Linux 下 Hadoop 2.6.0 集群环境的搭建
时间:2016-05-21 14:38 来源:linux.it.net.cn 作者:IT
本文旨在提供最基本的,可以用于在生产环境进行Hadoop、HDFS分布式环境的搭建,对自己是个总结和整理,也能方便新人学习使用。
基础环境
JDK的安装与配置
现在直接到Oracle官网(http://www.oracle.com/)寻找JDK7的安装包不太容易,因为现在官方推荐JDK8。找了半天才找到JDK下载列表页的地址(http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html)。因为选择Linux操作系统作为部署环境,所以选择64位的版本。我选择的是jdk-7u79-linux-x64.gz。
使用以下命令将jdk-7u79-linux-x64.gz下载到Linux下的/home/jiaan.gja/software目录
wget http://download.oracle.com/otn-pub/java/jdk/7u79-b15/jdk-7u79-linux-x64.tar.gz
然后使用以下命令将jdk-7u79-linux-x64.gz解压缩到/home/jiaan.gja/install目录
tar zxvf jdk-7u79-linux-x64.gz -C ../install
回到/home/jiaan.gja目录,配置java环境变量,命令如下:
cd ~
vim .bash_profile
在.bash_profile中加入以下内容:

立刻让java环境变量生效,执行如下命令:
source .bash_profile
最后验证java是否安装配置正确:

Host
由于我搭建Hadoop集群包含三台机器,所以需要修改调整各台机器的hosts文件配置,命令如下:
vi /etc/hosts
如果没有足够的权限,可以切换用户为root。
如果禁止使用root权限,则可以使用以下命令修改:
sudo vi /etc/hosts
三台机器的内容统一增加以下host配置:

SSH
由于NameNode与DataNode之间通信,使用了SSH,所以需要配置免登录。
首先登录Master机器,生成SSH的公钥,命令如下:
ssh-keygen -t rsa
执行命令后会在当前用户目录下生成.ssh目录,然后进入此目录将id_rsa.pub追加到authorized_keys文件中,命令如下:
cd .ssh
cat id_rsa.pub >> authorized_keys
最后将authorized_keys文件复制到其它机器节点,命令如下:
scp authorized_keys jiaan.gja@Slave1:/home/jiaan.gja/.ssh
scp authorized_keys jiaan.gja@Slave2:/home/jiaan.gja/.ssh
文件目录
为了便于管理,给Master的hdfs的NameNode、DataNode及临时文件,在用户目录下创建目录:
/home/jiaan.gja/hdfs/name
/home/jiaan.gja/hdfs/data
/home/jiaan.gja/hdfs/tmp
然后将这些目录通过scp命令拷贝到Slave1和Slave2的相同目录下。
HADOOP的安装与配置
下载
首先到Apache官网(http://www.apache.org/dyn/closer.cgi/hadoop/common/)下载Hadoop,从中选择推荐的下载镜像(http://mirrors.hust.edu.cn/apache/hadoop/common/),我选择hadoop-2.6.0的版本,并使用以下命令下载到Master机器的/home/jiaan.gja/software目录:
cd ~/software/
wget http://apache.fayea.com/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz
然后使用以下命令将hadoop-2.6.0.tar.gz解压缩到/home/jiaan.gja/install目录
tar zxvf hadoop-2.6.0.tar.gz -C ../install/
环境变量
回到/home/jiaan.gja目录,配置hadoop环境变量,命令如下:
cd ~
vim .bash_profile
在.bash_profile中加入以下内容:
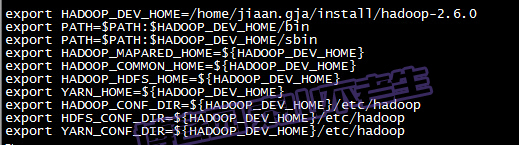
立刻让hadoop环境变量生效,执行如下命令:
source .bash_profile
Hadoop的配置
进入hadoop-2.6.0的配置目录:
cd ~/install/hadoop-2.6.0/etc/hadoop/
依次修改core-site.xml、hdfs-site.xml、mapred-site.xml及yarn-site.xml文件。
core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/jiaan.gja/hdfs/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/jiaan.gja/hdfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/jiaan.gja/hdfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.address</name>
<value>Master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>Master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>Master:18088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>Master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>Master:18141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce.shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
由于我们已经配置了JAVA_HOME的环境变量,所以hadoop-env.sh与yarn-env.sh这两个文件不用修改,因为里面的配置是:
export JAVA_HOME=${JAVA_HOME}
最后,将整个hadoop-2.6.0文件夹及其子文件夹使用scp复制到两台Slave的相同目录中:
scp -r hadoop-2.6.0 jiaan.gja@Slave1:/home/jiaan.gja/install/
scp -r hadoop-2.6.0 jiaan.gja@Slave2:/home/jiaan.gja/install/
运行HADOOP
运行HDFS
格式化NameNode
执行命令:
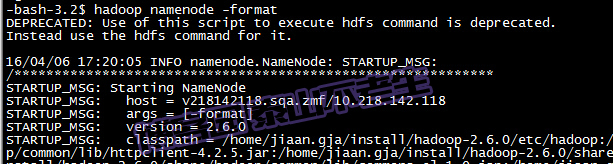
hadoop namenode -format
执行过程如下图:
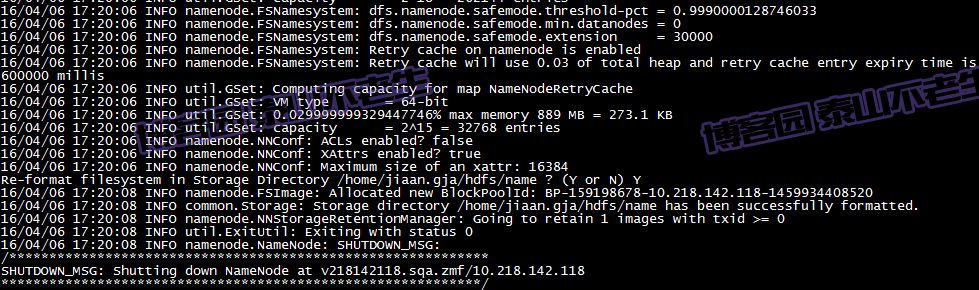
最后的执行结果如下图:
启动NameNode
执行命令如下:
hadoop-daemon.sh start namenode
执行结果如下图:

