1 Hadoop 是什么?
Apache Hadoop 是一个支持数据密集型分布式应用程序的开源软件框架,能在大型集群上运行应用程序。Hadoop 框架实现了 MapReduce 编程范式,把应用程序分成许多小部分,每个部分能在任意节点上运行。并且 Hadoop 提供了分布式文件系统存储所有计算节点的数据,为集群带来非常高的带宽。
2 搭建说明
-
本文几乎所有操作都需要在三台服务器上进行同样的操作,所以为了便于表示,在需要三台服务器上进行同样操作的时候会使用 x3 进行标注。
-
命令当中的 # 代表 root 用户执行。
-
命令当中的 $ 代表 hadoop 用户执行。
-
### 为该命令的注释。
注:可在一台机子上配置好后利用 scp 命令进行复制,若在虚拟机则可直接复制虚拟机。
2.1 节点机器配置
|
NodeName |
OS |
CPU |
RAM |
Disk |
IP |
|
NameNode |
CentOS 7.2 |
E7-4830 v3 @ 2.10GHz x2 |
2G |
100G |
192.168.1.69 |
|
DataNode1 |
CentOS 7.2 |
E7-4830 v3 @ 2.10GHz x2 |
2G |
500G |
192.168.1.70 |
|
DataNode2 |
CentOS 7.2 |
E7-4830 v3 @ 2.10GHz x2 |
2G |
500G |
192.168.1.71 |
2.2 软件包版本
|
Software |
Version |
|
JDK |
Oracle JDK 1.8.0_131(非OpenJDK) |
|
Hadoop |
2.8.0 |
3 安装JDK x3
-
# mkdir -p /usr/local/java
-
# cd /usr/local/java
-
# wget http://download.oracle.com/otn-pub/java/jdk/8u131-b11/d54c1d3a095b4ff2b6607d096fa80163/jdk-8u131-linux-x64.tar.gz
-
# tar -xvzf jdk-8u131-linux-x64.tar.gz
-
-
### 设置新的 JDK 为默认 JDK,如果机器已经安装 OpenJDK,可能需要先卸载。
-
-
# echo "export JAVA_HOME=/usr/local/java/jdk1.8.0_131/" >> /etc/profile
-
# echo "export PATH=$PATH:$JAVA_HOME/bin" >> /etc/profile
-
# source /etc/profile
-
-
### 测试运行
-
-
# $JAVA_HOME/bin/java -version
-
java version "1.8.0_131"
-
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
-
Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
4 关闭防火墙 x3
直接关闭整个防火墙不是一个明智的选择,在具体环境中应该挑选出需要的端口,进行放行,本文由于篇幅原因,不再详细讨论,故采用直接关闭防火墙的方法。
-
# systemctl stop firewalld.service
-
# systemctl disable firewalld.service
5 配置 hostname 及局域网映射 x3
-
# hostnamectl set-hostname namenode ### 为 namenode 节点设置 hostname
-
