简介
概览
本书所讲述内容适用于tomcat版本4.1.12至5.0.18。
适合读者
jsp/servlet开发人员,想了解tomcat内部机制的coder;
想加入tomcat开发团队的coder;
web开发人员,但对软件开发很有兴趣的coder;
想要对tomcat进行定制的coder。
在阅读之前,希望你已经对java中的面向对象和servlet开发有所了解。
servlet容器是如何工作的
servlet容器是一个挺复杂的系统。但是,基本上,针对一个servlet的request请求,servlet需要做一下三件事:
l 创建一个实现了javax.servlet.ServletRequest接口或javax.servlet.http.ServletRequest接口的Request对象,并用请求参数、请求头(headers)、cookies、查询字符串、uri等信息填充该Request对象;
l 创建一个实现了javax.servlet.ServletResponse接口或javax.servlet.http.ServletResponse接口的Response对象;
l 调用相应的servlet的服务方法,将先前创建的request对象和response对象作为参数传入。接收请求的servlet从request对象中读取信息,并将返回值写入到response对象。
catalina结构图
catalina本身是一个成熟的软件,设计开发结构十分优雅,功能结构模块化。从servlet容器的功能角度看,catalian可以划分为两大模块:connector模块和container模块。
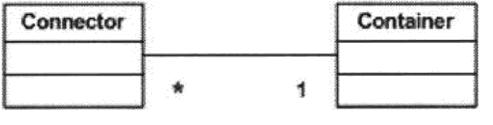
图表 1 Catalina功能总体划分图
这里connector的功能是将用户请求与container连接。connector的任务的是为每个接收到的HTTP请求建立request对象和response对象。然后,将处理过程交给container模块。container模块从connector模块中接收到request对象和response对象,并负责调用相应的servlet的服务方法。
当然,上面只是对这个处理过程的简化描述。在处理过程中,container还要做很多其他的事。例如,在调用servlet的服务方法前,它必须载入该servlet,对用户身份进行认证(需要的话),更新该用户的session对象等。
tomcat的版本4和版本5
区别如下:
l tomcat5支持servlet2.4和jsp2.0规范,tomcat4支持servlet2.3和jsp1.2规范;
l tomcat5默认的connector比tomcat4默认的connector执行效率更高;
l 在tomcat后台处理上,tomcat5是共享线程的,而tomcat4的组件都使用各自的线程,从这方面讲,tomcat5所消耗的资源更少;
l tomcat5不需要映射组件来查找子组件,因此,代码量更少,更简单。
章节简介
本书共20章,前两章是简介内容。
第1章介绍了HTTP服务器是如何工作的,第2章介绍了一个简单的servlet容器。接下来两章着重于connector的说明,从第5章到第20章着个介绍container中的各个组件(component)。
第1章 一个简单的Web服务器
本章介绍了java web服务器是如何运行的,简要介绍HTTP协议。一个java web服务器会使用两个很重要的类,java.net.Socket和java.net.ServerSocket,并通过HTTP消息与客户端进行通信。
 1.1 The Hypertext Transfer Protocol (HTTP) 1.1 The Hypertext Transfer Protocol (HTTP)
HTTP协议是基于请求-响应的协议,客户端请求一个文件,服务器对该请求进行响应。HTTP使用TCP协议,默认使用80端口。最初的HTTP协议版本是HTTP/0.9,后被HTTP/1.0替代。目前使用的版本是HTTP/1.1,该协议定义于Request for Comments (RFC) 2616。
在HTTP协议中,总是由主动建立连接、发送HTTP请求的客户端来初始化一个事务。服务器不负责连接客户端,或创建一个到客户端的回调连接(callback connection)。
1.2 HTTP Request
一个HTTP请求包含以下三部分:
l Method—Uniform Resource Identifier (URI)—Protocol/Version
l Request headers
l Entity body
举例如下(注意三部分之间要有空行):
java代码:
-
POST /examples/default.jsp HTTP/1.1
-
Accept: text/plain; text/html
-
Accept-Language: en-gb
-
Connection: Keep-Alive
-
Host: localhost
-
User-Agent: Mozilla/4.0 (compatible; MSIE 4.01; Windows 98)
-
Content-Length: 33
-
Content-Type: application/x-www-form-urlencoded
-
Accept-Encoding: gzip, deflate
-
-
lastName=Franks&firstName=Michael
每个HTTP请求都会有一个请求方法,HTTP1.1中支持的方法包括,GET、POST、HEAD、OPTIONS、PUT、DELETE和TRACE。互联网应用中最常用的是GET和POST。
URI指明了请求资源的地址,通常是从网站更目录开始计算的一个相对路径,因此它总是以斜线“/”开头的。URL实际上是URI的一种类型(参见http://www.ietf.org/rfc/rfc2396.txt))。
请求头(header)中包含了一些关于客户端环境和请求实体(entity)的有用的信息。例如,客户端浏览器所使用的语言,请求实体信息的长度等。每个请求头使用CRLF(回车换行符,“\r\n”)分隔。注意请求头的格式:
请求头名+英文空格+请求头值
请求头和请求实体之间有一个空白行(CRLF)。这是HTTP协议规定的格式。HTTP服务器,以此确定请求实体是从哪里开始的。上面的例子中,请求实体是:
java代码:
-
lastName=Franks&firstName=Michael
1.3 HTTP Response
与HTTP Request类似,HTTP Response也由三部分组成:
l Protocol—Status code—Description
l Response headers
l Entity body
举例如下:
java代码:
-
HTTP/1.1 200 OK
-
Server: Microsoft-IIS/4.0
-
Date: Mon, 5 Jan 2004 13:13:33 GMT
-
Content-Type: text/html
-
Last-Modified: Mon, 5 Jan 2004 13:13:12 GMT
-
Content-Length: 112
-
-
<html>
-
<head>
-
<title>HTTP Response Example</title>
-
</head>
-
<body>
-
Welcome to Brainy Software
-
</body>
-
</html>
注意响应实体(entity)与响应头(header)之间有一个空白行(CRLF)。
1.4 Socket类
socket通信的实例代码如下:
java代码:
-
Socket socket = new Socket("127.0.0.1", "8080"); //建立连接
-
OutputStream os = socket.getOutputStream(); //获取输出流
-
boolean autoflush = true;
-
PrintWriter out = new PrintWriter(
-
socket.getOutputStream(), autoflush); //设置自动flush
-
BufferedReader in = new BufferedReader(
-
new InputStreamReader( socket.getInputstream() ));
