Hadoop完全分布式配置
时间:2018-04-27 14:41 来源:linux.it.net.cn 作者:IT
Hadoop完全分布式配置
一、介绍
Hadoop2.0中,2个NameNode的数据其实是实时共享的。新HDFS采用了一种共享机制,Quorum Journal Node(JournalNode)集群或者Nnetwork File System(NFS)进行共享。NFS是操作系统层面的,JournalNode是hadoop层面的,我们这里使用JournalNode集群进行数据共享(这也是主流的做法)。如下图所示,便是JournalNode的架构图。
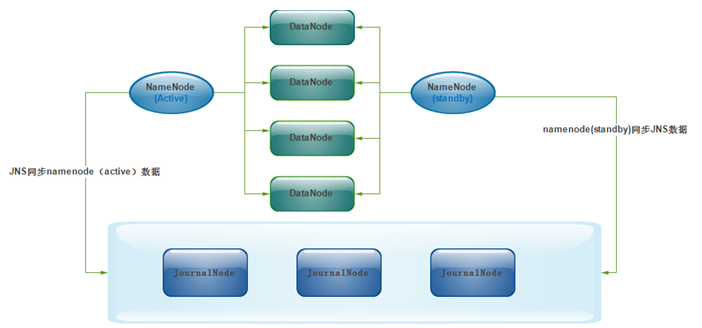
两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了。
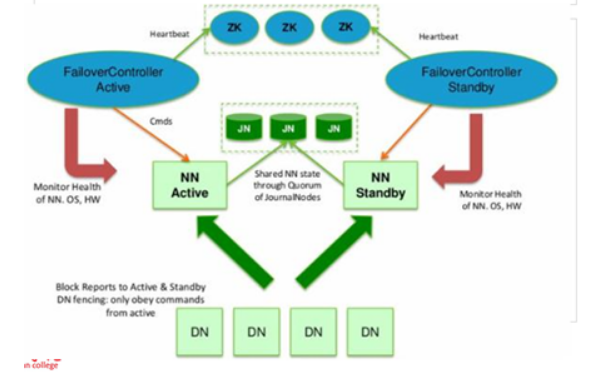
对于HA集群而言,确保同一时刻只有一个NameNode处于active状态是至关重要的。否则,两个NameNode的数据状态就会产生分歧,可能丢失数据,或者产生错误的结果。为了保证这点,这就需要利用使用ZooKeeper了。首先HDFS集群中的两个NameNode都在ZooKeeper中注册,当active状态的NameNode出故障时,ZooKeeper能检测到这种情况,它就会自动把standby状态的NameNode切换为active状态。
二、配置
1、准备环境
这里搭建一个5台服务器的集群,当然最低三台也可以搭建。
1.主机角色分配
以下为每台服务器的角色分配,可以根据自己的服务器数量进行调整。
1>hadoop01
Zookeeper、NameNode、DFSZKFailoverController、ResourceManager。
2>hadoop02
Zookeeper、NameNode2、DFSZKFailoverController。
3>hadoop03
Zookeeper、DataNode、NodeManager、JournalNode。
4>hadoop04
Zookeeper、DataNode、NodeManager、JournalNode。
5>hadoop05
Zookeeper、DataNode、NodeManager、JournalNode。
2.关闭防火墙
一般的生产环境不需要系统自带的防火墙,如果没有外置的防火墙也可以开启,但是要将通信的端口等在防火墙中允许通过。这里为了实验的简单,就直接将防火墙关闭。
service iptables status #查看防火墙状态
service iptables start #立即开启防火墙,但是重启后失效。
service iptables stop #立即关闭防火墙,但是重启后失效。
#重启后生效
chkconfig iptables on #开启防火墙,重启后生效。
chkconfig iptables off #关闭防火墙,重启后生效。
3.配置主机名
修改文件 /etc/sysconfig/network
vim /etc/sysconfig/network
!!!!!注意安装hadoop的集群主机名不能有下划线!!不然会找不到主机!无法启动!
