Tomcat是目前应用比较多的servlet容器。关于tomcat本身的特点及介绍,网上已经有很多描述了,这里不再赘述。Tomcat除了能够支撑通常的web app外,其本身高度模块化的架构体系,也能带来最大限度的可扩展性。目前tomcat版本已经衍生到tomcat7,但是主流的版本还是tomcat6。此系列架构体系介绍还是以tomcat6为蓝本。
Tomcat是有一系列逻辑模块组织而成,这些模块主要包括:
-
核心架构模块,例如Server,Service,engine,host和context及wrapper等
-
网络接口模块connector
-
log模块
-
session管理模块
-
jasper模块
-
naming模块
-
JMX模块
-
权限控制模块
-
……
这些模块会在相关的文档里逐一描述,本篇文档以介绍核心架构模块为主。
核心架构模块说明
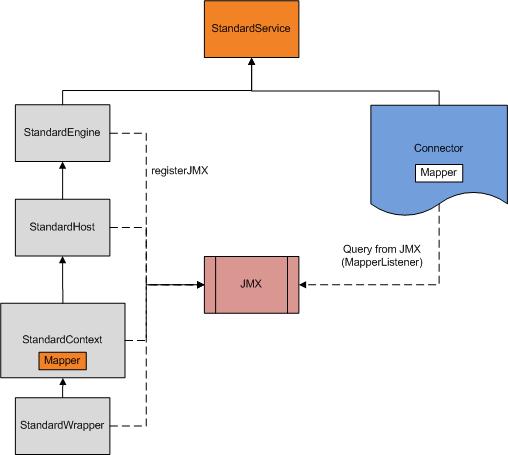
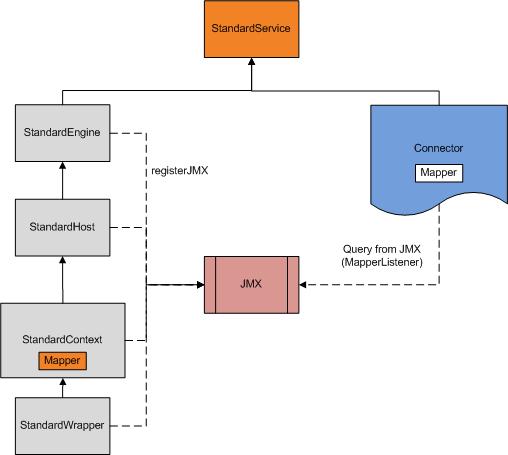
核心架构模块之间是层层包含关系。例如可以说Service是Server的子组件,Server是Service的父组件。在server.xml已经非常清晰的定义了这些组件之间的关系及配置。
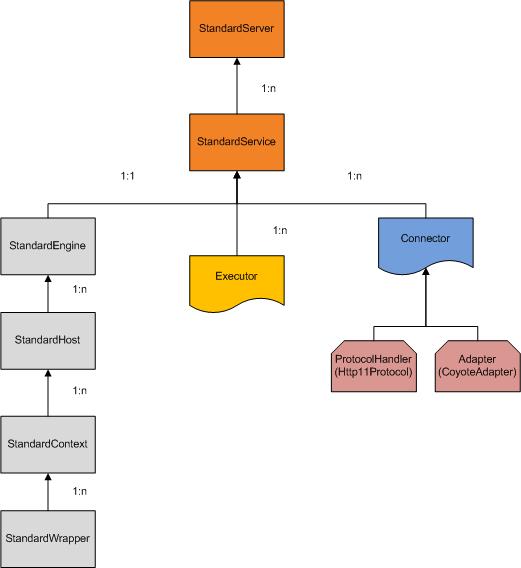
需要强调的是Service中配置了实际工作的Engine,同时配置了用来处理时间业务的线程组Executor(如果没有配置则用系统默认的WorkThread模式的线程组),以及处理网络socket的相关组件connector。详细情况如图所示。
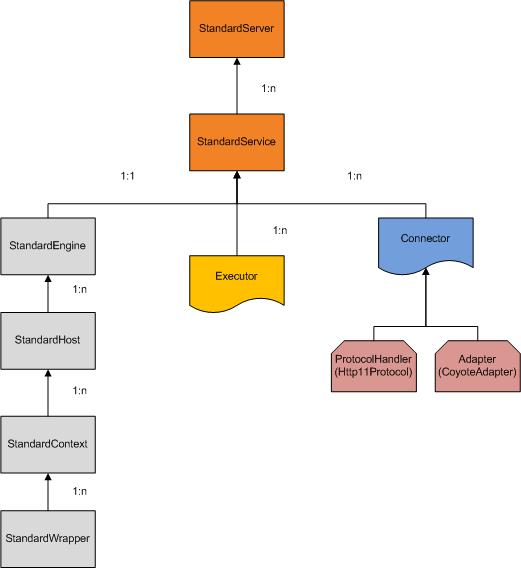
图中,1:n代表一对多的关系;1:1代表一对一的关系。
StandEngine, StandHost, StandContext及StandWrapper是容器,他们之间有互相的包含关系。例如,StandEngine是StandHost的父容器,StandHost是StandEngine的子容器。在StandService内还包含一个Executor及Connector。
1) Executor是线程池,它的具体实现是java的concurrent包实现的executor,这个不是必须的,如果没有配置,则使用自写的worker thread线程池
2) Connector是网络socket相关接口模块,它包含两个对象,ProtocolHandler及Adapter
-
ProtocolHandler是接收socket请求,并将其解析成HTTP请求对象,可以配置成nio模式或者传统io模式
-
Adapter是处理HTTP请求对象,它就是从StandEngine的valve一直调用到StandWrapper的valve
分层建模
对于上述的各个逻辑模块,理解起来可能比较抽象。其实一个服务器无非是接受HTTP request,然后处理请求,产生HTTP response通过原有连接返回给客户端(浏览器)。那为什么会整出这么多的模块进行处理,这些模块是不是有些多余。
其实这些模块各司其职,我们从底层wrapper开始讲解,一直上溯到顶层的server。这样易于理解。通过这些描述,会发现这正是tomcat架构的高度模块化的体现。这些细分的模块,使得tomcat非常健壮,通过一些配置和模块定制化,可以很大限度的扩展tomcat。
首先,我们以一个典型的页面访问为例,假设访问的URL是
引用
http://www.mydomain.com/app/index.html
详细情况如图所示。

-
Wrapper封装了具体的访问资源,例如 index.html
-
Context 封装了各个wrapper资源的集合,例如 app
-
Host 封装了各个context资源的集合,例如 www.mydomain.com
按照领域模型,这个典型的URL访问,可以解析出三层领域对象,他们之间互有隶属关系。这是最基本的建模。从上面的分析可以看出,从wrapper到host是层层递进,层层组合。那么host 资源的集合是什么呢,就是上面所说的engine。 如果说以上的三个容器可以看成是物理模型的封装,那么engine可以看成是一种逻辑的封装。
好了,有了这一整套engine的支持,我们已经可以完成从engine到host到context再到某个特定wrapper的定位,然后进行业务逻辑的处理了(关于怎么处理业务逻辑,会在之后的blog中讲述)。就好比,一个酒店已经完成了各个客房等硬件设施的建设与装修,接下来就是前台接待工作了。
先说线程池,这是典型的线程池的应用。首先从线程池中取出一个可用线程(如果有的话),来处理请求,这个组件就是connector。它就像酒店的前台服务员登记客人信息办理入住一样,主要完成了HTTP消息的解析,根据tomcat内部的mapping规则,完成从engine到host到context再到某个特定wrapper的定位,进行业务处理,然后将返回结果返回。之后,此次处理结束,线程重新回到线程池中,为下一次请求提供服务。
如果线程池中没有空闲线程可用,则请求被阻塞,一直等待有空闲线程进行处理,直至阻塞超时。线程池的实现有executor及worker thread两种。缺省的是worker thread 模式。
至此,可以说一个酒店有了前台接待,有了房间等硬件设施,就可以开始正式运营了。那么把engine,处理线程池,connector封装在一起,形成了一个完整独立的处理单元,这就是service,就好比某个独立的酒店。
通常,我们经常看见某某集团旗下酒店。也就是说,每个品牌有多个酒店同时运营。就好比tomcat中有多个service在独自运行。那么这多个service的集合就是server,就好比是酒店所属的集团。
作用域
那为什么要按层次分别封装一个对象呢?这主要是为了方便统一管理。类似命名空间的概念,在不同层次的配置,其作用域不一样。以tomcat自带的打印request与response消息的RequestDumperValve为例。这个valve的类路径是:
引用
org.apache.catalina.valves.RequestDumperValve
valve机制是tomcat非常重要的处理逻辑的机制,会在相关文档里专门描述。 如果这个valve配置在server.xml的节点下,则其只打印出访问这个app(my)的request与response消息。
Xml代码 
-
<Host name="localhost" appBase="webapps"
-
unpackWARs="true" autoDeploy="true"
-
xmlValidation="false" xmlNamespaceAware="false">
-
<Context path="/my" docBase=" /usr/local/tomcat/backup/my" >
-
<Valve className="org.apache.catalina.valves.RequestDumperValve"/>
-
</Context>
-
<Context path="/my2" docBase=" /usr/local/tomcat/backup/my" >
-
</Context>
-
</Host>
如果这个valve配置在server.xml的节点下,则其可以打印出访问这个host下两个app的request与response消息。
Xml代码
-
<Host name="localhost" appBase="webapps"
-
unpackWARs="true" autoDeploy="true"
-
xmlValidation="false" xmlNamespaceAware="false">
-
<Valve className="org.apache.catalina.valves.RequestDumperValve"/>
-
<Context path="/my" docBase=" /usr/local/tomcat/backup/my" >
-
</Context>
-
<Context path="/my2" docBase=" /usr/local/tomcat/backup/my" >
-
</Context>
-
</Host>
在这里贴一个缺省的server.xml的配置,通过这些配置可以加深对tomcat核心架构分层模块的理解,关于tomcat的配置,在相关的文档里另行说明。为了篇幅,我把里面的注释给删了。
Xml代码
-
<Server port="8005" shutdown="SHUTDOWN">
-
<Listener className="org.apache.catalina.core.AprLifecycleListener" SSLEngine="on" />
-
<Listener className="org.apache.catalina.core.JasperListener" />
-
<Listener className="org.apache.catalina.mbeans.ServerLifecycleListener" />
-
<Listener className="org.apache.catalina.mbeans.GlobalResourcesLifecycleListener" />
-
<GlobalNamingResources>
-
<Resource name="UserDatabase" auth="Container"
-
type="org.apache.catalina.UserDatabase"
-
description="User database that can be updated and saved"
-
factory="org.apache.catalina.users.MemoryUserDatabaseFactory"
-
pathname="conf/tomcat-users.xml" />
-
</GlobalNamingResources>
-
<Service name="Catalina">
-
<Executor name="tomcatThreadPool" namePrefix="catalina-exec-"
-
maxThreads="150" minSpareThreads="4"/>
-
<Connector port="80" protocol="HTTP/1.1"
-
connectionTimeout="20000"
-
redirectPort="7443" />
-
<Connector port="7009" protocol="AJP/1.3" redirectPort="7443" />
-
<Engine name="Catalina" defaultHost="localhost">
-
<Realm className="org.apache.catalina.realm.UserDatabaseRealm"
-
resourceName="UserDatabase"/>
-
<Host name="localhost" appBase="webapps"
-
unpackWARs="true" autoDeploy="true"
-
xmlValidation="false" xmlNamespaceAware="false">
-
<Context path="/my" docBase="/usr/local/tomcat/backup/my" >
-
</Context>
-
</Host>
-
</Engine>
-
</Service>
-
</Server>
-
Tomcat提供了engine,host,context及wrapper四种容器。在总体结构中已经阐述了他们之间的包含关系。这四种容器继承了一个容器基类,因此可以定制化。当然,tomcat也提供了标准实现。
-
Engine:org.apache.catalina.core.StandardEngine
-
Host: org.apache.catalina.core.StandardHost
-
Context:org.apache.catalina.core.StandardContext
-
Wrapper:org.apache.catalina.core.StandardWrapper
所谓容器,就是说它承载了若干逻辑单元及运行时数据。好比,整个酒店是一个容器,它包含了各个楼层等设施;每个楼层也是容器,它包含了各个房间;每个房间也是容器,它包含了各种家电等等。
首先来看一下容器类的类结构。

基类ContainerBase
ContainerBase是个abstract基类。其类路径为:
Java代码
-
org.apache.catalina.core.ContainerBase
这里只列出一些比较核心功能的组件及方法。需要注意的是,类中的方法及属性很多,限于篇幅不全部列出来了。
Enigne
Engine是最顶层的容器,它是host容器的组合。其标准实现类为:
Java代码
-
org.apache.catalina.core.StandardEngine
看一下StandardEngine的主要逻辑单元概念图。