-
-
// send an HTTP request to the web server
-
out.println("GET /index.jsp HTTP/1.1"); //拼装HTTP请求信息
-
out.println("Host: localhost:8080");
-
-
out.println("Connection: Close");
-
out.println();
-
-
// read the response
-
boolean loop = true;
-
StringBuffer sb = new StringBuffer(8096);
-
while (loop) {
-
if ( in.ready() ) {
-
int i=0;
-
while (i!=-1) {
-
i = in.read();
-
sb.append((char) i);
-
}
-
loop = false;
-
}
-
Thread.currentThread().sleep(50); //由于是阻塞写入,暂停50ms,保证可以写入。
-
}
-
-
// display the response to the out console
-
System.out.println(sb.toString());
-
socket.close();
1.5 ServerSocket类
Socket类表示一个客户端socket,相应的ServerSocket类表示了一个服务器端应用。服务器端socket需要等待来自客户端的连接请求。一旦ServerSocket接收到来自客户端的连接请求,它会实例化一个Socket类的对象来处理与客户端的通信。
1.6 应用举例
该程序包括三个部分,HttpServer、Request和Response。该程序只能发送静态资源,如HTML文件,图片文件,但不会发送响应头信息。
第2章 一个简单的servlet容器
2.1 简述
本章通过两个小程序说明如何开发一个自己的servlet容器。第一个程序的设计非常简单,仅仅用于说明servlet容器是如何运行的。第二个稍微复杂一点点,会调用第一个程序。这两个servlet容器都能处理简单的servlet和静态资源。PrimitiveServlet类可用于测试servlet容器。
注意,每一章内容中都会调用前一章的应用程序,直到第17章完成一个完整的servlet容器。
2.2 javax.servlet.Servlet接口
Servlet接口需要实现下面的5个方法:
l public void init(ServletConfig config) throws ServletException
l public void service(ServletRequest request, ServletResponse response) throws ServletException, java.io.IOException
l public void destroy()
l public ServletConfig getServletConfig()
l public java.lang.String getServletInfo()
在某个servlet类被实例化之后,init方法由servlet容器调用。servlet容器只调用该方法一次,调用后则可以执行服务方法了。在servlet接收任何请求之前,必须是经过正确初始化的。
当一个客户端请求到达后,servlet容器就调用相应的servlet的service方法,并将Request和Response对象作为参数传入。在servlet实例的生命周期内,service方法会被多次调用。
在将servlet实例从服务中移除前,会调用servlet实例的destroy方法。一般情况下,在服务器关闭前,会发生上述情况,servlet容器会释放内存。只有当servlet实例的service方法中所有的线程都退出或执行超时后,才会调用destroy方法。当容器调用了destroy方法精辟,就不会再调用service方法了。
2.3 Application 1
下面从servlet容器的角度观察servlet的开发。在一个全功能servlet容器中,对servlet的每个HTTP请求来说,容器要做下面几件事:
l 当第一次调用servlet时,要载入servlet类,调用init方法(仅此一次);
l 针对每个request请求,创建一个Request对象和一个Resposne对象;
l 调用相应的servlet的service方法,将Request对象和Response对象作为参数传入;
l 当关闭servlet时,调用destroy方法,并卸载该servlet类。
这里建立的servlet容器是一个很小的容器,没有实现所有的功能。因此,它仅能运行非常简单的servlet类,无法调用servlet的init和destroy方法。它能执行功能如下所示:
l 等待HTTP请求;
l 创建Request和Response对象;
l 若请求的是一个静态资源,则调用StaticResourceProcessor对象的process方法,传入request和response对象;
l 若请求的是servlet,则载入相应的servlet类,调用service方法,传入request对象和response对象。
注意,在这个servlet中,每次请求servlet都会载入servlet类。
该程序包括6个类:HttpServer1、Request、Response、StaticResourceProcessor、ServletProcessor1、Constants。
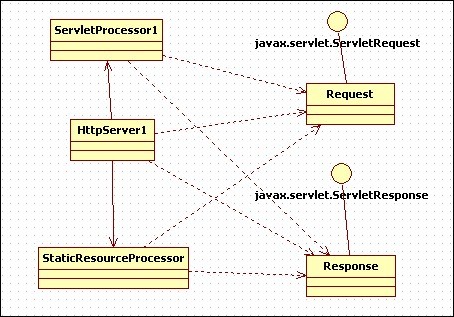
图表 2 简单servlet容器1的UML图
该程序的入口点(静态main方法)在类HttpServer1中。main方法中创建HttpServer1的实例,饭后调用其await方法。await方法等待HTTP请求,为接收到的每个请求创建request和response对象,将它们分发到一个StaticResourceProcessor类或ServletProcessor类的实例。
2.3.1 HttpServer1类
代码清单如下:
该类与第一章的HttpServer类类似,只是完善了对静态资源和动态资源的处理。
2.3.2 Request类
代码清单如下:
该类实现了javax.servlet.ServletRequest接口,但并不返回实际内容。
2.3.3 Response类
实现了javax.servlet.ServletResponse接口,大部分方法都返回一个空值,除了getWriter方法以外。
在getWriter方法中,PrintWriter类的构造函数的第二个参数表示是否启用autoFlush。因此,若是设置为false,则如果是servlet的service方法的最后一行调用打印方法,则该打印内容不会被发送到客户端。这个bug会在后续的版本中修改。
2.3.4 StaticResourceProcessor类
该类用于处理对静态资源的请求。

2.3.5 ServletProcessor1类
该类用于处理对servlet资源的请求。

该类很简单,只有一个process方法。载入servlet时使用的是UrlClassLoader类,它是ClassLoader类的直接子类,有三种构造方法。
l public URLClassLoader(URL[] urls);
参数为一个Url对象的数组,每个url指明了从哪里查找servlet类。若某个Url是以“/”结尾的,则认为它是一个目录;否则,认为它是一个jar文件,必要时会将它下载并解压。
注:在servlet容器中,查找servlet类的位置称为repository。
在我们的应用程序中,servlet容器只需要查找一个repository,在工作目录的webroot路径下。
l public URL(URL context, java.lang.String spec, URLStreamHandler hander) throws MalformedURLException
l public URL(java.lang.String protocol, java.lang.String host, java.lang.String file) throws MalformedURLException
2.4 Application 2