# hostnamectl set-hostname datanode1 ### 为 datanode1 节点设置 hostname
-
# hostnamectl set-hostname datanode2 ### 为 datanode2 节点设置 hostname
-
# echo "192.168.1.69 namenode" >> /etc/hosts
-
# echo "192.168.1.70 datanode1" >> /etc/hosts
-
# echo "192.168.1.71 datanode2" >> /etc/hosts
6 创建 hadoop 用户以及 hadoop 用户组 x3
-
# groupadd hadoop
-
# useradd -m -g hadoop hadoop
-
# passwd hadoop
7 SSH 免密登录
Hadoop 在 namenode 节点中使用 ssh 来访问各节点服务器,例如开启或关闭 hadoop。显然在大型集群中,不可能手动逐个输入密码,在这种情况下,我们可以利用 ssh-agent 代理我们输入密码。
注:该设置只需要在 namenode 节点设置。
7.1 ssh-agent
配置 ssh-agent 开机自动运行
-
# echo 'eval $(ssh-agent)' >> /etc/profile
-
# source /etc/profile
7.2 配置免密登录
在 namenode 节点上登录 hadoop 用户
-
$ ssh-keygen -t rsa -f ~/.ssh/id_rsa ### 输入密钥
-
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
-
$ chmod 644 ~/.ssh/authorized_keys
-
$ ssh-copy-id datanode1 ### 将公钥 copy 到 datanode1
-
$ ssh-copy-id datanode2 ### 将公钥 copy 到 datanode2
-
$ ssh-add ~/.ssh/id_rsa ### 使用 ssh-agent 实现免密登录
-
$ ssh datanode1 ### 测试无需密码即可登录 datanode1
8 磁盘挂载(可选) x3
-
# mkdir /home/hadoop/hdfs
-
# mount /dev/sdb1 /home/hadoop/hdfs/
-
# chown -R hadoop:hadoop /home/hadoop/hdfs/
-
# echo "/dev/sdb1 /home/hadoop/hdfs ext4 defaults 0 0" >> /etc/fstab
9 安装 Hadoop x3
-
# cd /usr/local
-
# wget https://mirrors.scau.edu.cn/hadoop/hadoop-2.8.0.tar.gz ### 使用自己的镜像源
-
# wget https://mirrors.ustc.edu.cn/apache/hadoop/common/hadoop-2.8.0/hadoop-2.8.0.tar.gz
-
# tar -xvzf hadoop-2.8.0.tar.gz
-
# chown -R hadoop:hadoop hadoop-2.8.0
10 配置 Hadoop x3
复制默认配置文件,在升级 hadoop 版本时可独立出来。
-
$ mkdir ~/config/
-
$ cp -r /usr/local/hadoop-2.8.0/etc/hadoop/ ~/config/
指定 hadoop 运行所使用的 JDK 与配置目录, vim ~/config/hadoop/hadoop-env.sh