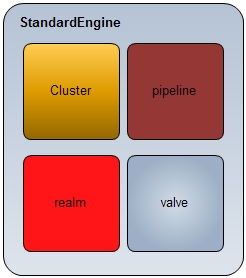
从图中可以看出,engine有四大组件:
-
Cluster: 实现tomcat集群,例如session共享等功能,通过配置server.xml可以实现,对其包含的所有host里的应用有效,该模块是可选的。其实现方式是基于pipeline+valve模式的,有时间会专门整理一个pipeline+valve模式应用系列;
-
Realm:实现用户权限管理模块,例如用户登录,访问控制等,通过通过配置server.xml可以实现,对其包含的所有host里的应用有效,该模块是可选的;
-
Pipeline:这里简单介绍下,之后会有专门文档说明。每个容器对象都有一个pipeline,它不是通过server.xml配置产生的,是必须有的。它就是容器对象实现逻辑操作的骨架,在pipeline上配置不同的valve,当需要调用此容器实现逻辑时,就会按照顺序将此pipeline上的所有valve调用一遍,这里可以参考责任链模式;
-
Valve:实现具体业务逻辑单元。可以定制化valve(实现特定接口),然后配置在server.xml里。对其包含的所有host里的应用有效。定制化的valve是可选的,但是每个容器有一个缺省的valve,例如engine的StandardEngineValve,是在StandardEngine里自带的,它主要实现了对其子host对象的StandardHostValve的调用,以此类推。
配置的例子有:
Xml代码
-
<Engine name="Catalina" defaultHost="localhost">
-
<Valve className="MyValve0"/>
-
<Valve className="MyValve1"/>
-
<Valve className="MyValve2"/>
-
……
-
<Host name="localhost" appBase="webapps">
-
</Host>
-
</Engine>
需要注意的是,运行环境中,pipeline上的valve数组按照配置的顺序加载,但是无论有无配置定制化的valve或有多少定制化的valve,每个容器缺省的valve,例如engine的StandardEngineValve,都会在数组中最后一个。
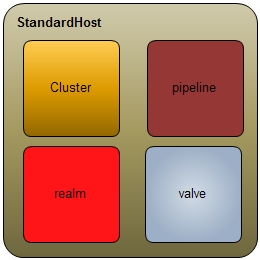
Host
Host是engine的子容器,它是context容器的集合。其标准实现类为:
Java代码
-
org.apache.catalina.core.StandardHost
StandardHost的核心模块与StandardEngine差不多。只是作用域不一样,它的模块只对其包含的子context有效。除此,还有一些特殊的逻辑,例如context的部署。Context的部署还是比较多的,主要分为:
有时间单独再说吧。照例贴个核心模块概念图。
Context
Context是host的子容器,它是wrapper容器的集合。其标准实现类为:
Java代码
-
org.apache.catalina.core.StandardContext
应该说StandardContext是tomcat中最大的一个类。它封装的是每个web app。
看一下StandardContext的主要逻辑单元概念图。
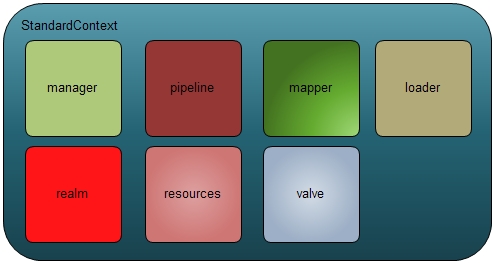
Pipeline,valve,realm与上面容器一样,只是作用域不一样,不多说了。
-
Manager: 它主要是应用的session管理模块。其主要功能是session的创建,session的维护,session的持久化(persistence),以及跨context的session的管理等。Manager模块可以定制化,tomcat也给出了一个标准实现;
Java代码
-
org.apache.catalina.session.StandardManager
manager模块是必须要有的,可以在server.xml中配置,如果没有配置的话,会在程序里生成一个manager对象。
-
Resources: 它是每个web app对应的部署结构的封装,比如,有的app是tomcat的webapps目录下的某个子目录或是在context节点配置的其他目录,或者是war文件部署的结构等。它对于每个web app是必须的。
-
Loader:它是对每个web app的自有的classloader的封装。具体内容涉及到tomcat的classloader体系,会在一篇文档中单独说明。Tomcat正是有一套完整的classloader体系,才能保证每个web app或是独立运营,或是共享某些对象等等。它对于每个web app是必须的。
-
Mapper:它封装了请求资源URI与每个相对应的处理wrapper容器的映射关系。
以某个web app的自有的web.xml配置为例;
Xml代码
-
<servlet>
-
<servlet-name>httpserver</servlet-name>
-
<servlet-class>com.gearever.servlet.TestServlet</servlet-class>
-
</servlet>
-
-
<servlet-mapping>
-
<servlet-name>httpserver</servlet-name>
-
<url-pattern>/*.do</url-pattern>
-
</servlet-mapping>
对于mapper对象,可以抽象的理解成一个map结构,其key是某个访问资源,例如/*.do,那么其value就是封装了处理这个资源TestServlet的某个wrapper对象。当访问/*.do资源时,TestServlet就会在mapper对象中定位到。这里需要特别说明的是,通过这个mapper对象定位特定的wrapper对象的方式,只有一种情况,那就是在servlet或jsp中通过forward方式访问资源时用到。例如,
Java代码
-
request.getRequestDispatcher(url).forward(request, response)
关于mapper机制会在一篇文档中专门说明,这里简单介绍一下,方便理解。如图所示。
Mapper对象在tomcat中存在于两个地方(注意,不是说只有两个mapper对象存在),其一,是每个context容器对象中,它只记录了此context内部的访问资源与相对应的wrapper子容器的映射;其二,是connector模块中,这是tomcat全局的变量,它记录了一个完整的映射对应关系,即根据访问的完整URL如何定位到哪个host下的哪个context的哪个wrapper容器。
这样,通过上面说的forward方式访问资源会用到第一种mapper,除此之外,其他的任何方式,都是通过第二种方式的mapper定位到wrapper来处理的。也就是说,forward是服务器内部的重定向,不需要经过网络接口,因此只需要通过内存中的处理就能完成。这也就是常说的forward与sendRedirect方式重定向区别的根本所在。
看一下request.getRequestDispatcher(url) 方法的源码。
Java代码
-
public RequestDispatcher getRequestDispatcher(String path) {
-
-
// Validate the path argument
-
if (path == null)
-
return (null);
-
if (!path.startsWith("/"))
-
throw new IllegalArgumentException
-
(sm.getString
-
("applicationContext.requestDispatcher.iae", path));
-
-
// Get query string
-
String queryString = null;
-
int pos = path.indexOf('?');
-
if (pos >= 0) {
-
queryString = path.substring(pos + 1);
-
path = path.substring(0, pos);
-
}
-
-
path = normalize(path);
-
if (path == null)
-
return (null);
-
-
pos = path.length();
-
-
// Use the thread local URI and mapping data
-
DispatchData dd = dispatchData.get();
-
if (dd == null) {
-
dd = new DispatchData();
-
dispatchData.set(dd);
-
}
-
-
MessageBytes uriMB = dd.uriMB;
-
uriMB.recycle();
-
-
// Use the thread local mapping data
-
MappingData mappingData = dd.mappingData;
-
-
// Map the URI
-
CharChunk uriCC = uriMB.getCharChunk();
-
try {
-
uriCC.append(context.getPath(), 0, context.getPath().length());
-
/*
-
* Ignore any trailing path params (separated by ';') for mapping
-
* purposes
-
*/
-
int semicolon = path.indexOf(';');
-
if (pos >= 0 && semicolon > pos) {
-
semicolon = -1;
-
}
-
uriCC.append(path, 0, semicolon > 0 ? semicolon : pos);
-
<span style="color: #ff0000;"> context.getMapper().map(uriMB, mappingData); </span>
-
if (mappingData.wrapper == null) {
-
return (null);
-
}
-
/*
-
* Append any trailing path params (separated by ';') that were
-
* ignored for mapping purposes, so that they're reflected in the
-
* RequestDispatcher's requestURI
-
*/
-
if (semicolon > 0) {
-
uriCC.append(path, semicolon, pos - semicolon);
-
}
-
} catch (Exception e) {
-
// Should never happen
-
log(sm.getString("applicationContext.mapping.error"), e);
-
return (null);
-
}
-
-
<span style="color: #ff0000;">Wrapper wrapper = (Wrapper) mappingData.wrapper; </span>
-
String wrapperPath = mappingData.wrapperPath.toString();
-
String pathInfo = mappingData.pathInfo.toString();
-
-
mappingData.recycle();
-
-
// Construct a RequestDispatcher to process this request
-
return new ApplicationDispatcher
-
(<span style="color: #ff0000;">wrapper</span>, uriCC.toString(), wrapperPath, pathInfo,
-
queryString, null);
-
-
}
红色部分标记了从context的mapper对象中定位wrapper子容器,然后封装在一个dispatcher对象内并返回。通过上面的阐述,也说明了为什么forward方法不能跨context访问资源了。
Wrapper
Wrapper是context的子容器,它封装的处理资源的每个具体的servlet。其标准实现类为:
Java代码
-
org.apache.catalina.core.StandardWrapper
应该说StandardWrapper是tomcat中比较重要的一个类。初认识它时,比较容易混淆。
先看一下StandardWrapper的主要逻辑单元概念图。
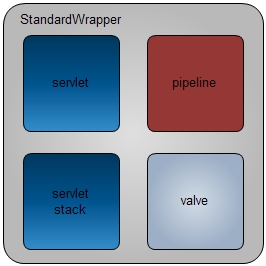
Pipeline,valve与上面容器一样,只是作用域不一样,不多说了。