最后在Master上执行ps -ef | grep hadoop,得到如下结果:

在Master上执行jps命令,得到如下结果:
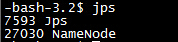
说明NameNode启动成功。
启动DataNode
执行命令如下:
hadoop-daemons.sh start datanode
执行结果如下:

在Slave1上执行命令,如下图:

在Slave2上执行命令,如下图:

说明Slave1和Slave2上的DataNode运行正常。
以上启动NameNode和DataNode的方式,可以用start-dfs.sh脚本替代:

运行YARN
运行Yarn也有与运行HDFS类似的方式。启动ResourceManager使用以下命令:
yarn-daemon.sh start resourcemanager
批量启动多个NodeManager使用以下命令:
yarn-daemons.sh start nodemanager
以上方式我们就不赘述了,来看看使用start-yarn.sh的简洁的启动方式:

在Master上执行jps:

说明ResourceManager运行正常。
在两台Slave上执行jps,也会看到NodeManager运行正常,如下图:

测试HADOOP
测试HDFS
最后测试下亲手搭建的Hadoop集群是否执行正常,测试的命令如下图所示:

测试YARN
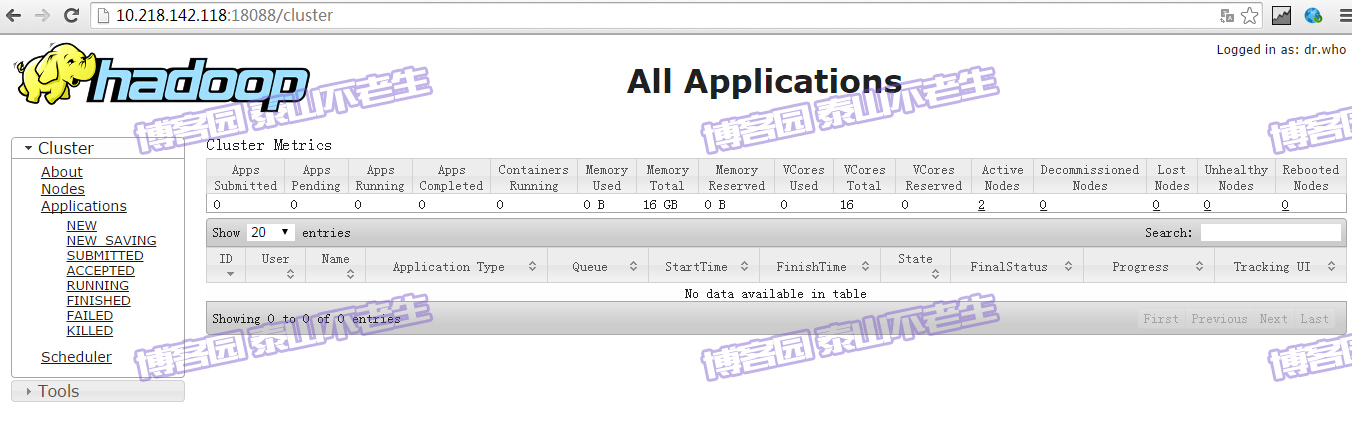
可以访问YARN的管理界面,验证YARN,如下图所示:
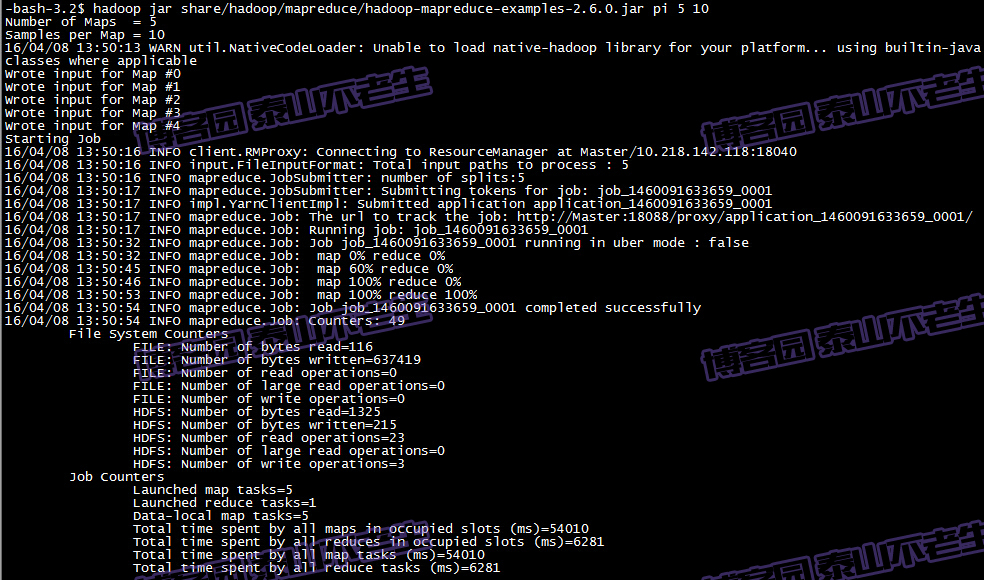
测试mapreduce