在之前的程序中,有一个严重的问题,必须将ex02.pyrmont.Request和ex02.pyrmont.Response分别转型为javax.servlet.ServletRequest和javax.servlet.ServletResponse,再作为参数传递给具体的servlet的service方法。这样并不安全,熟知servlet容器的人可以将ServletRequest和ServletResponse类向下转型为Request和Response类,并执行parse和sendStaticResource方法。
一种解决方案是将这两个方法的访问修饰符改为默认的(即,default),这样就可以避免包外访问。另一种更好的方案是使用外观设计模式。uml图如下:
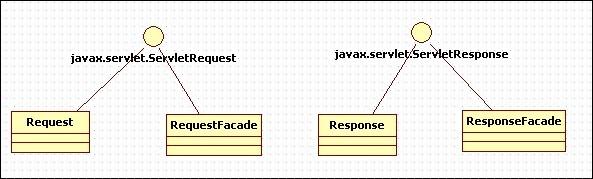
在第二个应用程序中,添加了两个façade类,RequestFacade和ResponseFacade。RequestFacade类实现了ServletRequest接口,通过在其构造方法中传入一个ServletRequest类型引用的Request对象来实例化。ServletRequest接口中每个方法的实现都会调用Request对象的相应方法。但是,ServletRequest对象本身是private类型,这样就不能从类的外部进行访问。这里也不再将Request对象向上转型为ServletRequest对象,而是创建一个RequestFacade对象,并把它传给service方法。这样,就算是将在servlet中获取了ServletRequest对象,并向下转型为RequestFacade对象,也不能再访问ServletRequest接口中的方法了,就可以避免前面所说的安全问题。
RequestFacade.java代码如下:

注意它的构造函数,接收一个Request对象,然后向上转型为ServletRequest对象,赋给其private成员变量request。该类的其他方法中,都是调用request的相应方法实现的,这样就将ServletRequest完整的封装得RequestFacade中了。
同理,ResponseFacade类也是这样的。
Application 2中的类包括,HttpServer2、Request、Response、StaticResourceProcessor、ServletProcessor2、Constants。
第3章 连接器(Connector)
3.1 概述
在简介一章里说明了,tomcat由两大模块组成:连接器(connector)和容器(container)。本章将使用连接器来增强application 2的功能。一个支持servlet2.3和2.4规范的连接器必须要负责创建javax.servlet.http.HttpServletRequest和javax.servlet.http.HttpServletResponse实例,并将它们作为参数传递给要调用的某个的servlet的service方法。在第2章中的servlet容器仅仅能运行实现了javax.servlet.Servlet接口,并想service方法中传入了javax.servlet.ServletRequest和javax.servlet.ServletResponse实例的servlet。由于连接器并不知道servlet的具体类型(例如,该servlet是否javax.servlet.Servlet接口,还是继承自javax.servlet.GenericServlet类,或继承自javax.servlet.http.HttpServlet类),因此连接器总是传入HttpServletRequest和HttpServletResponse的实例对象。
本章中所要建立的connector实际上是tomcat4中的默认连接器(将在第4章讨论)的简化版。本章中,connector和container将分离开。
在开始说明本章的程序之前,先花点时间介绍下org.apache.catalina.util.StringManager类,它被tomcat用来处理不同模块内错误信息的国际化。在本章中,也是这样用的。
3.2 StringManager类
tomcat将错误信息写在一个properties文件中,这样便于读取和编辑。但若是将所有类的错误信息都写在一个properties文件,优惠导致文件太大,不便于读写。为避免这种情况,tomcat将properties文件按照不同的包进行划分,每个包下都有自己的properties文件。例如,org.apache.catalina.connector包下的properties文件包含了该包下所有的类中可能抛出的错误信息。每个properties文件都由一个org.apache.catalina.util.StringManager实例来处理。在tomcat运行时,会建立很多StringManager类的实例,每个实例对应一个properties文件。
当包内的某个类要查找错误信息时,会先获取对应的StringManager实例。StringManager被设计为在包内是共享的一个单例,功过hashtable实现。如下面的代码所示:
java代码:
-
private static Hashtable managers = new Hashtable();
-
public synchronized static StringManager
-
getManager(String packageName) {
-
StringManager mgr = (StringManager)managers.get(packageName); if (mgr == null) {
-
mgr = new StringManager(packageName);
-
managers.put(packageName, mgr);
-
}
-
return mgr;
-
}
-
StringManager sm = StringManager.getManager("ex03.pyrmont.connector.http");
3.3 Application
从本章开始,每章的应用程序都会按照模块进行划分。本章的应用程序可分为3个模块:connector、startup、core。
startup模块仅包括一个StartUp类,负责启动应用程序。
connector模块的类可分为以下5个部分:
l 连接器及其支持类(HttpConnector和HttpProcessor);
l 表示http请求的类(HttpRequest)及其支持类;
l 表示http响应的类(HttpResponse)及其支持类;
l 外观装饰类(HttpRequestFacade和HttpResponseFacade);
l 常量类。
core模块包括ServletProcessor类和StaticResourceProcessor类。
下面是程序的uml图:
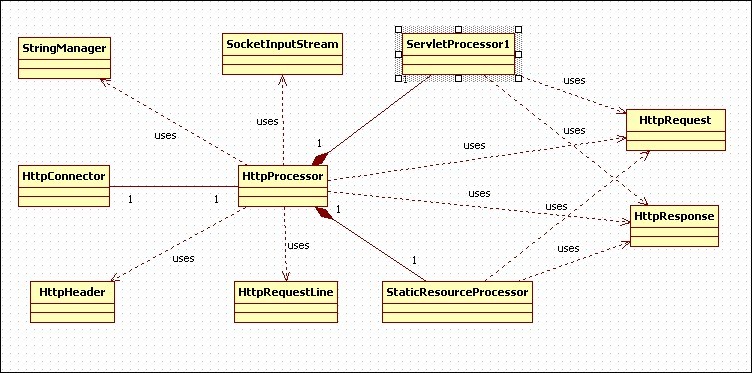
图表 4 application的uml图
相比于第2章中的程序,HttpServer在本章中被分成了HttpConnector和HttpProcessor两个类。Request和Response分别被HttpRequest和HttpResponse代替。此外,本章的应用程序中还使用了一些其他的类。
在第2章中,HttpServer负责等待http请求,并创建request和response对象。本章中,等待http请求的工作由HttpConnector完成,创建request和response对象的工作由HttpProcessor完成。
本章中,http请求用HttpRequest对象表示,该类实现了javax.servlet.http.HttpServletRequest接口。一个HttpRequest对象在传给servlet的service方法前,会被转型为HttpServletRequest对象。因此,需要正确设置每个HttpRequest对象的成员变量,方便servlet使用。需要设置的值包括,uri,请求字符串,参数,cookie和其他一些请求头信息等。由于连接器并不知道servlet中会使用那些变量,素以它会将从http请求中获取的变量都设置到HttpRequest对象中。但是,处理一个http请求会设计到一些比较耗时的操作,如字符串处理等。因此,若是connector仅仅传入servlet需要用到的值就会节省很多时间。tomcat的默认connector对这些值的处理是等到servlet真正用到的时候才处理的。
