Hadoop:The Definitive Guid 总结 Chapter 10 管理Hadoop
时间:2014-12-30 23:25 来源:linux.it.net.cn 作者:IT
1.HDFS
1).永久性数据结构
A.NameNode的目录结构
NameNode被格式化之后,将产生所示的目录结构:
${dfs.name.dir}/current/VERSION
/edits
/fsimage
/fstime
dfs.name.dir属性中列出的目录的内容都是相同,同为如上所示的目录结构
VERSION文件是一个Java属性文件,一般内容如下:
#Tue May 29 11:05:47 CST 2012
namespaceID=1545978810
cTime=0
storageType=NAME_NODE
layoutVersion=-18
layoutVersion是一个负数,描述HDFS永久性数据结构的版本,只要HDFS布局变更,这个数就会递减。
namespaceID是文件系统的唯一标识,是在文件首次格式化format的时候生成。
cTime属性标记了NameNode存储系统的创建时间,对于刚格式化的存储系统,整个属性值为0,升级后会有新时间戳。
storageType属性说明该存储目录包含的是NameNode的数据结构。
另外的三个文件edits、fsimage、fstime是二进制文件。
B.文件系统映像和编辑日志
在每次执行写操作之后,且在像客户端发送成功代码之前,edit log都需要更新同步。当NameNode向多个目录写数据时,只有在所在写操作均执行完毕之后方可返回成功代码,以确保任何操作都不会因为机器故障而丢失。
fsimage文件是文件元数据的一个永久性检查点。并非每一个写操作都会更新这个文件,因为fsimage是个大文件,如果频繁执行写操作,会使系统运行极为缓慢。但这个特性根本不会降低系统的恢复能力,因为如果NameNode发生故障,可以先把fsimage文件载入到内存重构新近的元数据,再执行编辑日志记录的各项操作。事实上,NameNode在启动阶段正是这样做的。
fsimage文件包含文件系统中的所有目录和文件inode的序列化信息。每个inode都是一个文件或目录的元数据的内容描述方式。数据块存储在DataNode中,但fsimage文件并不描述DataNode。而取而代之的是,NameNode将这种块映射关系放在内存中。
当频繁执行操作的时候,edits文件无限增长。尽管这种情况对NameNode的运行没有影响,但由于需要恢复编辑日志中的各项操作,NameNode重启操作会比较慢,这段时间内文件系统处于离线状态,造成无法使用。解决方案就是运行Secondary NameNode,为主NameNode内存中的文件系统元数据创建检查点。创建检查点的步骤如下:
(1)、Secondary NameNode请求NameNode停止使用edits文件,暂时将新的写操作记录到一个新文件中(命名为edits.new)。
(2)、Secondary NameNode从NameNode获取fsimage文件和edit log(采用HTTP GET方式)。
(3)、Secondary NameNode将fsimage文件载入内存,应用edit log,创建一个新的fsimage文件。
(4)、Secondary NameNode将新的fsimage文件发回NameNode(采用HTTP POST方式)。
(5)、NameNode用从Secondary NameNode接收的fsimage文件替换旧的fsimage文件,用1所产生的edits.new改为edits 替换原来的edits,同时,还更新fstime文件来记录检查点执行的时间。
最后,NameNode拥有新的fsimage文件和一个更小的edits文件(edits文件可能已经记录一些NameNode刚刚收到的写操作),过程如下图:
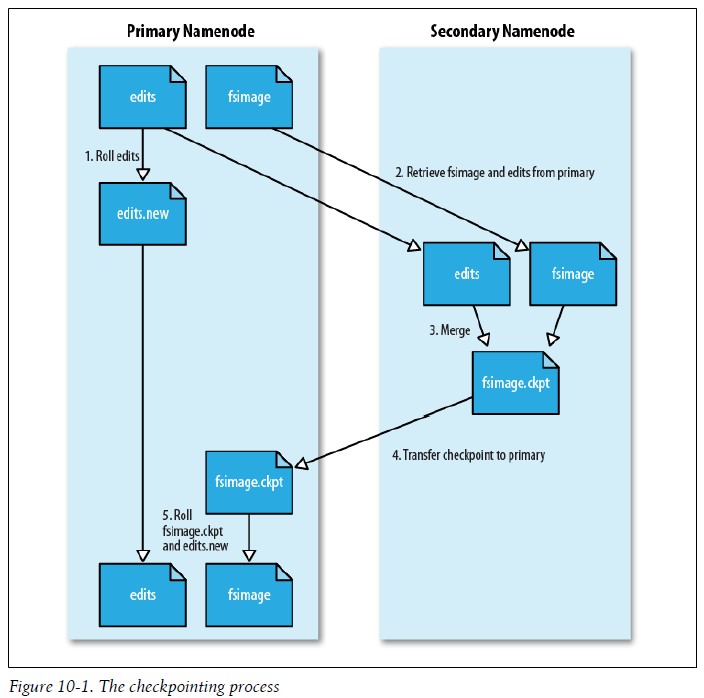