主要说说servlet对象与servlet stack对象。这两个对象在wrapper容器中只存在其中之一,也就是说只有其中一个不为空。当以servlet对象存在时,说明此servlet是支持多线程并发访问的,也就是说不存在线程同步的过程,此wrapper容器中只包含一个servlet对象(这是我们常用的模式);当以servlet stack对象存在时,说明servlet是不支持多线程并发访问的,每个servlet对象任一时刻只有一个线程可以调用,这样servlet stack实现的就是个简易的线程池,此wrapper容器中只包含一组servlet对象,它的基本原型是worker thread模式实现的。
那么,怎么来决定是以servlet对象方式存储还是servlet stack方式存储呢?其实,只要在开发servlet类时,实现一个SingleThreadModel接口即可。
如果需要线程同步的servlet类,例如:
Java代码
-
public class LoginServlet extends HttpServlet implements javax.servlet.SingleThreadModel{ …… }
但是值得注意的是,这种同步机制只是从servlet规范的角度来说提供的一种功能,在实际应用中并不能完全解决线程安全问题,例如如果servlet中有static数据访问等,因此如果对线程安全又比较严格要求的,最好还是用一些其他的自定义的解决方案。
Wrapper的基本功能已经说了。那么再说一个wrapper比较重要的概念。严格的说,并不是每一个访问资源对应一个wrapper对象。而是每一种访问资源对应一个wrapper对象。其大致可分为三种:
-
处理静态资源的一个wrapper:例如html,jpg等静态资源的wrapper,它包含了一个tomcat的实现处理静态资源的缺省servlet:
Java代码
-
org.apache.catalina.servlets.DefaultServlet
-
处理jsp的一个wrapper:例如访问的所有jsp文件,它包含了一个tomcat的实现处理jsp的缺省servlet:
Java代码
-
org.apache.jasper.servlet.JspServlet
它主要实现了对jsp的编译等操作
-
处理servlet的若干wrapper:它包含了自定义的servlet对象,就是在web.xml中配置的servlet。
需要注意的是,前两种wrapper分别是一个,主要是其对应的是DefaultServlet及JspServlet。这两个servlet是在tomcat的全局conf目录下的web.xml中配置的,当app启动时,加载到内存中。
Xml代码
-
<servlet>
-
<servlet-name>default</servlet-name>
-
<servlet-class>org.apache.catalina.servlets.DefaultServlet</servlet-class>
-
<init-param>
-
<param-name>debug</param-name>
-
<param-value>0</param-value>
-
</init-param>
-
<init-param>
-
<param-name>listings</param-name>
-
<param-value>false</param-value>
-
</init-param>
-
<load-on-startup>1</load-on-startup>
-
</servlet>
-
-
<servlet>
-
<servlet-name>jsp</servlet-name>
-
<servlet-class>org.apache.jasper.servlet.JspServlet</servlet-class>
-
<init-param>
-
<param-name>fork</param-name>
-
<param-value>false</param-value>
-
</init-param>
-
<init-param>
-
<param-name>xpoweredBy</param-name>
-
<param-value>false</param-value>
-
</init-param>
-
<load-on-startup>3</load-on-startup>
-
</servlet>
至此,阐述了tomcat的四大容器结构。 有时间接着探讨tomcat如何将这四大容器串起来运作的。关于tomcat的内部逻辑单元的存储空间已经在相关容器类的blog里阐述了。在每个容器对象里面都有一个pipeline及valve模块。它们是容器类必须具有的模块。在容器对象生成时自动产生。Pipeline就像是每个容器的逻辑总线。在pipeline上按照配置的顺序,加载各个valve。通过pipeline完成各个valve之间的调用,各个valve实现具体的应用逻辑。
先看一下pipeline及valve的逻辑概念图。

这些valve就是在tomcat的server.xml中配置,只要满足一定条件,继承ValveBase基类
引用
org.apache.catalina.valves.ValveBase
就可以在不同的容器中配置,然后在消息流中被逐一调用。每个容器的valve的作用域不一样,在总体结构中已有说明。这里红色标记的是配置的自定义的valve,这样可以扩展成多个其他应用,例如cluster应用等。
Tomcat实现
Tomcat提供了Pipeline的标准实现:
引用
org.apache.catalina.core.StandardPipeline
四大容器类StandardEngine,StandardHost,StandardContext及StandardWrapper都有各自缺省的标准valve实现。它们分别是
-
Engine:org.apache.catalina.core.StandardEngineValve
-
Host: org.apache.catalina.core.StandardHostValve
-
Context:org.apache.catalina.core.StandardContextValve
-
Wrapper:org.apache.catalina.core.StandardWrapperValve
容器类生成对象时,都会生成一个pipeline对象,同时,生成一个缺省的valve实现,并将这个标准的valve对象绑定在其pipeline对象上。以StandardHost类为例:
Java代码 
-
public class StandardHost extends ContainerBase implements Host {
-
-
protected Pipeline pipeline = new StandardPipeline(this);
-
public StandardHost() {
-
super();
-
pipeline.setBasic(new StandardHostValve());
-
}
-
-
}
Valve实现了具体业务逻辑单元。可以定制化valve(实现特定接口),然后配置在server.xml里。每层容器都可以配置相应的valve,当只在其作用域内有效。例如engine容器里的valve只对其包含的所有host里的应用有效。定制化的valve是可选的,但是每个容器有一个缺省的valve,例如engine的StandardEngineValve,是在StandardEngine里自带的,它主要实现了对其子host对象的StandardHostValve的调用,以此类推。
配置的例子有:
Xml代码
-
<Engine name="Catalina" defaultHost="localhost">
-
<Valve className="MyValve0"/>
-
<Valve className="MyValve1"/>
-
<Valve className="MyValve2"/>
-
……
-
<Host name="localhost" appBase="webapps">
-
</Host>
-
</Engine>
当在server.xml文件中配置了一个定制化valve时,会调用pipeline对象的addValve方法,将valve以链表方式组织起来,看一下代码;
Java代码
-
public class StandardPipeline implements Pipeline, Contained, Lifecycle{
-
-
protected Valve first = null;
-
-
public void addValve(Valve valve) {
-
-
// Validate that we can add this Valve
-
if (valve instanceof Contained)
-
((Contained) valve).setContainer(this.container);
-
-
// Start the new component if necessary
-
if (started) {
-
if (valve instanceof Lifecycle) {
-
try {
-
((Lifecycle) valve).start();
-
} catch (LifecycleException e) {
-
log.error("StandardPipeline.addValve: start: ", e);
-
}
-
}
-
// Register the newly added valve
-
registerValve(valve);
-
}
-
-
// 将配置的valve添加到链表中,并且每个容器的标准valve在链表的尾端
-
if (first == null) {
-
first = valve;
-
valve.setNext(basic);
-
} else {
-
Valve current = first;
-
while (current != null) {
-
if (current.getNext() == basic) {
-
current.setNext(valve);
-
valve.setNext(basic);
-
break;
-
}
-
current = current.getNext();
-
}
-
}
-
}
-
}
从上面可以清楚的看出,valve按照容器作用域的配置顺序来组织valve,每个valve都设置了指向下一个valve的next引用。同时,每个容器缺省的标准valve都存在于valve链表尾端,这就意味着,在每个pipeline中,缺省的标准valve都是按顺序,最后被调用。
消息流
先看一下四大容器的标准valve的调用逻辑图。从中可以梳理出标准valve的逻辑。注意此图只是在缺省配置下的状态,也就是说每个pipeline只包含一个标准valve的情况。
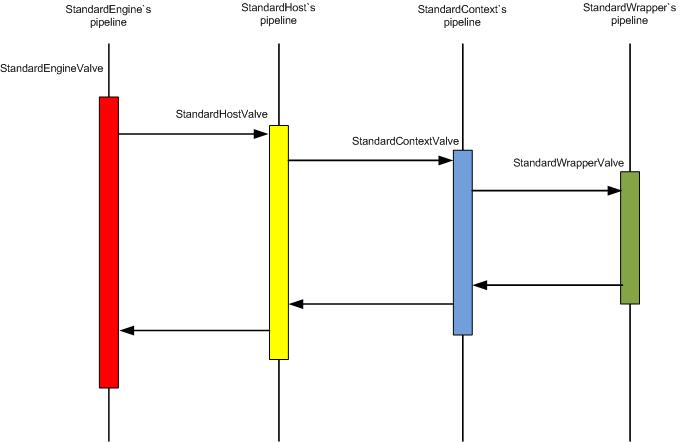
图中显示的是各个容器默认的valve之间的实际调用情况。从StandardEngineValve开始,一直到StandardWrapperValve,完成整个消息处理过程。注意每一个上层的valve都是在调用下一层的valve返回后再返回的,这样每个上层valve不仅具有request对象,同时还能拿到response对象,想象一下,这样是不是可以批量的做很多东西?现在通过源码来加深下理解。侯捷说过,源码面前,了无秘密。通过这些代码,可以看到在tomcat中我们经常碰到的一些现象或配置是怎么实现的。
StandardEngineValve
看一下StandardEngineValve的调用逻辑;
Java代码 
-
public final void invoke(Request request, Response response)
-
throws IOException, ServletException {
-
-
// 定位host
-
Host host = request.getHost();
-
if (host == null) {
-
......
-
return;
-
}
-
-
// 调用host的第一个valve
-
host.getPipeline().getFirst().invoke(request, response);
-
-
}
可以清晰的看到,根据request定位到可以处理的host对象,同时,开始从头调用host里的pipeline上的valve。
StandardHostValve
看一下StandardHostValve的调用逻辑;
Java代码
-
public final void invoke(Request request, Response response)
-
throws IOException, ServletException {
-
-
// 定位context
-
Context context = request.getContext();
-
if (context == null) {
-
......
-
return;
-
}
-
-
......