本人比较懒,不想编写mapreduce代码。幸好Hadoop安装包里提供了现成的例子,在Hadoop的share/hadoop/mapreduce目录下。运行例子:

配置运行HADOOP中遇见的问题
JAVA_HOME未设置?
我在启动Hadoop时发现Slave2机器一直启动不了,然后登录Slave2,在~/install/hadoop-2.6.0/logs目录下查看日志,发现了以下错误:
Error: JAVA_HOME is not set and could not be found.
如果我执行echo $JAVA_HOME或者查看.bash_profile文件,都证明正确配置了JAVA_HOME的环境变量。无奈之下,只能将Slave2机器的hadoop-env.sh硬编码为如下的配置:
# The java implementation to use.
export JAVA_HOME=/home/jiaan.gja/install/jdk1.7.0_79
然后问题就解决了。虽然解决了,但是目前不知道所以然,有好心的同仁,告诉我下。。。
Incompatible clusterIDs
由于配置Hadoop集群不是一蹴而就的,所以往往伴随着配置——>运行——>。。。——>配置——>运行的过程,所以DataNode启动不了时,往往会在查看日志后,发现以下问题:
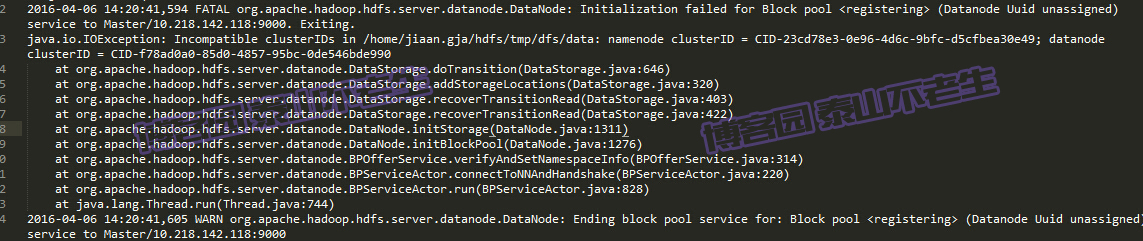
此问题是由于每次启动Hadoop集群时,会有不同的集群ID,所以需要清理启动失败节点上data目录(比如我创建的/home/jiaan.gja/hdfs/data)中的数据。
NativeCodeLoader的警告
在测试Hadoop时,细心的人可能看到截图中的警告信息:

