-

hadoop配置文件详解、安装及相关操作
日期:一、Hadoop伪分布配置 1.在conf/hadoop-env.sh文件中增加:export JAVA_HOME=/home/Java/jdk1.6 2.在conf/core-site.xml文件中增加如下内容: !--fs.default.name-这是一个描述集群中NameNode结点的URI(包括协议、主机名称、端口号),集群里面的每一台机器都...
-
CentOS上Hadoop环境的搭建与管理
日期:CentOS上Hadoop环境的搭建与管理 please down load the attachment 编辑日期:2015年9月1日 实验要求: 完成Hadoop平台安装部署、测试Hadoop平台功能和性能,记录实验过程,提交实验报告。 1) 掌握Hadoop安装过程 2) 理解Hadoop工作原理 3) 测试Hadoop系统的...
-
hadoop安全模式
日期:hadoop安全模式 在分布式文件系统启动的时候, 开始的时候会有安全模式 , 当分布式文件系统处于安全模式的情况下,文件系统中的内容不允许修改也不允许删除,直到安全模式结束。 安全模式主要是为了系统启动的时候检查各个DataNode上数据块的有效性,同时根...
-
用PHP编写Hadoop的MapReduce程序
日期:Hadoop流 虽然Hadoop是用java写的,但是Hadoop提供了Hadoop流,Hadoop流提供一个API, 允许用户使用任何语言编写map函数和reduce函数. Hadoop流动关键是,它使用UNIX标准流作为程序与Hadoop之间的接口。因此,任何程序只要可以从标准输入流中读取数据,并且可...
-
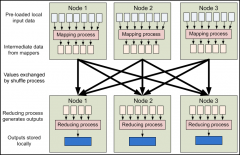
MapReduce数据流
日期:Hadoop的核心组件在一起工作时如下图所示: 图 4.4 高层 MapReduce 工作流水线 MapReduce 的输入一般来自 HDFS 中的文件,这些文件分布存储在集群内的节点上。运行一个 MapReduce 程序会在集群的许多节点甚至所有节点上运行 mapping 任务,每一个 mapping 任...
-
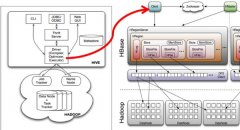
Hadoop Hive与Hbase整合+thrift
日期:1. 简介 Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapRe...
-

海量数据处理算法―Bloom Filter
日期:1. Bloom-Filter算法简介 Bloom-Filter,即布隆过滤器,1970年由Bloom中提出。它可以用于检索一个元素是否在一个集合中。 Bloom Filter(BF)是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。它是...
-
Storm集群安装详解
日期:storm有两种操作模式: 本地模式和远程模式。 本地模式:你可以在你的本地机器上开发测试你的topology, 一切都在你的本地机器上模拟出来; 远端模式:你提交的topology会在一个集群的机器上执行。 本文以Twitter Storm 官方Wiki 为基础,详细描述如何快速搭建...
-
你的数据根本不够大,别老扯什么Hadoop了
日期:本文原名 Dont use Hadoop when your data isnt that big ,出自有着多年从业经验的数据科学家 Chris Stucchio ,纽约大学柯朗研究所博士后,搞过高频交易平台,当过创业公司的CTO,更习惯称自己为统计学者。对了,他现在自己创业,提供数据分析、推荐优化咨...
-
Hive深入浅出
日期:1. Hive是什么 1) Hive是什么? 这里引用 Hive wiki 上的介绍: Hive is a data warehouse infrastructure built on top of Hadoop. It provides tools to enable easy data ETL, a mechanism to put structures on the data, and the capability to queryin...