-
-
// 调用context的第一个valve
-
context.getPipeline().getFirst().invoke(request, response);
-
-
// 更新session
-
if (Globals.STRICT_SERVLET_COMPLIANCE) {
-
request.getSession(false);
-
}
-
-
// Error page processing
-
response.setSuspended(false);
-
-
//如果有抛异常或某个HTTP错误,导向响应的配置页面
-
Throwable t = (Throwable) request.getAttribute(Globals.EXCEPTION_ATTR);
-
-
if (t != null) {
-
throwable(request, response, t);
-
} else {
-
status(request, response);
-
}
-
-
// Restore the context classloader
-
Thread.currentThread().setContextClassLoader
-
(StandardHostValve.class.getClassLoader());
-
-
}
可以清晰的看到,注释部分里根据request定位到可以处理的context对象,同时,开始从头调用context里的pipeline上的valve。在调用完context的所有的valve之后(当然也是context调用完其对应的wrapper上的所有valve之后),蓝色部分显示了拿到response对象时可以做的处理。
熟悉tomcat的可能有配置错误信息的经验,例如;
Xml代码
-
<error-page>
-
<error-code>404</error-code>
-
<location>/error.jsp</location>
-
</error-page>
它就是为了在用户访问资源出现HTTP 404错误时,将访问重定向到一个统一的错误页面。这样做一是为了美观,另一个主要作用是不会将一些具体的错误信息例如java抛异常时的栈信息暴露给用户,主要还是出于安全的考虑。 上述代码中的注释部分就是实现这个重定向功能。
StandardContextValve
看一下StandardContextValve的调用逻辑;其代码比较多,只贴一些比较核心的吧。
Java代码
-
public final void invoke(Request request, Response response)
-
throws IOException, ServletException {
-
-
......
-
-
// 定位wrapper
-
Wrapper wrapper = request.getWrapper();
-
if (wrapper == null) {
-
notFound(response);
-
return;
-
} else if (wrapper.isUnavailable()) {
-
......
-
}
-
-
// Normal request processing
-
//web.xml中配置web-app/listener/listener-class
-
Object instances[] = context.getApplicationEventListeners();
-
-
ServletRequestEvent event = null;
-
-
//响应request初始化事件,具体的响应listener是可配置的
-
......
-
//调用wrapper的第一个valve
-
wrapper.getPipeline().getFirst().invoke(request, response);
-
-
//响应request撤销事件,具体的响应listener是可配置的
-
......
-
}
可以清晰的看到,注释部分里根据request定位到可以处理的wrapper对象,同时,开始从头调用wrapper里的pipeline上的valve。 需要注意的是,这里在调用wrapper的valve前后,分别有响应request初始化及撤销事件的逻辑,tomcat有一整套事件触发体系,这里限于篇幅就不阐述了。有时间专门说。
StandardWrapperValve
看一下StandardWrapperValve的调用逻辑;其代码比较多,只贴一些比较核心的吧;
Java代码
-
public final void invoke(Request request, Response response)
-
throws IOException, ServletException {
-
-
......
-
requestCount++;
-
//定位wrapper
-
StandardWrapper wrapper = (StandardWrapper) getContainer();
-
Servlet servlet = null;
-
Context context = (Context) wrapper.getParent();
-
-
......
-
-
// Allocate a servlet instance to process this request
-
try {
-
if (!unavailable) {
-
//加载servlet
-
servlet = wrapper.allocate();
-
}
-
} catch (UnavailableException e) {
-
......
-
}
-
......
-
// 根据配置建立一个filter-servlet的处理链表,servlet在链表的尾端
-
ApplicationFilterFactory factory =
-
ApplicationFilterFactory.getInstance();
-
ApplicationFilterChain filterChain =
-
factory.createFilterChain(request, wrapper, servlet);
-
// Reset comet flag value after creating the filter chain
-
request.setComet(false);
-
-
// Call the filter chain for this request
-
// NOTE: This also calls the servlet's service() method
-
try {
-
String jspFile = wrapper.getJspFile();
-
if (jspFile != null)
-
request.setAttribute(Globals.JSP_FILE_ATTR, jspFile);
-
else
-
request.removeAttribute(Globals.JSP_FILE_ATTR);
-
if ((servlet != null) && (filterChain != null)) {
-
// Swallow output if needed
-
if (context.getSwallowOutput()) {
-
try {
-
SystemLogHandler.startCapture();
-
if (comet) {
-
filterChain.doFilterEvent(request.getEvent());
-
request.setComet(true);
-
} else {
-
//调用filter-servlet链表
-
filterChain.doFilter(request.getRequest(),
-
response.getResponse());
-
}
-
} finally {
-
String log = SystemLogHandler.stopCapture();
-
if (log != null && log.length() > 0) {
-
context.getLogger().info(log);
-
}
-
}
-
} else {
-
if (comet) {
-
request.setComet(true);
-
filterChain.doFilterEvent(request.getEvent());
-
} else {
-
//调用filter-servlet链表
-
filterChain.doFilter
-
(request.getRequest(), response.getResponse());
-
}
-
}
-
-
}
-
request.removeAttribute(Globals.JSP_FILE_ATTR);
-
} catch (ClientAbortException e) {
-
request.removeAttribute(Globals.JSP_FILE_ATTR);
-
throwable = e;
-
exception(request, response, e);
-
}
-
......
-
}
可以清晰的看到,注释部分里,先是能拿到相应的wrapper对象;然后完成加载wrapper对象中的servlet,例如如果是jsp,将完成jsp编译,然后加载servlet等;再然后,根据配置生成一个filter栈,通过执行栈,调用完所有的filter之后,就调用servlet,如果没有配置filter,就直接调用servlet,生成filter栈是通过request的URL模式匹配及servlet名称来实现的,具体涉及的东西在tomcat的servlet规范实现中再阐述吧。
以上,完成了一整套servlet调用的过程。通过上面的阐述,可以看见valve是个很灵活的机制,通过它可以实现很大的扩展。
Valve的应用及定制化
Tomcat除了提供上面提到的几个标准的valve实现外,也提供了一些用于调试程序的valve的实现。实现valve需要继承org.apache.catalina.valves.ValveBase基类。 以RequestDumperValve为例,
引用
org.apache.catalina.valves.RequestDumperValve
RequestDumperValve是打印出request及response信息的valve。其实现方法为:
Java代码
-
public void invoke(Request request, Response response)
-
throws IOException, ServletException {
-
-
Log log = container.getLogger();
-
-
// Log pre-service information
-
log.info("REQUEST URI =" + request.getRequestURI());
-
......
-
log.info(" queryString=" + request.getQueryString());
-
......
-
log.info("-------------------------------------------------------");
-
-
// 调用下一个valve
-
getNext().invoke(request, response);
-
-
// Log post-service information
-
log.info("-------------------------------------------------------");
-
......
-
log.info(" contentType=" + response.getContentType());
-
Cookie rcookies[] = response.getCookies();
-
for (int i = 0; i < rcookies.length; i++) {
-
log.info(" cookie=" + rcookies[i].getName() + "=" +
-
rcookies[i].getValue() + "; domain=" +
-
rcookies[i].getDomain() + "; path=" + rcookies[i].getPath());
-
}
-
String rhnames[] = response.getHeaderNames();
-
for (int i = 0; i < rhnames.length; i++) {
-
String rhvalues[] = response.getHeaderValues(rhnames[i]);
-
for (int j = 0; j < rhvalues.length; j++)
-
log.info(" header=" + rhnames[i] + "=" + rhvalues[j]);
-
}
-
log.info(" message=" + response.getMessage());
-
log.info("========================================================");
-
-
}
可以很清晰的看出,它打印出了request及response的信息,其中红色部分显示它调用valve链表中的下一个valve。我们可以这样配置它;
Xml代码
-
<Host name="localhost" appBase="webapps"
-
unpackWARs="true" autoDeploy="true"
-
xmlValidation="false" xmlNamespaceAware="false">
-
<Valve className="org.apache.catalina.valves.RequestDumperValve"/>
-
<Context path="/my" docBase=" /usr/local/tomcat/backup/my" >
-
</Context>
-
<Context path="/my2" docBase=" /usr/local/tomcat/backup/my" >
-
</Context>
-
</Host>
这样,只要访问此host下的所有context,都会打印出调试信息。 Valve的应用有很多,例如cluster,SSO等,会有专门一章来讲讲。Session管理是JavaEE容器比较重要的一部分,在app中也经常会用到。在开发app时,我们只是获取一个session,然后向session中存取数据,然后再销毁session。那么如何产生session,以及session池如何维护及管理,这些并没有在app涉及到。这些工作都是由容器来完成的。
Tomcat中主要由每个context容器内的一个Manager对象来管理session。对于这个manager对象的实现,可以根据tomcat提供的接口或基类来自己定制,同时,tomcat也提供了标准实现。
在tomcat架构分析(容器类)中已经介绍过,在每个context对象,即web app都具有一个独立的manager对象。通过server.xml可以配置定制化的manager,也可以不配置。不管怎样,在生成context对象时,都会生成一个manager对象。缺省的是StandardManager类,其类路径为:
引用
org.apache.catalina.session.StandardManager
Session对象也可以定制化实现,其主要实现标准servlet的session接口:
引用
javax.servlet.http.HttpSession
Tomcat也提供了标准的session实现:
引用
org.apache.catalina.session.StandardSession
本文主要就是结合消息流程介绍这两个类的实现,及session机制。
Session方面牵涉的东西还是蛮多的,例如HA,session复制是其中重要部分等,不过本篇主要从功能方面介绍session管理,有时间再说说扩展。
Session管理主要涉及到这几个方面:
-
创建session
-
注销session
-
持久化及启动加载session
创建session
在具体说明session的创建过程之前,先看一下BS访问模型吧,这样理解直观一点。

-
browser发送Http request;
-
tomcat内核Http11Processor会从HTTP request中解析出“jsessionid”(具体的解析过程为先从request的URL中解析,这是为了有的浏览器把cookie功能禁止后,将URL重写考虑的,如果解析不出来,再从cookie中解析相应的jsessionid),解析完后封装成一个request对象(当然还有其他的http header);
-
servlet中获取session,其过程是根据刚才解析得到的jsessionid(如果有的话),从session池(session maps)中获取相应的session对象;这个地方有个逻辑,就是如果jsessionid为空的话(或者没有其对应的session对象,或者有session对象,但此对象已经过期超时),可以选择创建一个session,或者不创建;
-
如果创建新session,则将session放入session池中,同时将与其相对应的jsessionid写入cookie通过Http response header的方式发送给browser,然后重复第一步。
以上是session的获取及创建过程。在servlet中获取session,通常是调用request的getSession方法。这个方法需要传入一个boolean参数,这个参数就是实现刚才说的,当jsessionid为空或从session池中获取不到相应的session对象时,选择创建一个新的session还是不创建。
