-

hadoop三个配置文件的参数含义说明(转)
日期:1获取默认配置 配置hadoop,主要是配置core-site.xml,hdfs-site.xml,mapred-site.xml三个配置文件,默认下来,这些配置文件都是空的,所以很难知道这些配置文件有哪些配置可以生效,上网找的配置可能因为各个hadoop版本不同,导致无法生效。浏览更多的配置,...
-
flume 集群datanode节点失败导致hdfs写失败(转)
日期:来自:http://www.geedoo.info/dfs-client-block-write-replace-datanode-on-failure-enable.html 这几天由于杭州集群处于升级过度时期,任务量大,集群节点少(4个DN),集群不断出现问题,导致flume收集数据出现错误,以致数据丢失。 出现数据丢失,最先拿...
-
hadoop old API CombineFileInputFormat
日期:来自:http://f.dataguru.cn/thread-271645-1-1.html 简介 本文主要介绍下面4个方面 1.为什么要使用CombineFileInputFormat 2.CombineFileInputFormat实现原理 3.怎样使用CombineFileInputFormat 4.现存的问题 使用CombineFileInputFormat的目的 在开发M...
-
hadoop multipleoutputs
日期:http://grepalex.com/2013/05/20/multipleoutputs-part1/ http://grepalex.com/2013/07/16/multipleoutputs-part2/...
-
hadoop 文件合并
日期:众所周知,Hadoop对处理单个大文件比处理多个小文件更有效率,另外单个文件也非常占用HDFS的存储空间。所以往往要将其合并起来。 1,getmerge hadoop有一个命令行工具getmerge,用于将一组HDFS上的文件复制到本地计算机以前进行合并 参考:http://hadoop.apa...
-
hadoop-处理小文件
日期:一个Hadoop程序的优化过程 根据文件实际大小实现CombineFileInputFormat http://www.rigongyizu.com/hadoop-job-optimize-combinefileinputformat/ mapreduce job让一个文件只由一个map来处理 http://www.rigongyizu.com/mapreduce-job-one-map-process-one-...
-
MapReduce实现大矩阵乘法
日期:引言 何 为大矩阵?Excel、SPSS,甚至SAS处理不了或者处理起来非常困难,需要设计巧妙的分布式方法才能高效解决基本运算(如转置、加法、乘法、求逆) 的矩阵,我们认为其可被称为大矩阵。这意味着此种矩阵的维度至少是百万级的、经常是千万级的、有时是亿万...
-
Mahout 协同过滤 itemBase RecommenderJob源码分析
日期:Mahout支持2种 M/R 的jobs实现itemBase的协同过滤 I.ItemSimilarityJob II.RecommenderJob 下面我们对RecommenderJob进行分析,版本是mahout-distribution-0.7 源码包位置:org.apache.mahout.cf.taste.hadoop.item.RecommenderJob RecommenderJob前几个阶段...
-
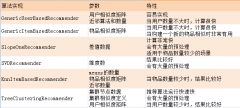
hadoop mahout 算法和API说明
日期:org.apache.mahout.cf.taste.hadoop.item.RecommenderJob.main(args) --input 偏好数据路径,文本文件。格式 userid\t itemid\t preference --output 推荐结果路径 -- numRecommendations 推荐个数 --usersFile 需要做出推荐的user,默认全部做推荐 --itemsF...
-
Maven进行Mahout编程,使其兼容Hadoop2.2.0环境运行 (转)
日期:http://blog.csdn.net/u010967382/article/details/39209329 http://blog.csdn.net/fansy1990/article/details/23261633 先编译mahout源码让其支持hadoop2 再把本地仓储repository里的jar包替换成编译后的jar包 修改后的源码包(http://download.csdn.net/de...