CentOS 5.10安装hadoop-1.2.1
时间:2015-09-15 20:06 来源:linux.it.net.cn 作者:IT
系统环境:CentOS 5.10(虚拟机下)
[plain] view plaincopyprint?

-
[root@localhost hadoop]# lsb_release -a
-
LSB Version: :core-4.0-ia32:core-4.0-noarch:graphics-4.0-ia32:graphics-4.0-noarch:printing-4.0-ia32:printing-4.0-noarch
-
Distributor ID: CentOS
-
Description: CentOS release 5.10 (Final)
-
Release: 5.10
-
Codename: Final
准备
Jdk安装与配置
Oracle官网下载jdk,这里我下载的是jdk-6u45-linux-i586.bin,并上传到虚拟机上,使用root用户,执行以下命令创建文件夹,移动安装文件,执行安装。
[plain] view plaincopyprint?
-
mkdir /usr/java
-
mv/home/auxu/Desktop/jdk-6u45-linux-i586.bin /usr/java
-
cd /usr/java
-
./jdk-6u45-linux-i586.bin
配置环境变量
[plain] view plaincopyprint?
-
vi /etc/profile
加入
export JAVA_HOME=/usr/java/jdk1.6.0_45
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
保存完毕之后,执行:
[sql] view plaincopyprint?
-
source /etc/profile
验证java配置
[sql] view plaincopyprint?
-
[root@localhost java]# java -version
-
java version "1.6.0_45"
-
Java(TM) SE Runtime Environment (build 1.6.0_45-b06)
-
Java HotSpot(TM) Client VM (build 20.45-b01, mixed mode, sharing)
可以简单写一个java class来进行测试,这里不多说明
创建Hadoop用户及相关应用文件夹
同样使用root用户创建一个名为hadoop的新用户
[plain] view plaincopyprint?
-
useradd hadoop
-
passwd hadoop
创建应用文件夹,以便进行之后的hadoop配置
[sql] view plaincopyprint?
-
mkdir /hadoop
-
mkdir /hadoop/hdfs
-
mkdir /hadoop/hdfs/data
-
mkdir /hadoop/hdfs/name
-
mkdir /hadoop/mapred
-
mkdir /hadoop/mapred/local
-
mkdir /hadoop/mapred/system
-
mkdir /hadoop/tmp
将文件夹属主更改为hadoop用户
[plain] view plaincopyprint?
-
chown -R hadoop /hadoop
设置Hadoop用户使之可以免密码ssh到localhost
[sql] view plaincopyprint?
-
su - hadoop
-
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
-
cat ~/.ssh/id_dsa.pub>> ~/.ssh/authorized_keys
-
-
cd /home/hadoop/.ssh
-
chmod 600 authorized_keys
注意这里的权限问题,保证.ssh目录权限为700,authorized_keys为600
验证:
[plain] view plaincopyprint?
-
[hadoop@localhost .ssh]$ ssh localhost
-
Last login: Sun Nov 17 22:11:55 2013
ssh localhost之后无需输入密码就可以连接,配置OK
安装配置Hadoop
创建目录并安装
重新切回root用户,创建安装目录
[plain] view plaincopyprint?
-
su
[plain] view plaincopyprint?
-
mkdir /opt/hadoop
将安装文件移动到以上新建目录,确保其执行权限,然后执行
[plain] view plaincopyprint?
-
mv /home/auxu/Desktop/hadoop-1.2.1.tar.gz /opt/hadoop
-
cd /opt/hadoop
-
tar -xzvf hadoop-1.2.1.tar.gz
将hadoop安装目录的属主更改为hadoop用户
[plain] view plaincopyprint?
-
chown -R hadoop /opt/hadoop
切换到hadoop用户,修改配置文件,这里根据前面创建的应用文件进行相关配置,依照各自情况而定
[plain] view plaincopyprint?
-
su - hadoop
[plain] view plaincopyprint?
-
cd /opt/hadoop/hadoop-1.2.1/conf
core-site.xml
[html] view plaincopyprint?