看一下核心代码逻辑;
Java代码 
-
protected Session doGetSession(boolean create) {
-
-
……
-
// 先获取所在context的manager对象
-
Manager manager = null;
-
if (context != null)
-
manager = context.getManager();
-
if (manager == null)
-
return (null); // Sessions are not supported
-
-
//这个requestedSessionId就是从Http request中解析出来的
-
if (requestedSessionId != null) {
-
try {
-
//manager管理的session池中找相应的session对象
-
session = manager.findSession(requestedSessionId);
-
} catch (IOException e) {
-
session = null;
-
}
-
//判断session是否为空及是否过期超时
-
if ((session != null) && !session.isValid())
-
session = null;
-
if (session != null) {
-
//session对象有效,记录此次访问时间
-
session.access();
-
return (session);
-
}
-
}
-
-
// 如果参数是false,则不创建新session对象了,直接退出了
-
if (!create)
-
return (null);
-
if ((context != null) && (response != null) &&
-
context.getCookies() &&
-
response.getResponse().isCommitted()) {
-
throw new IllegalStateException
-
(sm.getString("coyoteRequest.sessionCreateCommitted"));
-
}
-
-
// 开始创建新session对象
-
if (connector.getEmptySessionPath()
-
&& isRequestedSessionIdFromCookie()) {
-
session = manager.createSession(getRequestedSessionId());
-
} else {
-
session = manager.createSession(null);
-
}
-
-
// 将新session的jsessionid写入cookie,传给browser
-
if ((session != null) && (getContext() != null)
-
&& getContext().getCookies()) {
-
Cookie cookie = new Cookie(Globals.SESSION_COOKIE_NAME,
-
session.getIdInternal());
-
configureSessionCookie(cookie);
-
response.addCookieInternal(cookie);
-
}
-
//记录session最新访问时间
-
if (session != null) {
-
session.access();
-
return (session);
-
} else {
-
return (null);
-
}
-
}
尽管不能贴出所有代码,但是上述的核心逻辑还是很清晰的。从中也可以看出,我们经常在servlet中这两种调用方式的不同;
新创建session
引用
request.getSession(); 或者request.getSession(true);
不创建session
引用
request.getSession(false);
接下来,看一下StandardManager的createSession方法,了解一下session的创建过程;
Java代码
-
public Session createSession(String sessionId) {
-
是个session数量控制逻辑,超过上限则抛异常退出
-
if ((maxActiveSessions >= 0) &&
-
(sessions.size() >= maxActiveSessions)) {
-
rejectedSessions++;
-
throw new IllegalStateException
-
(sm.getString("standardManager.createSession.ise"));
-
}
-
return (super.createSession(sessionId));
-
}
这个最大支持session数量maxActiveSessions是可以配置的,先不管这个安全控制逻辑,看其主逻辑,即调用其基类的createSession方法;
Java代码
-
public Session createSession(String sessionId) {
-
-
// 创建一个新的StandardSession对象
-
Session session = createEmptySession();
-
-
// Initialize the properties of the new session and return it
-
session.setNew(true);
-
session.setValid(true);
-
session.setCreationTime(System.currentTimeMillis());
-
session.setMaxInactiveInterval(this.maxInactiveInterval);
-
if (sessionId == null) {
-
//设置jsessionid
-
sessionId = generateSessionId();
-
}
-
session.setId(sessionId);
-
sessionCounter++;
-
return (session);
-
}
关键是jsessionid的产生过程,接着看generateSessionId方法;
Java代码
-
protected synchronized String generateSessionId() {
-
-
byte random[] = new byte[16];
-
String jvmRoute = getJvmRoute();
-
String result = null;
-
-
// Render the result as a String of hexadecimal digits
-
StringBuffer buffer = new StringBuffer();
-
do {
-
int resultLenBytes = 0;
-
if (result != null) {
-
buffer = new StringBuffer();
-
duplicates++;
-
}
-
-
while (resultLenBytes < this.sessionIdLength) {
-
getRandomBytes(random);
-
random = getDigest().digest(random);
-
for (int j = 0;
-
j < random.length && resultLenBytes < this.sessionIdLength;
-
j++) {
-
byte b1 = (byte) ((random[j] & 0xf0) >> 4);
-
byte b2 = (byte) (random[j] & 0x0f);
-
if (b1 < 10)
-
buffer.append((char) ('0' + b1));
-
else
-
buffer.append((char) ('A' + (b1 - 10)));
-
if (b2 < 10)
-
buffer.append((char) ('0' + b2));
-
else
-
buffer.append((char) ('A' + (b2 - 10)));
-
resultLenBytes++;
-
}
-
}
-
if (jvmRoute != null) {
-
buffer.append('.').append(jvmRoute);
-
}
-
result = buffer.toString();
-
//注意这个do…while结构
-
} while (sessions.containsKey(result));
-
return (result);
-
}
这里主要说明的不是生成jsessionid的算法了,而是这个do…while结构。把这个逻辑抽象出来,可以看出;
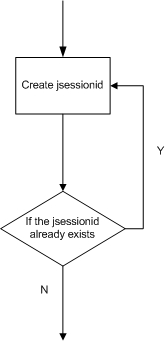
如图所示,创建jsessionid的方式是由tomcat内置的加密算法算出一个随机的jsessionid,如果此jsessionid已经存在,则重新计算一个新的,直到确保现在计算的jsessionid唯一。
好了,至此一个session就这么创建了,像上面所说的,返回时是将jsessionid以HTTP response的header:“Set-cookie”发给客户端。
注销session
Session创建完之后,不会一直存在,或是主动注销,或是超时清除。即是出于安全考虑也是为了节省内存空间等。例如,常见场景:用户登出系统时,会主动触发注销操作。
主动注销
主动注销时,是调用标准的servlet接口:
引用
session.invalidate();
看一下tomcat提供的标准session实现(StandardSession)
Java代码
-
public void invalidate() {
-
if (!isValidInternal())
-
throw new IllegalStateException
-
(sm.getString("standardSession.invalidate.ise"));
-
// 明显的注销方法
-
expire();
-
}
Expire方法的逻辑稍后再说,先看看超时注销,因为它们调用的是同一个expire方法。
超时注销
Tomcat定义了一个最大空闲超时时间,也就是说当session没有被操作超过这个最大空闲时间时间时,再次操作这个session,这个session就会触发expire。
这个方法封装在StandardSession中的isValid()方法内,这个方法在获取这个request请求对应的session对象时调用,可以参看上面说的创建session环节。也就是说,获取session的逻辑是,先从manager控制的session池中获取对应jsessionid的session对象,如果获取到,就再判断是否超时,如果超时,就expire这个session了。
看一下tomcat提供的标准session实现(StandardSession)
Java代码
-
public boolean isValid() {
-
……
-
//这就是判断距离上次访问是否超时的过程
-
if (maxInactiveInterval >= 0) {
-
long timeNow = System.currentTimeMillis();
-
int timeIdle = (int) ((timeNow - thisAccessedTime) / 1000L);
-
if (timeIdle >= maxInactiveInterval) {
-
expire(true);
-
}
-
}
-
return (this.isValid);
-
}
Expire方法
是时候来看看expire方法了。
Java代码
-
public void expire(boolean notify) {
-
-
synchronized (this) {
-
......
-
//设立标志位
-
setValid(false);
-
-
//计算一些统计值,例如此manager下所有session平均存活时间等
-
long timeNow = System.currentTimeMillis();
-
int timeAlive = (int) ((timeNow - creationTime)/1000);
-
synchronized (manager) {
-
if (timeAlive > manager.getSessionMaxAliveTime()) {
-
manager.setSessionMaxAliveTime(timeAlive);
-
}
-
int numExpired = manager.getExpiredSessions();
-
numExpired++;
-
manager.setExpiredSessions(numExpired);
-
int average = manager.getSessionAverageAliveTime();
-
average = ((average * (numExpired-1)) + timeAlive)/numExpired;
-
manager.setSessionAverageAliveTime(average);
-
}
-
-
// 将此session从manager对象的session池中删除
-
manager.remove(this);
-
......
-
}
-
}
不需要解释,已经很清晰了。
这个超时时间是可以配置的,缺省在tomcat的全局web.xml下配置,也可在各个app下的web.xml自行定义;
Xml代码
-
<session-config>
-
<session-timeout>30</session-timeout>
-
</session-config>
单位是分钟。
Session持久化及启动初始化
这个功能主要是,当tomcat执行安全退出时(通过执行shutdown脚本),会将session持久化到本地文件,通常在tomcat的部署目录下有个session.ser文件。当启动tomcat时,会从这个文件读入session,并添加到manager的session池中去。
这样,当tomcat正常重启时, session没有丢失,对于用户而言,体会不到重启,不影响用户体验。
看一下概念图吧,觉得不是重要实现逻辑,代码就不说了。

总结
由此可以看出,session的管理是容器层做的事情,应用层一般不会参与session的管理,也就是说,如果在应用层获取到相应的session,已经是由tomcat提供的,因此如果过多的依赖session机制来进行一些操作,例如访问控制,安全登录等就不是十分的安全,因为如果有人能得到正在使用的jsessionid,则就可以侵入系统。JNDI(Java Naming and Directory Interface,Java命名和目录接口)是一组在Java应用中访问命名和目录服务的API。命名服务将名称和对象联系起来,使得我们可以用名称访问对象。目录服务是一种命名服务,在这种服务里,对象不但有名称,还有属性。
---百度百科
通俗点说,JNDI封装了一个简单name到实体对象的mapping,通过字符串可以方便的得到想要的对象资源。通常这种对象资源有很多种,例如数据库JDBC,JMS,EJB等。平时用的最多的就是数据库了。在tomcat中,这些资源都是以java:comp/env开头的字符串来绑定的。以数据库连接为例,我们在app中的调用场景是;
Java代码 
-
//获得对数据源的引用:
-
Context ctx = new InitalContext();
-
DataSource ds = (DataSource) ctx.lookup("java:comp/env/jdbc/myDB");
-
//获得数据库连接对象:
-
Connection conn = ds.getConnection();
-
//返回数据库连接到连接池:
-
conn.close();
因为经常看到有人问怎么在tomcat中配置数据库连接池等问题,这篇文章就对tomcat中的JNDI的配置做一个小结,不涉及tomcat代码方面。tomcat架构分析 (JNDI体系绑定)从代码原理角度专门说明这些配置是如何生效,及app中调用JNDI API获取对象,其底层如何实现的。
Tomcat内部有一堆类型的resource配置。这些类型的resource的配置大体上可分为两个层次来进行,这两个层次是并列的关系,分别针对不同的开发部署方案设定的。
第一种方案
这种方案主要是对于快速部署而言,其核心是tomcat本身有一个global的resource池,新部署的app只引用其中已有的resouce,而不是创建新的resource。
先看看<tomcat>/conf/server.xml
Xml代码
-
<Server port="8005">
-
<GlobalNamingResources>
-
<Resource
-
name="jdbc/mysql"
-
type="javax.sql.DataSource"
-
username="root"
-
password="root"
-
driverClassName="com.mysql.jdbc.Driver"
-
maxIdle="200"
-
maxWait="5000"
-
url="……"
-
maxActive="100"/>
-
</GlobalNamingResources>
-
……
-
</Server>
这是一个全局的配置,这时如果每个具体的context(webapp)中如果要引用这个resource,则需要在各个context对象中配置 resourcelink,然后在各个app的web.xml中配置<resource-ref>.