-
$ export JAVA_HOME=/usr/local/java/jdk1.8.0_131/
-
$ export HADOOP_CONF_DIR=/home/hadoop/config/hadoop/
-
-
### 最好将该环境变量也加入 /etc/profile
-
# echo "export HADOOP_CONF_DIR=/home/hadoop/config/hadoop/" >> /etc/profile
10.1 log 存储位置
修改 hadoop log 存储位置。
-
$ echo "export HADOOP_LOG_DIR=~/log/hadoop" >> ~/config/hadoop/hadoop-env.sh
修改 YARN log 存储位置,$ vim config/hadoop/yarn-env.sh。
-
YARN_LOG_DIR="/home/hadoop/log/yarn/"
10.2 配置 core-site.xml
-
$ vim ~/config/hadoop/core-site.xml
-
<?xml version="1.0" encoding="UTF-8"?>
-
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
-
<!-- Put site-specific property overrides in this file. -->
-
<configuration>
-
<property>
-
<description>默认文件系统及端口</description>
-
<name>fs.defaultFS</name>
-
<value>hdfs://namenode/</value>
-
<final>true</final>
-
</property>
-
</configuration>
10.3 配置 hdfs-site.xml
-
$ vim ~/config/hadoop/hdfs-site.xml
-
<?xml version="1.0" encoding="UTF-8"?>
-
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
-
<!-- Put site-specific property overrides in this file. -->
-
<configuration>
-
<property>
-
<description>namedoe 存储永久性的元数据目录列表</description>
-
<name>dfs.namenode.name.dir</name>
-
<value>/home/hadoop/hdfs/name/</value>
-
<final>true</final>
-
</property>
-
-
<property>
-
<description>datanode 存放数据块的目录列表</description>
-
<name>dfs.datanode.data.dir</name>
-
<value>/home/hadoop/hdfs/data/</value>
-
<final>true</final>
-
</property>
-
</configuration>
10.4 配置 mapred-site.xml
-
$ vim ~/config/hadoop/mapred-site.xml
-
<?xml version="1.0"?>
-
<configuration>
-
<property>
-
<description>MapReduce 执行框架设为 Hadoop YARN. </description>
-