-
<configuration>
-
<property>
-
<name>fs.default.name</name>
-
<value>hdfs://localhost:9000</value>
-
</property>
-
<property>
-
<name>hadoop.tmp.dir</name>
-
<value>/hadoop/tmp</value>
-
</property>
-
</configuration>
hdfs-site.xml
[html] view plaincopyprint?
-
<configuration>
-
<property>
-
<name>dfs.replication</name>
-
<value>1</value>
-
</property>
-
<property>
-
<name>dfs.name.dir</name>
-
<value>/hadoop/hdfs/name</value>
-
</property>
-
<property>
-
<name>dfs.data.dir</name>
-
<value>/hadoop/hdfs/data</value>
-
</property>
-
</configuration>
mapred-site.xml
[html] view plaincopyprint?
-
<configuration>
-
<property>
-
<name>mapred.job.tracker</name>
-
<value>localhost:9001</value>
-
</property>
-
</configuration>
hadoop-env.sh
配置JAVA_HOME 与 HADOOP_HOME_WARN_SUPPRESS。
PS:HADOOP_HOME_WARN_SUPPRESS这个变量可以避免某些情况下出现这样的提醒 "WARM: HADOOP_HOME is deprecated”
[plain] view plaincopyprint?
-
export JAVA_HOME=/usr/java/jdk1.6.0_45
-
export HADOOP_HOME_WARN_SUPPRESS="TRUE"
-
source hadoop-env.sh
重新配置 /etc/profile 文件,最终如:
[html] view plaincopyprint?
-
export JAVA_HOME=/usr/java/jdk1.6.0_45
-
export JRE_HOME=$JAVA_HOME/jre
-
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
-
export HADOOP_HOME=/opt/hadoop/hadoop-1.2.1
-
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
使更新后的配置文件生效
[html] view plaincopyprint?
-
source /etc/profile
测试hadoop安装
[html] view plaincopyprint?
-
[hadoop@localhost conf]$ hadoop version
-
Hadoop 1.2.1
-
Subversion https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.2 -r 1503152
-
Compiled by mattf on Mon Jul 22 15:23:09 PDT 2013
-
From source with checksum 6923c86528809c4e7e6f493b6b413a9a
启动HADOOP
需要先格式化namenode,再启动所有服务
[html] view plaincopyprint?
-
hadoop namenode -format
-
start-all.sh
查看进程
[html] view plaincopyprint?
-
hadoop@localhost conf]$ jps
-
6360 NameNode
-
6481 DataNode
-
6956 Jps
-
6818 TaskTracker
-
6610 SecondaryNameNode
-
6698 JobTracker
如果能找到这些服务,说明Hadoop已经成功启动了。
如果有什么问题,可以去/opt/hadoop/hadoop-1.2.1/logs查看相应的日志
最后就可以通过以下链接访问haddop服务了
localhost:50030/ for the Jobtracker
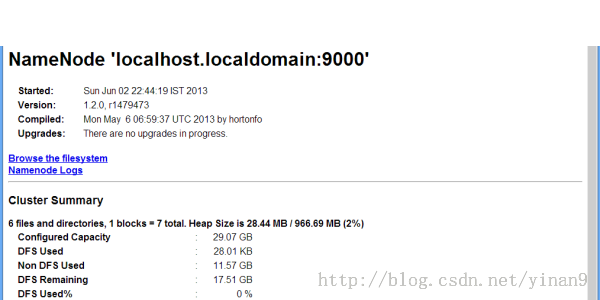
localhost:50070/ for the Namenode
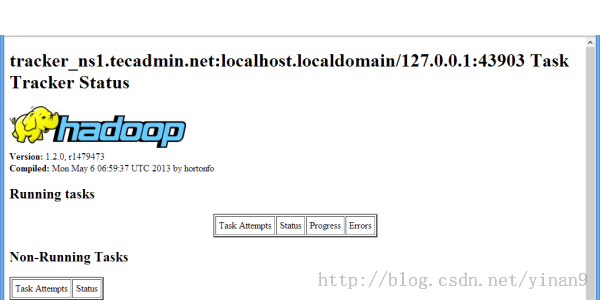
localhost:50060/ for the Tasktracker
Hadoop JobTracker:
 Hadoop Namenode:
Hadoop Namenode:
 Hadoop TaskTracker:
Hadoop TaskTracker:
 PS:完全分布式的安装与伪分布式安装大同小异,注意如下几点即可
1.集群内ssh免用户登录
2.配置文件中指定具体的ip地址(或机器名),而不是localhost
3.配置masters和slaves文件,加入相关ip地址(或机器名)即可
以上配置需要在各个节点上保持一致。
PS:完全分布式的安装与伪分布式安装大同小异,注意如下几点即可
1.集群内ssh免用户登录
2.配置文件中指定具体的ip地址(或机器名),而不是localhost
3.配置masters和slaves文件,加入相关ip地址(或机器名)即可
以上配置需要在各个节点上保持一致。
(责任编辑:IT)
系统环境:CentOS 5.10(虚拟机下)
[plain] view plaincopyprint?