我也是查阅网络资料,得知以下解决办法:
1、下载hadoop-native-64-2.6.0.tar:
在网站http://dl.bintray.com/sequenceiq/sequenceiq-bin/可以找到下载的相应版本,由于我是2.6.0的Hadoop,所以选择下载
2、停止Hadoop,执行命令如下:
下载完以后,解压到hadoop的native目录下,覆盖原有文件即可。操作如下:
tar xvf hadoop-native-64-2.6.0.tar -C /home/jiaan.gja/install/hadoop-2.6.0/lib/native/
令人失望的是,这种方式并不好使,看到最后的解决方案是需要下载Hadoop源码,重新编译,但这种方式有些重,我不打算尝试了。有没有简便的解决方案,还希望知道的同学告诉一下。
yarn.nodemanager.aux-services错误
在执行start-yarn.sh脚本启动YARN时,在Slave1和Slave2机器上执行jps命令未发现NodeManager进程,于是登录Slave机器查看日志,发现以下错误信息:

参考网上的解决方式,是因为yarn.nodemanager.aux-services对应的值mapreduce.shuffle已经被替换为mapreduce_shuffle。有些参考用书上也错误的写为另一个值mapreduce-shuffle。
(责任编辑:IT)
本文旨在提供最基本的,可以用于在生产环境进行Hadoop、HDFS分布式环境的搭建,对自己是个总结和整理,也能方便新人学习使用。 基础环境JDK的安装与配置现在直接到Oracle官网(http://www.oracle.com/)寻找JDK7的安装包不太容易,因为现在官方推荐JDK8。找了半天才找到JDK下载列表页的地址(http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html)。因为选择Linux操作系统作为部署环境,所以选择64位的版本。我选择的是jdk-7u79-linux-x64.gz。 使用以下命令将jdk-7u79-linux-x64.gz下载到Linux下的/home/jiaan.gja/software目录 wget http://download.oracle.com/otn-pub/java/jdk/7u79-b15/jdk-7u79-linux-x64.tar.gz 然后使用以下命令将jdk-7u79-linux-x64.gz解压缩到/home/jiaan.gja/install目录 tar zxvf jdk-7u79-linux-x64.gz -C ../install 回到/home/jiaan.gja目录,配置java环境变量,命令如下: cd ~ vim .bash_profile 在.bash_profile中加入以下内容:
source .bash_profile 最后验证java是否安装配置正确:
Host由于我搭建Hadoop集群包含三台机器,所以需要修改调整各台机器的hosts文件配置,命令如下: vi /etc/hosts 如果没有足够的权限,可以切换用户为root。 如果禁止使用root权限,则可以使用以下命令修改: sudo vi /etc/hosts 三台机器的内容统一增加以下host配置:
SSH由于NameNode与DataNode之间通信,使用了SSH,所以需要配置免登录。 首先登录Master机器,生成SSH的公钥,命令如下: ssh-keygen -t rsa 执行命令后会在当前用户目录下生成.ssh目录,然后进入此目录将id_rsa.pub追加到authorized_keys文件中,命令如下: cd .ssh cat id_rsa.pub >> authorized_keys 最后将authorized_keys文件复制到其它机器节点,命令如下: scp authorized_keys jiaan.gja@Slave1:/home/jiaan.gja/.ssh scp authorized_keys jiaan.gja@Slave2:/home/jiaan.gja/.ssh 文件目录
为了便于管理,给Master的hdfs的NameNode、DataNode及临时文件,在用户目录下创建目录: HADOOP的安装与配置下载首先到Apache官网(http://www.apache.org/dyn/closer.cgi/hadoop/common/)下载Hadoop,从中选择推荐的下载镜像(http://mirrors.hust.edu.cn/apache/hadoop/common/),我选择hadoop-2.6.0的版本,并使用以下命令下载到Master机器的/home/jiaan.gja/software目录: cd ~/software/ wget http://apache.fayea.com/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz 然后使用以下命令将hadoop-2.6.0.tar.gz解压缩到/home/jiaan.gja/install目录 tar zxvf hadoop-2.6.0.tar.gz -C ../install/ 环境变量回到/home/jiaan.gja目录,配置hadoop环境变量,命令如下: cd ~ vim .bash_profile 在.bash_profile中加入以下内容:
立刻让hadoop环境变量生效,执行如下命令: source .bash_profile Hadoop的配置进入hadoop-2.6.0的配置目录: cd ~/install/hadoop-2.6.0/etc/hadoop/ 依次修改core-site.xml、hdfs-site.xml、mapred-site.xml及yarn-site.xml文件。 core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/jiaan.gja/hdfs/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/jiaan.gja/hdfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/jiaan.gja/hdfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.address</name>
