-

HDFS 常用的文件操作命令
日期:1.-cat 使用方法:hadoop fs -cat URI 说明:将路径指定的文件输出到屏幕 示例: hadoop fs -cat hdfs://host1:port1/file hadoop fs -cat file:///file3 2.-copyFromLocal 使用方法:hadoop fs -copyFromLocal localsrcURI 说明: 将本地文件复制到 HDFS 中...
-
Hadoop2.2.0+Hive0.13+MySQL5.1集成安装
日期:安装的Hive是Hive最新版本中的稳定版本,是基于Hadoop2.2.0,以前有写过,如何在hadoop1.x下面安装Hive0.8,本次Hive的版本是Hive0.13,可以直接在Hive官网上下载二进制包,无须进行源码编译。Hive需要依赖底层的Hadoop环境,所以在安装Hive前,请确保你的had...
-
Hadoop2.2.0伪分布式完全安装手册
日期:网络上充斥着大量Hadoop1的教程,版本老旧,Hadoop2的中文资料相对较少,本教程的宗旨在于从Hadoop2出发,结合作者在实际工作中的经验,提供一套最新版本的Hadoop2相关教程。 为什么是Hadoop2.2.0,而不是Hadoop2.4.0 本文写作时,Hadoop的最新版本已经是2.4...
-
hadoop常见配置含义
日期:参数 取值 备注 fs.default.name NameNode 的URI。 hdfs://主机名/ dfs.hosts/dfs.hosts.exclude 许可/拒绝DataNode列表。 如有必要,用这个文件控制许可的datanode列表。 dfs.replication 默认: 3 数据复制的分数 dfs.name.dir 举例: /home/username/hado...
-
hadoop安装及配置流程
日期:Hadoop环境配置以及安装过程: 1、Linux系统安装,以及网络的搭建 1.1 网络的选择为host-only模式 1.2 启动vmwave的虚拟网络配置器 1.3修改ip地址,将VMware网络配置器中的iP地址设置成192.168.80.1,在Linux中网络连接中将连接更改为manual(自定义),并设...
-
apache+tomcat+mysql 负载平衡和集群技术
日期:公司开发了一个网站,估计最高在线人数是3 万,并发人数最多100 人。开发的网站是否能否承受这个压力,如何确保网站的负荷没有问题,经过研究决定如下: (1 )采用负载平衡和集群技术,初步机构采用Apache+Tomcat 的机群技术。 (2 )采用压力测试工具,测试...
-
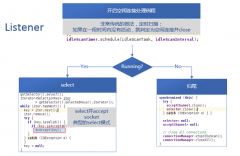
Hadoop 的 Server 及其线程模型分析
日期:一、Listener Listener线程,当Server处于运行状态时,其负责监听来自客户端的连接,并使用Select模式处理Accept事件。 同时,它开启了一个空闲连接(Idle Connection)处理例程,如果有过期的空闲连接,就关闭。这个例程通过一个计时器来实现。 当select操...
-

Linux 下 Hadoop 2.6.0 集群环境的搭建
日期:本文旨在提供最基本的,可以用于在生产环境进行Hadoop、HDFS分布式环境的搭建,对自己是个总结和整理,也能方便新人学习使用。 基础环境 JDK的安装与配置 现在直接到Oracle官网(http://www.oracle.com/)寻找JDK7的安装包不太容易,因为现在官方推荐JDK8。...
-
Hadoop DistributedCache分布式缓存的使用
日期:做项目的时候遇到一个问题,在Mapper和Reducer方法中处理目标数据时,先要去检索和匹配一个已存在的标签库,再对所处理的字段打标签。因为标签库不是很大,没必要用HBase。我的实现方法是把标签库存储成HDFS上的文件,用分布式缓存存储,这样让每个slave都能...
-
Memcached 分布式缓存实现原理
日期:摘要 在高并发环境下,大量的读、写请求涌向数据库,此时磁盘IO将成为瓶颈,从而导致过高的响应延迟,因此缓存应运而生。无论是单机缓存还是分布式缓存都有其适应场景和优缺点,当今存在的缓存产品也是数不胜数,最常见的有redis和memcached等,既然是分布式...