hadoop启动脚本解读
时间:2015-02-27 01:32 来源:linux.it.net.cn 作者:IT
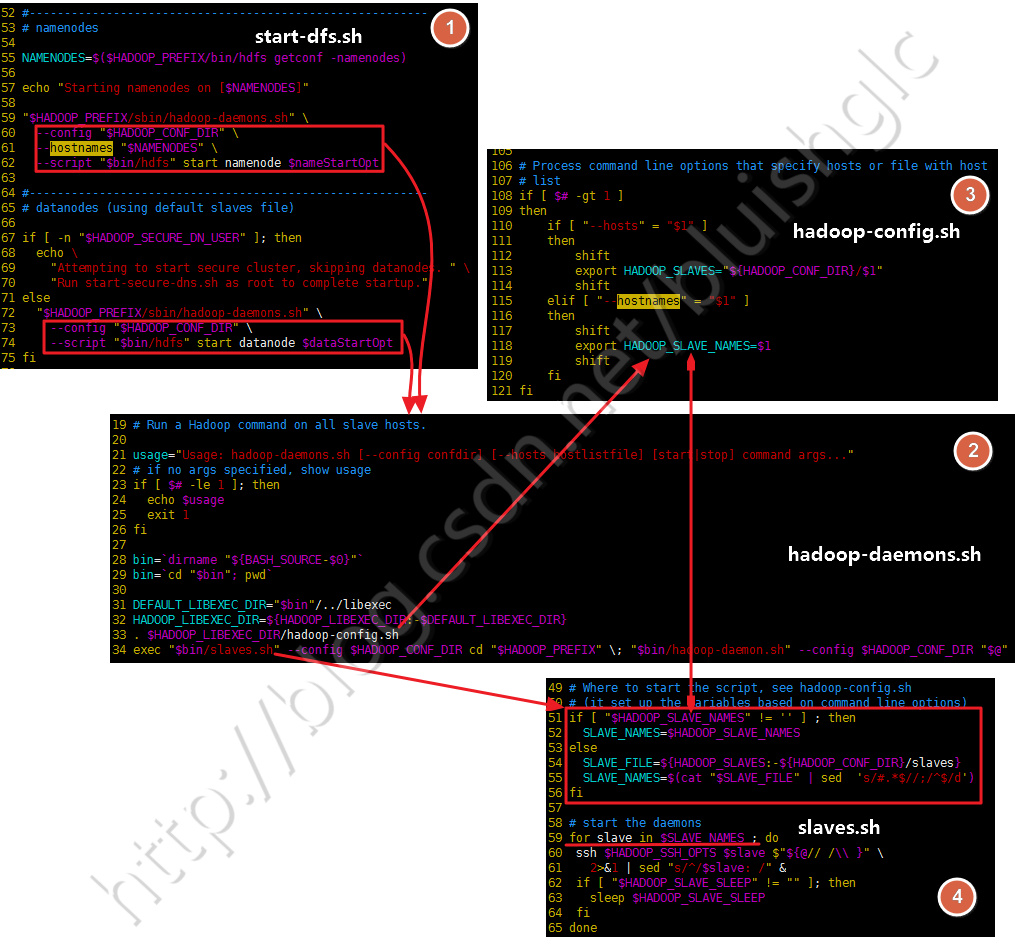
本文以start-dfs.sh为例向下延展解释各脚本的作用和相互关系,对于start-yarn.sh同理可证。下图解释了各个脚本的作用:

注意:slaves.sh在通过SSH推送命令时,会首先读取$HADOOP_SLAVE_NAMES这个数组中的机器列表作为推送目标,当这个数组为空时才使用slaves文件中给出的机器列表。实际上slaves.sh这个脚本的命名很不好,它会给人一种误导,这个脚本实际上是一个向目标机器列表推送命令的util脚本,而不是只向slave节点通信的!这一点在start-dfs.sh(start-yarn.sh)脚本中都有明确的体现,实际上:start-dfs.sh所有的命令,不管是启动单个的namenode还是启动多个datanode,都是通过hadoop-daemons.sh,再通过slaves.sh推送到目标机器上的,唯一不同的地方是:在启动namenode和secondary-namenode的时候都通过--hostnames参数显示地给出了命令的推送目标(注:将--hostnames参数的值会赋给HADOOP_SLAVE_NAMES这个动作发生在libexec/hadoop-config.sh脚本里,在hadoop-daemons.sh里,调用slaves.sh之前会先执行hadoop-config.sh,完成对HADOOP_SLAVE_NAMES的设值)而在启动datanode时,则不会设置--hostnames的值,这样HADOOP_SLAVE_NAMES的值会从slaves文件中读取,也就datanode的列表。关于这一过程,请参考下图!
(责任编辑:IT)
| 本文以start-dfs.sh为例向下延展解释各脚本的作用和相互关系,对于start-yarn.sh同理可证。下图解释了各个脚本的作用:
注意:slaves.sh在通过SSH推送命令时,会首先读取$HADOOP_SLAVE_NAMES这个数组中的机器列表作为推送目标,当这个数组为空时才使用slaves文件中给出的机器列表。实际上slaves.sh这个脚本的命名很不好,它会给人一种误导,这个脚本实际上是一个向目标机器列表推送命令的util脚本,而不是只向slave节点通信的!这一点在start-dfs.sh(start-yarn.sh)脚本中都有明确的体现,实际上:start-dfs.sh所有的命令,不管是启动单个的namenode还是启动多个datanode,都是通过hadoop-daemons.sh,再通过slaves.sh推送到目标机器上的,唯一不同的地方是:在启动namenode和secondary-namenode的时候都通过--hostnames参数显示地给出了命令的推送目标(注:将--hostnames参数的值会赋给HADOOP_SLAVE_NAMES这个动作发生在libexec/hadoop-config.sh脚本里,在hadoop-daemons.sh里,调用slaves.sh之前会先执行hadoop-config.sh,完成对HADOOP_SLAVE_NAMES的设值)而在启动datanode时,则不会设置--hostnames的值,这样HADOOP_SLAVE_NAMES的值会从slaves文件中读取,也就datanode的列表。关于这一过程,请参考下图!
(责任编辑:IT) |