hadoop文件读取剖析
时间:2015-10-08 11:31 来源:51cto.com 作者:IT
文件读取剖析
为了了解客户端及与之交互的HDFS、名称节点和数据节点之间的数据流是怎样的,我们可参考图3-1,其中显示了在读取文件时一些事件的主要顺序。
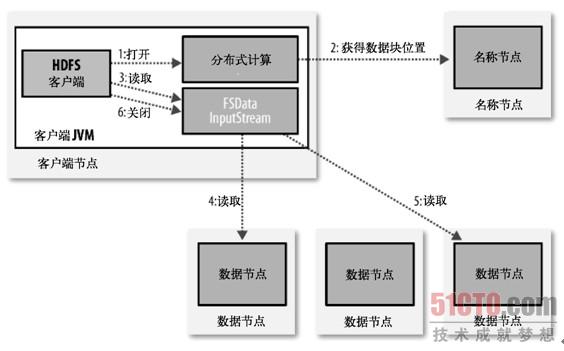
(点击查看大图)图3-1:客户端从HDFS中读取数据
客户端通过调用FileSystem对象的open()来读取希望打开的文件,对于HDFS来说,这个对象是分布式文件系统(图3-1中的步骤1)的一个实例。DistributedFileystem通过使用RPC来调用名称节点,以确定文件开头部分的块的位置(步骤2)。对于每一个块,名称节点返回具有该块副本的数据节点地址。此外,这些数据节点根据它们与客户端的距离来排序(根据网络集群的拓扑;参见后文补充材料"网络拓扑与Hadoop")。如果该客户端本身就是一个数据节点(比如在一个MapReduce任务中),便从本地数据节点中读取。
Distributed FilesyStem返回一个FSData InputStream对象(一个支持文件定位的输入流)给客户端读取数据。FSData InputStream转而包装了一个DFSInputStream对象。
接着,客户端对这个输入流调用read()(步骤3)。存储着文件开头部分的块的数据节点地址的DFSInputStream随即与这些块最近的数据节点相连接。通过在数据流中重复调用read(),数据会从数据节点返回客户端(步骤4)。到达块的末端时,DFSInputStream会关闭与数据节点间的联系,然后为下一个块找到最佳的数据节点(步骤5)。客户端只需要读取一个连续的流,这些对于客户端来说都是透明的。
客户端从流中读取数据时,块是按照DFSInputStream打开与数据节点的新连接的顺序读取的。它也会调用名称节点来检索下一组需要的块的数据节点的位置。一旦客户端完成读取,就对文件系统数据输入流调用close()(步骤6)。
在读取的时候,如果客户端在与数据节点通信时遇到一个错误,那么它就会去尝试对这个块来说下一个最近的块。它也会记住那个故障的数据节点,以保证不会再对之后的块进行徒劳无益的尝试。客户端也会确认从数据节点发来的数据的校验和。如果发现一个损坏的块,它就会在客户端试图从别的数据节点中读取一个块的副本之前报告给名称节点。
这个设计的一个重点是,客户端直接联系数据节点去检索数据,并被名称节点指引到每个块中最好的数据节点。因为数据流动在此集群中是在所有数据节点分散进行的,所以这种设计能使HDFS可扩展到最大的并发客户端数量。同时,名称节点只不过是提供块位置请求(存储在内存中,因而非常高效),不是提供数据。否则如果客户端数量增长,名称节点会快速成为一个"瓶颈"。
网络拓扑与Hadoop
两个节点在一个本地网络中被称为"彼此的近邻"是什么意思?在高容量数据处理中,限制因素是我们在节点间传送数据的速率--带宽很稀缺。这个想法便是将两个节点间的带宽作为距离的衡量标准。
衡量节点间的带宽,实际上很难实现(它需要一个稳定的集群,并且在集群中成对的节点的数量的增长要是节点数量的平方),不及Hadoop采用一个简单的方法,把网络看作一棵树,两个节点间的距离是距离它们最近的共同祖先的总和。该树中的等级是没有被预先设定的,但是它对于相当于数据中心、框架和一直在运
行的节点的等级是共同的。这个想法是,对于以下每个场景,可用带宽依次减少:
相同节点中的进程
同一机架上的不同节点
同一数据中心的不同机架上的节点
不同数据中心的节点
例如,假设节点n1在数据中心d1中的机架r1上。这被表示成/d1/r1/n1。利用这种标记,这里给出四种描述的距离:
距离(/d1/r1/n1, /d1/r1/n1)=0(相同节点中的进程)
距离(/d1/r1/n1, /d1/r1/n2)=2(同一机架上的不同节点)
距离(/d1/r1/n1, /d1/r2/n3)=4(同一数据中心的不同机架上的节点)
距离(/d1/r1/n1, /d2/r3/n4)=6(不同数据中心的节点)
这在图3-2中用图示形式表达(数学爱好者会注意到这是一个距离公制的例子)。
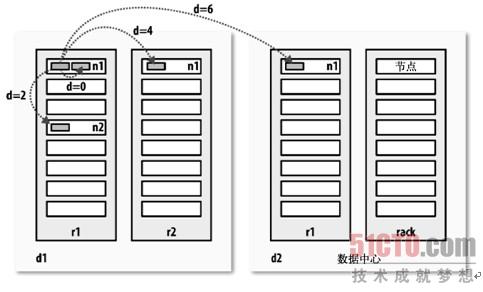