通过配置fs.checkpoint.period属性可以指定创建检查点时间间隔,默认是1小时,值的单位是秒。还有一个属性fs.checkpoint.size会触发创建检查点,默认是当edits大小超过64M时创建。
C.Secondary NameNode的目录结构
Secondary NameNode创建检查点的过程不仅是为NameNode创建检查点数据,还可以用作NameNode元数据的备份(尽管非最新),它的目录结构如下:
${fs.checkpoint.dir}/current/VERSION
/edits
/fsimage
/fstime
/previouts.checkpoint/VERSION
/edits
/fsimage
/fstime
目录结构previouts.checkpoint和NameNode结构相同,这种设计方案的好处是,在NameNode发生故障时(假设没有及时备份,甚至NFS也没有),可以从Secondary NameNode恢复数据。一种方法是将相关存储目录复制到新的NameNode中;另一种方法是使用-importCheckpoint选项重启Secondary NameNode守护进程,从而将Secondary NameNode用作新的NameNode。借助这个选项,dfs.name.dir属性定义的目录中没有元数据时,Secondary NameNode就从fs.checkpoint.dir目录载入最新的检查点数据。
D.DataNode的目录结构
和NameNode不同,DataNode的存储目录是启动时自动创建的,不需要额外格式化。DataNode的关键文件和目录如下:
${dfs.data.dir}/current/VERSION
/blk_<id_1>
/blk_<id_1>.meta
/blk_<id_2>
/blk_<id_2>.meta
/......
/blk_<id_64>
/blk_<id_64>.meta
/subdir0/
/subdir1/
/......
/subdir63/
DataNode的VERSION文件和NameNode的VERSION文件非常相似,内容类似如下:
#Tue Mar 10 21:32:31 GMT 2009
namespaceID=134368441
storageID=DS-547717739-172.16.85.1-50010-1236720751627
cTime=0
storageType=DATA_NODE
layoutVersion=-18
namespaceID属性、cTime属性和layoutVersion属性的值与NameNode中的值相同,实际上,namespaceID是DataNode首次访问NameNode的时候从NameNode处读取的,各个DataNode的storageID都不相同(但对于存储目录是相同的),NameNode可用这个属性来识别DataNode。storageType表示这个目录是DATA_NODE,区别于NAME_NODE。
DataNode的current目录中的文件有blk_前缀的,包含两种文件类型:HDFS块文件(仅包含原始数据)和块的元数据文件(含.meta后缀)。元数据文件包括头部(含版本和类型信息)和该块各区段的一系列的校验和。
当目录中数据块的数量增加到一定规模时,DataNode会创建一个子目录来存放新的数据块及其元数据信息。这个数量规模由属性dfs.DataNode.numblocks进行配置,默认是64块就创建一个子目录。终极目标是设计一棵高扇出的树,只要访问少数几个目录即可获取数据,同时也避免了很多文件放在一个目录之中的难题。如果dfs.data.dir属性指定了不同磁盘上的多个目录,那么数据块会以轮转的方式写到各个目录中。注意:同一个DataNode上的每个磁盘上的块不会重复,不同DataNode之间的块才可能重复。
2).安全模式
NameNode启动时,是在安全模式下的。它首先将fsimage载入内存,并执行edit log中的各项操作。一旦在内存中成功创建文件系统元数据的映像,则创建一个新的fsimage文件(不需要借助Secondary NameNode)和一个空的编辑日志。此时NameNode监听RPC和HTTP请求。这个过程NameNode的文件系统对于客户端来说是只读的。由于在安全模式下,写、删除或重命名等操作都会失败。