<name>mapreduce.framework.name</name>
-
<value>yarn</value>
-
</property>
-
-
<property>
-
<description>Map 和 Reduce 执行的比例,Map 执行到百分之几后开始 Reduce 作业</description>
-
<!-- 此处设为1.0 即为 完成 Map 作业后才开始 Reduce 作业,内存情况不够的可设为 1.0 默认值为 0.05 -->
-
<name>mapreduce.job.reduce.slowstart.completedmaps</name>
-
<value>1.0</value>
-
</property>
-
</configuration>
10.5 配置 yarn-site.xml
-
$ vim ~/config/hadoop/yarn-site.xml
-
<?xml version="1.0"?>
-
<configuration>
-
<!-- Site specific YARN configuration properties -->
-
<property>
-
<description>The address of the applications manager interface in the RM.</description>
-
<name>yarn.resourcemanager.address</name>
-
<value>namenode:8032</value>
-
</property>
-
-
<property>
-
<name>yarn.nodemanager.aux-services</name>
-
<value>mapreduce_shuffle</value>
-
</property>
-
-
<property>
-
<description>存储中间数据的本地目录</description>
-
<name>yarn.nodemanager.local-dirs</name>
-
<value>/home/hadoop/nm-local-dir</value>
-
<final>true</final>
-
</property>
-
-
<property>
-
<description>每个容器可在 RM 申请的最大内存</description>
-
<name>yarn.scheduler.maximum-allocation-mb</name>
-
<value>2048</value>
-
<final>true</final>
-
</property>
-
-
-
<property>
-
<description>每个容器可在 RM 申请的最小内存</description>
-
<name>yarn.scheduler.minimum-allocation-mb</name>
-
<value>300</value>
-
<final>true</final>
-
</property>
-
-
<property>
-
<description>自动检测节点 CPU 与 Mem</description>
-
<name>yarn.nodemanager.resource.detect-hardware-capabilities</name>
-
<value>true</value>
-
</property>
-
-
<property>
-
<description>The address of the scheduler interface.</description>
-
<name>yarn.resourcemanager.scheduler.address</name>
-