tomcat的默认connector和本程序的connector通过SocketInputStream类来读取字节流,可通过socket的getInputStream方法来获取该对象。它有两个重要的方法readRequestLine和readHeader。readRequestLine方法返回一个http请求的第一行,包括uri,请求方法和http协议版本。从socket的inputStream中处理字节流意味着要从头读到尾(即不能返回来再读前面的内容),因此,readRequestLine方法一定要在readHeader方法前调用。readRequestLine方法返回的是HttpRequestLine对象,readHeader方法返回的是HttpHeader对象(key-value形式)。获取HttpHeader对象时,应重复调用readHeader方法,直到再也无法获取到。
HttpProcessor对象负责创建HttpRequest对象,并填充它的成员变量。在其parse方法中,将请求行(request line)和请求头(request header)信息填充到HttpRequest对象中,但并不会填充请求体(request body)和查询字符串(query string)。
3.3.1 启动
在Bootstrap类的main方法内实例化一个HttpConnector类的对象,并调用其start方法就可以启动应用程序。
3.3.2 connector
HttpConnector类实现了java.lang.Runnable接口,这样它可以专注于自己的线程。启动应用程序时,会创建一个HttpConnector对象,其run方法会被调用。其run方法中是一个循环体,执行以下三件事:
l 等待http请求;
l 为每个请求创建一个HttpPorcessor对象;
l 调用HttpProcessor对象的process方法。
HttpProcessor类的process方法从http请求中获取socket。对每个http请求,它要做一下三件事:
l 创建一个HttpRequest对象和一个HttpResponse对象;
l 处理请求行(request line)和请求头(request headers),填充HttpRequest对象;
l 将HttpRequest对象和HttpResponse对象传给ServletProcessor或StaticResourceProcessor的process方法。

3.3.3 创建HttpRequest对象
HttpRequest类实现了javax.servlet.http.HttpServletRequest接口。其伴随的外观类是HttpRequestFacade。日uml图如下所示:
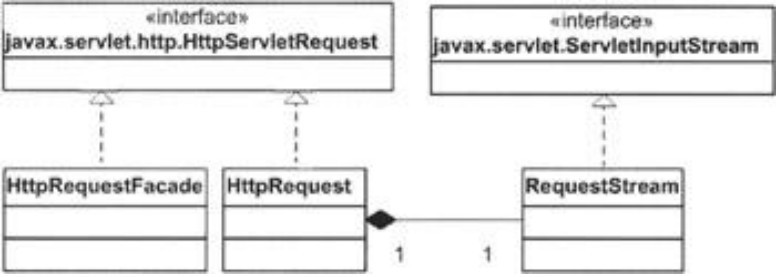
图表 5 HttpRequest类的uml图
其中HttpRequest的很多方法都是空方法,但已经可以从hhtp请求中获取headers,cookies和参数信息了。这三种数据分别以HashMap、ArrayList和ParameterMap(后面介绍)存储。
3.3.3.1 SocketInputStream类
本章的应用程序中,使用的SocketInputStream就是org.apache.catalina.connector.http.SocketInputStream。该类提供了获取请求行(request line)和请求头(request header)的方法。通过传入一个InputStream对象和一个代表缓冲区大小的整数值来创建SocketInputStream对象。
3.3.3.2 解析请求行(request line)
HttpProcessor的process调用其私有方法parseRequest来解析请求行(request line,即http请求的第一行)。下面是一个请求行(request line)的例子:
GET /myApp/ModernServlet?userName=tarzan&password=pwd HTTP/1.1
注意:“GET”后面和“HTTP”前面各有一个空格。
请求行的第2部分是uri加上查询字符串。在上面的例子中,uri是:
/myApp/ModernServlet
问号后面的都是查询字符串,这里是:
userName=tarzan&password=pwd
在servlet/jsp编程中,参数jsessionid通常是嵌入到cookie中的,也可以将其嵌入到查询字符串中。parseRequest方法的具体内容参见代码。

3.3.3.3 解析请求头(request header)
请求头(request header)由HttpHeader对象表示。可以通过HttpHeader的无参构造方法建立对象,并将其作为参数传给SocketInputStream的readHeader方法,该方法会自动填充HttpHeader对象。parseHeader方法内有一个循环体,不断的从SocketInputStream中读取header信息,直到读完。获取header的name和value值可使用下米娜的语句:
java代码:
-
String name = new String(header.name, 0, header.nameEnd);
-
String value = new String(header.value, 0, header.valueEnd);
-
获取到header的name和value后,要将其填充到HttpRequest的header属性(hashMap类型)中:
-
request.addHeader(name, value);
-
其中某些header要设置到request对象的属性中,如contentLength等。
3.3.3.4 解析cookie
ookie是由浏览器作为请求头的一部分发送的,这样的请求头的名字是cookie,它的值是一个key-value对。举例如下:
java代码:
-
Cookie: userName=budi; password=pwd;
对cookie的解析是通过org.apache.catalina.util.RequestUtil类的parseCookieHeader方法完成的。该方法接受一个cookie头字符串,返回一个javax.servlet.http.Cookie类型的数组。方法实现如下:
java代码:
-
public static Cookie[] parseCookieHeader(String header) {
-
if ((header == null) || (header.length 0 < 1) )
-
return (new Cookie[0]);
-
ArrayList cookies = new ArrayList();
-
while (header.length() > 0) {
-
int semicolon = header.indexOf(';');
-
if (semicolon < 0)
-
semicolon = header.length();
-
if (semicolon == 0)
-
break;
-
String token = header.substring(0, semicolon);
-
if (semicolon < header.length())
-
header = header.substring(semicolon + 1);
-
else
-
header = "";
-
try {
-
int equals = token.indexOf('=');
-
if (equals > 0) {
-
String name = token.substring(0, equals).trim();
-
String value = token.substring(equals+1).trim();
-
cookies.add(new Cookie(name, value));
-
}
-
} catch (Throwable e) { ; }
-
}
-
return ((Cookie[]) cookies.toArray (new Cookie [cookies.size ()]));
-
}
3.3.3.5 获取参数