<value>Master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>Master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>Master:18088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>Master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>Master:18141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce.shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
由于我们已经配置了JAVA_HOME的环境变量,所以hadoop-env.sh与yarn-env.sh这两个文件不用修改,因为里面的配置是:
export JAVA_HOME=${JAVA_HOME}
最后,将整个hadoop-2.6.0文件夹及其子文件夹使用scp复制到两台Slave的相同目录中: scp -r hadoop-2.6.0 jiaan.gja@Slave1:/home/jiaan.gja/install/ scp -r hadoop-2.6.0 jiaan.gja@Slave2:/home/jiaan.gja/install/ 运行HADOOP运行HDFS格式化NameNode执行命令: hadoop namenode -format 执行过程如下图:
最后的执行结果如下图:
启动NameNode执行命令如下: hadoop-daemon.sh start namenode 执行结果如下图:
最后在Master上执行ps -ef | grep hadoop,得到如下结果:
在Master上执行jps命令,得到如下结果:
说明NameNode启动成功。 启动DataNode执行命令如下: hadoop-daemons.sh start datanode 执行结果如下:
在Slave1上执行命令,如下图:
说明Slave1和Slave2上的DataNode运行正常。 以上启动NameNode和DataNode的方式,可以用start-dfs.sh脚本替代:
运行YARN运行Yarn也有与运行HDFS类似的方式。启动ResourceManager使用以下命令: yarn-daemon.sh start resourcemanager 批量启动多个NodeManager使用以下命令: yarn-daemons.sh start nodemanager 以上方式我们就不赘述了,来看看使用start-yarn.sh的简洁的启动方式:
在Master上执行jps:
说明ResourceManager运行正常。 在两台Slave上执行jps,也会看到NodeManager运行正常,如下图:
测试HADOOP测试HDFS最后测试下亲手搭建的Hadoop集群是否执行正常,测试的命令如下图所示:
测试YARN可以访问YARN的管理界面,验证YARN,如下图所示:
测试mapreduce本人比较懒,不想编写mapreduce代码。幸好Hadoop安装包里提供了现成的例子,在Hadoop的share/hadoop/mapreduce目录下。运行例子:
配置运行HADOOP中遇见的问题JAVA_HOME未设置?我在启动Hadoop时发现Slave2机器一直启动不了,然后登录Slave2,在~/install/hadoop-2.6.0/logs目录下查看日志,发现了以下错误: Error: JAVA_HOME is not set and could not be found. 如果我执行echo $JAVA_HOME或者查看.bash_profile文件,都证明正确配置了JAVA_HOME的环境变量。无奈之下,只能将Slave2机器的hadoop-env.sh硬编码为如下的配置: # The java implementation to use. export JAVA_HOME=/home/jiaan.gja/install/jdk1.7.0_79 然后问题就解决了。虽然解决了,但是目前不知道所以然,有好心的同仁,告诉我下。。。 Incompatible clusterIDs由于配置Hadoop集群不是一蹴而就的,所以往往伴随着配置——>运行——>。。。——>配置——>运行的过程,所以DataNode启动不了时,往往会在查看日志后,发现以下问题:
此问题是由于每次启动Hadoop集群时,会有不同的集群ID,所以需要清理启动失败节点上data目录(比如我创建的/home/jiaan.gja/hdfs/data)中的数据。 NativeCodeLoader的警告在测试Hadoop时,细心的人可能看到截图中的警告信息:
我也是查阅网络资料,得知以下解决办法:
1、下载hadoop-native-64-2.6.0.tar: 2、停止Hadoop,执行命令如下:
下载完以后,解压到hadoop的native目录下,覆盖原有文件即可。操作如下: tar xvf hadoop-native-64-2.6.0.tar -C /home/jiaan.gja/install/hadoop-2.6.0/lib/native/ 令人失望的是,这种方式并不好使,看到最后的解决方案是需要下载Hadoop源码,重新编译,但这种方式有些重,我不打算尝试了。有没有简便的解决方案,还希望知道的同学告诉一下。 yarn.nodemanager.aux-services错误在执行start-yarn.sh脚本启动YARN时,在Slave1和Slave2机器上执行jps命令未发现NodeManager进程,于是登录Slave机器查看日志,发现以下错误信息:
参考网上的解决方式,是因为yarn.nodemanager.aux-services对应的值mapreduce.shuffle已经被替换为mapreduce_shuffle。有些参考用书上也错误的写为另一个值mapreduce-shuffle。 |