|
1.etcd 是一个应用在分布式环境下的 key/value 存储服务。利用 etcd 的特性,应用程序可以在集群中共享信息、配置或作服务发现,etcd 会在集群的各个节点中复制这些数据并保证这些数据始终正确。etcd 无论是在 CoreOS 还是 Kubernetes 体系中都是不可或缺的一环。笔者由于项目的原因对 etcd 进行了一些了解,也已经使用了一段时间。同时在与同行的交流中常被问到 etcd 是什么、与 ZooKeeper 有什么不同。那么借着 etcd 0.5.0 即将发布的机会,向感兴趣的读者介绍一下 etcd,希望可以帮助读者了解 etcd 的工作原理以及具体实现,同时也作为 CoreOS 实战的第二部分内容为后面相关的部分进行铺垫。 随着 etcd 0.5.0 alpha (本文完稿时为 etcd 0.5.0 alpha.3)版发布,etcd 将在未来几周内迎来一次重要的更新。在 0.5.0 版里除了修复现有稳定版中的一系列 Bug 之外,一些新的特性和变更也将随之发布。这些变化将提升 etcd 服务安全性、可靠性和可维护性。 新的特性包括
重要的变更包括
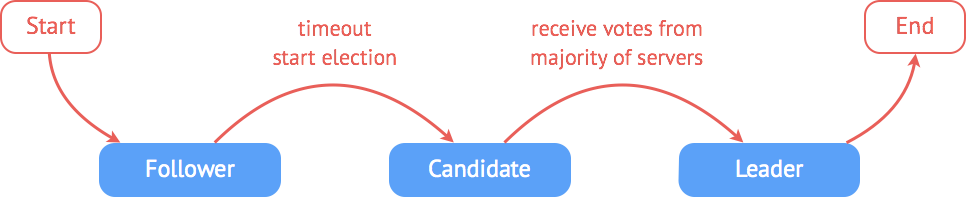
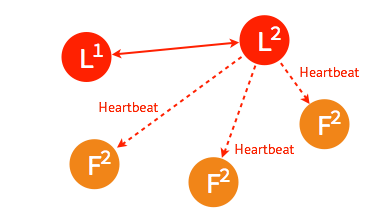
2. 规范词汇表etcd 0.5.0 版首次对 etcd 代码、文档及 CLI 中使用的术语进行了定义。 2.1. nodenode 指一个 raft 状态机实例。每个 node 都具有唯一的标识,并在处于 leader 状态时记录其它节点的步进数。 2.2. membermember 指一个 etcd 实例。member 运行在每个 node 上,并向这一 node 上的其它应用程序提供服务。 2.3. ClusterCluster 由多个 member 组成。每个 member 中的 node 遵循 raft 共识协议来复制日志。Cluster 接收来自 member 的提案消息,将其提交并存储于本地磁盘。 2.4. Peer同一 Cluster 中的其它 member。 2.5. ClientClient 指调用 Cluster API 的对象。 3. Raft 共识算法etcd 集群的工作原理基于 raft 共识算法 (The Raft Consensus Algorithm)。etcd 在 0.5.0 版本中重新实现了 raft 算法,而非像之前那样依赖于第三方库 go-raft 。raft 共识算法的优点在于可以在高效的解决分布式系统中各个节点日志内容一致性问题的同时,也使得集群具备一定的容错能力。即使集群中出现部分节点故障、网络故障等问题,仍可保证其余大多数节点正确的步进。甚至当更多的节点(一般来说超过集群节点总数的一半)出现故障而导致集群不可用时,依然可以保证节点中的数据不会出现错误的结果。 3.1. 集群建立与状态机raft 集群中的每个节点都可以根据集群运行的情况在三种状态间切换:follower, candidate 与 leader。leader 向 follower 同步日志,follower 只从 leader 处获取日志。