(点击查看大图)图3-2:Hadoop中的网络距离
我们必须意识到,Hadoop无法预测网络拓扑结构。它需要一定帮助,我们将在第9章讨论如何配置拓扑。不过在默认情况下,假设网络是平的(一个单层的等级制),或者换句话说,所有节点都在同一数据中心的同一机架。小的集群可能如此,所以不需要进一步的配置。 (责任编辑:IT)
文件读取剖析 为了了解客户端及与之交互的HDFS、名称节点和数据节点之间的数据流是怎样的,我们可参考图3-1,其中显示了在读取文件时一些事件的主要顺序。
客户端通过调用FileSystem对象的open()来读取希望打开的文件,对于HDFS来说,这个对象是分布式文件系统(图3-1中的步骤1)的一个实例。DistributedFileystem通过使用RPC来调用名称节点,以确定文件开头部分的块的位置(步骤2)。对于每一个块,名称节点返回具有该块副本的数据节点地址。此外,这些数据节点根据它们与客户端的距离来排序(根据网络集群的拓扑;参见后文补充材料"网络拓扑与Hadoop")。如果该客户端本身就是一个数据节点(比如在一个MapReduce任务中),便从本地数据节点中读取。 Distributed FilesyStem返回一个FSData InputStream对象(一个支持文件定位的输入流)给客户端读取数据。FSData InputStream转而包装了一个DFSInputStream对象。 接着,客户端对这个输入流调用read()(步骤3)。存储着文件开头部分的块的数据节点地址的DFSInputStream随即与这些块最近的数据节点相连接。通过在数据流中重复调用read(),数据会从数据节点返回客户端(步骤4)。到达块的末端时,DFSInputStream会关闭与数据节点间的联系,然后为下一个块找到最佳的数据节点(步骤5)。客户端只需要读取一个连续的流,这些对于客户端来说都是透明的。 客户端从流中读取数据时,块是按照DFSInputStream打开与数据节点的新连接的顺序读取的。它也会调用名称节点来检索下一组需要的块的数据节点的位置。一旦客户端完成读取,就对文件系统数据输入流调用close()(步骤6)。 在读取的时候,如果客户端在与数据节点通信时遇到一个错误,那么它就会去尝试对这个块来说下一个最近的块。它也会记住那个故障的数据节点,以保证不会再对之后的块进行徒劳无益的尝试。客户端也会确认从数据节点发来的数据的校验和。如果发现一个损坏的块,它就会在客户端试图从别的数据节点中读取一个块的副本之前报告给名称节点。 这个设计的一个重点是,客户端直接联系数据节点去检索数据,并被名称节点指引到每个块中最好的数据节点。因为数据流动在此集群中是在所有数据节点分散进行的,所以这种设计能使HDFS可扩展到最大的并发客户端数量。同时,名称节点只不过是提供块位置请求(存储在内存中,因而非常高效),不是提供数据。否则如果客户端数量增长,名称节点会快速成为一个"瓶颈"。 网络拓扑与Hadoop 两个节点在一个本地网络中被称为"彼此的近邻"是什么意思?在高容量数据处理中,限制因素是我们在节点间传送数据的速率--带宽很稀缺。这个想法便是将两个节点间的带宽作为距离的衡量标准。 衡量节点间的带宽,实际上很难实现(它需要一个稳定的集群,并且在集群中成对的节点的数量的增长要是节点数量的平方),不及Hadoop采用一个简单的方法,把网络看作一棵树,两个节点间的距离是距离它们最近的共同祖先的总和。该树中的等级是没有被预先设定的,但是它对于相当于数据中心、框架和一直在运 行的节点的等级是共同的。这个想法是,对于以下每个场景,可用带宽依次减少: 相同节点中的进程 同一机架上的不同节点 同一数据中心的不同机架上的节点 不同数据中心的节点 例如,假设节点n1在数据中心d1中的机架r1上。这被表示成/d1/r1/n1。利用这种标记,这里给出四种描述的距离: 距离(/d1/r1/n1, /d1/r1/n1)=0(相同节点中的进程) 距离(/d1/r1/n1, /d1/r1/n2)=2(同一机架上的不同节点) 距离(/d1/r1/n1, /d1/r2/n3)=4(同一数据中心的不同机架上的节点) 距离(/d1/r1/n1, /d2/r3/n4)=6(不同数据中心的节点) 这在图3-2中用图示形式表达(数学爱好者会注意到这是一个距离公制的例子)。
|