在调用javax.servlet.http.HttpServletRequest的getParameter、getParameterMap、getParameterNames或getParameterValues方法之前,都不会涉及到对查询字符串或http请求体的解析。因此,这四个方法的实现都是先调用parseParameter方法。
参数只会被解析一次,因为,HttpRequest类会设置一个标志位表明是否已经完成参数解析了。参数可以出现在查询字符串或请求体中。若用户使用的GET方法,则所有的参数都会在查询字符串中;若是使用的POST方法,则请求体中也可能会有参数。所有的key-value的参数对都会存储在HashMap中,其中的值是不可修改的。tomcat中使用的是一个特殊的hashmap类,org.apache.catalina.util.ParameterMap。
ParameterMap类继承自java.util.HashMap,使用一个标志位来表示锁定。如果该标志位为false,则可以对其中的key-value进行添加、修改、删除操作,否则,执行这些操作时,会抛出IllegalStateException异常。代码如下:

3.3.3.6 创建HttpResponse对象
HttpResponse类继承自javax.servlet.http.HttpServletResponse,其相应的外观类是HttpResponseFacade。其uml图如下所示:
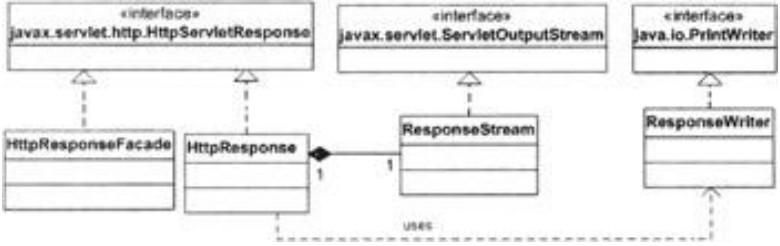
图表 6 HttpResponse及其外观类的uml图示
在第2章中,HttpResponse的功能有限,例如,它的getWriter方法返回的java.io.PrintWriter对象执行了print方法时,并不会自动flush。本章的程序将解决此问题。在此之前,先说明一下什么是Writer。
在servlet中,可以使用PrintWriter对象想输出流中写字符。可以使用任意编码格式,但在发送的时候,实际上都是字节流。
在本章中,将要使用的是ex03.pyrmont.connector.ResponseStream类作为PrintWriter的输出流。该类直接继承自java.io.OutputStream类。
类ex03.pyrmont.connector.ResponseWriter继承自PrintWriter,重写了其print和println方法,实现自动flush。因此,本章适用ResponseWriter作为输出对象。
示例代码如下:
java代码:
-
public PrintWriter getWriter() throws IOException {
-
ResponseStream newStream = new ResponseStream(this);
-
newStream.setCommit(false);
-
OutputStreamWriter osr =
-
new OutputStreamWriter(newStream, getCharacterEncoding());
-
writer = new ResponseWriter(osr);
-
return writer;
-
}
3.3.3.7 静态资源处理器和servlet处理器
本章的servlet处理器和第2章的servlet处理器类似,都只有一个process方法。但个,本章中,process方法接收的参数类型为HttpRequest和HttpResponse。方法签名如下:
public void process(HttpRequest request, HttpResponse response);
此外,process使用了request和response的外观类,并在调用了servlet的service方法后,再调用HttpResponse的finishResponse方法。示例代码如下:
java代码:
-
servlet = (Servlet) myClass.newInstance();
-
HttpRequestFacade requestPacade = new HttpRequestFacade(request);
-
HttpResponseFacade responseFacade = new
-
HttpResponseFacade(response);
-
servlet.service(requestFacade, responseFacade);
-
((HttpResponse) response).finishResponse();
4.1 简介
第三章的连接器只是一个学习版,是为了介绍tomcat的默认连接器而写。第四章会深入讨论下tomcat的默认连接器(这里指的是tomcat4的默认连接器,现在该连接器已经不推荐使用,而是被Coyote取代)。
tomcat的连接器是一个独立的模块,可被插入到servlet容器中。目前已经有很多连接器的实现,包括Coyote,mod_jk,mod_jk2,mod_webapp等。tomcat的连接器需要满足以下要求:
(1)实现org.apache.catalina.Connector接口;
(2)负责创建实现了org.apache.catalina.Request接口的request对象;
(3)负责创建实现了org.apache.catalina.Response接口的response对象。
tomcat4的连接器与第三章实现的连接器类似,等待http请求,创建request和response对象,调用org.apache.catalina.Container的invoke方法将request对象和response对象传入container。在invoke方法中,container负责载入servlet类,调用其call方法,管理session,记录日志等工作
tomcat的默认连接器中有一些优化操作没有在chap3的连接器中实现。首先是提供了一个对象池,避免频繁创建一些创佳代价高昂的对象。其次,默认连接器中很多地方使用了字符数组而非字符串。
本章的程序是实现一个使用默认连接器的container。但,本章的重点不在于container,而是connector。另一个需要注意的是,默认的connector实现了HTTP1.1,也可以服务HTTP1.0和HTTP0.9的客户端。
本章以HTTP1.1的3个新特性开始,这对于理解默认connector的工作机理很重要。然后,要介绍org.apache.catalina.Connector接口。
4.2 HTTP1.1的新特性
4.2.1 持久化连接
在http1.1之前,当服务器端将请求的资源返回后,就会断开与客户端的连接。但是,网页上会包含一些其他资源,如图片,applet等。因此,客户端请求资源后,浏览器还需要下载页面引用的 资源。如果页面和资源使用是通过不同的连接下载的,那么整个处理过程会很慢。因此,HTTP1.1引入了持久化连接。
使用持久化连接,当客户端下载页面后,服务器并不会立刻关闭连接,而是等待浏览器请求页面要引用的页面资源。这样,页面和资源使用同一个连接下载,这样就节省很多的工作和时间。
HTTP1.1中默认使用持久化连接,而客户端也可以主动使用。方法是在请求头中加入下面信息:
connection: keep-alive
4.2.2 编码
建立了持久化连接后,服务器可以使用该连接发送多个资源,而客户端也可以使用该连接发送多个请求。发送方在发送消息时就要附带上发送内容的长度,这样,接收方才能知道如何解释这些字节。但,通常的情况是,发送方并不知道要发送多少字节。例如,container可以在接收到一些字节后就向客户端返回一些信息,而不必等所有的字节都接收后再返回响应。因此,必须有某种方法告诉接收方如何解释字节流。
其实,即使没有发出多个请求,服务器或客户端也不需要知道有多少字节要发送。在HTTP1.0中,服务器可以不管content-length头信息,尽管往连接中写响应内容就行。这种情况下,客户端就一直读内容,直到读方法返回-1,此时表示已经没有更多信息了。
在HTTP1.1中,使用了一个特殊的头信息,transfer-encoding,表明字节流按照块发送。每个块的长度以16进制表示,后跟CRLF,然后是发送的内容。每次事务以一个0长度的块为结束标识。
例如,你想发送两个块,一个29字节,一个9字节。发送格式如下:
java代码:
-
1D\r\n
-
I'm as helpless as a kitten u
-
9\r\n
-
p a tree.
