-

Centos6.5编译Hadoop2.4源码
日期:今天来说说编译hadoop源码的事情吧~ 1、首先下载源码 地址: http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.4.0/ 2、加压tar包到指定文件夹 :/home/hadoop/soft/hadoop view sourceprint? 1. tar zxvf hadoop- 2.4 . 0 -src.tar.gz 3、Linux编译...
-
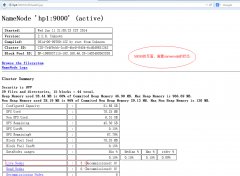
Centos6.5下部署Hadoop2.2的完全分布式集群
日期:我们来看下,如何在Centos6.5下,部署完全分布式集群。 下面先来看下具体的系统环境 序号 名称 描述 1 系统环境Centos6.5 最好在linux上部署 2 Hadoop版本Hadoop2.2.0 Hadoop2.x中的第一个稳定版本 3 JAVA环境JDK1.7 64位(build 1.7.0_25-b15) 部署情况 序号...
-
使用ganglia监控hadoop的配置方法
日期:介绍:Hadoop本身提供了很多监控工具的接口,如JMX、Nagios、Ganglia等。使用Ganglia监控hadoop,配置起来非常简单,只需要修改$HADOOP_HOME/conf/hadoop-metrics.properties文件,把相关的配置段修改为下面的示例: 复制代码 代码如下: # Configuration of...
-
创建hadoop账号的方法
日期:之前安装hadoop集群时,使用了root账号,后来发现有一些安全隐患,于是就把线上的集群统一配置到了hadoop账号下。 以下是具体操作步骤: 1:创建hadoop账号 复制代码 代码如下: useradd hadoop 2:ssh无密码登陆 复制代码 代码如下: su hadoop ssh-keygen...
-
Hadoop 报错:"Name node is in safe mode" 的解决方法
日期:运行hadoop程序时,有时会报如下的错误: org.apache.hadoop.dfs.SafeModeException: Cannot delete /user/hadoop/input. Name node is in safe mode 这个错误应该很常见的吧。 错误分析,从字面上来理解: Name node is in safe mode 说明Hadoop的NameNode...
-
linux下搭建hadoop环境步骤分享
日期:1、下载hadoop包 wget http://apache.freelamp.com/hadoop/core/stable/hadoop-0.20.2.tar.gz 2、tar xvzf hadoop-0.20.2.tar.gz 3、安装JDK,从oracle网站上直接下载JDK,地址:http://www.oracle.com/technetwork/java/javase/downloads/index.html 4、chm...
-
学习hadoop过程中用到的一些命令
日期:学习hadoop过程中用到的一些命令,这里作个记录,以备后阅。 1、ubuntu12 下如何打开终端:CTRL+ALT+t 2、ubuntu12 下查看JAVA_HOME环境变量:echo $JAVA_HOME 3、解压压缩文件:tar -xzvf hadoop-1.0.1.tar.gz 4、文件编辑命令:sudo gedit hadoop_env.sh 5...
-
执行bin/stop-all.sh的时候发现no datanode ....的解决方法
日期:hadoop使用过程中出现了很多错误,例如,执行bin/stop-all.sh的时候发现no datanode .... 解决方法: 配置完hadoop,执行bin/hadoop namenode -format 之后还需要执行 bin/hadoop datanode -format 。...
-
详解Hadoop的InputFormat类
日期:Hadoop的InputFormat类 本节介绍下org.apache.hadoop.mapreduce.InputFormat这个抽象类。 关于此抽象类的功能描述: 1、首先为Job验证输入; 2、将输入的文件分成逻辑上的splits,每个split会被应用到一个单独的mapper上; 3、提供RecorderReader的实现,用...
-
详解Hadoop更快排序的方法
日期:在Hadoop中,键默认的排序处理方法是这样的: 从一个流中读键类型的实例,使用键类型的readFields()方法来解析字节流,然后对这两个对象调用compareTo()方法。 其实,还可以实现更快的排序,可以只通过检视字节流而不用解析出包含在其中的数据来判断这两个ke...