需要强调的是数据块的位置并不是NameNode维护的,而是以块列表的形式存储在DataNode中。在系统的正常操作期间,NameNode会在内存中保留所有块位置的映射信息。各个DataNode会向NameNode检查块列表信息(即向NameNode发送块列表的最新情况),NameNode了解到足够多的块位置信息之后,即可高效运行文件系统。但如果NameNode没有检查到足够多的DataNode,则需要将块复制到其他DataNode,而大多数情况下这都不必要的(因为只要等待检查到若干DataNode检入),这会浪费很多资源。所以需要安全模式,在安全模式下NameNode并不向DataNode发出任何块复制或删除的指令。如果满足“最小复本条件”,NameNode会在30秒后退出安全模式,所谓最小复本条件指在整个文件系统中99.9%的块满足dfs.replication.min属性设置的值即可。
在启动一个刚刚格式化的HDFS集群时,系统中没有任何块,所以不会进入安全模式。相关属性如下:
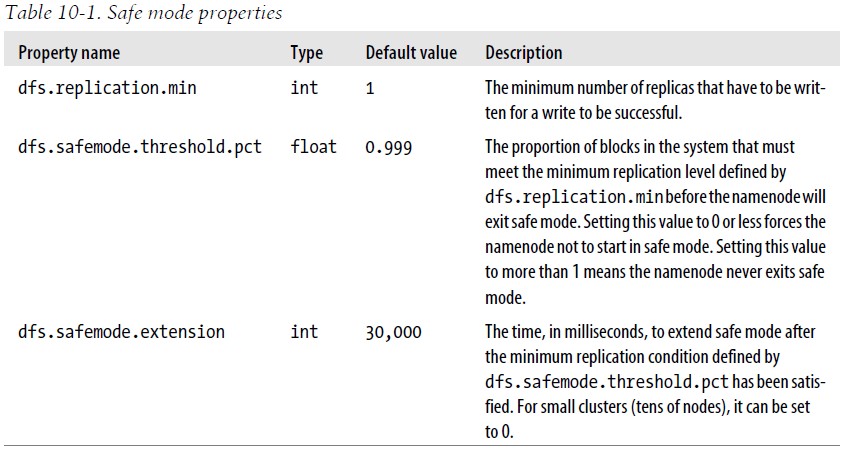
关于安全模式命令:
利用dfsadmin命令查看NameNode是否处于安全模式:
% hadoop dfsadmin -safemode get
Safe mode is ON
执行某条命令之前NameNode先退出安全模式:
% hadoop dfsadmin -safemode wait
# command to read or write a file
进入安全模式:
% hadoop dfsadmin -safemode enter
Safe mode is ON
离开安全模式:
% hadoop dfsadmin -safemode leave
Safe mode is OFF
3).日志审计
HDFS的日志能够记录所有文件系统访问请求,有些组织需要这项特性来进行审计,对日志进行审计是log4j在INFO级别实现
4).工具
A.dfsadmin工具
dfsadmin工具可查找HDFS状态信息,也可以在HDFS上执行管理操作,调用形式:hadoop dfsadmin。下面列举了dfsadmin命令:
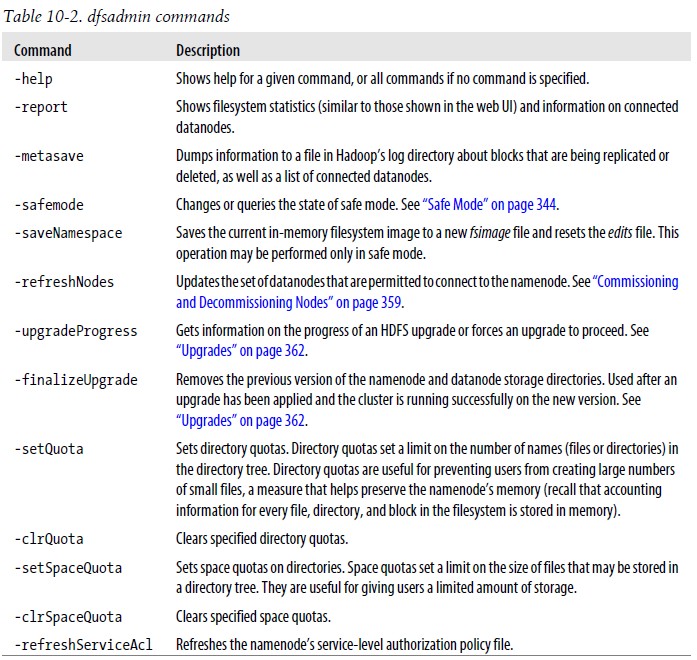
B.fsck工具
Hadoop提供fsck工具来检查HDFS中文件的健康状况,该工具会查找那些所有DataNode中缺失的块以及过少或过多副本的块, fsck执行如下某一选项操作:
-
-move选项将受影响的文件移到HDFS的/lost+found/目录
-
-delete选项删除受影响文件
-
-files选项显示第一行信息,包括文件名称、大小、块数量和健康状况(是否有缺损块)
-
-blocks选项描述文件中各个快信息,每一个块一行
-
-racks选项显示各个块的机架位置和DataNode的地址
C.DataNode块扫描器
各个DataNode运行一个块扫描器,定期检测本节点上的所有块,从而在客户端读到坏块之前及时地检测和修复坏块,用户可以访问http://datanode:50075/blockScannerReport来获取该DataNode的块测试报告
D.均衡器
均衡器(balancer)程序是一个Hadoop守护程序,它将块从忙碌的DataNode移到相对空闲的DataNode,从而重新分配块,这个作用有利于防止节点之间负载不均匀,调用均衡器指令:
% start-balancer.sh
2.监控
1).日志
Hadoop所产生的日志用于查看系统所发生的事件,其中可以通过log4j.properties的级别来控制日志的输出
2).度量
HDFS和MapReduce守护进程的事件和度量相关的信息,这些信息统称为“度量”。度量从属于特定的上下文(Context),利用上下文可以收集度量,关于上下文的类有:FileContext、GangliaContext、NullContextWithUpdateThread和CompositeContext