<tomcat>/conf/server.xml
Xml代码
-
<Server port="8005">
-
<Service>
-
<Engine>
-
<Host>
-
<Context>
-
< ResourceLink globalname=" jdbc/mysql " name="myDB" type="…"/>
-
</Context>
-
</Host>
-
</Engine>
-
</Service>
-
……
-
</Server>
或者在每个app的Context.xml中配置
Xml代码
-
<Context>
-
< ResourceLink globalname=" jdbc/mysql " name="myDB" type="…"/>
-
</Context>
然后在app的WEB-INF/web.xml中配置
Xml代码
-
<web-app>
-
<resource-ref>
-
<description/>
-
<res-auth/>
-
<res-ref-name>myDB</res-ref-name>
-
<res-sharing-scope/>
-
<res-type/>
-
</resource-ref>
-
</web-app>
代码中这么调用
Java代码
-
//获得对数据源的引用:
-
Context ctx = new InitalContext();
-
DataSource ds = (DataSource) ctx.lookup("java:comp/env/myDB");
-
//获得数据库连接对象:
-
Connection conn = ds.getConnection();
-
//返回数据库连接到连接池:
-
conn.close();
由此可见,context中配置的ResourceLink属于一个中转的作用,这主要是为了在tomcat启动状态下,如果新部署一个app,可以在app中指定到相应的全局的resource。
它们的mapping关系是;

Tomcat这种资源不限于数据库连接,还有很多例如EJB,Web Service等,在配置中它们分别对应不同的节点。例如上面的数据库连接,在server.xml中对应<Resource>,在web.xml中对应的是<resource-ref>,EJB连接在server.xml中对应<Ejb>,在web.xml中对应的是<ejb-ref>等,因为有些资源在现在的开发中应用的不是很多,就不一一例举了,总结一下它们所有的对应关系;
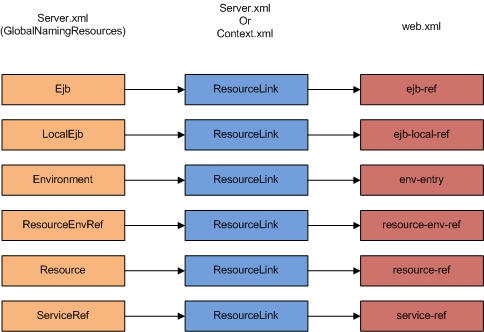
第二种方案
没有上述方案那么麻烦,主要是为了需要引用一个自己独有的资源对象的app而言。
<tomcat>/conf/server.xml
Xml代码
-
<Server port="8005">
-
<Service>
-
<Engine>
-
<Host>
-
<Context>
-
<Resource
-
name="jdbc/mysql"
-
type="javax.sql.DataSource"
-
username="root"
-
password="root"
-
driverClassName="com.mysql.jdbc.Driver"
-
maxIdle="200"
-
maxWait="5000"
-
url="……"
-
maxActive="100"/>
-
</Context>
-
</Host>
-
</Engine>
-
</Service>
-
……
-
</Server>
或者在每个app的Context.xml中配置
Xml代码
-
<Context>
-
<Resource
-
name="jdbc/mysql"
-
type="javax.sql.DataSource"
-
username="root"
-
password="root"
-
driverClassName="com.mysql.jdbc.Driver"
-
maxIdle="200"
-
maxWait="5000"
-
url="……"
-
maxActive="100"/>
-
</Context>
这种方式,不需要在app的WEB-INF/web.xml中再设定resource-ref了,直接在程序中就可lookup到相应的对象。
代码中这么调用
Java代码
-
//获得对数据源的引用:
-
Context ctx = new InitalContext();
-
DataSource ds = (DataSource) ctx.lookup("java:comp/env/jdbc/mysql");
-
//获得数据库连接对象:
-
Connection conn = ds.getConnection();
-
//返回数据库连接到连接池:
-
conn.close();
比较一下,两种方式的配置,调用java:comp/env的name时还是不一样的。以配置JDBC数据库连接为例,介绍了tomcat中常用的JNDI配置的几种用法。使用这种配置,在app里可以通过JNDI API非常简单的调用相应的资源对象。但是调用越简单,那其背后封装的逻辑越多。就好比汽车分为手动档自动挡一样。对司机而言,自动挡开起来会轻松很多,那是因为很多复杂的操作,已经封装起来由机器来完成了。
本篇就是从代码原理角度来揭示tomcat中JNDI的配置是如何生效的,以及app中的调用逻辑是如何实现的。通过这些,可以看到tomcat中一块比较重要的体系结构,同时加深对JNDI的理解。
上文介绍了两种配置方案,一个是global的配置,在各个app中引用;一个是各个app自己配置资源对象。这两种方案,从实现角度来看,原理一样,只是第一种比第二种多了一层mapping关系。所以为了方便理解,先从第二种方案,即各个app配置自己的资源对象来说明。
另外,需要说明的是,本章涉及的代码
-
Tomcat源码
-
JNDI源码(javax.naming.*),参考OpenJDK项目
先看一个概念图

JNDI体系分为三个部分;
-
在tomcat架构分析 (容器类)中介绍了StandardContext类,它是每个app的一个逻辑封装。当tomcat初始化时,将根据配置文件,对StandardContext中的NamingResources对象进行赋值,同时,将实例化一个NamingContextListener对象作为这个context作用域内的事件监听器,它会响应一些例如系统启动,系统关闭等事件,作出相应的操作;
-
初始化完成后,tomcat启动,完成启动逻辑,抛出一个系统启动event,由那个NamingContextListener捕获,进行处理,将初始化时的NamingResources对象中的数据,绑定到相应的JNDI对象树(namingContext)上,即java:comp/env分支,然后将这个根namingContext与这个app的classloader进行绑定,这样每个app只有在自己的JNDI对象树上调用,互不影响;
-
每个app中的类都由自己app的classloader加载,如果需要用到JNDI绑定对象,也是从自己classloader对应的JNDI对象树上获取资源对象
这里需要说明的是,在后面会经常涉及到两类context,一个是作为tomcat内部实现逻辑的容器StandardContext;一个是作为JNDI内部分支对象NamingContext;它们实现不同接口,互相没有任何关系,不要混淆。
开始看看每个部分详细情况吧。
初始化NamingResources
先看看配置;
<tomcat>/conf/server.xml
Xml代码 
-
<Server port="8005">
-
<Service>
-
<Engine>
-
<Host>
-
<Context>
-
<Resource
-
name="jdbc/mysql"
-
type="javax.sql.DataSource"
-
username="root"
-
password="root"
-
driverClassName="com.mysql.jdbc.Driver"
-
maxIdle="200"
-
maxWait="5000"
-
url="……"
-
maxActive="100"/>
-
-
</Context>
-
</Host>
-
</Engine>
-
</Service>
-
……
-
</Server>
通过这个配置,可以非常清楚的看出tomcat内部的层次结构,不同的层次实现不同的作用域,同时每个层次都有相应的类进行逻辑封装,这是tomcat面向对象思想的体现。那么相应的,Context节点下的Resource节点也有类进行封装;
Java代码
-
org.apache.catalina.deploy.ContextResource
上面例子中Resource节点配置的所有属性会以键值对的方式存入ContextResource的一个HashMap对象中,这一步只是初始化,不会用到每个属性,它只是为了每个真正处理的资源对象用到,例如后面会说的缺省的tomcat的数据库连接池对象BasicDataSourceFactory,如果用其他的数据库连接池,例如c3p0,那么其配置的属性对象就应该按照c3p0中需要的属性名称来配。
但是,这些属性中的name和type是ContextResource需要的,name是JNDI对象树的分支节点,上面配的“jdbc/mysql”,那么这个数据库连接池对象就对应在“java:comp/env/jdbc/mysql”的位置。type是这个对象的类型,如果是“javax.sql.DataSource”,tomcat会有一些特殊的逻辑处理。
当tomcat初始化时,StandardContext对象内部会生成一个NamingResources对象,这个对象就是做一些预处理,存储一些Resource对象,看一下NamingResources存储Resource对象的逻辑;
Java代码
-
public void addResource(ContextResource resource) {
-
//确保每一个资源对象的name都是唯一的
-
//不仅是Resource对象之间,包括Service等所有的资源对象
-
if (entries.containsKey(resource.getName())) {
-
return;
-
} else {
-
entries.put(resource.getName(), resource.getType());
-
}
-
//建立一个name和资源对象的mapping
-
synchronized (resources) {
-
resource.setNamingResources(this);
-
resources.put(resource.getName(), resource);
-
}
-
support.firePropertyChange("resource", null, resource);
-
}
需要说明的是,不仅仅是Resource一种对象,还有Web Service资源对象,EJB对象等,这里就是拿数据库连接的Resource对象举例。
启动JNDI绑定
当tomcat启动时,会抛出一个start event,由StandardContext的NamingContextListener监听对象捕捉到,响应start event。
Java代码
-
public void lifecycleEvent(LifecycleEvent event) {
-
-
container = event.getLifecycle();
-
-
if (container instanceof Context) {
-
//这个namingResources对象就是StandardContext的namingResources对象
-
namingResources = ((Context) container).getNamingResources();
-
logger = log;
-
} else if (container instanceof Server) {
-
namingResources = ((Server) container).getGlobalNamingResources();
-
} else {
-
return;
-
}
-
//响应start event
-
if (event.getType() == Lifecycle.START_EVENT) {
-
-
if (initialized)
-
return;
-
Hashtable contextEnv = new Hashtable();
-
try {
-
//生成这个StandardContext域的JNDI对象树根NamingContext对象
-
namingContext = new NamingContext(contextEnv, getName());
-
} catch (NamingException e) {
-
// Never happens
-
}
-
ContextAccessController.setSecurityToken(getName(), container);
-
//将此StandardContext对象与JNDI对象树根NamingContext对象绑定
-
ContextBindings.bindContext(container, namingContext, container);
-
if( log.isDebugEnabled() ) {
-
log.debug("Bound " + container );
-
}
-
// Setting the context in read/write mode
-
ContextAccessController.setWritable(getName(), container);
-
try {
-
//将初始化时的资源对象绑定JNDI对象树
-
createNamingContext();
-
} catch (NamingException e) {
-
logger.error
-
(sm.getString("naming.namingContextCreationFailed", e));
-
}
-
-
// 针对Context下配置Resource对象而言
-
if (container instanceof Context) {
-
// Setting the context in read only mode
-
ContextAccessController.setReadOnly(getName());
-
try {
-
//通过此StandardContext对象获取到JNDI对象树根NamingContext对象
-
//同时将此app的classloader与此JNDI对象树根NamingContext对象绑定
-
ContextBindings.bindClassLoader
-
(container, container,
-
((Container) container).getLoader().getClassLoader());
-
} catch (NamingException e) {
-
logger.error(sm.getString("naming.bindFailed", e));
-
}
-
}
-
// 针对global资源而言,这里不用关注
-
if (container instanceof Server) {
-
namingResources.addPropertyChangeListener(this);
-
org.apache.naming.factory.ResourceLinkFactory.setGlobalContext
-
(namingContext);
-
try {
-
ContextBindings.bindClassLoader
-
(container, container,
-
this.getClass().getClassLoader());
-
} catch (NamingException e) {
-
logger.error(sm.getString("naming.bindFailed", e));
-
}
-
if (container instanceof StandardServer) {
-
((StandardServer) container).setGlobalNamingContext
-
(namingContext);
-
}
-
}
-
initialized = true;
-
}
-
//响应stop event
-
else if (event.getType() == Lifecycle.STOP_EVENT) {
-
......