-
0\r\n
4.2.3 状态码100的使用
在HTTP1.1中,客户端在发送请求体之前,可能会先向服务器端发送这样的头信息:
Expect: 100-continue
然后等待服务器端的确认。
当客户端准备发送一个较长的请求体,而不确定服务端是否会接收时,就可能会发送上面的头信息。而服务器若是可以接受,则可以对此头信息进行响应,返回:
HTTP/1.1 100 Continue
注意,返回内容后面要加上CRLF。
4.3 Connector接口
tomcat的connector必须实现org.apache.catalina.Connector接口。该接口有很多方法,最重要的是getContainer,setContainer,createRequest和createResponse。
setContainer方法用于将connector和container联系起来,getContainer则可以返回响应的container,createRequest和createResponse则分别负责创建request和response对象。
org.apache.catalina.connector.http.HttpConnector类是Connector接口的一个实现,将在下一章讨论。响应的uml图如下所示:
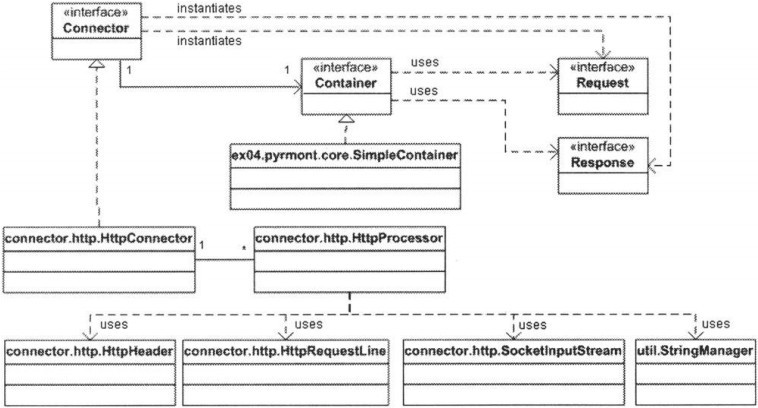
图表 7 默认连接器的uml示意图
注意,connector和container是一对一的关系,而connector和processor是一对多的关系。
4.4 HttpConnector类
在第三章中,已经实现了一个与org.apache.catalina.connector.http.HttpConnector类似的简化版connector。它实现了org.apache.catalina.Connector接口,java.lang.Runnable接口(确保在自己的线程中运行)和org.apache.catalina.Lifecycle接口。Lifecycle接口用于维护每个实现了该接口的tomcat的组件的生命周期。
Lifecycle具体内容将在第六章介绍。实现了Lifecycle接口后,当创建一个HttpConnector实例后,就应该调用其initialize方法和start方法。在组件的整个生命周期内,这两个方法只应该被调用一次。下面要介绍一些与第三章不同的功能:创建ServerSocket,维护HttpProcessor池,提供Http请求服务。
4.4.1 创建ServerSocket
HttpConnector的initialize方法会调用一个私有方法open,返回一个java.net.ServerSocket实例,赋值给成员变量serverSocket。这里并没有直接调用ServerSocket的构造方法,而是用过open方法调用ServerSocket的一个工厂方法来实现。具体的实现方式可参考ServerSocketFactory类和DefaultServerSocketFactory类(都在org.apache.catalina.net包内)。
4.4.2 维护HttpProcessor对象池
在第三章的程序中,每次使用HttpProcessor时,都会创建一个实例。而在tomcat的默认connector中,使用了一个HttpProcessor的对象池, 其中的每个对象都在其自己的线程中使用。因此,connector可同时处理多个http请求。
HttpConnector维护了一个HttpProcessor的对象池,避免了频繁的创建HttpProcessor对象。该对象池使用java.io.Stack实现。
在HttpConnector中,创建的HttpProcessor数目由两个变量决定:minProcessors和maxProcessors。
protected int minProcessors = 5;
private int maxProcessors = 20;
默认情况下,minProcessors=5,maxProcessors=20,可通过其setter方法修改。
初始化的时候,HttpConnector会创建minProcessors个HttpProcessor对象。若不够用就继续创建,直到到达maxProcessors个。此时,若还不够,则后达到的http请求将被忽略。若是不希望对maxProcessors进行限制,可以将其置为负数。此外,变量curProcessors表示当前已有的HttpProcessor实例数目。
下面是start方法中初始化HttpProcessor对象的代码:
java代码:
-
while (curProcessors < minProcessors) {
-
if ((maxProcessors > 0) && (curProcessors >= maxProcessors))
-
break;
-
HttpProcessor processor = newProcessor();
-
recycle(processor);
-
}
其中newProcessor方法负责创建HttpProcessor实例,并将curProcessors加1。recycle方法将新创建的HttpProcessor对象入栈。
每个HttpProcessor对象负责解析请求行和请求头,填充request对象。因此,每个HttpProcessor对象都关联一个request对象和response对象。HttpProcessor的构造函数会调用HttpConnector的createRequest方法和createResponse方法。
4.4.3 提供Http请求服务
HttpConnector类的主要业务逻辑在其run方法中(例如第三章的程序中那样)。run方法中维持一个循环体,该循环体内,服务器等待http请求,直到HttpConnector对象回收。
java代码:
-
while (!stopped) {
-
Socket socket = null;
-
try {
-
socket = serverSocket.accept();
-
...
对于每个http请求,通过调用其私有方法createProcessor获得一个HttpProcessor对象。这里,实际上是从HttpProcessor的对象池中拿一个对象。
注意,若是此时对象池中已经没有空闲的HttpProcessor实例可用,则createProcessor返回null。此时,服务器会直接关闭该连接,忽略该请求。如代码所示:
java代码:
-
if (processor == null) {
-
try {
-
log(sm.getString("httpConnector.noProcessor"));
-
socket.close();
-
}
-
...
-
continue;
若是createProcessor方法返回不为空,则调用该HttpProcessor实例的assign方法,并将客户端socket对象作为参数传入:
java代码:
-
processor.assign(socket);
这时,HttpProcessor实例开始读取socket的输入流,解析http请求。这里有一个重点,assign方法必须立刻返回,不能等待HttpProcessor实例完成解析再返回,这样才能处理后续的http请求。由于每个HttpProcessor都可以使用它自己的线程进行处理,所以这并不难实现。
4.5 HttpProcessor类
HttpProcessor类与第三章中的实现相类似。本章讨论下它的assign方法是如何实现异步功能的(即可同时处理多个http请求)。
在第三章中,HttpProcessor类运行在其自己的线程中。在处理下一个请求之前,它必须等待当前请求的处理完成。下面是第三章中的HttpConnector类的run方法的部分代码:
java代码:
-
public void run() {
-
...
-
while (!stopped) {
-
Socket socket = null;
-
try {
-
socket = serversocket.accept();
-
} catch (Exception e) {
-
continue;
-
}
-
// Hand this socket off to an Httpprocessor
-
HttpProcessor processor = new Httpprocessor(this);
-
processor.process(socket);
-
}
-
}
可以process方法是同步的。但是在tomcat的默认连接器中,HttpProcessor实现了java.lang.Runnable接口,每个HttpProcessor的实例都可以在其自己的线程中运行,成为“处理器线程”(“processor thread”)。HttpConnector创建每个HttpProcessor实例时,都会调用其start方法,启动其处理器线程。下面的代码显示了tomcat默认connector的HttpProcessor实例的run方法:
java代码:
-
public void run() {
-
// Process requests until we receive a shutdown signal
-
while (!stopped) {
-
// Wait for the next socket to be assigned
-
Socket socket = await();
-
if (socket == null)
-
continue;
-
// Process the request from this socket
-
try {
-
process(socket);
-
} catch (Throwable t) {
-
log("process.invoke", t);
-
}
-
// Finish up this request
-
connector.recycle(this);
-
}
-
// Tell threadStop() we have shut ourselves down successfully
-
synchronized (threadSync) {
-
threadSync.notifyAll();
-
}
-
}
这个循环体做的事是:获取socket,处理它,调用connector的recycle方法将当前的HttpProcessor入栈。recycle方法的实现是:
java代码:
-
void recycle(HttpProcessor processor) {
-
processors.push(processor);
-
}
注意,循环体在执行到await方法时会暂停当前处理器线程的控制流,直到获取到一个新的socket。换句话说,在HttpConnector调用HttpProcessor实例的assign方法前,程序会一直等下去。但是,assign方法并不是在当前线程中执行的,而是在HttpConnector的run方法中被调用的。这里称HttpConnector实例所在的线程为连接器线程(connector thread)。那么,assign方法是如何通知await方法它已经被调用了呢?方法是使用一个成为available的boolean变量和java.lang.Object的wait和notifyAll方法。
注意,wait方法会暂停本对象所在的当前线程,使其处于等待状态,直到另一线程调用了该对象的notify或notifyAll方法。
下面是HttpProcessor的assign方法和await方法的实现代码:
java代码:
-
synchronized void assign(Socket socket) {
-
// Wait for the processor to get the previous socket
-
while (available) {
-
try {
-
wait();
-
}
-
catch (InterruptedException e) {
-
}
-
}
-
// Store the newly available Socket and notify our thread
-
this.socket = socket;
-
available = true;
-
notifyAll();
-
...
