log 命令都会默认检测重命名。如果不喜欢这种行为(或者,更现实的情况,你在通过一个脚本来解析 diff 输出),那么你可以通过显式的传递 --no-renames 标志来禁用这种行为。
详细的提交你经历过调用 git commit 然后盯着空白的 shell 试图想起你刚刚做过的所有改动吗?verbose 标志就为此而来! 不像这样:
……你可以调用 git commit --verbose 来查看你改动造成的行内差异。不用担心,这不会包含在你的提交信息中:
--verbose 标志并不是新出现的,但是直到 Git v2.9 你才可以通过 git config --global commit.verbose true 永久的启用它。
实验性的 Diff 改进当一个被修改部分前后几行相同时,git diff 可能产生一些稍微令人迷惑的输出。如果在一个文件中有两个或者更多相似结构的函数时这可能发生。来看一个有些刻意人为的例子,想象我们有一个 JS 文件包含一个单独的函数:
现在想象一下我们刚提交的改动包含一个我们专门做的 另一个可以做相似事情的函数:
我们希望 git diff 显示开头五行被新增,但是实际上它不恰当地将最初提交的第一行也包含进来。
错误的注释被包含在了 diff 中!这虽不是世界末日,但每次发生这种事情总免不了花费几秒钟的意识去想 啊? 在十二月,Git v2.11 介绍了一个新的实验性的 diff 选项,--indent-heuristic,尝试生成从美学角度来看更赏心悦目的 diff。
在后台,--indent-heuristic 在每一次改动造成的所有可能的 diff 中循环,并为它们分别打上一个 “不良” 分数。这是基于启发式的,如差异文件块是否以不同等级的缩进开始和结束(从美学角度讲“不良”),以及差异文件块前后是否有空白行(从美学角度讲令人愉悦)。最后,有着最低不良分数的块就是最终输出。 这个特性还是实验性的,但是你可以通过应用 --indent-heuristic 选项到任何 git diff 命令来专门测试它。如果,如果你喜欢尝鲜,你可以这样将其在你的整个系统内启用:
(责任编辑:IT) |