在节点初始启动时,节点的 raft 状态机将处于 follower 状态并被设定一个 election timeout,如果在这一时间周期内没有收到来自 leader 的 heartbeat,节点将发起选举:节点在将自己的状态切换为 candidate 之后,向集群中其它 follower 节点发送请求,询问其是否选举自己成为 leader。当收到来自集群中过半数节点的接受投票后,节点即成为 leader,开始接收保存 client 的数据并向其它的 follower 节点同步日志。leader 节点依靠定时向 follower 发送 heartbeat 来保持其地位。任何时候如果其它 follower 在 election timeout 期间都没有收到来自 leader 的 heartbeat,同样会将自己的状态切换为 candidate 并发起选举。每成功选举一次,新 leader 的步进数都会比之前 leader 的步进数大1。
图 3-1 raft 状态切换示意图 3.2. 选举3.2.1. 一个 candidate 成为 leader 需要具备三个要素:
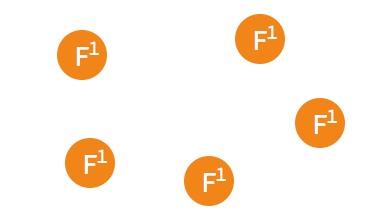
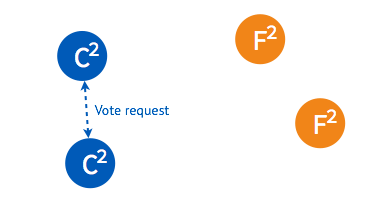
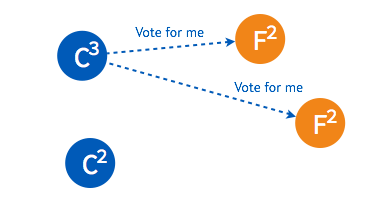
3.2.2. 下面为一个 etcd 集群选举过程的简单描述:➢ 初始状态下集群中的所有节点都处于 follower 状态。
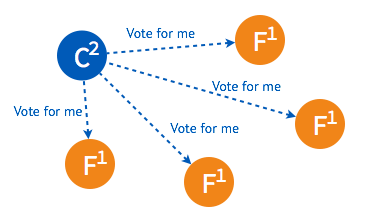
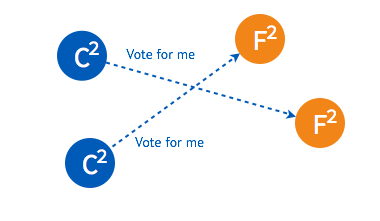
➢ 某一时刻,其中的一个 follower 由于没有收到 leader 的 heartbeat 率先发生 election timeout 进而发起选举。
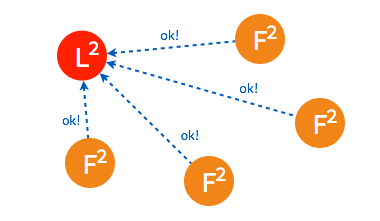
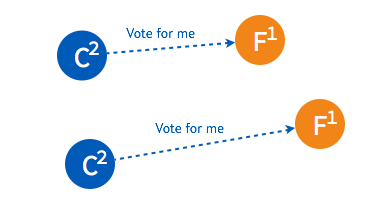
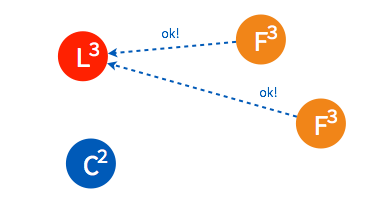
➢ 只要集群中超过半数的节点接受投票,candidate 节点将成为即切换 leader 状态。
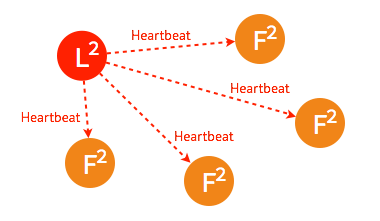
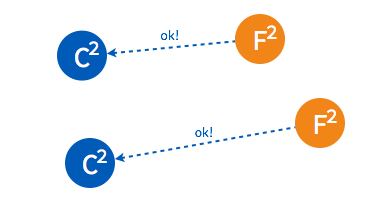
➢ 成为 leader 节点之后,leader 将定时向 follower 节点同步日志并发送 heartbeat。
3.3. 节点异常集群中各个节点的状态随时都有可能发生变化。从实际的变化上来分类的话,节点的异常大致可以分为四种类型:
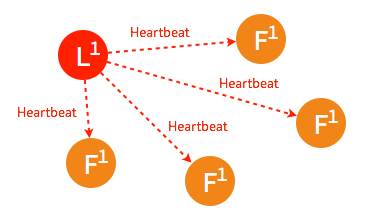
3.3.1. leader 不可用下面将说明当集群中的 leader 节点不可用时,raft 集群是如何应对的。 ➢ 一般情况下,leader 节点定时发送 heartbeat 到 follower 节点。
➢ 由于某些异常导致 leader 不再发送 heartbeat ,或 follower 无法收到 heartbeat 。
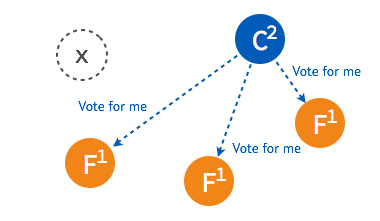