<value>namenode:8030</value>
-
</property>
-
-
<property>
-
<description>The address of the RM web application.</description>
-
<name>yarn.resourcemanager.webapp.address</name>
-
<value>namenode:8088</value>
-
</property>
-
-
<property>
-
<description>The address of the resource tracker interface.</description>
-
<name>yarn.resourcemanager.resource-tracker.address</name>
-
<value>namenode:8031</value>
-
</property>
-
-
<property>
-
<description>The hostname of the RM.</description>
-
<name>yarn.resourcemanager.hostname</name>
-
<value>namenode</value>
-
</property>
-
</configuration>
10.6 配置 slaves
-
$ vim ~/config/hadoop/slaves
-
namenode
-
datanode1
-
datanode2
11 优化 namenode 节点命令使用
-
$ echo "export PATH=$PATH:/usr/local/hadoop-2.8.0/bin/:/usr/local/hadoop-2.8.0/sbin/" >> ~/.bash_profile
-
$ source ~/.bash_profile
12 启动集群及测试
测试之前最好重启一遍三台机器,以确保配置都生效,并且没有其他问题。
登录 namenode 节点
-
$ ssh-add ~/.ssh/id_rsa ### 验证密钥
-
$ hadoop namenode -format ### 初始化集群
-
$ start-dfs.sh ### 启动 HDFS
-
$ start-yarn.sh ### 启动 YARN
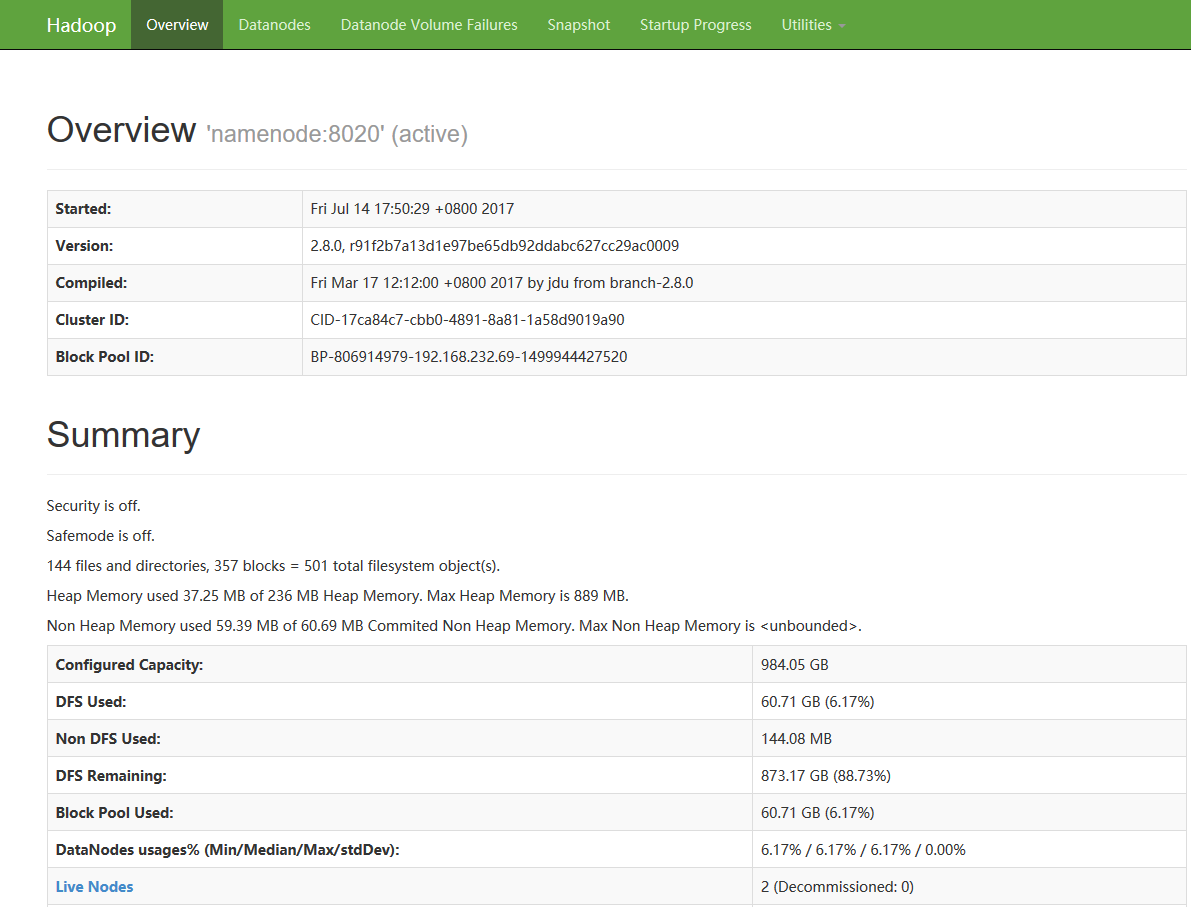
12.1 集群总览
12.2 测试用例
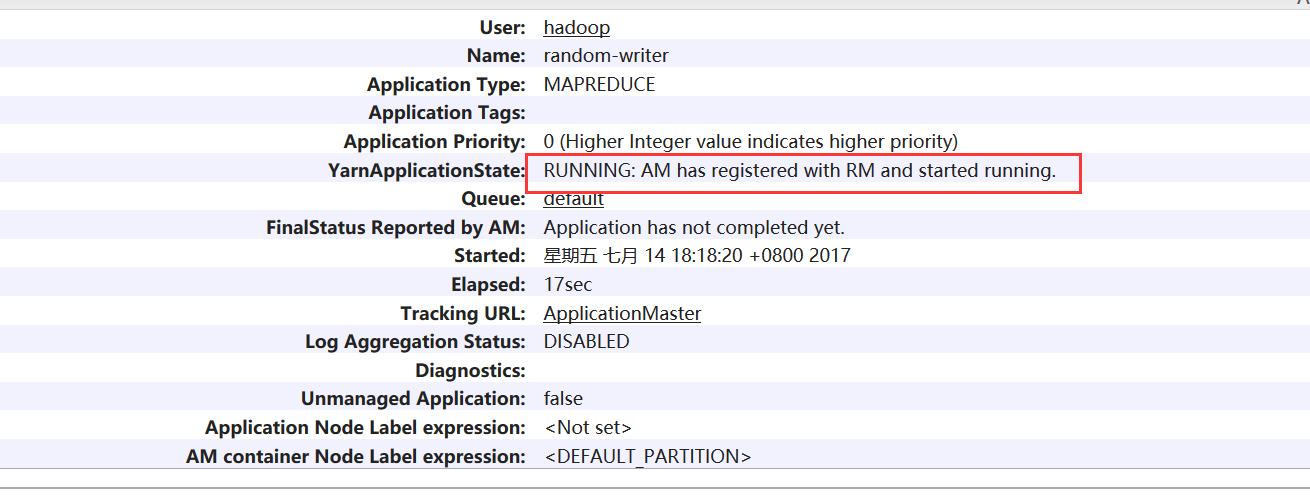
hadoop 自带了许多测试用例,所以可以很方便的快速测试集群是否搭建成功。
-
$ yarn jar /usr/local/hadoop-2.8.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.0.jar randomwriter random-data
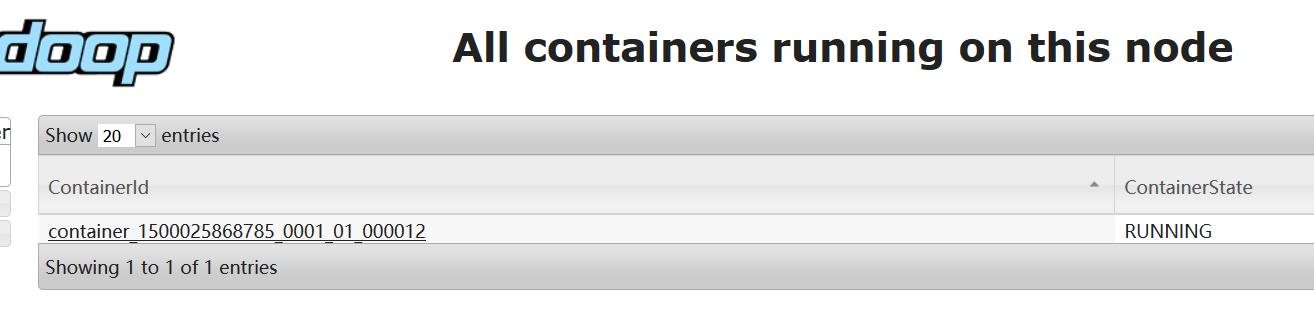
执行上述命令后,打开 RM 以及 NM 的 URL ,查看任务是否被执行,如执行,则搭建成功。
12.3 图片展示
hadoop
hadoop-task
hadoop-task
13 总结
本文从零开始搭建了具有三个节点服务器的 Hadoop 集群,示范了 Hadoop 搭建集群的基本配置。并且从中我们可以知道 Hadoop 集群的每台机子的配置几乎是相同的,这是大量重复性的劳动,因此使用 docker 会大大加快集群的部署。文中的配置文件,是我根据我自己的三台服务器的机器硬件所决定的参数,读者应该根据自己的实际情况选择参数的设置,下文的参考资料给出了各种属性的说明以及默认值。
14 参考资料
(责任编辑:IT) |