-
}
-
private synchronized Socket await() {
-
// Wait for the Connector to provide a new Socket
-
while (!available) {
-
try {
-
wait();
-
}
-
catch (InterruptedException e) {
-
}
-
}
-
-
// Notify the Connector that we have received this Socket
-
Socket socket = this.socket;
-
available = false;
-
notifyAll();
-
if ((debug >= 1) && (socket != null))
-
log(" The incoming request has been awaited");
-
return (socket);
-
}
当处理器线程刚刚启动时,available值为false,线程在循环体内wait,直到任意一个线程调用了notify或notifyAll方法。也就是说,调用wait方法会使线程暂定,直到连接器线程调用HttpProcessor实例的notify或notifyAll方法。
当一个新socket被设置后,连接器线程调用HttpProcessor的assign方法。此时available变量的值为false,会跳过循环体,该socket对象被设置到HttpProcessor实例的socket变量中。然后连接器变量设置了available为true,调用notifyAll方法,唤醒处理器线程。此时available的值为true,跳出循环体,将socket对象赋值给局部变量,将available设置为false,调用notifyAll方法,并将给socket返回。
为什么await方法要使用一个局部变量保存socket对象的引用,而不返回实例的socket变量呢?是因为在当前socket被处理完之前,可能会有新的http请求过来,产生新的socket对象将其覆盖。
为什么await方法要调用notifyAll方法?考虑这种情况,当available变量的值还是true时,有一个新的socket达到。在这种情况下,连接器线程会在assign方法的循环体中暂停,直到处理器线程调用notifyAll方法。
4.6 request对象
默认连接器中的http request对象由org.apache.catalina.Request接口表示。该接口直接集成自RequestBase类,RequestBase是HttpRequest的父类。最终的实现类是HttpRequestImpl,继承自HttpRequest。与第三章的类关系类似,本章中也有外观类,RequestFacade和HttpRequestFacade。响应的uml示意图如下:
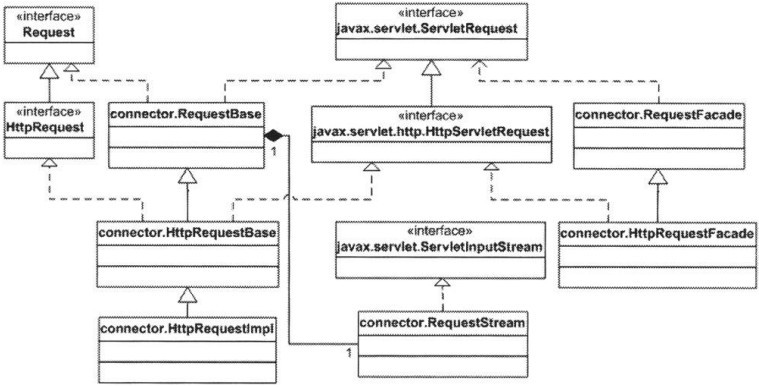
图表 8 Request接口及相关类的UML示意图
图表 8 Request接口及相关类的UML示意图
注意,图中报名包括javax.servlet和javax.servlet.http,其余类的报名均是org.apache.catalina,只是被省略掉了。
4.7 response对象
uml示意图如下:
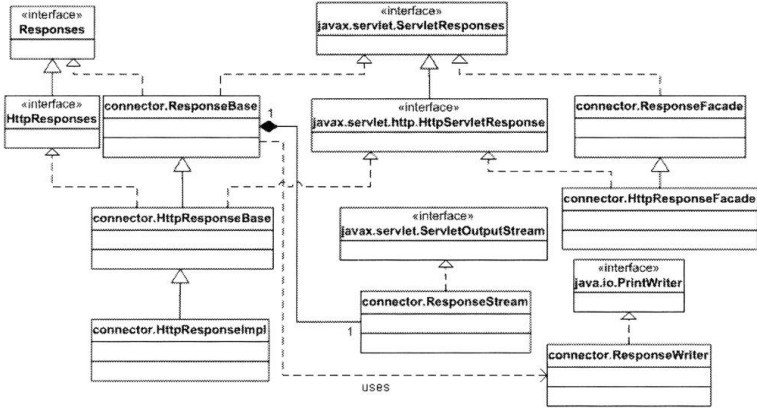
图表 9 Response接口及其相关类UML示意图
4.8 处理request对象
在这一点上,你已经知道了request对象和response对象,以及HttpConnector是如何创建它们的。本节中,将着重讨论HttpProcessor类的process方法。process方法做了三件事,解析连接,解析请求,解析请求头。
process使用一个boolean变量ok来表示在处理过程中是否有错误发生,以及一个boolean变量finishResponse来表示是否应该调用Response接口的finishResponse方法。
此外,process还是了实例的其他一些boolean变量,如keepAlive,stopped和http11。keepAlive表明该连接是否是持久化连接,stopped表明HttpProcessor实例是否被connector终止,这样的话processor也应该停止。http11表明客户端发来的请求是否支持HTTP/1.1
与第三章类似,SocketInputStream实例用于包装socket输入流。注意,SocketInputStream的构造函数也接受缓冲区的大小为参数,该参数来自connector,而不是HttpProcessor的一个局部变量。因为对默认connector的使用者来说,HttpProcessor是不可见的。如下面的代码所示:
java代码:
-
SocketInputStream input = null;
-
OutputStream output = null;
-
// Construct and initialize the objects we will need
-
try {
-
input = new SocketInputStream(socket.getInputstream(),
-
connector.getBufferSize());
-
}
-
catch (Exception e) {
-
ok = false;
-
}
然后是一个while循环,不断的读取输入流内容,直到HttpProcessor实例被终止,或处理过程报异常,或连接被断开。代码如下:
java代码:
-
keepAlive = true;
-
while (!stopped && ok && keepAlive) {
-
...
-
}
在循环体内,process方法现将finishResponse设置为true,获取输出流,执行一些request和response对象的初始化操作。
java代码:
-
finishResponse = true;
-
try {
-
request.setStream(input);
-
request.setResponse(response);
-
output = socket.getOutputStream();
-
response.setStream(output);
-
response.setRequest(request);
-
((HttpServletResponse) response.getResponse()).setHeader
-
("Server", SERVER_INFO);
-
}
-
catch (Exception e) {
-
log("process.create", e); //logging is discussed in Chapter 7
-
ok = false;
-
}
-
-
然后,process方法调用parseConnection,parseRequest和parseHeaders方法开始解析http请求。
-
try {
-
if (ok) {
-
parseConnection(socket);
-
parseRequest(input, output);
-
if (!request.getRequest().getProtocol()
-
.startsWith("HTTP/0"))
-
parseHeaders(input);
parseConnection方法获取请求所使用的协议,其值可以是HTTP 0.9, HTTP 1.0或HTTP 1.1。若值为HTTP 1.0,则将keepAlive置为false,因此HTTP 1.0不支持持久化连接。若是在http请求头中找到发现“Expect: 100-continue”,则parseHeaders设置sendAck为true。若请求协议为HTTP 1.1,会对调用ackRequest方法对“Expect: 100-continue”请求头响应。此外,还会检查是否允许分块。
java代码:
-
if (http11) {
-
// Sending a request acknowledge back to the client if
-
// requested.
