-

Hadoop序列化中的Writable接口(附部分源码)
日期:序列化是将结构化对象为字节流以便与通过网络进行传输或者写入持久存储。反序列化指的是将字节流转为一系列结构化对象的过程。 序化在分布式数据处理的两列大领域经常出现:进程间通信和永久存储 hadoop中,节点直接的进程间通信是用远程过程调用(RPC)实现...
-
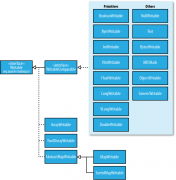
Hadoop 实现定制的Writable类型(附部分源码)
日期:writeable接口对java基本类型提供了封装,short和char除外。所有的封装包含get()和set()两个方法用于读取和设置值。 Writable的Java基本类封装 Java基本类型 Writable使用序列化大小(字节) 布尔型 BooleanWritable 1 字节型 ByteWritable 1 整型 IntWritab...
-
hadoop 压缩
日期:编码器和解码器用以执行压缩解压算法。在Hadoop里,编码/解码器是通过一个压缩解码器接口实现的。 Hadoop可用的编码/解码器。 压缩格式 Hadoop压缩编码/解码器 DEFLATE org.apache.hadoop.io.compress.DefaultCodec gzip org.apache.hadoop.io.compress.Gzip...
-
hadoop 数据一致模型
日期:文件系统的一致模型描述了对文件读写的数据可见性。HDFS为性能牺牲了一些POSIX请求,因此一些操作可能比想像的困难。 在创建一个文件之后,在文件系统的命名空间中是可见的,如下所示: pathp=newPath(p); Fs.create(p); assertThat(fs.exists(p),is(true));...
-
hadoop常见问题Browse the filesystem链接打不开
日期:现象: 在访问 Master:50070 之后,点击 browse the filesystem 后,该页无法显示。 原因: 点击 browse the filesystem 后,网页转向的地址用的是 hadoop 集群的某一个 datanode 的主机名,由于客户端的浏览器无法解析这个主机名,因此该页无法显示。 解决...
-
hadoop ClassNotFoundException解决办法
日期:我在测试hadoop时候,自己写了一个类,并且这个类中引用了2个类,运行的时候找不到引用的类。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 5...
-

hadoop文件读取剖析
日期:文件读取剖析 为了了解客户端及与之交互的HDFS、名称节点和数据节点之间的数据流是怎样的,我们可参考图3-1,其中显示了在读取文件时一些事件的主要顺序。 (点击查看大图)图3-1:客户端从HDFS中读取数据 客户端通过调用FileSystem对象的open()来读取希望打...
-
hadoop FileSystem查询文件系统
日期:文件元数据:Filestatus 任何文件系统的一个重要特征是定位其目录结构及检索其存储的文件和目录信息的能力。FileStatus类封装了文件系统中文件和目录的元数据,包括文件长度、块大...
-
hadoop包简介-HDFS的概念
日期:Hadoop的package的介绍: Package Dependences tool 提供一些命令行工具,如 DistCp , archive mapreduce Hadoop 的 Map/Reduce 实现 filecache 提供 HDFS 文件的本地缓存,用于加快 Map/Reduce 的数据访问速度 fs 文件系统的抽象,可以理解为支持多种文件...
-
hadoop-FileSystem文件写入数据
日期:FileSystem类有一系列创建文件的方法。最简单的是给拟创建的文件指定一个路径对象,然后返回一个用来写的输出流: 1 public FSDataOutputStream create(Path f) throws IOException 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 2...