source /etc/sysconfig/network
经过上面的修改,主机名称不会马上改变,必须重启才能生效。所以可以使用如下命令进行立即更改:
hostname
4.配置hosts
修改文件 /etc/hosts
vim /etc/hosts
填入以下内容
127.0.0.1 hadoop01
其他主机和ip对应信息。。。
以上两部操作是为了实现ip的解耦,如果你在多个框架服务里全部填写的是ip那么,一旦你服务器的ip发生改变,那么每个服务框架都需要修改ip,如果你设置的是主机名,那么当你的服务器ip发生改变,只需要修改hosts文件中,主机名和ip的映射关系即可。
5.配置免密登录
集群中所有主机都要互相进行免密登录。
生成密钥:
ssh-keygen
发送公钥:
ssh-copy-id root@hadoop01
此时在远程主机的/root/.ssh/authorized_keys文件中保存了公钥,在known_hosts中保存了已知主机信息,当再次访问的时候就不需要输入密码了。
ssh hadoop01
通过此命令远程连接,检验是否可以不需密码连接。
这里需要注意的是一定要给本机也发送一下。
6.安装jdk
1>解压安装
通过fz将jdk安装包上传、解压安装包,命令如下:
tar -zxvf [jdk安装包位置]
2>配置环境变量
修改/etc/profile。
这个文件是每个用户登录时都会运行的环境变量设置,当用户第一次登录时,该文件被执行。并从/etc/profile.d目录的配置文件中搜集shell的设置。
vim /etc/profile
在文件行尾加入以下内容后保存退出。
export JAVA_HOME=/home/app/jdk1.7.0_45/
export PATH=$PATH:$JAVA_HOME/bin
3>重新加载
重新加载profile使配置生效。
source /etc/profile
环境变量配置完成,测试环境变量是否生效。
echo $JAVA_HOME
java -version
7.搭建Zookeeper集群
参见:ZooKepper集群搭建。
2、配置hadoop
1.解压
将安装包上传到服务器,进行解压。
tar -zxvf hadoop-2.7.1_64bit.tar.gz
2.修改配置
以下文件均为Hadoop完全分布式需要配置的文件。此配置按照上述的5台服务器组件的集群。
1>hadoop-env.sh
在此文件中,将java的环境变量改为和/etc/profile文件中的java环境变量值一致即可。
JAVA_HOME=/home/app/jdk1.7.0_45/
2>core-site.xml
以下为此文件的配置模版。
<configuration>
<!-- 指定hdfs的nameservice为ns -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<!--指定hadoop数据临时存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/work/hadoop-2.7.1/tmp</value>
</property>
<!--指定hdfs操作数据的缓冲区大小 可以不配-->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!--指定zookeeper地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181,hadoop04:2181,hadoop05:2181</value>
</property>
</configuration>
3>hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为ns,需要和core-site.xml中的保持一致 --> <property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!-- ns下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>hadoop01:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>hadoop01:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>hadoop02:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>hadoop02:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop03:8485;hadoop04:8485;hadoop05:8485/ns</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/root/work/hadoop-2.7.1/tmp/journal</value>
</property>
<!-- 开启NameNode故障时自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- namenode存储位置 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/work/hadoop-2.7.1/tmp/name</value>
</property>
<!-- dataode存储位置 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/work/hadoop-2.7.1/tmp/data</value>
</property>
<!-- 副本数量根据自己的需求配置,这里配置2个 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 在NN和DN上开启WebHDFS (REST API)功能,不是必须 -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
4>mapredu-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5>yarn-site.xml
<configuration>
<!-- 指定nodemanager启动时加载server的方式为shuffle server -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定resourcemanager地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
</configuration>
6>slaves
这里我们将hadoop03、hadoop04、hadoop05配置为存储数据的节点。
vim slaves
hadoop03
hadoop04
hadoop05
3.环境变量
配置文件/etc/profile:
vim /etc/profile
在其末尾追加如下内容:
export HADOOP_HOME=[hadoop的安装路径]
export PATH=$PATH:$HADOOP_HOME\bin:$HADOOP_HOME\sbin
4.其他服务器
使用scp命令将配置文件拷贝到其他服务器上。
这里要注意,如果其他服务器的jdk,Zookeeper等配置和当前这台服务器的配置是一样的话,直接拷贝过去不用修改。
三、启动
启动完全分布式hadoop:
1、启动zk集群
./zkServer.sh start
2、启动jn集群
sbin/hadoop-daemons.sh start journalnode
1.格式化zkfc
第一次启动要格式化
hdfs zkfc -formatZK
2.格式化hdfs
第一次启动要格式化
hadoop namenode -format
3、启动NameNode
在hadoop01上:
hadoop-daemon.sh start namenode
在hadoop02上:
hdfs namenode -bootstrapStandby #把NameNode的数据同步到hadoop02上
hadoop-daemon.sh start namenode #启动备用的namenode
4、启动DataNode
hadoop-daemons.sh start datanode
5、启动yarn
start-yarn.sh
6、启动ZKFC
在hadoop01
hadoop-daemon.sh start zkfc
在hadoop02
hadoop-daemon.sh start zkfc
7、启动之后
启动完成之后,使用jps命令查看各台服务器,进程如下:
hadoop01:
10877 QuorumPeerMain
11351 NameNode
11871 DFSZKFailoverController
11570 ResourceManager
hadoop02:
16019 QuorumPeerMain
16214 NameNode
16344 DFSZKFailoverController
hadoop03:
16548 QuorumPeerMain
16783 DataNode
16893 NodeManager
16701 JournalNode
hadoop04:
16565 QuorumPeerMain
16798 DataNode
16908 NodeManager
16716 JournalNode
hadoop05:
16562 QuorumPeerMain
16809 DataNode
16919 NodeManager
16727 JournalNode
至此整个集群搭建完成,可以正常使用!