-
}
-
}
注意上面方法中有两层绑定关系;
ContextBindings.bindContext()
Java代码
-
public static void bindContext(Object name, Context context,
-
Object token) {
-
if (ContextAccessController.checkSecurityToken(name, token))
-
//先是将StandardContext对象与JNDI对象树根NamingContext对象绑定
-
//注意,这里第一个参数name是StandardContext对象
-
contextNameBindings.put(name, context);
-
}
ContextBindings.bindClassLoader()
Java代码
-
public static void bindClassLoader(Object name, Object token,
-
ClassLoader classLoader)
-
throws NamingException {
-
if (ContextAccessController.checkSecurityToken(name, token)) {
-
//根据上面的StandardContext对象获取刚才绑定的NamingContext对象
-
Context context = (Context) contextNameBindings.get(name);
-
if (context == null)
-
throw new NamingException
-
(sm.getString("contextBindings.unknownContext", name));
-
//将classloader与NamingContext对象绑定
-
clBindings.put(classLoader, context);
-
clNameBindings.put(classLoader, name);
-
}
-
}
主要看一下将初始化时的资源对象绑定JNDI对象树的createNamingContext()方法;
Java代码
-
private void createNamingContext()
-
throws NamingException {
-
-
// Creating the comp subcontext
-
if (container instanceof Server) {
-
compCtx = namingContext;
-
envCtx = namingContext;
-
} else {
-
//对于StandardContext而言,在JNDI对象树的根namingContext对象上
-
//建立comp树枝,以及在comp树枝上建立env树枝namingContext对象
-
compCtx = namingContext.createSubcontext("comp");
-
envCtx = compCtx.createSubcontext("env");
-
}
-
......
-
// 从初始化的NamingResources对象中获取Resource对象加载到JNDI对象树上
-
ContextResource[] resources = namingResources.findResources();
-
for (i = 0; i < resources.length; i++) {
-
addResource(resources[i]);
-
}
-
......
-
}
看一下addResource的具体加载逻辑;
Java代码
-
public void addResource(ContextResource resource) {
-
-
// Create a reference to the resource.
-
Reference ref = new ResourceRef
-
(resource.getType(), resource.getDescription(),
-
resource.getScope(), resource.getAuth());
-
// 遍历Resource对象的各个属性,这些属性存在一个HashMap中
-
Iterator params = resource.listProperties();
-
while (params.hasNext()) {
-
String paramName = (String) params.next();
-
String paramValue = (String) resource.getProperty(paramName);
-
//封装成StringRefAddr,这些都是JNDI的标准API
-
StringRefAddr refAddr = new StringRefAddr(paramName, paramValue);
-
ref.add(refAddr);
-
}
-
try {
-
if (logger.isDebugEnabled()) {
-
logger.debug(" Adding resource ref "
-
+ resource.getName() + " " + ref);
-
}
-
//在上面创建的comp/env树枝节点上,根据Resource配置的name继续创建新的节点
-
//例如配置的name=”jdbc/mysql”,则在comp/env树枝节点下再创建一个jdbc树枝节点
-
createSubcontexts(envCtx, resource.getName());
-
//绑定叶子节点,它不是namingContext对象,而是最后的Resource对象
-
envCtx.bind(resource.getName(), ref);
-
} catch (NamingException e) {
-
logger.error(sm.getString("naming.bindFailed", e));
-
}
-
//这就是上面说的对于配置type="javax.sql.DataSource"时的特殊逻辑
-
//将数据库连接池类型的资源对象注册到tomcat全局的JMX中,方便管理及调试
-
if ("javax.sql.DataSource".equals(ref.getClassName())) {
-
try {
-
ObjectName on = createObjectName(resource);
-
Object actualResource = envCtx.lookup(resource.getName());
-
Registry.getRegistry(null, null).registerComponent(actualResource, on, null);
-
objectNames.put(resource.getName(), on);
-
} catch (Exception e) {
-
logger.warn(sm.getString("naming.jmxRegistrationFailed", e));
-
}
-
}
-
}
这就是上面配置的jdbc/mysql数据库连接池的JNDI对象树;
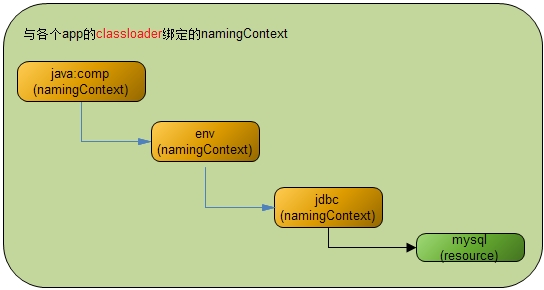
到目前为止,完成了JNDI对象树的绑定,可以看到,每个app对应的StandardContext对应一个JNDI对象树,并且每个app的各个classloader与此JNDI对象树分别绑定,那么各个app之间的JNDI可以不互相干扰,各自配置及调用。
需要注意的是,NamingContext对象就是JNDI对象树上的树枝节点,类似文件系统中的目录,各个Resource对象则是JNDI对象树上的叶子节点,类似文件系统的具体文件,通过NamingContext对象将整个JNDI对象树组织起来,每个Resource对象才是真正存储数据的地方。
本篇就描述tomcat内部是如何构造JNDI对象树的,如何通过JNDI获取对象,涉及到JNDI API内部运作了,将在另一篇中继续。connector组件是service容器中的一部分。它主要是接收,解析http请求,然后调用本service下的相关servlet。由于tomcat从架构上采用的是一个分层结构,因此根据解析过的http请求,定位到相应的servlet也是一个相对比较复杂的过程。
整个connector实现了从接收socket到调用servlet的全部过程。先来看一下connector的功能逻辑;
-
接收socket
-
从socket获取数据包,并解析成HttpServletRequest对象
-
从engine容器开始走调用流程,经过各层valve,最后调用servlet完成业务逻辑
-
返回response,关闭socket
可以看出,整个connector组件是tomcat运行主干,之前介绍的各个模块都是tomcat启动时,静态创建好的,通过connector将这些模块串了起来。
通常在实际运行中,特别是对于一些互联网应用而言,网络吞吐一直是整个服务的瓶颈所在,因此,connector的运行效率在一定程度上影响了tomcat的整体性能。相对来说,tomcat在处理静态页面方面一直有一些瓶颈,因此通常的服务架构都是前端类似nginx的web服务器,后端挂上tomcat作为应用服务器(当然还有些其他原因,例如负载均衡等)。Tomcat在connector的优化上做了一些特殊的处理,这些都是可选的,通过部署,配置方便完成,例如APR(Apache Portable Runtime),BIO,NIO等。
目前connector支持的协议是HTTP和AJP。AJP是Apache与其他服务器之间的通信协议。通常在集群环境中,例如前端web服务器和后端应用服务器或servlet容器,使用AJP会比HTTP有更好的性能,这里引述apache官网上的一段话“ If integration with the native webserver is needed for any reason, an AJP connector will provide faster performance than proxied HTTP. AJP clustering is the most efficient from the Tomcat perspective. It is otherwise functionally equivalent to HTTP clustering.”
本篇主要是针对HTTP协议的connector进行阐述。先来看一下connector的配置,在server.xml里;
Xml代码 
-
<Connector port="80" URIEncoding="UTF-8" protocol="HTTP/1.1"
-
connectionTimeout="20000"
-
redirectPort="7443" />
熟悉的80端口不必说了。“protocol”这里是指这个connector支持的协议。针对HTTP协议而言,这个属性可以配置的值有:
-
HTTP/1.1
-
org.apache.coyote.http11.Http11Protocol –BIO实现
-
org.apache.coyote.http11.Http11NioProtocol –NIO实现
-
定制的接口
配置“HTTP/1.1”和“org.apache.coyote.http11.Http11Protocol”的效果是一样的,因此connector的HTTP协议实现缺省是支持BIO的。无论是BIO还是NIO都是实现一个org.apache.coyote.ProtocolHandler接口,因此如果需要定制化,也必须实现这个接口。
本篇就来看看缺省状态下HTTP connector的架构及其消息流。
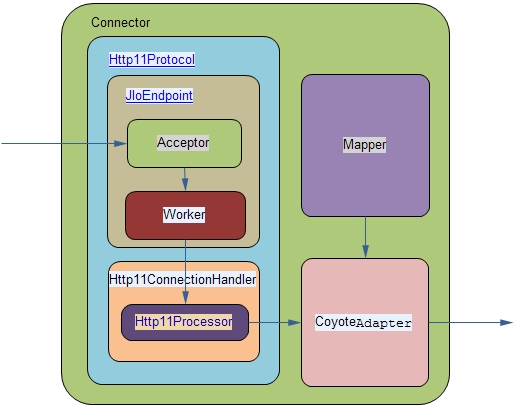
可以看见connector中三大块
-
Http11Protocol
-
Mapper
-
CoyoteAdapter
Http11Protocol
类全路径org.apache.coyote.http11.Http11Protocol,这是支持http的BIO实现。 Http11Protocol包含了JIoEndpoint对象及Http11ConnectionHandler对象。
Http11ConnectionHandler对象维护了一个Http11Processor对象池,Http11Processor对象会调用CoyoteAdapter完成http request的解析和分派。
JIoEndpoint维护了两个线程池,Acceptor及Worker。Acceptor是接收socket,然后从Worker线程池中找出空闲的线程处理socket,如果worker线程池没有空闲线程,则Acceptor将阻塞。Worker是典型的线程池实现。Worker线程拿到socket后,就从Http11Processor对象池中获取Http11Processor对象,进一步处理。除了这个比较基础的Worker线程池,也可以通过基于java concurrent 系列的java.util.concurrent.ThreadPoolExecutor线程池实现,不过需要在server.xml中配置相应的节点,即在connector同级别配置<Executor>,配置完后,使用ThreadPoolExecutor与Worker在实现上没有什么大的区别,就不赘述了。
Xml代码
-
<Executor name="tomcatThreadPool" namePrefix="catalina-exec-"
-
maxThreads="150" minSpareThreads="4"/>
图中的箭头代表了消息流。
Mapper
类全路径org.apache.tomcat.util.http.mapper.Mapper,此对象维护了一个从Host到Wrapper的各级容器的快照。它主要是为了,当http request被解析后,能够将http request绑定到相应的servlet进行业务处理。前面的文章中已经说明,在加载各层容器时,会将它们注册到JMX中。
所以当connector组件启动的时候,会从JMX中查询出各层容器,然后再创建这个Mapper对象中的快照。
CoyoteAdapter
全路径org.apache.catalina.connector.CoyoteAdapter,此对象负责将http request解析成HttpServletRequest对象,之后绑定相应的容器,然后从engine开始逐层调用valve直至该servlet。在session管理中,已经说明,根据request中的jsessionid绑定服务器端的相应session。这个jsessionid按照优先级或是从request url中获取,或是从cookie中获取,然后再session池中找到相应匹配的session对象,然后将其封装到HttpServletRequest对象。所有这些都是在CoyoteAdapter中完成的。看一下将request解析为HttpServletRequest对象后,开始调用servlet的代码;
Java代码
-
connector.getContainer().getPipeline().getFirst().invoke(request, response);
connector的容器就是StandardEngine,代码的可读性很强,获取StandardEngine的pipeline,然后从第一个valve开始调用逻辑,相应的过程请参照tomcat架构分析(valve机制)。配置的connector的内部构造及消息流,同时此connector也是基于BIO的实现。除了BIO外,也可以通过配置快速部署NIO的connector。在server.xml中如下配置;
Xml代码 
-
<Connector port="80" URIEncoding="UTF-8" protocol="org.apache.coyote.http11.Http11NioProtocol"
-
connectionTimeout="20000"
-
redirectPort="7443" />
整个tomcat是一个比较完善的框架体系,各个组件之间都是基于接口的实现,所以比较方便扩展和替换。像这里的“org.apache.coyote.http11.Http11NioProtocol”和BIO的“org.apache.coyote.http11.Http11Protocol”都是统一的实现org.apache.coyote.ProtocolHandler接口,所以从整体结构上来说,NIO还是与BIO的实现保持大体一致。
首先来看一下NIO connector的内部结构,箭头方向还是消息流;
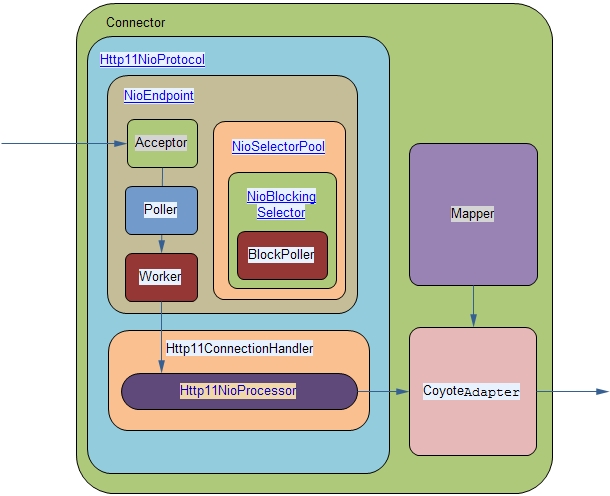
还是可以看见connector中三大块
-
Http11NioProtocol
-
Mapper
-
CoyoteAdapter
基本功能与BIO的类似,参见tomcat架构分析(connector BIO实现)。重点看看Http11NioProtocol.
