|
一个操作系统最重要的就是进程管理和文件系统了,而文件系统与驱动程序联系的更加紧密,所以想先把linux文件系统搞清楚。这博客是我读了很多文章做的读书笔记和自己的一些体会而成的,方便以后查找。参考书籍在参考文献中。 首先分析一下linux实现文件系统所用到的数据结构,这些是实现Linux文件系统的核心。接着说明一下这些数据结构是如何组织起来实现文件系统的。最后介绍一下linux进程是如何使用这些数据结构的。 1, 核心数据结构 1.1 linux虚拟文件系统核心数据结构分析 主要有以下几个数据结构: * 超级块结构(struct super_block {...} ) 该结构保存了一个被安装在linux系统上的文件系统的信息。对于基于磁盘的文件系统,该结构一般和保存在磁盘上的"文件系统控制块"对应。也就是说如果是磁盘文件系统,该结构保存的磁盘文件系统的控制信息。 * inode结构( struct inode {...} ) 该结构中存储的是一个特定文件的一般信息,对于一个基于磁盘的文件系统,该结构对应磁盘上的"文件数据控制块"。每一个inode结构都对应一个inode节点号,这个节点号是唯一的,它也唯一标识一个文件系统中的文件。 * file结构( struct file {...} ) 该结构中存储的是一个打开的文件和打开这个文件的进程间的交互信息。该结构保存在kernel的内存区,在打开文件时被创建,关闭文件时被释放。 * dentry结构( struct dentry {...} ) 该结构存储的是目录实体和对应的文件的关联信息。 1.2 数据结构详细分析 1.2.1 inode 结构分析 inode结构包括一个文件的所有的信息。文件系统要对文件进行操作,主要依靠inode数据结构提供的信息。文件名字只是文件的一个标签,可以任意的改变,但是inode却保持到文件被删除。 这里指列出需要分析的一些重要的项: struct inode { unsigned long i_ino; //i节点号,一个文件对应一个唯一的i节点号 unsigned int i_nlink; //文件的硬链接数 struct timespec i_atime; //文件最后一次被访问的时间 struct timespec i_mtime; //文件内容最后一次被修改的时间 struct timespec i_ctime; //文件inode被修改的时间 unsigned long i_blocks; //文件的所占的块数 struct inode_operations *i_op; //inode的操作接口 struct file_operations *i_fop; //默认的文件操作former->i_op->default_file_ops struct super_block *i_sb; //指向超级块结构 struct file_lock *i_flock; //文件锁指针 struct address_space *i_mapping; // struct address_space i_data; struct pipe_inode_info *i_pipe; //如果文件是一个管道 struct block_device *i_bdev; //指向块设备驱动程序 struct cdev *i_cdev; //指向字符设备驱动程序 unsigned long i_state; //inode的状态标识符 }; 1.2.2 file 结构分析 file结构主要保存进程打开一个文件时的交互信息,该结构的内容不是保存在磁盘上,而是保存在内存中的。当进程打开一个文件时,该结构被创建。进程打开文件时创建的数据结构如此: task_struct-->files_struct-->file 下面看一下file结构的具体内容: struct file { struct list_head f_list; struct dentry *f_dentry; //与文件结构对应的dentry struct vfsmount *f_vfsmnt; //装载的文件系统中包含了该文件 struct file_operations *f_op; //文件操作表 atomic_t f_count; //文件对象被引用的数 unsigned int f_flags; // mode_t f_mode; //进程访问方式 int f_error; loff_t f_pos; //目前文件偏移量(文件指针的位置) struct fown_struct f_owner; unsigned int f_uid, f_gid; //用户的UID和GID struct file_ra_state f_ra; size_t f_maxcount; unsigned long f_version; void *f_security; void *private_data; struct address_space *f_mapping; //指向文件的地址空间结构 }; 该结构中一个重要的项就是f_pos,因为几个进程可能同时打开一个文件,而每个进程对文件的操作不一样,偏移量也对每个进程不一样,所以f_pos应该在struct file中,而不应该在inode结构中。这就是apue在讲文件打开接口时提到的。 1.3 使用以上数据结构 2. 进程和文件系统的交互 2.1 进程打开和关闭文件操作 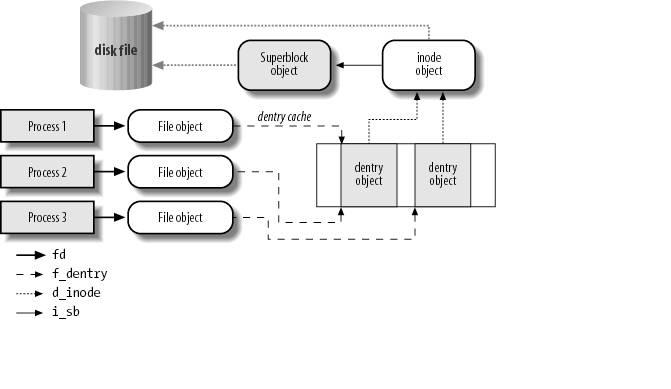 图 2.1 在进程task_struct结构中有两个与文件相关的数据结构: struct task_struc { ... struct fs_struct *fs; //文件系统信息 struct file_struct *file; //打开文件的信息 ... } 当进程打开一个文件时,首先创建一个file结构,如图2.1所示。三个进程打开了同一个文件,其中的进程1和进程2使用了该文件的同一个硬连接(相同的路径)。这样,每一个进程都创建file结构,但是1和2号进程都指向了相同的dentry结构(因为硬链接相同),但每个dentry都指向同一个inode结构,通过inode 结构可以得到超级块以及磁盘文件的信息。 3, 文件系统注册 文件系统注册过程比较简单,就是把file_system_type定义的变量注册到file_systems这个全局静态变量为头的链表中。 注册过程前面有分析,这里主要要注意file_system_type结构中的get_sb和kill_sb的函数。 