➢ 当某一 follower 发生 election timeout 时,其状态变更为 candidate,并向其他 follower 发起投票。
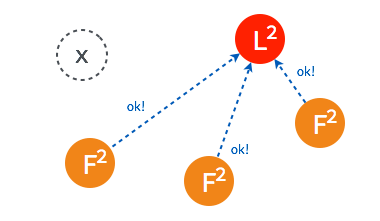
➢ 当超过半数的 follower 接受投票后,这一节点将成为新的 leader,leader 的步进数加1并开始向 follower 同步日志。
➢ 当一段时间之后,如果之前的 leader 再次加入集群,则两个 leader 比较彼此的步进数,步进数低的 leader 将切换自己的状态为 follower。
➢ 较早前 leader 中不一致的日志将被清除,并与现有 leader 中的日志保持一致。
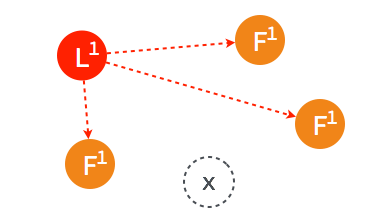
3.3.2. follower 节点不可用follower 节点不可用的情况相对容易解决。因为集群中的日志内容始终是从 leader 节点同步的,只要这一节点再次加入集群时重新从 leader 节点处复制日志即可。 ➢ 集群中的某个 follower 节点发生异常,不再同步日志以及接收 heartbeat。
➢ 经过一段时间之后,原来的 follower 节点重新加入集群。
➢ 这一节点的日志将从当时的 leader 处同步。
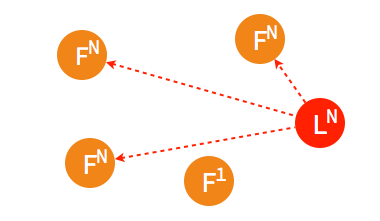
3.3.3. 多个 candidate 或多个 leader在集群中出现多个 candidate 或多个 leader 通常是由于数据传输不畅造成的。出现多个 leader 的情况相对少见,但多个 candidate 比较容易出现在集群节点启动初期尚未选出 leader 的“混沌”时期。 ➢ 初始状态下集群中的所有节点都处于 follower 状态。
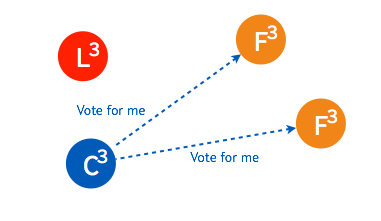
➢ 两个节点同时成为 candidate 发起选举。
➢ 两个 candidate 都只得到了少部分 follower 的接受投票。
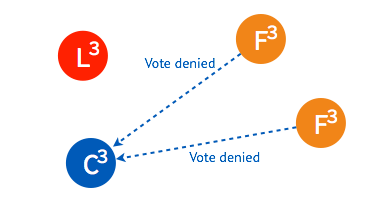
➢ candidate 继续向其他的 follower 询问。
➢ 由于一些 follower 已经投过票了,所以均返回拒绝接受。
➢ candidate 也可能向一个 candidate 询问投票。
➢ 在步进数相同的情况下,candidate 将拒绝接受另一个 candidate 的请求。
➢ 由于第一次未选出 leader,candidate 将随机选择一个等待间隔(150ms ~ 300ms)再次发起投票。
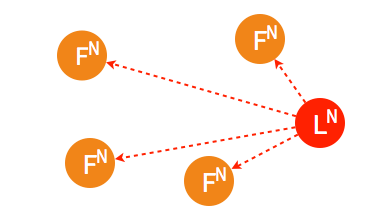
➢ 如果得到集群中半数以上的 follower 的接受,这一 candidate 将成为 leader。
➢ 稍后另一个 candidate 也将再次发起投票。
➢ 由于集群中已经选出 leader,candidate 将收到拒绝接受的投票。
➢ 在被多数节点拒绝之后,并已知集群中已存在 leader 后,这一 candidate 节点将终止投票请求、切换为 follower,从 leader 节点同步日志。
(责任编辑:IT) |