和JIoEndpoint一样,NioEndpoint是Http11NioProtocol中负责接收处理socket的主要模块。但是在结构上比JIoEndpoint要复杂一些,毕竟是非阻塞的。但是需要注意的是,tomcat的NIO connector并非完全是非阻塞的,有的部分,例如接收socket,从socket中读写数据等,还是阻塞模式实现的,在后面会逐一介绍。
如图所示,NioEndpoint的主要流程;

图中Acceptor及Worker分别是以线程池形式存在,Poller是一个单线程。注意,与BIO的实现一样,缺省状态下,在server.xml中没有配置<Executor>,则以Worker线程池运行,如果配置了<Executor>,则以基于java concurrent 系列的java.util.concurrent.ThreadPoolExecutor线程池运行。
Acceptor
接收socket线程,这里虽然是基于NIO的connector,但是在接收socket方面还是传统的serverSocket.accept()方式,获得SocketChannel对象,然后封装在一个tomcat的实现类org.apache.tomcat.util.net.NioChannel对象中。然后将NioChannel对象封装在一个PollerEvent对象中,并将PollerEvent对象压入events queue里。这里是个典型的生产者-消费者模式,Acceptor与Poller线程之间通过queue通信,Acceptor是events queue的生产者,Poller是events queue的消费者。
Poller
Poller线程中维护了一个Selector对象,NIO就是基于Selector来完成逻辑的。在connector中并不止一个Selector,在socket的读写数据时,为了控制timeout也有一个Selector,在后面的BlockSelector中介绍。可以先把Poller线程中维护的这个Selector标为主Selector。
Poller是NIO实现的主要线程。首先作为events queue的消费者,从queue中取出PollerEvent对象,然后将此对象中的channel以OP_READ事件注册到主Selector中,然后主Selector执行select操作,遍历出可以读数据的socket,并从Worker线程池中拿到可用的Worker线程,然后将socket传递给Worker。整个过程是典型的NIO实现。
Worker
Worker线程拿到Poller传过来的socket后,将socket封装在SocketProcessor对象中。然后从Http11ConnectionHandler中取出Http11NioProcessor对象,从Http11NioProcessor中调用CoyoteAdapter的逻辑,跟BIO实现一样。在Worker线程中,会完成从socket中读取http request,解析成HttpServletRequest对象,分派到相应的servlet并完成逻辑,然后将response通过socket发回client。在从socket中读数据和往socket中写数据的过程,并没有像典型的非阻塞的NIO的那样,注册OP_READ或OP_WRITE事件到主Selector,而是直接通过socket完成读写,这时是阻塞完成的,但是在timeout控制上,使用了NIO的Selector机制,但是这个Selector并不是Poller线程维护的主Selector,而是BlockPoller线程中维护的Selector,称之为辅Selector。
NioSelectorPool
NioEndpoint对象中维护了一个NioSelecPool对象,这个NioSelectorPool中又维护了一个BlockPoller线程,这个线程就是基于辅Selector进行NIO的逻辑。以执行servlet后,得到response,往socket中写数据为例,最终写的过程调用NioBlockingSelector的write方法。
Java代码
-
public int write(ByteBuffer buf, NioChannel socket, long writeTimeout,MutableInteger lastWrite) throws IOException {
-
SelectionKey key = socket.getIOChannel().keyFor(socket.getPoller().getSelector());
-
if ( key == null ) throw new IOException("Key no longer registered");
-
KeyAttachment att = (KeyAttachment) key.attachment();
-
int written = 0;
-
boolean timedout = false;
-
int keycount = 1; //assume we can write
-
long time = System.currentTimeMillis(); //start the timeout timer
-
try {
-
while ( (!timedout) && buf.hasRemaining()) {
-
if (keycount > 0) { //only write if we were registered for a write
-
//直接往socket中写数据
-
int cnt = socket.write(buf); //write the data
-
lastWrite.set(cnt);
-
if (cnt == -1)
-
throw new EOFException();
-
written += cnt;
-
//写数据成功,直接进入下一次循环,继续写
-
if (cnt > 0) {
-
time = System.currentTimeMillis(); //reset our timeout timer
-
continue; //we successfully wrote, try again without a selector
-
}
-
}
-
//如果写数据返回值cnt等于0,通常是网络不稳定造成的写数据失败
-
try {
-
//开始一个倒数计数器
-
if ( att.getWriteLatch()==null || att.getWriteLatch().getCount()==0) att.startWriteLatch(1);
-
//将socket注册到辅Selector,这里poller就是BlockSelector线程
-
poller.add(att,SelectionKey.OP_WRITE);
-
//阻塞,直至超时时间唤醒,或者在还没有达到超时时间,在BlockSelector中唤醒
-
att.awaitWriteLatch(writeTimeout,TimeUnit.MILLISECONDS);
-
}catch (InterruptedException ignore) {
-
Thread.interrupted();
-
}
-
if ( att.getWriteLatch()!=null && att.getWriteLatch().getCount()> 0) {
-
keycount = 0;
-
}else {
-
//还没超时就唤醒,说明网络状态恢复,继续下一次循环,完成写socket
-
keycount = 1;
-
att.resetWriteLatch();
-
}
-
-
if (writeTimeout > 0 && (keycount == 0))
-
timedout = (System.currentTimeMillis() - time) >= writeTimeout;
-
} //while
-
if (timedout)
-
throw new SocketTimeoutException();
-
} finally {
-
poller.remove(att,SelectionKey.OP_WRITE);
-
if (timedout && key != null) {
-
poller.cancelKey(socket, key);
-
}
-
}
-
return written;
-
}
也就是说当socket.write()返回0时,说明网络状态不稳定,这时将socket注册OP_WRITE事件到辅Selector,由BlockPoller线程不断轮询这个辅Selector,直到发现这个socket的写状态恢复了,通过那个倒数计数器,通知Worker线程继续写socket动作。看一下BlockSelector线程的逻辑;
Java代码
-
public void run() {
-
while (run) {
-
try {
-
......
-
-
Iterator iterator = keyCount > 0 ? selector.selectedKeys().iterator() : null;
-
while (run && iterator != null && iterator.hasNext()) {
-
SelectionKey sk = (SelectionKey) iterator.next();
-
KeyAttachment attachment = (KeyAttachment)sk.attachment();
-
try {
-
attachment.access();
-
iterator.remove(); ;
-
sk.interestOps(sk.interestOps() & (~sk.readyOps()));
-
if ( sk.isReadable() ) {
-
countDown(attachment.getReadLatch());
-
}
-
//发现socket可写状态恢复,将倒数计数器置位,通知Worker线程继续
-
if (sk.isWritable()) {
-
countDown(attachment.getWriteLatch());
-
}
-
}catch (CancelledKeyException ckx) {
-
if (sk!=null) sk.cancel();
-
countDown(attachment.getReadLatch());
-
countDown(attachment.getWriteLatch());
-
}
-
}//while
-
}catch ( Throwable t ) {
-
log.error("",t);
-
}
-
}
-
events.clear();
-
try {
-
selector.selectNow();//cancel all remaining keys
-
}catch( Exception ignore ) {
-
if (log.isDebugEnabled())log.debug("",ignore);
-
}
-
}
使用这个辅Selector主要是减少线程间的切换,同时还可减轻主Selector的负担。以上描述了NIO connector工作的主要逻辑,可以看到在设计上还是比较精巧的。NIO connector还有一块就是Comet,有时间再说吧。需要注意的是,上面从Acceptor开始,有很多对象的封装,NioChannel及其KeyAttachment,PollerEvent和SocketProcessor对象,这些不是每次都重新生成一个新的,都是NioEndpoint分别维护了它们的对象池;
Java代码
-
ConcurrentLinkedQueue<SocketProcessor> processorCache = new ConcurrentLinkedQueue<SocketProcessor>()
-
ConcurrentLinkedQueue<KeyAttachment> keyCache = new ConcurrentLinkedQueue<KeyAttachment>()
-
ConcurrentLinkedQueue<PollerEvent> eventCache = new ConcurrentLinkedQueue<PollerEvent>()
-
ConcurrentLinkedQueue<NioChannel> nioChannels = new ConcurrentLinkedQueue<NioChannel>()
当需要这些对象时,分别从它们的对象池获取,当用完后返回给相应的对象池,这样可以减少因为创建及GC对象时的性能消耗。
(责任编辑:IT) |