struct file_system_type { //文件系统类型 const char *name; //文件系统名 int fs_flags; int (*get_sb) (struct file_system_type *, int, const char *, void *, struct vfsmount *); //读取超级块的方法 void (*kill_sb) (struct super_block *); struct module *owner; struct file_system_type * next; //文件系统链表的下一个节点 struct list_head fs_supers; //具有相同文件系统类型的超级块对象链表头 ... } 3.1 ext2文件系统类型 static struct file_system_type ext2_fs_type = { .owner = THIS_MODULE, .name = "ext2", //文件系统类型名 .get_sb = ext2_get_sb, //获取超级块函数 .kill_sb = kill_block_super, //卸载超级块函数 .fs_flags = FS_REQUIRES_DEV, //文件系统类型标记 }; 3.2 超级块的获取 .超级块和文件系统其他数据结构结构的关系 task_struct->file->dentry->inode->super_block->(磁盘文件数据) .挂载文件系统结构和其他数据结构的关系 .ext2文件系统类型获取超级块 static int ext2_get_sb(struct file_system_type *fs_type, int flags, const char *dev_name, void *data, struct vfsmount *mnt) { return get_sb_bdev(fs_type, flags, dev_name, data, ext2_fill_super, mnt); } .获取block设备超级块 int get_sb_bdev(struct file_system_type *fs_type, int flags, const char *dev_name, void *data, int (*fill_super)(struct super_block *, void *, int), struct vfsmount *mnt) { struct block_device *bdev; struct super_block *s; int error = 0; bdev = open_bdev_excl(dev_name, flags, fs_type); //打开设备为dev_name的设备 if (IS_ERR(bdev)) return PTR_ERR(bdev); /* * once the super is inserted into the list by sget, s_umount * will protect the lockfs code from trying to start a snapshot * while we are mounting */ down(&bdev->bd_mount_sem); //搜索文件系统的超级块对象链表 s = sget(fs_type, test_bdev_super, set_bdev_super, bdev); up(&bdev->bd_mount_sem); if (IS_ERR(s)) goto error_s; if (s->s_root) { if ((flags ^ s->s_flags) & MS_RDONLY) { //超级块只读 up_write(&s->s_umount); deactivate_super(s); error = -EBUSY; goto error_bdev; } close_bdev_excl(bdev); } else { char b[BDEVNAME_SIZE]; s->s_flags = flags; strlcpy(s->s_id, bdevname(bdev, b), sizeof(s->s_id)); sb_set_blocksize(s, block_size(bdev)); error = fill_super(s, data, flags & MS_SILENT ? 1 : 0); if (error) { up_write(&s->s_umount); deactivate_super(s); goto error; } s->s_flags |= MS_ACTIVE; } return simple_set_mnt(mnt, s); error_s: error = PTR_ERR(s); error_bdev: close_bdev_excl(bdev); error: return error; } //把sb和mnt_root进行赋值 int simple_set_mnt(struct vfsmount *mnt, struct super_block *sb) { mnt->mnt_sb = sb; mnt->mnt_root = dget(sb->s_root); return 0; } /** * sget - find or create a superblock * @type: filesystem type superblock should belong to * @test: comparison callback * @set: setup callback * @data: argument to each of them */ struct super_block *sget(struct file_system_type *type, int (*test)(struct super_block *,void *), int (*set)(struct super_block *,void *), void *data) { struct super_block *s = NULL; struct super_block *old; int err; retry: spin_lock(&sb_lock); if (test) { //在该文件系统的超级快链表中检查 list_for_each_entry(old, &type->fs_supers, s_instances) { if (!test(old, data)) //块设备是否相同,不相同继续 continue; if (!grab_super(old)) goto retry; if (s) //若s已经有值,释放之 destroy_super(s); return old; } } if (!s) { //若s为NULL,分配一个 spin_unlock(&sb_lock); s = alloc_super(type); //分配一个文件系统为type的超级块 if (!s) return ERR_PTR(-ENOMEM); goto retry; } err = set(s, data); //设置data(挂载点数据)的值 if (err) { spin_unlock(&sb_lock); destroy_super(s); return ERR_PTR(err); } s->s_type = type; strlcpy(s->s_id, type->name, sizeof(s->s_id)); list_add_tail(&s->s_list, &super_blocks); //插入到超级块全局链表 