-

一、Ubuntu14.04下安装Hadoop2.4.0 (单机模式)
日期:一、在Ubuntu下创建hadoop组和hadoop用户 增加hadoop用户组,同时在该组里增加hadoop用户,后续在涉及到hadoop操作时,我们使用该用户。 1、创建hadoop用户组 2、创建hadoop用户 sudo adduser -ingroup hadoop hadoop 回车后会提示输入新的UNIX密码,这是新...
-

二、Ubuntu14.04下安装Hadoop2.4.0 (伪分布模式)
日期:在Ubuntu14.04下安装Hadoop2.4.0(单机模式)基础上配置 一、配置core-site.xml /usr/local/hadoop/etc/hadoop/core-site.xml 包含了hadoop启动时的配置信息。 编辑器中打开此文件 sudo gedit /usr/local/hadoop/etc/hadoop/core-site.xml 在该文件的configu...
-

ubuntu + hadoop2.5.2分布式环境配置
日期:我之前有详细写过hadoop-0.20.203.0rc1版本的环境搭建 hadoop学习笔记环境搭建 http://www.cnblogs.com/huligong1234/p/3533382.html 本篇部分细节就不多说。 一、基础环境准备 系统:(VirtualBox) ubuntu-12.04.2-desktop-i386.iso hadoop版本:hadoop-2.5....
-
CentOS 6.4 编译 Hadoop 2.5.1
日期:1 前提准备 建议关闭编译机器上的防火墙与SELinux。 需要保证编译机器可以访问互联网。 卸载机器上的OpenJDK,并安装上64位的Oracle JDK。此处选用JDK7。 注意:经过实践,直到Hadoop 2.6.3使用JDK8进行编译依然存在出现各种问题。理论上应该可以解决,可是...
-
Hadoop CDH5 Impala部署
日期:Cloudera发布了实时查询开源项目Impala!多款产品实测表明,比原来基于MapReduce的Hive SQL查询速度提升3~90倍。Impala是Google Dremel的模仿,但在SQL功能上青出于蓝胜于蓝。 CDH5 Impala 安装 1impala由四部分组成: impalad - Impala的守护进程. 计划执...
-
Hadoop CDH5 Spark部署
日期:Spark是一个基于内存计算的开源的集群计算系统,目的是让数据分析更加快速,Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分...
-
hadoop云框架配置方案
日期:虽然和GOOGLE的云计算框架相差很远,但是基本能够实现云框架还是可以的,我选择了hadoop,最近这个框架在网络上炒的很火,一部分IT高手加入了开发队列,本人也不例外(不过我不是高手,只是一个很普通的系统架构师而已)。 好了废话少说,直接切入主题吧 首先使...
-
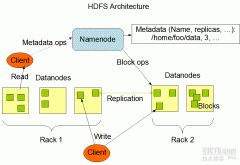
hadoop原理浅析及安装
日期:经过几天的测试,hadoop分布式系统搭建完毕。首先说一下这几天对hadoop理论知识的理解,然后说一下安装及碰到的问题。有图有真相http://192.168.0.20:50070/dfshealth.jsp 第一:理论知识: 什么是hadoop: 由三部分组成:HDFS,MapReduce和Hbase。 维基百科...
-
HDFS 常用的文件操作命令
日期:1.-cat 使用方法:hadoop fs -cat URI 说明:将路径指定的文件输出到屏幕 示例: hadoop fs -cat hdfs://host1:port1/file hadoop fs -cat file:///file3 2.-copyFromLocal 使用方法:hadoop fs -copyFromLocal localsrcURI 说明: 将本地文件复制到 HDFS 中...
-
Hadoop2.2.0+Hive0.13+MySQL5.1集成安装
日期:安装的Hive是Hive最新版本中的稳定版本,是基于Hadoop2.2.0,以前有写过,如何在hadoop1.x下面安装Hive0.8,本次Hive的版本是Hive0.13,可以直接在Hive官网上下载二进制包,无须进行源码编译。Hive需要依赖底层的Hadoop环境,所以在安装Hive前,请确保你的had...