准备
Jdk安装与配置
Oracle官网下载jdk,这里我下载的是jdk-6u45-linux-i586.bin,并上传到虚拟机上,使用root用户,执行以下命令创建文件夹,移动安装文件,执行安装。
[plain] view plaincopyprint?
配置环境变量
[plain] view plaincopyprint?
加入
export JAVA_HOME=/usr/java/jdk1.6.0_45
export JRE_HOME=$JAVA_HOME/jre export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$PATH:$JAVA_HOME/bin
保存完毕之后,执行:
[sql] view plaincopyprint?
[sql] view plaincopyprint?
创建Hadoop用户及相关应用文件夹
同样使用root用户创建一个名为hadoop的新用户
[plain] view plaincopyprint?
[sql] view plaincopyprint?
[plain] view plaincopyprint?
设置Hadoop用户使之可以免密码ssh到localhost
[sql] view plaincopyprint?
验证:
[plain] view plaincopyprint?
安装配置Hadoop
创建目录并安装
重新切回root用户,创建安装目录
[plain] view plaincopyprint?
[plain] view plaincopyprint?
[plain] view plaincopyprint?
将hadoop安装目录的属主更改为hadoop用户
[plain] view plaincopyprint?
[plain] view plaincopyprint?
[plain] view plaincopyprint?
core-site.xml
[html] view plaincopyprint?
hdfs-site.xml
[html] view plaincopyprint?
mapred-site.xml
[html] view plaincopyprint?
hadoop-env.sh
配置JAVA_HOME 与 HADOOP_HOME_WARN_SUPPRESS。
PS:HADOOP_HOME_WARN_SUPPRESS这个变量可以避免某些情况下出现这样的提醒 "WARM: HADOOP_HOME is deprecated”
[plain] view plaincopyprint?
重新配置 /etc/profile 文件,最终如:
[html] view plaincopyprint?
使更新后的配置文件生效
[html] view plaincopyprint?
[html] view plaincopyprint?
启动HADOOP
需要先格式化namenode,再启动所有服务
[html] view plaincopyprint?
查看进程
[html] view plaincopyprint?
如果有什么问题,可以去/opt/hadoop/hadoop-1.2.1/logs查看相应的日志
最后就可以通过以下链接访问haddop服务了
localhost:50030/ for the Jobtracker localhost:50070/ for the Namenode localhost:50060/ for the Tasktracker
Hadoop JobTracker:
Hadoop Namenode:
Hadoop TaskTracker:
PS:完全分布式的安装与伪分布式安装大同小异,注意如下几点即可
1.集群内ssh免用户登录
2.配置文件中指定具体的ip地址(或机器名),而不是localhost
3.配置masters和slaves文件,加入相关ip地址(或机器名)即可
以上配置需要在各个节点上保持一致。
|