list_add(&s->s_instances, &type->fs_supers); //插入该文件系统类型超级块链表 spin_unlock(&sb_lock); get_filesystem(type); return s; //返回超级块对象 } 4, 安装文件系统 vfsmount->(super_block *mnt_sb) ->(dentry *mnt_root) ->(dentry *mnt_parent) ->(dentry *mnt_mountpoint) 4.1 基本结构 struct vfsmount { struct list_head mnt_hash; struct vfsmount *mnt_parent; /* fs we are mounted on */ struct dentry *mnt_mountpoint; /* dentry of mountpoint */ struct dentry *mnt_root; /* root of the mounted tree */ struct super_block *mnt_sb; /* pointer to superblock */ struct list_head mnt_mounts; /* list of children, anchored here */ struct list_head mnt_child; /* and going through their mnt_child */ int mnt_flags; /* 4 bytes hole on 64bits arches */ const char *mnt_devname; /* Name of device e.g. /dev/dsk/hda1 */ struct list_head mnt_list; struct list_head mnt_expire; /* link in fs-specific expiry list */ struct list_head mnt_share; /* circular list of shared mounts */ struct list_head mnt_slave_list;/* list of slave mounts */ struct list_head mnt_slave; /* slave list entry */ struct vfsmount *mnt_master; /* slave is on master->mnt_slave_list */ struct mnt_namespace *mnt_ns; /* containing namespace */ int mnt_id; /* mount identifier */ int mnt_group_id; /* peer group identifier */ /* * We put mnt_count & mnt_expiry_mark at the end of struct vfsmount * to let these frequently modified fields in a separate cache line * (so that reads of mnt_flags wont ping-pong on SMP machines) */ atomic_t mnt_count; int mnt_expiry_mark; /* true if marked for expiry */ int mnt_pinned; int mnt_ghosts; /* * This value is not stable unless all of the mnt_writers[] spinlocks * are held, and all mnt_writer[]s on this mount have 0 as their ->count */ atomic_t __mnt_writers; }; 4.2 挂载一个文件系统调用的函数是mount,该函数的实现流程如下: sys_mount() ->do_mount() ->do_remount() ->do_move_mount() ->do_loopback() ->do_new_mount() //这是普遍情况 ->do_kern_mount() struct vfsmount * do_kern_mount(const char *fstype, int flags, const char *name, void *data) { struct file_system_type *type = get_fs_type(fstype); //获取文件系统类型 struct vfsmount *mnt; if (!type) return ERR_PTR(-ENODEV); mnt = vfs_kern_mount(type, flags, name, data); if (!IS_ERR(mnt) && (type->fs_flags & FS_HAS_SUBTYPE) && !mnt->mnt_sb->s_subtype) mnt = fs_set_subtype(mnt, fstype); //设置文件系统类型 put_filesystem(type); return mnt; } struct vfsmount * vfs_kern_mount(struct file_system_type *type, int flags, const char *name, void *data) { struct vfsmount *mnt; char *secdata = NULL; int error; if (!type) return ERR_PTR(-ENODEV); error = -ENOMEM; mnt = alloc_vfsmnt(name); //分配新的文件系统安装描述符 if (!mnt) goto out; if (data && !(type->fs_flags & FS_BINARY_MOUNTDATA)) { secdata = alloc_secdata(); if (!secdata) goto out_mnt; error = security_sb_copy_data(data, secdata); if (error) goto out_free_secdata; } error = type->get_sb(type, flags, name, data, mnt); //分配并初始化新的超级块 if (error < 0) //并用新的超级块对象初始化mnt_sb goto out_free_secdata; BUG_ON(!mnt->mnt_sb); error = security_sb_kern_mount(mnt->mnt_sb, secdata); if (error) goto out_sb; mnt->mnt_mountpoint = mnt->mnt_root; //文件系统根目录对应的对象地址 mnt->mnt_parent = mnt; //用mnt初始化mnt_parent字段 up_write(&mnt->mnt_sb->s_umount); //增加该目录对象的引用计数 free_secdata(secdata); return mnt; //返回安装文件对象mnt out_sb: dput(mnt->mnt_root); up_write(&mnt->mnt_sb->s_umount); deactivate_super(mnt->mnt_sb); out_free_secdata: free_secdata(secdata); out_mnt: free_vfsmnt(mnt); out: return ERR_PTR(error); } 5, 文件系统常用函数分析 5.1 路径名查找 //通过 int path_lookup(const char *name, unsigned int flags, struct nameidata *nd) { return do_path_lookup(AT_FDCWD, name, flags, nd); } /* Returns 0 and nd will be valid on success; Retuns error, otherwise. */ static int do_path_lookup(int dfd, const char *name, unsigned int flags, struct nameidata *nd) { int retval = 0; int fput_needed; struct file *file; struct fs_struct *fs = current->fs; //获取当前进程的fs指针 nd->last_type = LAST_ROOT; /* if there are only slashes... */ nd->flags = flags; //给nd结构赋初值 nd->depth = 0; if (*name=='/') { //从/根路径开始查找 read_lock(&fs->lock); nd->path = fs->root; //获取根路径 path_get(&fs->root); //获取根路径引用计数 read_unlock(&fs->lock); } else if (dfd == AT_FDCWD) { //从当前目录开始查找 read_lock(&fs->lock); nd->path = fs->pwd; //获取当前路径 path_get(&fs->pwd); //获取当前路径的引用计数 read_unlock(&fs->lock); } else { //其他路径开始查找 struct dentry *dentry; file = fget_light(dfd, &fput_needed); //轻度文件查找,获取dfd对应的file结构 retval = -EBADF; if (!file) //没取到file指针 goto out_fail; dentry = file->f_path.dentry; //获取dentry结构指针 retval = -ENOTDIR; if (!S_ISDIR(dentry->d_inode->i_mode)) //非目录 goto fput_fail; retval = file_permission(file, MAY_EXEC); //检查是否有可执行权限 if (retval) goto fput_fail; nd->path = file->f_path; //把file结构的path指针复制 path_get(&file->f_path); fput_light(file, fput_needed); } retval = path_walk(name, nd); if (unlikely(!retval && !audit_dummy_context() && nd->path.dentry && nd->path.dentry->d_inode)) audit_inode(name, nd->path.dentry); out_fail: return retval; fput_fail: fput_light(file, fput_needed); goto out_fail; } //最终调用 static int path_walk(const char *name, struct nameidata *nd) { current->total_link_count = 0; return link_path_walk(name, nd); } /* * Wrapper to retry pathname resolution whenever the underlying * file system returns an ESTALE. * * Retry the whole path once, forcing real lookup requests * instead of relying on the dcache. */ static __always_inline int link_path_walk(const char *name, struct nameidata *nd) { struct path save = nd->path; //获取路径结构值 int result; /* make sure the stuff we saved doesn't go away */ path_get(&save); result = __link_path_walk(name, nd); if (result == -ESTALE) { /* nd->path had been dropped */ nd->path = save; path_get(&nd->path); nd->flags |= LOOKUP_REVAL; result = __link_path_walk(name, nd); } path_put(&save); return result; } /* * Name resolution. * This is the basic name resolution function, turning a pathname into * the final dentry. We expect 'base' to be positive and a directory. * * Returns 0 and nd will have valid dentry and mnt on success. * Returns error and drops reference to input namei data on failure. */ static int __link_path_walk(const char *name, struct nameidata *nd) { struct path next; struct inode *inode; int err; unsigned int lookup_flags = nd->flags; //把flags值给局部变量 while (*name=='/') //逃过路径名前面的/ name++; if (!