3).Java管理扩展
Java管理扩展是一个标准的Java API,可控制和管理应用,详见相关文档
3.维护
1).日志管理过程
A.元数据备份
两种方法:第一种,直接保存这些元数据文件的副本。第二种,方法整合到namenode上正在使用的文件中。
B.数据备份
distcp是一个理想的备份工具,其并行复制文件的功能可以将备份文件存储到其他HDFS集群
C.fsck工具
D.系统均衡器
2).委任和解除节点
A.委任添加节点
-
向集群添加新节点的步骤
-
将新节点的网络地址添加到include文件中
-
执行以下命令,使用一系列新的审核过的datanode来更新namenode设置:
% hadoop dfsadmin -refreshNodes
-
执行以下命令,使用一系列新的审核过的tasktracker来更新jobtracker设置:
% hadoop mradmin -refreshNodes
-
以新节点更新slaves文件,这样的话,Hadoop控制脚本会将新节点包括在未来操作中。
-
启动新的datanode和tasktracker。
-
检查新的datanode和tasktracker是否出现在Web UI中
B.解除节点
-
将待解除节点的网址地址添加exclude文件中。不更新include文件
-
重启MapReduce集群,以终止在待解除节点上运行的tasktracker。
-
执行以下命令,使用一系列新的审核过的datanode来更新namenode设置:
% hadoop dfsadmin -refreshNodes
-
执行以下命令,使用一系列新的审核过的tasktracker来更新jobtracker设置:
% hadoop mradmin -refreshNodes
-
转到Web UI,查看带解除datanode的管理状态是否已经变为“Decommission In Progress”,这些datanode的块将自己的数据复制到其他datanode中。
-
当所有datanode的状态为“Decommissioned”时,表明所有块都已经复制完毕。关闭已经解除的节点。
-
从include文件中移除这些节点,并运行以下命令:
% hadoop dfsadmin -refreshNodes
% hadoop mradmin -refreshNodes
-
从slaves文件移除节点
HDFS中的include文件和exclude文件:

3).升级
升级集群会导致文件系统的布局变化,则需要采用下述步骤进行升级
-
在升级任务执行之前,确保前一升级已经定妥
-
关闭MapReduce,终止子tasktracker上运行的任何孤儿任务
-
关闭HDFS,并备份namenode目录
-
在集群和客户端安装新版本的Hadoop HDFS和MapReduce
-
使用 -upgrade选项启动HDFS
-
等地,直到升级完成
-
检验HDFS是否运行正常
-
启动MapReduce
-
回滚或定妥升级人去(可选)
各步骤详细命令见Hadoop手册
转载地址:http://www.cnblogs.com/biyeymyhjob/archive/2012/08/13/2636452.html
(责任编辑:IT)
1.HDFS 1).永久性数据结构 A.NameNode的目录结构 NameNode被格式化之后,将产生所示的目录结构:
dfs.name.dir属性中列出的目录的内容都是相同,同为如上所示的目录结构 VERSION文件是一个Java属性文件,一般内容如下:
layoutVersion是一个负数,描述HDFS永久性数据结构的版本,只要HDFS布局变更,这个数就会递减。 namespaceID是文件系统的唯一标识,是在文件首次格式化format的时候生成。 cTime属性标记了NameNode存储系统的创建时间,对于刚格式化的存储系统,整个属性值为0,升级后会有新时间戳。 storageType属性说明该存储目录包含的是NameNode的数据结构。 另外的三个文件edits、fsimage、fstime是二进制文件。
