-

Hadoop 1.0.3 在CentOS 6.2上安装过程
日期://安装SSH [root@localhost /]# sudo yum install ssh //生成密钥 [root@localhost /]# ssh-keygen (可以一路回车) 生成下面两个文件: /root/.ssh/id_rsa /root/.ssh/id_rsa.pub [root@localhost .ssh]# cd /root/.ssh/ //实际情况是把公钥复制到另外一台...
-
Hadoop的shell脚本分析
日期:Hadoop的shell脚本分析 前记: 这些天一直学习hadoop,学习中也遇到了许多的问题,主要是对hadoop的shell脚本和hadoop的源码概念不够清楚,所以我就对hadoop的bin目录下的shell脚本进行了研究,有一些成果想记录下来,也希望大家前来批评指正。 分析原因: 很...
-
hadoop启动脚本分析
日期:HadoopCluster的启动可以说十分简单,最简单的一种方法就是运行$HADOOP_HOME/bin/start-all.sh,我也相信绝大多数的人都是这么启动的。但是这个脚本里面到底做了些什么呢?让我们来抽丝剥茧的看一看: 注:不失一般性,我们这里以dfs的启动为例子,mapred的启...
-
non dfs used 和dfs remaining区别
日期:DFS Used hadoop文件系统所使用的空间 Non DFS Used 非hadoop文件系统所使用的空间,比如说本身的linux系统使用的,或者存放的其它文件...
-
Hadoop YARN中内存和CPU两种资源的调度和隔离
日期:同时支持内存和CPU两种资源的调度(默认只支持内存,如果想进一步调度CPU,需要自己进行一些配置),本文将介绍Hadoop YARN是如何对这些资源进行调度和隔离的。 在YARN中,资源管理由ResourceManager和NodeManager共同完成,其中,ResourceManager中的调度器...
-
MapReduce: 提高MapReduce性能的七点建议
日期:Cloudera提供给客户的服务内容之一就是调整和优化MapReduce job执行性能。MapReduce和HDFS组成一个复杂的分布式系统,并且它们运行着各式各样用户的代码,这样导致没有一个快速有效的规则来实现优化 代码性能的目的。在我看来,调整cluster或job的运行更像一...
-
hadoop作业调优参数整理及原理(主要为shuffle过程)
日期:目录[-] 1 Map side tuning参数 1.1 MapTask运行内部原理 1.2 Map side相关参数调优 2 Reduce side tuning参数 2.1 ReduceTask运行内部原理 2.2 Reduce side相关参数调优 1 Map side tuning参数 1.1 MapTask运行内部原理 当map task开始运算,并产生中间数据...
-
hadoop数据库操作解析及注意事项
日期:1从mysql读数据到hdfs: mapreduce读数据库数据到hdfs使用map读取,连接数和map数对应,读的时候会锁表读取全量数据,此时,其它更新或者写入操作就会处于等待状态。所以读的数据库尽量不能为主库,而是用从库,主库主要负责写,从库主要负责读。若锁表读取...
-
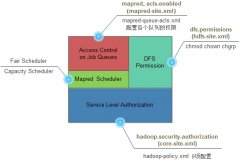
hadoop权限管理
日期:如下图,hadoop访问控制分为两级,其中ServiceLevel Authorization为系统级,用于控制是否可以访问指定的服务,例如用户/组是否可以向集群提交Job,它是最基础的访问控制,优先于文件权限和 mapred队列权限验证。Access Control on Job Queues在job调度策略...
-