*name) //若路径只有/,没有其他字符,退出 goto return_reval; inode = nd->path.dentry->d_inode; //取得inode指针 if (nd->depth) //若nd的深度大于0,设置FOLLOW标记 lookup_flags = LOOKUP_FOLLOW | (nd->flags & LOOKUP_CONTINUE); /* At this point we know we have a real path component. */ for(;;) { unsigned long hash; struct qstr this; unsigned int c; nd->flags |= LOOKUP_CONTINUE; err = exec_permission_lite(inode); //inode权限检查 if (err == -EAGAIN) //错误码是AGAIN err = vfs_permission(nd, MAY_EXEC); //再次检查 if (err) //权限有错,跳出 break; this.name = name; //保存路径每个分段(/为分段符)的开始字符指针 c = *(const unsigned char *)name; //获取每个分段的起始字符 hash = init_name_hash(); //初始化hash值 do { //把/当成分隔符,一段一段的处理路径名 name++; //name指针向前移 hash = partial_name_hash(c, hash); //计算hash值,为前面的值+现在字符的计算值 c = *(const unsigned char *)name; //取下一个字符 } while (c && (c != '/')); //指针向前查找,直到找到一个'/'或字符串末尾 this.len = name - (const char *) this.name; //计算这一分段长度 this.hash = end_name_hash(hash); //获取这一分段的hash值 /* remove trailing slashes? */ if (!c) //此时c是分段的后一个字符,其值可能是/或NULL;若是NULL,路径名结束 goto last_component; //跳到路径的最后处理 while (*++name == '/'); //跳过中间的/字符 if (!*name) //name为NULL,说明name以/结尾 goto last_with_slashes; /* * "." and ".." are special - ".." especially so because it has * to be able to know about the current root directory and * parent relationships. */ if (this.name[0] == '.') switch (this.len) { //本端的name字符是.,一定在/后 default: break; case 2: //开始字符是.而且长度为2,可能是'..' if (this.name[1] != '.') break; follow_dotdot(nd); //是'..',要处理父目录 inode = nd->path.dentry->d_inode; //获取inode /* fallthrough */ case 1: continue; } /* * See if the low-level filesystem might want * to use its own hash.. */ if (nd->path.dentry->d_op && nd->path.dentry->d_op->d_hash) { err = nd->path.dentry->d_op->d_hash(nd->path.dentry, &this); //计算this字符串的hash if (err < 0) break; } /* This does the actual lookups.. */ err = do_lookup(nd, &this, &next); if (err) break; err = -ENOENT; inode = next.dentry->d_inode; if (!inode) goto out_dput; err = -ENOTDIR; if (!inode->i_op) goto out_dput; if (inode->i_op->follow_link) { err = do_follow_link(&next, nd); if (err) goto return_err; err = -ENOENT; inode = nd->path.dentry->d_inode; if (!inode) break; err = -ENOTDIR; if (!inode->i_op) break; } else path_to_nameidata(&next, nd); err = -ENOTDIR; if (!inode->i_op->lookup) break; continue; /* here ends the main loop */ last_with_slashes: lookup_flags |= LOOKUP_FOLLOW | LOOKUP_DIRECTORY; last_component: /* Clear LOOKUP_CONTINUE iff it was previously unset */ nd->flags &= lookup_flags | ~LOOKUP_CONTINUE; if (lookup_flags & LOOKUP_PARENT) goto lookup_parent; if (this.name[0] == '.') switch (this.len) { default: break; case 2: if (this.name[1] != '.') break; follow_dotdot(nd); inode = nd->path.dentry->d_inode; /* fallthrough */ case 1: goto return_reval; } if (nd->path.dentry->d_op && nd->path.dentry->d_op->d_hash) { err = nd->path.dentry->d_op->d_hash(nd->path.dentry, &this); if (err < 0) break; } err = do_lookup(nd, &this, &next); if (err) break; inode = next.dentry->d_inode; if ((lookup_flags & LOOKUP_FOLLOW) && inode && inode->i_op && inode->i_op->follow_link) { err = do_follow_link(&next, nd); if (err) goto return_err; inode = nd->path.dentry->d_inode; } else path_to_nameidata(&next, nd); err = -ENOENT; if (!inode) break; if (lookup_flags & LOOKUP_DIRECTORY) { err = -ENOTDIR; if (!inode->i_op || !inode->i_op->lookup) break; } goto return_base; lookup_parent: nd->last = this; nd->last_type = LAST_NORM; if (this.name[0] != '.') goto return_base; if (this.len == 1) nd->last_type = LAST_DOT; else if (this.len == 2 && this.name[1] == '.') nd->last_type = LAST_DOTDOT; else goto return_base; return_reval: /* * We bypassed the ordinary revalidation routines. * We may need to check the cached dentry for staleness. */ if (nd->path.dentry && nd->path.dentry->d_sb && (nd->path.dentry->d_sb->s_type->fs_flags & FS_REVAL_DOT)) { err = -ESTALE; /* Note: we do not d_invalidate() */ if (!nd->path.dentry->d_op->d_revalidate( nd->path.dentry, nd)) break; } return_base: return 0; out_dput: path_put_conditional(&next, nd); break; } path_put(&nd->path); return_err: return err; } /* * It's more convoluted than I'd like it to be, but... it's still fairly * small and for now I'd prefer to have fast path as straight as possible. * It _is_ time-critical. */ static int do_lookup(struct nameidata *nd, struct qstr *name, struct path *path) { struct vfsmount *mnt = nd->path.mnt; //获取文件系统安装对象 struct dentry *dentry = __d_lookup(nd->path.dentry, name); if (!dentry) //没有在目录缓存中找到,继续在真实环境中查找 goto need_lookup; if (dentry->d_op && dentry->d_op->d_revalidate) goto need_revalidate; done: path->mnt = mnt; //找到的mnt赋给path path->dentry = dentry; //把找到的dentry赋给path __follow_mount(path); //跟踪该目录下新安装的文件系统 return 0; need_lookup: dentry = real_lookup(nd->path.dentry, name, nd); //真实的路径查找 if (IS_ERR(dentry)) goto fail; goto done; need_revalidate: dentry = do_revalidate(dentry, nd); if (!dentry) goto need_lookup; if (IS_ERR(dentry)) goto fail; goto done; fail: return PTR_ERR(dentry); } /* * This is called when everything else fails, and we actually have * to go to the low-level filesystem to find out what we should do.. * * We get the directory semaphore, and after getting that we also * make sure that nobody added the entry to the dcache in the meantime.. * SMP-safe */ static struct dentry * real_lookup(struct dentry * parent, struct qstr * name, struct nameidata *nd) { struct dentry * result; struct inode *dir = parent->d_inode; //获取父目录的inode指针 mutex_lock(&dir->i_mutex); //添加互斥锁 /* * First re-do the cached lookup just in case it was created * while we waited for the directory semaphore.. * * FIXME! This could use version numbering or similar to * avoid unnecessary cache lookups. * * The "dcache_lock" is purely to protect the RCU list walker * from concurrent renames at this point (we mustn't get false * negatives from the RCU list walk here, unlike the optimistic * fast walk). * * so doing d_lookup() (with seqlock), instead of lockfree __d_lookup */ result = d_lookup(parent, name); //在目录缓存中再查找一次 if (!result) { //没找到 struct dentry *dentry; /* Don't create child dentry for a dead directory. */ result = ERR_PTR(-ENOENT); if (IS_DEADDIR(dir)) //目录已经被删除 goto out_unlock; dentry = d_alloc(parent, name); result = ERR_PTR(-ENOMEM); if (dentry) { result = dir->i_op->lookup(dir, dentry, nd); if (result) dput(dentry); else result = dentry; } out_unlock: mutex_unlock(&dir->i_mutex); return result; } /* * Uhhuh! Nasty case: the cache was re-populated while * we waited on the semaphore. Need to revalidate. */ mutex_unlock(&dir->i_mutex); if (result->d_op && result->d_op->d_revalidate) { result = do_revalidate(result, nd); if (!result) result = ERR_PTR(-ENOENT); } return result; } /* no need for dcache_lock, as serialization is taken care in * namespace.c */ static int __follow_mount(struct path *path) { int res = 0; while (d_mountpoint(path->dentry)) { //返回在该dentry目录上安装的文件系统数目 struct vfsmount *mounted = lookup_mnt(path->mnt, path->dentry); if (!mounted) //没有找到 break; dput(path->dentry); if (res) mntput(path->mnt); path->mnt = mounted; path->dentry = dget(mounted->mnt_root); res = 1; } return res; } static __always_inline void follow_dotdot(struct nameidata *nd) { struct fs_struct *fs = current->fs; //获取当前进程的文件系统指针 while(1) { struct vfsmount *parent; struct dentry *old = nd->path.dentry; //获取nd的目录指针 read_lock(&fs->lock); if (nd->path.dentry == fs->root.dentry && nd->path.mnt == fs->root.mnt) { //若最近解析的目录是进程根目录不能往上了 read_unlock(&fs->lock); break; } read_unlock(&fs->lock); spin_lock(&dcache_lock); if (nd->path.dentry != nd->path.mnt->mnt_root) { //不是文件根目录 nd->path.dentry = dget(nd->path.dentry->d_parent); //是父目录 spin_unlock(&dcache_lock); dput(old); break; } spin_unlock(&dcache_lock); spin_lock(&vfsmount_lock); parent = nd->path.mnt->mnt_parent; //获取父目录的 if (parent == nd->path.mnt) { //若何父目录的mount结构相等,在同一个文件系统中 spin_unlock(&vfsmount_lock); break; } mntget(parent); nd->path.dentry = dget(nd->path.mnt->mnt_mountpoint); //若不在同一个文件系统 spin_unlock(&vfsmount_lock); dput(old); mntput(nd->path.mnt); nd->path.mnt = parent; //获取父目录的vfsmount结构指针 } follow_mount(&nd->path.mnt, &nd->path.dentry); } /* * Lightweight file lookup - no refcnt increment if fd table isn't shared. * You can use this only if it is guranteed that the current task already * holds a refcnt to that file. That check has to be done at fget() only * and a flag is returned to be passed to the corresponding fput_light(). * There must not be a cloning between an fget_light/fput_light pair. */ struct file *fget_light(unsigned int fd, int *fput_needed) { struct file *file; struct files_struct *files = current->files; *fput_needed = 0; if (likely((atomic_read(&files->count) == 1))) { //f_count为1,不需要锁 file = fcheck_files(files, fd); //直接取file } else { rcu_read_lock(); file = fcheck_files(files, fd); //检查fd是否已达到最大,并获取fd对应的file结构 if (file) { //取得file结构指针 if (atomic_long_inc_not_zero(&file->f_count)) //f_count加1 *fput_needed = 1; //把fput_needed设置成1 else /* Didn't get the reference, someone's freed */ file = NULL; } rcu_read_unlock(); //解锁 } return file; } 参考文献: 《ulk v3》 《linux内核源代码情景分析》 linux-2.6.27 (责任编辑:IT) |