-

Hadoop常用配置总结
日期:Hadoop守护进程日志存放目录:可以用环境变量${Hadoop_LOG_DIR}进行配置,默认情况下是${HADOOP_HOME}/logs 1.配置类型节点的环境变量 在配置集群的时候可以在conf/hadoop-env.sh配置不同节点的环境变量: Daemon ConfigureOptions NameNode HADOOP_NAMENOD...
-

hadoop 优化0
日期:1.hadoop-env.sh:该文件用来配置hadoop所需的特殊环境变量: JAVA与HADOOP环境变量的设置(如果在~/.bash_profile中设置了环境变量,这里可以不进行配置) export JAVA_HOME=/home/admin/deploy/java6 exportHADOOP_HOME=/home/admin/deploy/hadoop-0.20.2...
-
Hadoop集群作业调度算法
日期:Hadoop集群中有三种作业调度算法,分别为FIFO,公平调度算法和计算能力调度算法 先来先服务(FIFO) FIFO比较简单,hadoop中只有一个作业队列,被提交的作业按照先后顺序在作业队列中排队,新来的作业插入到队尾。一个作业运行完后,总是从队首取下一个作业...
-
hadoop2.0 遇到的问题 (持续更新)
日期:最近在弄hadoop2.0,把遇到的一些问题做个笔记: 版本:apache hadoop-2.2.0 2013-10-29 在启动nodemanager的时候报下面的错误: 2013-10-2911:32:21,523FATALorg.apache.hadoop.yarn.server.nodemanager.NodeManager:ErrorstartingNodeManager java.lang.Il...
-
Hadoop HDFS 升级到2.0 笔记
日期:首先先看一下文档: http://dongxicheng.org/mapreduce-nextgen/hadoop-upgrade-to-version-2/ http://dongxicheng.org/mapreduce-nextgen/hadoop-upgrade-in-version-1/ http://www.cloudera.com/content/cloudera-content/cloudera-docs/CDH4/latest/CDH4-...
-
Hadoop2.2.0 实例测试 WordCount程序
日期:装好的hadoop测试一1个示例程序WordCount,首先需要在操作系统上新建两个任意文件,然后上传到hadoop,再运行该程序统计文件中单词的个数,最后查看结果。 在操作系统上新建任意文件: 例如: [hadoop@hadoop01 input]$ ls test1.txt test2.txt 查看hadoop的...
-

storm知识
日期:做软件开发的都知道模块化思想,这样设计的原因有两方面: 一方面是可以模块化,功能划分更加清晰,从数据采集--数据接入--流失计算--数据输出/存储 1).数据采集 负责从各节点上实时采集数据,选用cloudera的flume来实现 2).数据接入 由于采集数据的速度和...
-
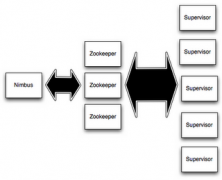
Hadoop storm知识
日期:一、Storm基本概念 在运行一个Storm任务之前,需要了解一些概念: Topologies Streams Spouts Bolts Stream groupings Reliability Tasks Workers Configuration Storm集群和Hadoop集群表面上看很类似。但是Hadoop上运行的是MapReduce jobs,而在Storm上运行...
-
hadoop---常见命令
日期:hadoop fs ls 查看/usr/root目录下的内容,默认如果不填路径这就是当前用户路径; hadoop fs rmr xxx xxx就是删除目录; hadoop dfsadmin -report 这个命令可以全局的查看DataNode的情况; hadoop job -list 后面增加参数是对于当前运行的Job的操作,例如list...
-
hadoop--bug
日期:刚刚搭建了立一个namenode,一个datanode的集群,format节点成功,并且start-all成功,但是当我运行 $ bin/hadoop fs -mkdir input $ bin/hadoop fs -put conf/core-site.xml input 命令后,出现了异常:error hdfs.DFSClient:Exception closing file /user/...