B.文件系统映像和编辑日志 在每次执行写操作之后,且在像客户端发送成功代码之前,edit log都需要更新同步。当NameNode向多个目录写数据时,只有在所在写操作均执行完毕之后方可返回成功代码,以确保任何操作都不会因为机器故障而丢失。 fsimage文件是文件元数据的一个永久性检查点。并非每一个写操作都会更新这个文件,因为fsimage是个大文件,如果频繁执行写操作,会使系统运行极为缓慢。但这个特性根本不会降低系统的恢复能力,因为如果NameNode发生故障,可以先把fsimage文件载入到内存重构新近的元数据,再执行编辑日志记录的各项操作。事实上,NameNode在启动阶段正是这样做的。
当频繁执行操作的时候,edits文件无限增长。尽管这种情况对NameNode的运行没有影响,但由于需要恢复编辑日志中的各项操作,NameNode重启操作会比较慢,这段时间内文件系统处于离线状态,造成无法使用。解决方案就是运行Secondary NameNode,为主NameNode内存中的文件系统元数据创建检查点。创建检查点的步骤如下:
最后,NameNode拥有新的fsimage文件和一个更小的edits文件(edits文件可能已经记录一些NameNode刚刚收到的写操作),过程如下图:
通过配置fs.checkpoint.period属性可以指定创建检查点时间间隔,默认是1小时,值的单位是秒。还有一个属性fs.checkpoint.size会触发创建检查点,默认是当edits大小超过64M时创建。
C.Secondary NameNode的目录结构 Secondary NameNode创建检查点的过程不仅是为NameNode创建检查点数据,还可以用作NameNode元数据的备份(尽管非最新),它的目录结构如下:
目录结构previouts.checkpoint和NameNode结构相同,这种设计方案的好处是,在NameNode发生故障时(假设没有及时备份,甚至NFS也没有),可以从Secondary NameNode恢复数据。一种方法是将相关存储目录复制到新的NameNode中;另一种方法是使用-importCheckpoint选项重启Secondary NameNode守护进程,从而将Secondary NameNode用作新的NameNode。借助这个选项,dfs.name.dir属性定义的目录中没有元数据时,Secondary NameNode就从fs.checkpoint.dir目录载入最新的检查点数据。
D.DataNode的目录结构 和NameNode不同,DataNode的存储目录是启动时自动创建的,不需要额外格式化。DataNode的关键文件和目录如下:
DataNode的VERSION文件和NameNode的VERSION文件非常相似,内容类似如下:
namespaceID属性、cTime属性和layoutVersion属性的值与NameNode中的值相同,实际上,namespaceID是DataNode首次访问NameNode的时候从NameNode处读取的,各个DataNode的storageID都不相同(但对于存储目录是相同的),NameNode可用这个属性来识别DataNode。storageType表示这个目录是DATA_NODE,区别于NAME_NODE。 DataNode的current目录中的文件有blk_前缀的,包含两种文件类型:HDFS块文件(仅包含原始数据)和块的元数据文件(含.meta后缀)。元数据文件包括头部(含版本和类型信息)和该块各区段的一系列的校验和。 当目录中数据块的数量增加到一定规模时,DataNode会创建一个子目录来存放新的数据块及其元数据信息。这个数量规模由属性dfs.DataNode.numblocks进行配置,默认是64块就创建一个子目录。终极目标是设计一棵高扇出的树,只要访问少数几个目录即可获取数据,同时也避免了很多文件放在一个目录之中的难题。如果dfs.data.dir属性指定了不同磁盘上的多个目录,那么数据块会以轮转的方式写到各个目录中。注意:同一个DataNode上的每个磁盘上的块不会重复,不同DataNode之间的块才可能重复。