-
ackRequest(output);
-
// If the protocol is HTTP/1.1, chunking is allowed.
-
if (connector.isChunkingAllowed())
-
response.setAllowChunking(true);
-
}
-
-
ackRequest方法检查sendAck的值,若其值为true,则发送下面格式的字符串:
-
HTTP/1.1 100 Continue\r\n
-
-
在解析http请求的过程中,有可能会抛出很多种异常。发生任何一个异常都会将变量ok或finishResponse设置为false。完成解析后,process方法将request和response对象作为参数传入container的invoke方法。
-
try {
-
((HttpServletResponse) response).setHeader
-
("Date", FastHttpDateFormat.getCurrentDate());
-
if (ok) {
-
connector.getContainer().invoke(request, response);
-
}
-
}
-
-
然后,若变量finishResponse的值为true,则调用response对象的finishResponse方法和request对象的finishRequest,再将输出flush掉。
-
if (finishResponse) {
-
...
-
response.finishResponse();
-
...
-
request.finishRequest();
-
...
-
output.flush();
-
-
while循环的最后一部分是检查response的头信息“Connection”是否被设为了“close”,或者协议是否是HTTP1.0。若这两种情况为真,则将keepAlive置为false。最后将request和response对象回收。
-
if ( "close".equals(response.getHeader("Connection")) ) {
-
keepAlive = false;
-
}
-
// End of request processing
-
status = Constants.PROCESSOR_IDLE;
-
// Recycling the request and the response objects
-
request.recycle();
-
response.recycle();
-
}
-
-
若keepAlive为true,或在解析和container的invoke中没有发生错误,或HttpProcessor对象没有被回收,则while循环则继续运行。否则调用shutdownInput方法,并关闭socket。
-
try {
-
shutdownInput(input);
-
socket.close();
-
}
-
...
-
注意,shutdownInput会检查是否有为读完的字节,若有,则跳过这些字节。
4.8.1 解析连接
parseConnection从socket接收internet地址,将其赋值给HttpRequestImpl对象。此外,还要检查是否使用了代理,将socket对象赋值给request对象。代码如下:
java代码:
-
private void parseConnection(Socket socket) throws IOException, ServletException {
-
if (debug >= 2)
-
log(" parseConnection: address=" + socket.getInetAddress() + ", port=" + connector.getPort());
-
((HttpRequestImpl) request).setInet(socket.getInetAddress());
-
if (proxyPort != 0)
-
request.setServerPort(proxyPort);
-
else
-
request.setServerPort(serverPort);
-
request.setSocket(socket);
-
}
4.8.2 解析request
与第三章的程序类似。
4.8.3 解析请求头
默认connector的parseHeaders方法是用了org.apache.catalina.connector.http包内的HttpHeader类和DefaultHeader类。HttpHeader类表示一个http请求中的请求头。这里与第三章不同的是,这里并没有使用字符串,而是使用了字符数组来避免代价高昂的字符串操作。DefaultHeaders类是一个final类,包含了字符数组形式的标准http请求头:
java代码:
-
static final char[] AUTHORIZATION_NAME = "authorization".toCharArray();
-
static final char[] ACCEPT_LANGUAGE_NAME = "accept-language".toCharArray();
-
static final char[] COOKIE_NAME = "cookie".toCharArray();
-
...
-
-
parseHeaders方法使用while循环读取所有的请求头信息。while循环以调用request对象的allocateHeader方法获取一个内容为空的HttpHeader实例开始。然后,该HttpHeader实例被传入SocketInputStream的readHeader方法中。
-
HttpHeader header = request.allocateHeader();
-
// Read the next header
-
input.readHeader(header);
-
-
若所有的请求头都已经读取过了,则readHeader方法不会再给HttpHeader对象设置name属性了。这时就可退出parseHeaders方法了。
-
if (header.nameEnd == 0) {
-
if (header.valueEnd == 0) {
-
return;
-
}
-
else {
-
throw new ServletException
-
(sm.getString("httpProcessor.parseHeaders.colon"));
-
}
-
}
-
-
若是一个HttpHeader有name,那么肯定也会有value。
-
String value = new String(header.value, 0, header.valueEnd);
-
-
接下来,与第三章类似,parseHeaders方法将读取到的请求头的name与DefaultHeaders中header的name比较。注意,这里的比较是字符数组的比较,而不是字符串的比较。
-
if (header.equals(DefaultHeaders.AUTHORIZATION_NAME)) {
-
request.setAuthorization(value);
-
}
-
else if (header.equals(DefaultHeaders.ACCEPT_LANGUAGE_NAME)) {
-
parseAcceptLanguage(value);
-
}
-
else if (header.equals(DefaultHeaders.COOKIE_NAME)) {
-
// parse cookie
-
}
-
else if (header.equals(DefaultHeaders.CONTENT_LENGTH_NAME)) {
-
// get content length
-
}
-
else if (header.equals(DefaultHeaders.CONTENT_TYPE_NAME)) {
-
request.setContentType(value);
-
}
-
else if (header.equals(DefaultHeaders.HOST_NAME)) {
-
// get host name
-
}
-
else if (header.equals(DefaultHeaders.CONNECTION_NAME)) {
-
if (header.valueEquals(DefaultHeaders.CONNECTION_CLOSE_VALUE)) {
-
keepAlive = false;
-
response.setHeader("Connection", "close");
-
}
-
} else if (header.equals(DefaultHeaders.EXPECT_NAME)) {
-
if (header.valueEquals(DefaultHeaders.EXPECT_100_VALUE))
-
sendAck = true;
-
else
-
throw new ServletException(sm.getstring
-
("httpProcessor.parseHeaders.unknownExpectation"));
-
}
-
else if (header.equals(DefaultHeaders.TRANSFER_ENCODING_NAME)) {
-
//request.setTransferEncoding(header);
-
}
-
-
request.nextHeader();
4.9 简单的container程序
这里重在展示如何使用默认的connector。程序包括两个类:ex04.pyrmont.core.SimpleContainer类和ex04 pyrmont.startup.Bootstrap类。SimpleContainer类继承自org.apache.catalina.Container,这样就可以金额默认的connector进行关联。Bootstrap用于启动程序。
这里仅仅给出了invoke方法的实现。invoke方法会创建一个class loader,载入servlet类,调用servlet的service方法。与第三章中的ServletProcessor类的process方法类似。

Boorstrap类的main方法创建org.apache.catalina.connector.http.HttpConnector类和SimpleContainer类的实例,然后调用connector的setContainer方法将connector和container关联。接下来调用connector的initialize和start方法。
(责任编辑:IT) |