(责任编辑:IT)
Hadoop完全分布式配置一、介绍Hadoop2.0中,2个NameNode的数据其实是实时共享的。新HDFS采用了一种共享机制,Quorum Journal Node(JournalNode)集群或者Nnetwork File System(NFS)进行共享。NFS是操作系统层面的,JournalNode是hadoop层面的,我们这里使用JournalNode集群进行数据共享(这也是主流的做法)。如下图所示,便是JournalNode的架构图。
两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了。
对于HA集群而言,确保同一时刻只有一个NameNode处于active状态是至关重要的。否则,两个NameNode的数据状态就会产生分歧,可能丢失数据,或者产生错误的结果。为了保证这点,这就需要利用使用ZooKeeper了。首先HDFS集群中的两个NameNode都在ZooKeeper中注册,当active状态的NameNode出故障时,ZooKeeper能检测到这种情况,它就会自动把standby状态的NameNode切换为active状态。 二、配置1、准备环境这里搭建一个5台服务器的集群,当然最低三台也可以搭建。 1.主机角色分配以下为每台服务器的角色分配,可以根据自己的服务器数量进行调整。 1>hadoop01Zookeeper、NameNode、DFSZKFailoverController、ResourceManager。 2>hadoop02Zookeeper、NameNode2、DFSZKFailoverController。 3>hadoop03Zookeeper、DataNode、NodeManager、JournalNode。 4>hadoop04Zookeeper、DataNode、NodeManager、JournalNode。 5>hadoop05Zookeeper、DataNode、NodeManager、JournalNode。 2.关闭防火墙一般的生产环境不需要系统自带的防火墙,如果没有外置的防火墙也可以开启,但是要将通信的端口等在防火墙中允许通过。这里为了实验的简单,就直接将防火墙关闭。
3.配置主机名修改文件 /etc/sysconfig/network
!!!!!注意安装hadoop的集群主机名不能有下划线!!不然会找不到主机!无法启动!
经过上面的修改,主机名称不会马上改变,必须重启才能生效。所以可以使用如下命令进行立即更改:
4.配置hosts修改文件 /etc/hosts
填入以下内容
以上两部操作是为了实现ip的解耦,如果你在多个框架服务里全部填写的是ip那么,一旦你服务器的ip发生改变,那么每个服务框架都需要修改ip,如果你设置的是主机名,那么当你的服务器ip发生改变,只需要修改hosts文件中,主机名和ip的映射关系即可。 5.配置免密登录集群中所有主机都要互相进行免密登录。 生成密钥:
发送公钥:
此时在远程主机的/root/.ssh/authorized_keys文件中保存了公钥,在known_hosts中保存了已知主机信息,当再次访问的时候就不需要输入密码了。
通过此命令远程连接,检验是否可以不需密码连接。 这里需要注意的是一定要给本机也发送一下。 6.安装jdk1>解压安装通过fz将jdk安装包上传、解压安装包,命令如下:
2>配置环境变量修改/etc/profile。 这个文件是每个用户登录时都会运行的环境变量设置,当用户第一次登录时,该文件被执行。并从/etc/profile.d目录的配置文件中搜集shell的设置。
在文件行尾加入以下内容后保存退出。
3>重新加载重新加载profile使配置生效。
环境变量配置完成,测试环境变量是否生效。
7.搭建Zookeeper集群参见:ZooKepper集群搭建。 2、配置hadoop1.解压将安装包上传到服务器,进行解压。
2.修改配置以下文件均为Hadoop完全分布式需要配置的文件。此配置按照上述的5台服务器组件的集群。 1>hadoop-env.sh在此文件中,将java的环境变量改为和/etc/profile文件中的java环境变量值一致即可。
2>core-site.xml以下为此文件的配置模版。
3>hdfs-site.xml
4>mapredu-site.xml
5>yarn-site.xml
6>slaves这里我们将hadoop03、hadoop04、hadoop05配置为存储数据的节点。
3.环境变量配置文件/etc/profile:
在其末尾追加如下内容:
4.其他服务器使用scp命令将配置文件拷贝到其他服务器上。 这里要注意,如果其他服务器的jdk,Zookeeper等配置和当前这台服务器的配置是一样的话,直接拷贝过去不用修改。 三、启动启动完全分布式hadoop: 1、启动zk集群
2、启动jn集群
1.格式化zkfc第一次启动要格式化
2.格式化hdfs第一次启动要格式化
3、启动NameNode在hadoop01上:
在hadoop02上:
4、启动DataNode
5、启动yarn
6、启动ZKFC在hadoop01
在hadoop02
7、启动之后启动完成之后,使用jps命令查看各台服务器,进程如下: hadoop01:
hadoop02:
hadoop03:
hadoop04:
hadoop05:
至此整个集群搭建完成,可以正常使用! (责任编辑:IT) |