2).安全模式 NameNode启动时,是在安全模式下的。它首先将fsimage载入内存,并执行edit log中的各项操作。一旦在内存中成功创建文件系统元数据的映像,则创建一个新的fsimage文件(不需要借助Secondary NameNode)和一个空的编辑日志。此时NameNode监听RPC和HTTP请求。这个过程NameNode的文件系统对于客户端来说是只读的。由于在安全模式下,写、删除或重命名等操作都会失败。 需要强调的是数据块的位置并不是NameNode维护的,而是以块列表的形式存储在DataNode中。在系统的正常操作期间,NameNode会在内存中保留所有块位置的映射信息。各个DataNode会向NameNode检查块列表信息(即向NameNode发送块列表的最新情况),NameNode了解到足够多的块位置信息之后,即可高效运行文件系统。但如果NameNode没有检查到足够多的DataNode,则需要将块复制到其他DataNode,而大多数情况下这都不必要的(因为只要等待检查到若干DataNode检入),这会浪费很多资源。所以需要安全模式,在安全模式下NameNode并不向DataNode发出任何块复制或删除的指令。如果满足“最小复本条件”,NameNode会在30秒后退出安全模式,所谓最小复本条件指在整个文件系统中99.9%的块满足dfs.replication.min属性设置的值即可。 在启动一个刚刚格式化的HDFS集群时,系统中没有任何块,所以不会进入安全模式。相关属性如下:
关于安全模式命令: 利用dfsadmin命令查看NameNode是否处于安全模式:
执行某条命令之前NameNode先退出安全模式:
进入安全模式:
离开安全模式:
3).日志审计 HDFS的日志能够记录所有文件系统访问请求,有些组织需要这项特性来进行审计,对日志进行审计是log4j在INFO级别实现
4).工具 A.dfsadmin工具 dfsadmin工具可查找HDFS状态信息,也可以在HDFS上执行管理操作,调用形式:hadoop dfsadmin。下面列举了dfsadmin命令:
B.fsck工具 Hadoop提供fsck工具来检查HDFS中文件的健康状况,该工具会查找那些所有DataNode中缺失的块以及过少或过多副本的块, fsck执行如下某一选项操作:
C.DataNode块扫描器 各个DataNode运行一个块扫描器,定期检测本节点上的所有块,从而在客户端读到坏块之前及时地检测和修复坏块,用户可以访问http://datanode:50075/blockScannerReport来获取该DataNode的块测试报告
D.均衡器 均衡器(balancer)程序是一个Hadoop守护程序,它将块从忙碌的DataNode移到相对空闲的DataNode,从而重新分配块,这个作用有利于防止节点之间负载不均匀,调用均衡器指令:
2.监控 1).日志 Hadoop所产生的日志用于查看系统所发生的事件,其中可以通过log4j.properties的级别来控制日志的输出 2).度量 HDFS和MapReduce守护进程的事件和度量相关的信息,这些信息统称为“度量”。度量从属于特定的上下文(Context),利用上下文可以收集度量,关于上下文的类有:FileContext、GangliaContext、NullContextWithUpdateThread和CompositeContext 3).Java管理扩展 Java管理扩展是一个标准的Java API,可控制和管理应用,详见相关文档
3.维护 1).日志管理过程 A.元数据备份 两种方法:第一种,直接保存这些元数据文件的副本。第二种,方法整合到namenode上正在使用的文件中。 B.数据备份 distcp是一个理想的备份工具,其并行复制文件的功能可以将备份文件存储到其他HDFS集群 C.fsck工具 D.系统均衡器
2).委任和解除节点 A.委任添加节点
B.解除节点
HDFS中的include文件和exclude文件:
3).升级 升级集群会导致文件系统的布局变化,则需要采用下述步骤进行升级
各步骤详细命令见Hadoop手册 |